Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Häufige ElastiCache Anwendungsfälle und wie ElastiCache Sie helfen können
Ob es sich um die neuesten Nachrichten, eine Top-10-Rangliste, einen Produktkatalog oder den Verkauf von Eintrittskarten für eine Veranstaltung handelt - Geschwindigkeit ist das A und O. Der Erfolg Ihrer Website und Ihres Unternehmens hängt stark von der Geschwindigkeit ab, mit der Sie Inhalte bereitstellen.
In ihrem Artikel „For Unpatient Web Users, an Eye Blink Is Just Too Long to Wait
Wenn jemand Daten wünscht, können Sie diese Daten viel schneller bereitstellen, wenn sie im Cache gespeichert sind. Das gilt sowohl für eine Webseite als auch für einen Bericht, der als Grundlage für Geschäftsentscheidungen dient. Kann es sich Ihr Unternehmen leisten, Ihre Webseiten nicht zwischenzuspeichern, um sie so mit der kürzestmöglichen Latenz bereitzustellen?
Es mag intuitiv einleuchtend erscheinen, dass Sie die am häufigsten nachgefragten Artikel in den Cache stellen wollen. Aber warum sollten Sie nicht auch weniger häufig angefragte Elemente zwischenspeichern? Selbst eine optimierte Datenbankabfrage oder ein Remote-API-Aufruf ist deutlich langsamer als das Abrufen eines flachen Schlüssels aus einem In-Memory-Cache. Eine merkliche Verlangsamung führt dazu, dass Kunden abwandern.
Die folgenden Beispiele veranschaulichen einige Möglichkeiten, wie Sie die Gesamtleistung Ihrer Anwendung verbessern ElastiCache können.
In-Memory Datenspeicher
Der primäre Zweck eines Hauptspeicher-basierten Key-Value Store besteht darin, superschnellen (mit einer Latenz von unter einer Millisekunde) und kostengünstigen Zugriff auf Kopien von Daten bereitzustellen. Die meisten Datenspeicher haben Bereiche mit Daten, auf die häufig zugegriffen wird, die aber selten aktualisiert werden. Außerdem wird das Abfragen einer Datenbank immer langsamer und kostspieliger sein als das Auffinden eines Schlüssels in einem Schlüsselwertpaar-Cache. Manche Datenbankabfragen sind besonders aufwendig in der Durchführung. Ein Beispiel dafür sind Abfragen, die Joins über mehrere Tabellen oder Abfragen mit intensiven Berechnungen beinhalten. Durch die Zwischenspeicherung solcher Abfrageergebnisse zahlen Sie den Preis für die Abfrage nur einmal. Dann können Sie die Daten schnell und mehrfach abrufen, ohne die Abfrage erneut ausführen zu müssen.
Was sollte ich zwischenspeichern?
Bei der Entscheidung, welche Daten zwischengespeichert werden, sind folgende Faktoren zu berücksichtigen:
Geschwindigkeit und Kosten – Es ist immer langsamer und teurer, Daten aus einer Datenbank abzurufen als aus einem Cache. Manche Datenbankabfragen sind grundsätzlich langsamer und kostspieliger als andere. Beispielsweise sind Abfragen, bei denen mehrere Tabellen miteinander verknüpft werden, viel langsamer und teurer als einfache Abfragen, die nur eine Tabelle betreffen. Wenn die interessanten Daten eine langsame und teure Abfrage erfordern, sind sie ein Kandidat für das Caching. Wenn der Abruf der Daten eine relativ schnelle und einfache Abfrage erfordert, kann er je nach anderen Faktoren immer noch ein Kandidat für die Zwischenspeicherung sein.
Daten und Zugriffsmuster – Um zu bestimmen, was zwischengespeichert werden soll, müssen auch die Daten selbst und ihre Zugriffsmuster verstanden werden. So ist es beispielsweise nicht sinnvoll, Daten, die sich schnell ändern oder auf die nur selten zugegriffen wird, im Cache zu speichern. Damit die Zwischenspeicherung einen echten Nutzen bringt, sollten die Daten relativ statisch sein und häufig abgerufen werden. Ein Beispiel wäre ein persönliches Profil auf einer Social-Media-Website. Andererseits sollten Sie keine Daten zwischenspeichern, wenn das Zwischenspeichern keine Geschwindigkeits- oder Preisvorteile bringt. So ist es beispielsweise nicht sinnvoll, Webseiten, die Suchergebnisse liefern, in den Cache zu stellen, da die Abfragen und Ergebnisse in der Regel einzigartig sind.
