Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon-Athena-MSK-Konnektor
Der Amazon-Athena-Konnektor für Amazon MSK
Dieser Konnektor verwendet keine Glue Connections, um die Konfigurationseigenschaften in Glue zu zentralisieren. Die Verbindungskonfiguration erfolgt über Lambda.
Voraussetzungen
Stellen Sie den Konnektor für Ihr AWS-Konto mithilfe der Athena-Konsole oder AWS Serverless Application Repository bereit. Für weitere Informationen siehe Eine Datenquellenverbindung erstellen oder Verwenden Sie den AWS Serverless Application Repository , um einen Datenquellenconnector bereitzustellen.
Einschränkungen
-
Schreiboperationen wie DDL werden nicht unterstützt.
-
Alle relevanten Lambda-Grenzwerte. Weitere Informationen finden Sie unter Lambda quotas (Lambda-Kontingente) im AWS Lambda -Entwicklerhandbuch.
-
Datums- und Zeitstempeldatentypen in Filterbedingungen müssen in geeignete Datentypen umgewandelt werden.
-
Datums- und Zeitstempel-Datentypen werden für den CSV-Dateityp nicht unterstützt und als Varchar-Werte behandelt.
-
Die Zuordnung zu verschachtelten JSON-Feldern wird nicht unterstützt. Der Konnektor ordnet nur Felder der obersten Ebene zu.
-
Der Konnektor unterstützt keine komplexen Typen. Komplexe Typen werden als Zeichenfolgen interpretiert.
-
Verwenden Sie die in Athena verfügbaren JSON-related Funktionen, um komplexe JSON-Werte zu extrahieren oder damit zu arbeiten. Weitere Informationen finden Sie unter Extrahieren Sie JSON-Daten aus Zeichenfolgen.
-
Der Konnektor unterstützt keinen Zugriff auf Kafka-Nachrichtenmetadaten.
Bedingungen
-
Metadaten-Handler – Ein Lambda-Handler, der Metadaten von Ihrer Datenbank-Instance abruft.
-
Record Handler – Ein Lambda-Handler, der Datensätze aus Ihrer Datenbank-Instance abruft.
-
Composite Handler – Ein Lambda-Handler, der sowohl Metadaten als auch Datensätze aus Ihrer Datenbank-Instance abruft.
-
Kafka-Endpunkt – Eine Textzeichenfolge, die eine Verbindung zu einer Kafka-Instance herstellt.
Cluster-Kompatibilität
Der MSK-Konnektor kann mit den folgenden Cluster-Typen verwendet werden.
-
Von MSK bereitgestellter Cluster – Sie spezifizieren, überwachen und skalieren die Cluster-Kapazität manuell.
-
MSK Serverless Cluster — Bietet On-Demand-Kapazität, die automatisch mit der Skalierung der Anwendung skaliert wird. I/O
-
Eigenständiges Kafka – Eine direkte Verbindung zu Kafka (authentifiziert oder unauthentifiziert).
Unterstützte Authentifizierungsmethoden
Der Konnektor unterstützt die folgenden Authentifizierungsmethoden.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NO_AUTH
Weitere Informationen finden Sie unter Konfigurieren der Authentifizierung für den Athena-MSK-Konnektor.
Unterstützte Eingabedatenformate
Der Konnektor unterstützt die folgenden Eingabedatenformate.
-
JSON
-
CSV
Parameters
Verwenden Sie die Parameter in diesem Abschnitt, um den Athena-MSK-Konnektor zu konfigurieren.
-
auth_type – Gibt den Authentifizierungstyp des Clusters an. Der Konnektor unterstützt die folgenden Arten der Authentifizierung:
-
NO_AUTH – Stellen Sie eine direkte Verbindung zu Kafka ohne Authentifizierung her (z. B. zu einem Kafka-Cluster, der über eine EC2-Instance bereitgestellt wird, die keine Authentifizierung verwendet).
