Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von Auto Scaling für AWS Glue
Auto Scaling ist für interaktive Sitzungsaufträge, AWS Glue-ETL- und Streaming-Aufträge ab AWS Glue Version 3.0 verfügbar.
Das Aktivieren von Auto Scaling bietet die folgenden Vorteile:
-
AWS Glue automatisches Hinzufügen und Entfernen von Workern aus dem Cluster abhängig von der Parallelität in jeder Phase oder jedemMikro-Stapel der Auftragsausführung.
-
Dadurch müssen Sie nicht experimentieren und entscheiden, wie viele Worker Sie Ihren AWS Glue-ETL-Aufträgen zuweisen möchten.
-
Bei einer vorgegebenen Worker-Anzahl wählt AWS Glue die Ressourcen in der richtigen Größe für den Workload aus.
-
Sie können sehen, wie sich die Größe des Clusters während der Jobausführung ändert, indem Sie sich die CloudWatch Metriken auf der Detailseite der Jobausführung in AWS Glue Studio ansehen.
Auto Scaling für AWS Glue-ETL- und Streaming-Aufträge ermöglicht die bedarfsgerechte Skalierung der Rechenressourcen Ihrer AWS Glue-Aufträge. Beim Hochskalieren auf Abruf können Sie nur die erforderlichen Rechenressourcen zunächst beim Start des Auftrags zuweisen und auch die erforderlichen Ressourcen je nach Bedarf während des Auftrags bereitstellen.
Auto Scaling unterstützt auch dynamisches Abskalieren der AWS Glue-Auftragsressourcen im Laufe eines Auftrags. Wenn während einer Auftragsausführung mehr Ausführer von Ihrer Spark-Anwendung angefordert werden, werden dem Cluster mehr Worker hinzugefügt. Wenn der Ausführer ohne aktive Berechnungsaufgaben im Leerlauf verblieben ist, werden der Ausführer und der zugehörige Worker entfernt.
Folgende sind Beispiele zu den häufigsten Szenarien, in denen Auto Scaling Sie bei den Kosten und der Auslastung Ihrer Spark-Anwendungen unterstützt:
-
Ein Spark-Treiber, der eine große Anzahl von Dateien in Amazon S3 auflistet oder einen Ladevorgang durchführt, während die Executors inaktiv sind.
-
Spark-Phasen laufen aufgrund von zu viel Provisioning mit nur wenigen Executors.
-
Datenverzerrungen oder ungleichmäßige Rechenanforderungen über Spark-Phasen hinweg.
Voraussetzungen
Auto Scaling ist nur für AWS Glue-Version 3.0 oder höher verfügbar. Um Auto Scaling zu verwenden, können Sie die Migrationsanleitung befolgen, um Ihre vorhandenen Aufträge auf AWS Glue-Version 3.0 oder höher zu migrieren oder neue Aufträge mit AWS Glue-Version 3.0 oder höher zu erstellen.
Auto Scaling ist für AWS Glue-Aufträge mit den Worker-Typen G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, R.8X oder G.025X (nur für Streaming-Aufträge) verfügbar. Standard DPUs werden für Auto Scaling nicht unterstützt.
Aktivieren von Auto Scaling in AWS Glue Studio
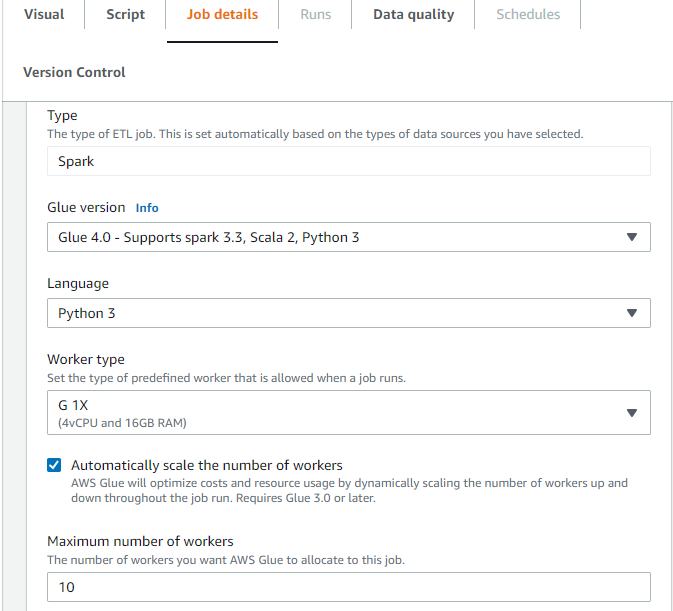
Wählen Sie auf der Registerkarte Auftragsdetails in AWS Glue Studio als Typ Spark oder Spark Streaming und als Glue-Version Glue 3.0 oder neuer aus. Anschließend wird unter Worker-Typ ein Kontrollfeld angezeigt.