Unvergänglichkeit – Per Definition sind zwischengespeicherte Daten veraltete Daten. Selbst wenn es unter bestimmten Umständen nicht veraltet ist, sollte es immer als veraltet betrachtet und behandelt werden. Um festzustellen, ob Ihre Daten für die Zwischenspeicherung geeignet sind, müssen Sie die Toleranz Ihrer Anwendung gegenüber veralteten Daten ermitteln.
Es kann sein, dass Ihre Anwendung veraltete Daten in dem einen Kontext tolerieren kann, nicht jedoch in einem anderen. Nehmen wir zum Beispiel an, dass Ihre Website einen öffentlich gehandelten Aktienkurs anbietet. Ihre Kunden könnten eine gewisse Unbeständigkeit akzeptieren, wenn sie darauf hingewiesen werden, dass sich die Preise um n Minuten verzögern können. Aber wenn Sie diesen Aktienkurs einem Broker für einen Kauf oder Verkauf zur Verfügung stellen, benötigen Sie Echtzeitdaten.
Erwägen Sie die Zwischenspeicherung Ihrer Daten, wenn Folgendes zutrifft:
Der Abruf Ihrer Daten ist im Vergleich zum Abruf aus dem Cache langsam oder teuer.
Benutzer greifen häufig auf Ihre Daten zu.
Ihre Daten bleiben relativ konstant, oder wenn sie sich schnell ändern, ist die Unbeständigkeit kein großes Problem.
Weitere Informationen finden Sie unter Caching-Strategien für Memcached.
Gaming-Bestenlisten
Mit sortierten Sets von Valkey oder Redis OSS können Sie die Rechenkomplexität von Bestenlisten von Ihrer Anwendung auf Ihren Cluster verlagern.
Bestenlisten, wie z. B. die 10 besten Ergebnisse eines Spiels, sind rechenintensiv. Dies gilt vor allem bei einer großen Anzahl gleichzeitiger Spieler und sich ständig ändernden Spielständen. Die sortierten Sätze von Valkey und Redis OSS garantieren sowohl Einzigartigkeit als auch Reihenfolge der Elemente. Bei sortierten Sätzen wird jedes Mal, wenn ein neues Element zur sortierten Menge hinzugefügt wird, dieses in Echtzeit neu eingestuft. Es wird dann in der numerisch richtigen Reihenfolge in die Menge eingefügt.
In der folgenden Abbildung können Sie sehen, wie eine ElastiCache Gaming-Bestenliste funktioniert.