-
SASL_SSL_PLAIN – Diese Methode verwendet das
SASL_SSL-Sicherheitsprotokoll und denPLAIN-SASL-Mechanismus. -
SASL_PLAINTEXT_PLAIN – Diese Methode verwendet das
SASL_PLAINTEXT-Sicherheitsprotokoll und denPLAIN-SASL-Mechanismus.Anmerkung
Die
SASL_SSL_PLAIN- undSASL_PLAINTEXT_PLAIN-Authentifizierungstypen werden von Apache Kafka unterstützt, jedoch nicht von Amazon MSK. -
SASL_SSL_ AWS_MSK_IAM — Mit der IAM-Zugriffskontrolle für Amazon MSK können Sie sowohl die Authentifizierung als auch die Autorisierung für Ihren MSK-Cluster durchführen. Die AWS Anmeldeinformationen Ihres Benutzers (geheimer Schlüssel und Zugriffsschlüssel) werden für die Verbindung mit dem Cluster verwendet. Weitere Informationen finden Sie unter IAM-Zugriffskontrolle im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
-
SASL_SSL_SCRAM_SHA512 – Mit diesem Authentifizierungstyp können Sie den Zugriff auf Ihre Amazon-MSK-Cluster steuern. Diese Methode speichert den Benutzernamen und das Passwort auf AWS Secrets Manager. Das Geheimnis muss dem Amazon-MSK-Cluster zugeordnet sein. Weitere Informationen finden Sie unter Einrichten der SASL/SCRAM Authentifizierung für einen Amazon MSK-Cluster im Amazon Managed Streaming for Apache Kafka Developer Guide.
-
SSL – Die SSL-Authentifizierung verwendet Schlüsselspeicher- und Vertrauensspeicherdateien, um eine Verbindung mit dem Amazon-MSK-Cluster herzustellen. Sie müssen die Trust-Store- und Key-Store-Dateien generieren, sie in einen Amazon-S3-Bucket hochladen und die Referenz auf Amazon S3 angeben, wenn Sie den Konnektor bereitstellen. Der Schlüsselspeicher, der Vertrauensspeicher und der SSL-Schlüssel werden in AWS Secrets Manager gespeichert. Ihr Client muss den AWS geheimen Schlüssel angeben, wenn der Connector bereitgestellt wird. Weitere Informationen finden Sie unter Gegenseitige TLS-Authentifizierung im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
Weitere Informationen finden Sie unter Konfigurieren der Authentifizierung für den Athena-MSK-Konnektor.
-
-
certificates_s3_reference – Der Amazon-S3-Speicherort, der die Zertifikate enthält (die Schlüsselspeicher- und Vertrauensspeicherdateien).
-
disable_spill_encryption – (Optional) Bei Einstellung auf
True, wird die Spill-Verschlüsselung deaktiviert. Die Standardeinstellung istFalseso, dass Daten, die auf S3 übertragen werden, entweder mit AES-GCM einem zufällig generierten Schlüssel oder mit KMS zur Schlüsselgenerierung verschlüsselt werden. Das Deaktivieren der Überlauf-Verschlüsselung kann die Leistung verbessern, insbesondere wenn Ihr Überlauf-Standort eine serverseitige Verschlüsselung verwendet. -
kafka_endpoint – Die Endpunktdetails, die Kafka bereitgestellt werden sollen. Für einen Amazon MSK-Cluster stellen Sie beispielsweise eine Bootstrap-URL für den Cluster bereit.
-
secrets_manager_secret – Der Name des AWS -Geheimnisses, in dem die Anmeldeinformationen gespeichert sind. Dieser Parameter ist für die IAM-Authentifizierung nicht erforderlich.
-
Überlauf-Parameter – Lambda-Funktionen speichern vorübergehend („Überlauf“) Daten, die nicht in den Speicher von Amazon S3 passen. Alle Datenbank-Instances, auf die mit derselben Lambda-Funktion zugegriffen wird, werden an denselben Speicherort verschoben. Verwenden Sie die Parameter in der folgenden Tabelle, um den Überlauf-Standort anzugeben.
Parameter Description spill_bucketErforderlich Der Name des Amazon-S3-Buckets, in den die Lambda-Funktion Daten übertragen kann. spill_prefixErforderlich Das Präfix innerhalb des Überlauf-Buckets, in dem die Lambda-Funktion Daten ausgeben kann. spill_put_request_headers(Optional) Eine JSON-codierte Zuordnung von Anforderungsheadern und Werten für die Amazon-S3- putObject-Anforderung, die für den Überlauf verwendet wird (z. B.{"x-amz-server-side-encryption" : "AES256"}). Weitere mögliche Header finden Sie PutObjectin der Amazon Simple Storage Service API-Referenz.