-
Wählen Sie die Option Automatisches Skalieren der Worker-Anzahl aus.
-
Legen Sie die Maximale Worker-Anzahl fest, um die maximale Anzahl von Workern zu definieren, die für die Auftragsausführung ausgegeben werden können.
Auto Scaling mit der AWS CLI oder dem SDK aktivieren
Um Auto Scaling über die AWS CLI für Ihren Joblauf zu aktivieren, führen Sie start-job-run ihn mit der folgenden Konfiguration aus:
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
Wenn die ETL-Auftragsausführung abgeschlossen ist, können Sie auch get-job-run aufrufen, um die tatsächliche Ressourcennutzung der Ausführung in DPU-Sekunden zu prüfen. Hinweis: Das neue Feld DPUSecondswird nur für Ihre Batch-Jobs auf AWS Glue Version 4.0 oder höher angezeigt, die mit Auto Scaling aktiviert sind. Dieses Feld wird für Streaming-Aufträge nicht unterstützt.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
Sie können Auftragsausführungen mit Auto Scaling auch über das AWS Glue -SDK konfigurieren. Die Konfiguration ist dieselbe.
Aktivieren von Auto Scaling mit interaktiven Sitzungen
Informationen zur Aktivierung von Auto Scaling beim Erstellen von AWS Glue Jobs mit interaktiven Sitzungen finden Sie unter AWS Glue Interaktive Sitzungen konfigurieren.
Tipps und Überlegungen
Tipps und Überlegungen zur Feinabstimmung von AWS Glue Auto Scaling:
-
Falls Sie keine Vorstellung vom Anfangswert der maximalen Anzahl von Arbeitern haben, können Sie mit der groben Berechnung beginnen, die in Estimate AWS Glue DPU erklärt wird. Sie sollten für Daten mit sehr geringem Volumen keinen extrem hohen Wert für die maximale Anzahl von Workern konfigurieren.
-
AWS Glue Auto Scaling konfiguriert
spark.sql.shuffle.partitionsundspark.default.parallelismbasiert auf der maximalen Anzahl von DPU (berechnet mit der maximalen Anzahl von Arbeitern und dem Workertyp), die für den Job konfiguriert sind. Falls Sie bei diesen Konfigurationen den festen Wert bevorzugen, können Sie diese Parameter mit den folgenden Auftragsparametern überschreiben:-
Schlüssel:
--conf -
Value (Wert):
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
Bei Streaming-Jobs erfolgt standardmäßig AWS Glue keine auto Skalierung innerhalb von Mikrobatches und es sind mehrere Mikrobatches erforderlich, um die auto Skalierung zu starten. Falls Sie Auto Scaling innerhalb von Mikrobatches aktivieren möchten, geben Sie
--auto-scale-within-microbatchan. Weitere Informationen finden Sie unter Auftragsparameter-Referenz.