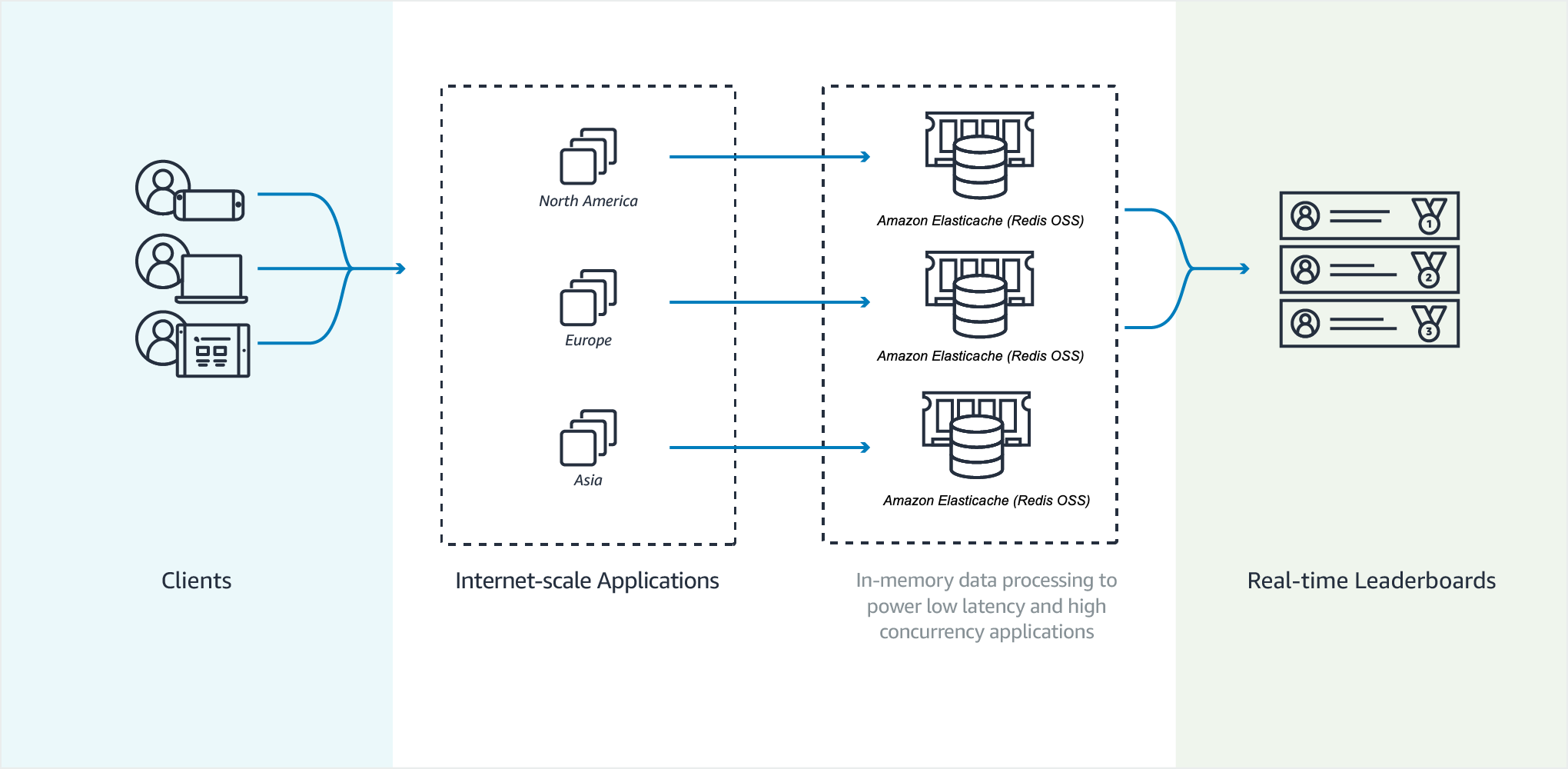
Beispiel Valkey oder Redis OSS-Bestenliste
In diesem Beispiel werden vier Spieler und ihre Ergebnisse mithilfe von ZADD in eine sortierte Liste eingegeben. Der Befehl ZREVRANGEBYSCORE listet die Spieler in absteigender Reihenfolge entsprechend ihrem Ergebnis auf. Als Nächstes wird ZADD verwendet, um das Ergebnis von June zu aktualisieren, indem der bestehende Eintrag überschrieben wird. Zum Schluss werden die Spieler von ZREVRANGEBYSCORE nach ihrer Punktzahl aufgelistet, von hoch bis niedrig. Die Liste zeigt, dass June in der Rangliste aufgestiegen ist.
ZADD leaderboard 132 Robert ZADD leaderboard 231 Sandra ZADD leaderboard 32 June ZADD leaderboard 381 Adam ZREVRANGEBYSCORE leaderboard +inf -inf 1) Adam 2) Sandra 3) Robert 4) June ZADD leaderboard 232 June ZREVRANGEBYSCORE leaderboard +inf -inf 1) Adam 2) June 3) Sandra 4) Robert
Mit dem folgenden Befehl erfährt June, auf welchem Platz sie unter allen Spielern steht. Da die Rangliste auf der Basis von Nullen erstellt wird, ergibt ZREVRANK eine 1 für June, die an zweiter Stelle steht.