Datentypunterstützung
Die folgende Tabelle zeigt die entsprechenden Datentypen, die für Kafka und Apache Arrow unterstützt werden.
| Kafka | Arrow |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP (ZEITSTEMPEL) | MILLISEKUNDE |
| DATE | TAG |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
Partitionen und Splits
Kafka-Themen sind in Partitionen unterteilt. Jede Partition ist geordnet. Jede Nachricht in einer Partition hat eine inkrementelle ID, die Offset genannt wird. Jede Kafka-Partition wird für die parallele Verarbeitung in weitere Splits unterteilt. Daten sind für den in Kafka-Clustern konfigurierten Aufbewahrungszeitraum verfügbar.
Bewährte Methoden
Verwenden Sie als bewährte Methode bei der Abfrage von Athena das Prädikat-Pushdown, wie in den folgenden Beispielen.
SELECT * FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE integercol = 2147483647
SELECT * FROM "msk_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'
Einrichten des MSK-Konnektors
Bevor Sie den Konnektor verwenden können, müssen Sie Ihren Amazon-MSK-Cluster einrichten, die AWS Glue -Schema-Registry verwenden, um Ihr Schema zu definieren, und die Authentifizierung für den Connector konfigurieren.
Anmerkung
Wenn Sie den Konnektor in einer VPC bereitstellen, um auf private Ressourcen zuzugreifen und auch eine Verbindung zu einem öffentlich zugänglichen Service wie Confluent herstellen möchten, müssen Sie den Konnektor einem privaten Subnetz zuordnen, das über ein NAT-Gateway verfügt. Weitere Informationen finden Sie unter NAT-Gateways im Amazon-VPC-Benutzerhandbuch.
Beachten Sie bei der Arbeit mit der AWS Glue Schema Registry die folgenden Punkte:
-
Stellen Sie sicher, dass der Text im Feld Description (Beschreibung) des AWS Glue -Schema-Registry die Zeichenfolge
{AthenaFederationMSK}enthält. Diese Markierungszeichenfolge ist für AWS Glue Registries erforderlich, die Sie mit dem Amazon Athena MSK-Connector verwenden. -
Verwenden Sie für Ihre Datenbanknamen und -tabellen nur Kleinbuchstaben, um eine optimale Leistung zu erzielen. Bei der Verwendung gemischter Groß- und Kleinschreibung führt der Konnektor eine Suche ohne Berücksichtigung der Groß- und Kleinschreibung durch, die rechenintensiver ist.
Um Ihre Amazon MSK-Umgebung einzurichten und AWS Glue Schema Registry
-
Richten Sie Ihre Amazon MSK-Umgebung ein. Informationen und Schritte finden Sie unter Einrichten von Amazon MSK und Erste Schritte mit Amazon MSK im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
-
Laden Sie die Kafka-Themenbeschreibungsdatei (d. h. ihr Schema) im JSON-Format in die AWS Glue Schema Registry hoch. Weitere Informationen finden Sie unter Integration mit AWS Glue Schema Registry im AWS Glue Entwicklerhandbuch. Beispielschemata finden Sie im folgenden Abschnitt.
Verwenden Sie das Format der Beispiele in diesem Abschnitt, wenn Sie Ihr Schema in das AWS Glue -Schema Registry hochladen.
Beispielschema für einen JSON-Typ
Im folgenden Beispiel gibt json das Schema, das in der AWS Glue Schemaregistry erstellt werden soll, den Wert für an dataFormat und verwendet datatypejson fürtopicName.
Anmerkung
Der Wert für topicName sollte die gleiche Schreibweise wie der Themenname in Kafka verwenden.