ZREVRANK leaderboard June 1
Weitere Informationen finden Sie in der Valkey-Dokumentation
Nachrichtenübermittlung () Pub/Sub
Wenn Sie eine E-Mail-Nachricht versenden, senden Sie sie an mindestens einen angegebenen Empfänger. Im pub/sub OSS-Paradigma von Valkey und Redis senden Sie eine Nachricht an einen bestimmten Kanal, ohne zu wissen, wer, wenn überhaupt, sie empfängt. Die Nachricht wird nur an die Personen gesendet, die den Kanal abonniert haben. Angenommen, Sie haben etwa den news.sports.golf-Channel abonniert. Sie und alle anderen, die den Kanal news.sports.golf abonniert haben, erhalten alle auf news.sports.golf veröffentlichten Nachrichten.
Pub/sub Funktionalität hat keinen Bezug zu einem Schlüsselraum. Daher gibt es auf keinem Level Beeinträchtigungen. Im folgenden Diagramm finden Sie eine Abbildung des ElastiCache Messagings mit Valkey und Redis OSS.
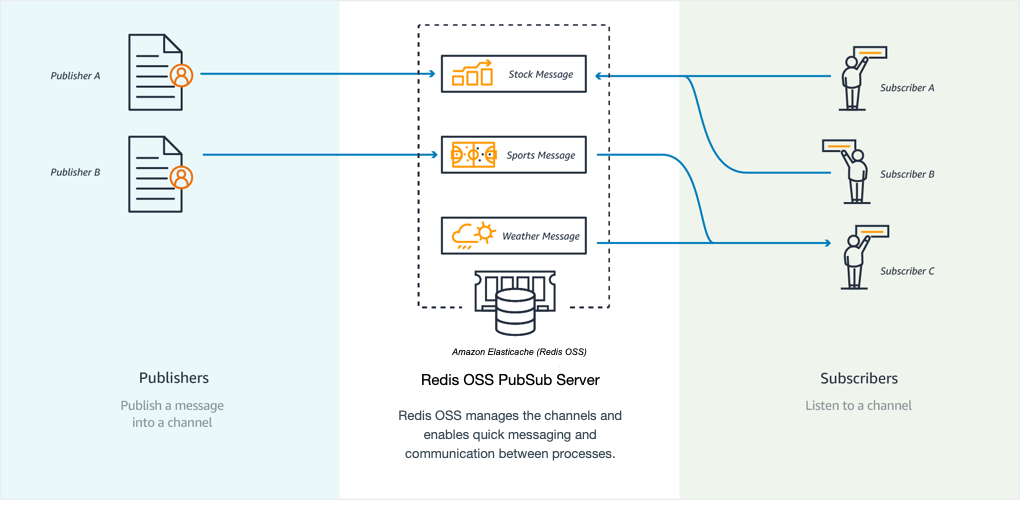
Abonnieren
Um Nachrichten in einem Kanal zu erhalten, abonnieren Sie den Kanal. Sie können einen einzelnen Channel, mehrere spezielle Channels oder alle Channels, die einem Muster entsprechen, abonnieren. Um ein Abonnement zu kündigen, melden Sie sich von dem Kanal ab, den Sie abonniert haben. Wenn Sie sich mit Hilfe eines Musterabgleichs angemeldet haben, können Sie sich auch mit demselben Muster wieder abmelden, das Sie zuvor verwendet haben.
Beispiel– Abonnement eines einzelnen Channels
Um einen einzelnen Channel zu abonnieren, verwenden Sie den SUBSCRIBE-Befehl unter Angabe des Channels, den Sie abonnieren möchten. Im folgenden Beispiel abonniert ein Client den Channel news.sports.golf.
SUBSCRIBE news.sports.golf
Nach einer Weile kündigt der Client das Abonnement für den Channel mithilfe des UNSUBSCRIBE-Befehls unter Angabe des Channels, dessen Abonnement gekündigt werden soll.
UNSUBSCRIBE news.sports.golf
Beispiel– Abonnement mehrerer ausgewählter Channels
Um mehrere bestimmte Channels zu abonnieren, listen Sie die Channels mit dem SUBSCRIBE-Befehl auf. Im folgenden Beispiel abonniert ein Client die Channels news.sports.golf, news.sports.soccer und news.sports.skiing.
SUBSCRIBE news.sports.golf news.sports.soccer news.sports.skiing
Um ein Abonnement für einen bestimmten Kanal zu kündigen, verwenden Sie den Befehl UNSUBSCRIBE und geben Sie den Kanal an, von dem Sie sich abmelden möchten.
UNSUBSCRIBE news.sports.golf
Um Abonnements für mehrere Kanäle zu kündigen, verwenden Sie den Befehl UNSUBSCRIBE und geben Sie die Kanäle an, die Sie abbestellen möchten.
UNSUBSCRIBE news.sports.golf news.sports.soccer
Um alle Abonnements zu kündigen, verwenden Sie UNSUBSCRIBE und geben Sie jeden Kanal an. Oder verwenden Sie UNSUBSCRIBE ohne einen Kanal anzugeben.
UNSUBSCRIBE news.sports.golf news.sports.soccer news.sports.skiing
oder
UNSUBSCRIBE
Beispiel– Abonnements mithilfe von Musterabgleich
Clients können alle Channels abonnieren, die einem Muster entsprechen, indem sie den PSUBSCRIBE-Befehl verwenden.
Im folgenden Beispiel abonniert ein Client alle Sport-Channels. Sie listen nicht alle Sportkanäle einzeln auf, wie Sie es bei SUBSCRIBE tun. Mit dem PSUBSCRIBE-Befehl verwenden Sie stattdessen den Mustervergleich.
PSUBSCRIBE news.sports.*
Beispiel Kündigen von Abonnements
Um Abonnements für diese Channels zu kündigen, verwenden Sie den PUNSUBSCRIBE-Befehl.
PUNSUBSCRIBE news.sports.*
Wichtig
Die Channel-Zeichenfolgen, die an einen [P]SUBSCRIBE-Befehl bzw. an den [P]UNSUBSCRIBE-Befehl gesendet werden, müssen übereinstimmen.
PSUBSCRIBEzu news.* undPUNSUBSCRIBEvon news.sports.* oderUNSUBSCRIBEvon news.sports.golf ist nicht möglich.PSUBSCRIBEundPUNSUBSCRIBEsind nicht für ElastiCache Serverless verfügbar.
Veröffentlichen
Um eine Nachricht an alle Abonnenten eines Kanals zu senden, verwenden Sie den PUBLISH-Befehl, wobei Sie den Kanal und die Nachricht angeben. Im folgenden Beispiel wird diese Nachricht veröffentlicht: "Es ist Samstag und sonnig. Ich fahre zu den Links.“ auf den news.sports.golf-Kanal.
PUBLISH news.sports.golf "It's Saturday and sunny. I'm headed to the links."
Ein Client kann nicht auf einem Kanal veröffentlichen, den er abonniert hat.
Weitere Informationen finden Sie Pub/Sub
Empfehlungsdaten (Hashes)
Die Verwendung von INCR oder DECR in Valkey oder Redis OSS macht das Kompilieren von Empfehlungen einfach. Jedes Mal, wenn ein Nutzer ein Produkt mit „Gefällt mir“ markiert, erhöhen Sie einen Artikel:Produktzähler. ID:like Jedes Mal, wenn ein Nutzer ein Produkt „nicht mag“, erhöhen Sie den Artikel-/Produktzähler. ID:dislike Mithilfe von Hashes können Sie auch eine Liste aller Personen führen, denen ein Produkt gefallen oder nicht gefallen hat.