{ "topicName": "datatypejson", "message": { "dataFormat": "json", "fields": [ { "name": "intcol", "mapping": "intcol", "type": "INTEGER" }, { "name": "varcharcol", "mapping": "varcharcol", "type": "VARCHAR" }, { "name": "booleancol", "mapping": "booleancol", "type": "BOOLEAN" }, { "name": "bigintcol", "mapping": "bigintcol", "type": "BIGINT" }, { "name": "doublecol", "mapping": "doublecol", "type": "DOUBLE" }, { "name": "smallintcol", "mapping": "smallintcol", "type": "SMALLINT" }, { "name": "tinyintcol", "mapping": "tinyintcol", "type": "TINYINT" }, { "name": "datecol", "mapping": "datecol", "type": "DATE", "formatHint": "yyyy-MM-dd" }, { "name": "timestampcol", "mapping": "timestampcol", "type": "TIMESTAMP", "formatHint": "yyyy-MM-dd HH:mm:ss.SSS" } ] } }
Beispielschema für einen CSV-Typ
Im folgenden Beispiel wird das Schema, das in der AWS Glue Schemaregistry erstellt werden soll, csv als Wert für angegeben dataFormat und verwendet datatypecsvbulk fürtopicName. Der Wert für topicName sollte die gleiche Schreibweise wie der Themenname in Kafka verwenden.
{ "topicName": "datatypecsvbulk", "message": { "dataFormat": "csv", "fields": [ { "name": "intcol", "type": "INTEGER", "mapping": "0" }, { "name": "varcharcol", "type": "VARCHAR", "mapping": "1" }, { "name": "booleancol", "type": "BOOLEAN", "mapping": "2" }, { "name": "bigintcol", "type": "BIGINT", "mapping": "3" }, { "name": "doublecol", "type": "DOUBLE", "mapping": "4" }, { "name": "smallintcol", "type": "SMALLINT", "mapping": "5" }, { "name": "tinyintcol", "type": "TINYINT", "mapping": "6" }, { "name": "floatcol", "type": "DOUBLE", "mapping": "7" } ] } }
Konfigurieren der Authentifizierung für den Athena-MSK-Konnektor
Sie können verschiedene Methoden verwenden, um sich bei Ihrem Amazon-MSK-Cluster zu authentifizieren, darunter IAM, SSL, SCRAM und eigenständiges Kafka.
Die folgende Tabelle zeigt die Authentifizierungstypen für den Konnektor sowie das jeweilige Sicherheitsprotokoll und den SASL-Mechanismus. Weitere Informationen finden Sie unter Authentifizierung und Autorisierung für Apache-Kafka-APIs im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
| auth_type | security.protocol | sasl.mechanik |
|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
SASL_SSL_AWS_MSK_IAM |
SASL_SSL |
AWS_MSK_IAM |
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
SSL |
SSL |
N/A |
Anmerkung
Die SASL_SSL_PLAIN- und SASL_PLAINTEXT_PLAIN-Authentifizierungstypen werden von Apache Kafka unterstützt, jedoch nicht von Amazon MSK.
SASL/IAM
Wenn der Cluster die IAM-Authentifizierung verwendet, müssen Sie bei der Einrichtung des Clusters die IAM-Richtlinie für den Benutzer konfigurieren. Weitere Informationen finden Sie unter IAM-Zugriffskontrolle im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
Um diesen Authentifizierungstyp zu verwenden, legen Sie die auth_type-Lambda-Umgebungsvariable für den Konnektor auf SASL_SSL_AWS_MSK_IAM fest.
SSL
Wenn der Cluster SSL-authentifiziert ist, müssen Sie die Vertrauensspeicher- und Schlüsselspeicherdateien generieren und sie in den Amazon-S3-Bucket hochladen. Sie müssen diese Amazon-S3-Referenz angeben, wenn Sie den Konnektor bereitstellen. Der Schlüsselspeicher, der Vertrauensspeicher und der SSL-Schlüssel werden in der AWS Secrets Manager gespeichert. Sie geben den AWS geheimen Schlüssel an, wenn Sie den Connector bereitstellen.
Informationen zum Erstellen eines Geheimnisses im Secrets Manager finden Sie unter Erstellen eines AWS Secrets Manager -Geheimnisses.
Um diesen Authentifizierungstyp zu verwenden, legen Sie die Umgebungsvariablen wie in der folgenden Tabelle gezeigt fest.
| Parameter | Wert |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
Der Amazon-S3-Speicherort, der die Zertifikate enthält. |
secrets_manager_secret |
Der Name Ihres AWS geheimen Schlüssels. |
Nachdem Sie ein Geheimnis in Secrets Manager erstellt haben, können Sie es in der Secrets-Manager-Konsole anzeigen.