Beispiel– Likes und Dislikes
INCR item:38923:likes HSET item:38923:ratings Susan 1 INCR item:38923:dislikes HSET item:38923:ratings Tommy -1
Semantisches Caching für generative KI-Anwendungen
Der Betrieb generativer KI-Anwendungen in großem Maßstab kann aufgrund der Kosten und der Latenz, die mit Inferenzaufrufen für große Sprachmodelle (LLMs) verbunden sind, eine Herausforderung sein. Sie können es ElastiCache für semantisches Caching in generativen KI-Anwendungen verwenden, wodurch Sie die Kosten und die Latenz von LLM-Inferenzaufrufen reduzieren können. Mit semantischem Caching können Sie eine zwischengespeicherte Antwort zurückgeben, indem Sie mithilfe eines vektorbasierten Abgleichs Ähnlichkeiten zwischen aktuellen und früheren Eingabeaufforderungen ermitteln. Wenn die Eingabeaufforderung eines Benutzers einer vorherigen Aufforderung semantisch ähnelt, wird eine zwischengespeicherte Antwort zurückgegeben, anstatt einen neuen LLM-Inferenzaufruf zu tätigen. Dadurch werden die Kosten für generative KI-Anwendungen gesenkt und schnellere Antworten bereitgestellt, die die Benutzererfahrung verbessern. Sie können steuern, welche Abfragen an den Cache weitergeleitet werden, indem Sie Ähnlichkeitsschwellenwerte für Eingabeaufforderungen konfigurieren und Tagfilter oder numerische Metadatenfilter anwenden.
Die Inline-Indexaktualisierungen in Echtzeit, die von Vector Search for bereitgestellt werden ElastiCache , stellen sicher, dass der Cache kontinuierlich aktualisiert wird, wenn Benutzeraufforderungen und LLM-Antworten eingehen. Diese Indizierung in Echtzeit ist entscheidend, um die Aktualität der zwischengespeicherten Ergebnisse und die Cache-Trefferquoten aufrechtzuerhalten, insbesondere bei hohem Datenverkehr. Darüber hinaus ElastiCache vereinfacht sie Operationen für das semantische Caching durch ausgereifte Cache-Primitive wie TTLs pro Schlüssel, konfigurierbare Entfernungsstrategien, atomare Operationen und umfangreiche Datenstruktur- und Skriptunterstützung.
Speicher für generative KI-Assistenten und -Agenten
Sie können ElastiCache es verwenden, um personalisiertere, kontextsensivere Antworten zu geben, indem Sie Speichermechanismen implementieren, die LLMs den Verlauf sitzungsübergreifender Konversationen anzeigen. Das Konversationsgedächtnis ermöglicht generativen KI-Assistenten und -Agenten, vergangene Interaktionen zu speichern und zu nutzen, um Antworten zu personalisieren und die Relevanz zu verbessern. Das bloße Zusammenfassen aller vorherigen Interaktionen in der Aufforderung ist jedoch ineffektiv, da irrelevante zusätzliche Token die Kosten erhöhen, die Antwortqualität verschlechtern und das Risiko bergen, das Kontextfenster des LLM zu überschreiten. Stattdessen können Sie die Vektorsuche verwenden, um für jeden LLM-Aufruf nur die relevantesten Daten im Kontext abzurufen und bereitzustellen.
ElastiCache for Valkey bietet Integrationen mit Open-Source-Speicherschichten und bietet integrierte Konnektoren zum Speichern und Abrufen von Speichern für LLM-Anwendungen und -Agenten. Die Vektorsuche für ElastiCache ermöglicht schnelle Indexaktualisierungen, hält den Speicher auf dem neuesten Stand und macht neue Speicher sofort durchsuchbar. Die Vektorsuche mit niedriger Latenz ermöglicht eine schnelle Speichersuche, sodass sie im Online-Pfad jeder Anfrage implementiert werden kann, nicht nur bei Hintergrundaufgaben. Neben der Vektorsuche bietet ElastiCache for Valkey auch Caching-Primitive für Sitzungsstatus, Benutzereinstellungen und Feature-Flags und bietet so einen einzigen Dienst zum Speichern von kurzlebigen Sitzungszuständen und langfristigen „Erinnerungen“ in einem Datenspeicher.
Erweiterte Generierung (Retrieval Augmented Generation)
RAG ist der Prozess, bei dem LLMs aktuelle Informationen zur Verfügung gestellt werden, um die Relevanz der Antworten zu verbessern. RAG reduziert Halluzinationen und verbessert die Genauigkeit der Fakten, indem es die Ergebnisse auf realen Datenquellen stützt. RAG-Anwendungen verwenden die Vektorsuche, um semantisch relevante Inhalte aus einer Wissensdatenbank abzurufen. Die von bereitgestellte Vektorsuche mit niedriger Latenz ElastiCache eignet sich für die Implementierung von RAG in Workloads mit großen Datensätzen mit Millionen von Vektoren und mehr. Darüber hinaus ElastiCache eignet sich die Unterstützung für Online-Vektorindex-Updates für Assistenten mit Upload-Workflows, die sicherstellen müssen, dass alle hochgeladenen Daten sofort durchsuchbar sind. RAG stellt in KI-Systemen für Agenturen sicher, dass die Agenten über aktuelle Informationen verfügen, um präzise Maßnahmen ergreifen zu können. Die Vektorsuche mit niedriger Latenz ist auch für RAG in agentischen KI-Systemen von entscheidender Bedeutung, bei denen eine einzelne Abfrage mehrere LLM-Aufrufe auslösen und die Latenz der zugrunde liegenden Vektorsuche erhöhen kann.
Das folgende Diagramm zeigt eine Beispielarchitektur, mit ElastiCache der ein semantischer Cache, Speichermechanismen und RAG implementiert werden, um eine generative KI-Anwendung in der Produktion zu verbessern.
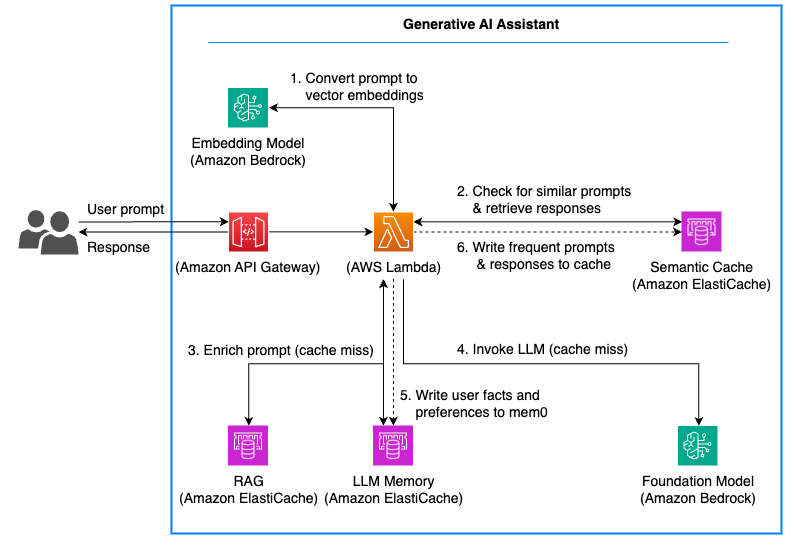
Semantische Suche
Die Vektorsuche ruft die relevantesten Text-, Sprach-, Bild- oder Videodaten auf der Grundlage ähnlicher Bedeutungen oder Merkmale ab. Diese Funktion ermöglicht Anwendungen für maschinelles Lernen, die auf der Ähnlichkeitssuche in verschiedenen Datenmodalitäten basieren, darunter Empfehlungsmaschinen, Anomalieerkennungs-, Personalisierungs- und Wissensmanagementsysteme. Empfehlungssysteme verwenden Vektordarstellungen, um komplexe Muster im Nutzerverhalten und in den Artikelmerkmalen zu erfassen, sodass sie die relevantesten Inhalte vorschlagen können. Die Vektorsuche nach eignet sich gut für diese Anwendungen, da sie fast in Echtzeit aktualisiert ElastiCache wird und die Latenz gering ist. Sie ermöglicht Ähnlichkeitsvergleiche, die sofortige, hochrelevante Empfehlungen auf der Grundlage von Benutzerinteraktionen in Echtzeit liefern.
ElastiCache Kundenreferenzen
Weitere Informationen darüber, wie Unternehmen wie Airbnb, PBS, Esri und andere Amazon nutzen, ElastiCache um ihr Geschäft durch ein verbessertes Kundenerlebnis auszubauen, finden Sie unter So nutzen andere
Sie können sich auch die Tutorial-Videos für weitere Anwendungsfälle von ElastiCache Kunden ansehen.