So zeigen Sie Ihr Geheimnis in Secrets Manager an
Öffnen Sie die Secrets Manager Manager-Konsole unter https://console.aws.amazon.com/secretsmanager/
. -
Wählen Sie im Navigationsbereich Secrets (Geheimnisse).
-
Wählen Sie auf der Seite Secrets (Geheimnisse) den Link zu Ihrem Geheimnis aus.
-
Wählen Sie auf der Detailseite für Ihr Geheimnis die Option Retrieve secret value (Geheimniswert abrufen).
Die folgende Abbildung zeigt ein Beispiel für einen geheimen Schlüssel mit drei key/value Paaren:
keystore_passwordtruststore_password, undssl_key_password.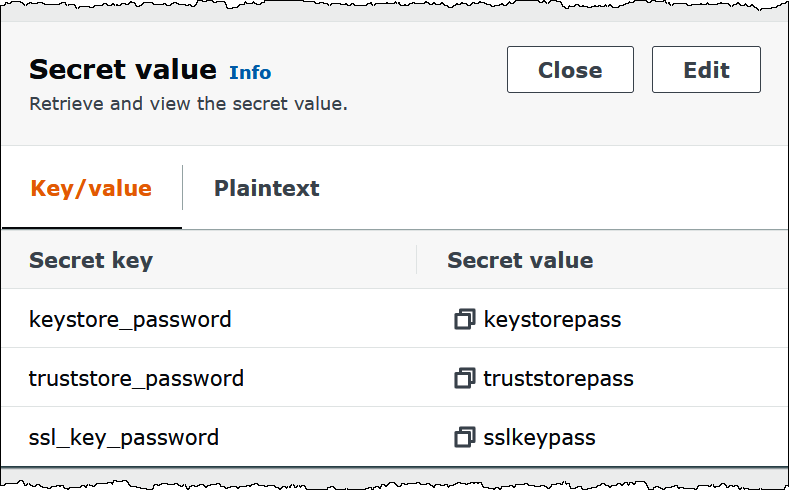
SASL/SCRAM
Wenn Ihr Cluster SCRAM-Authentifizierung verwendet, geben Sie bei der Bereitstellung des Konnektor den Secrets-Manager-Schlüssel an, der dem Cluster zugeordnet ist. Die AWS -Anmeldeinformationen des Benutzers (geheimer Schlüssel und Zugriffsschlüssel) werden für die Authentifizierung mit dem Cluster verwendet.
Legen Sie die Umgebungsvariablen wie in der folgenden Tabelle angegeben fest.
| Parameter | Wert |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
Der Name Ihres AWS geheimen Schlüssels. |
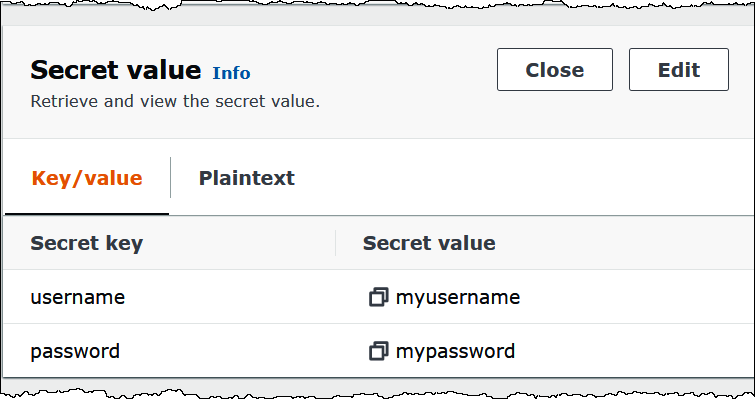
Die folgende Abbildung zeigt ein Beispiel für ein Geheimnis in der Secrets Manager Manager-Konsole mit zwei key/value Paaren: eines für username und eines fürpassword.
Lizenzinformationen
Durch die Verwendung dieses Connectors bestätigen Sie, dass Komponenten von Drittanbietern enthalten sind. Eine Liste dieser Komponenten finden Sie in der Datei pom.xml
Weitere Ressourcen
Weitere Informationen zu diesem Connector finden Sie auf der entsprechenden Website