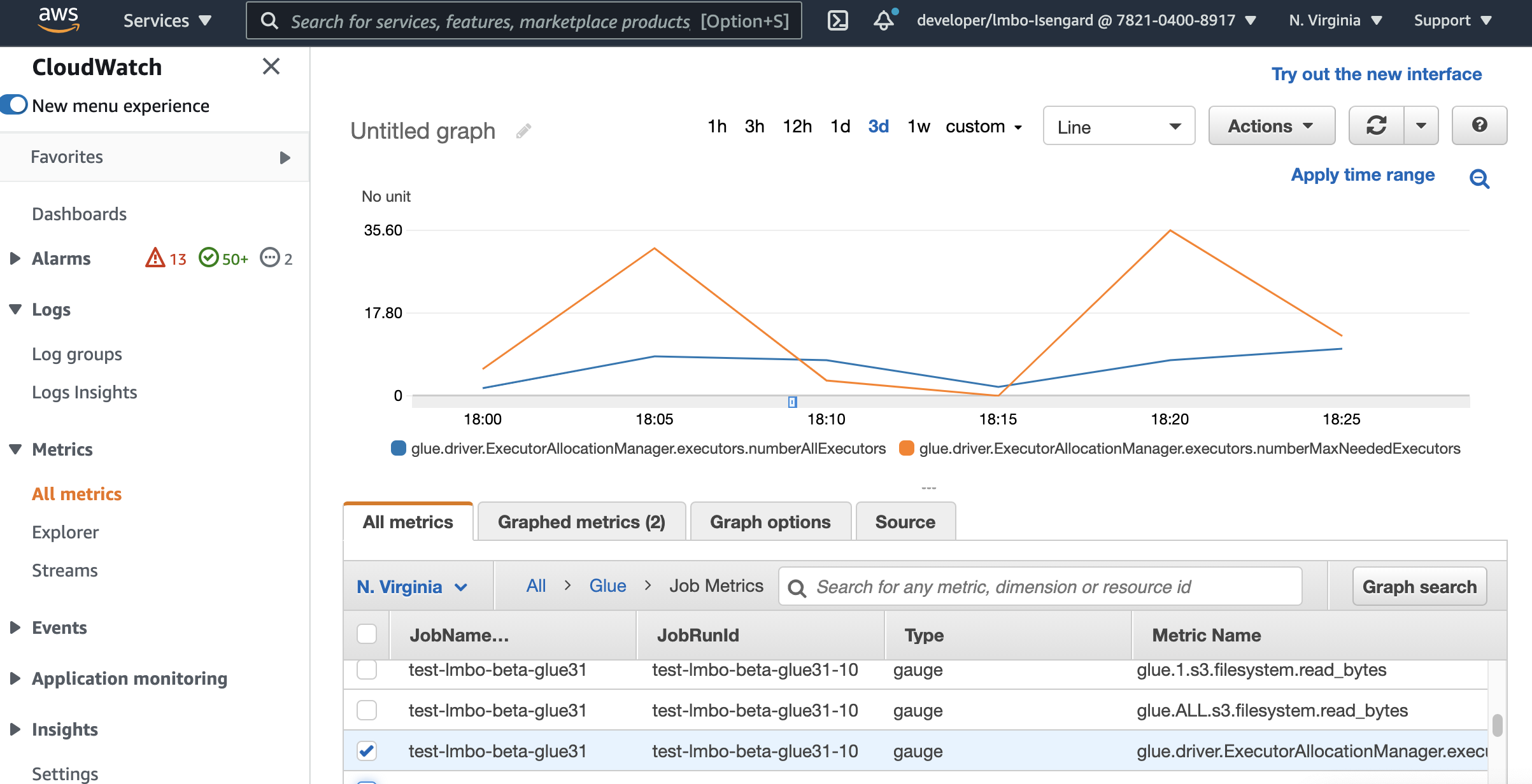
Überwachung von Auto Scaling mit CloudWatch Amazon-Metriken
Die CloudWatch Executor-Metriken sind für Ihre Jobs der AWS Glue Version 3.0 oder höher verfügbar, wenn Sie Auto Scaling aktivieren. Die Metriken können verwendet werden, um die Nachfrage und die optimierte Nutzung von Ausführern in ihren Spark-Anwendungen, die mit Auto Scaling aktiviert sind, zu überwachen. Weitere Informationen finden Sie unter Überwachung AWS Glue anhand von CloudWatch Amazon-Metriken.
Sie können auch AWS Glue Observability-Metriken verwenden, um Einblicke in die Ressourcennutzung zu erhalten. Durch die Überwachung von glue.driver.workerUtilization können Sie beispielsweise überwachen, wie viele Ressourcen mit und ohne Auto Scaling tatsächlich genutzt wurden. Ein anderes Beispiel: Durch die Überwachung von glue.driver.skewness.job und glue.driver.skewness.stage können Sie sehen, wie die Daten verzerrt sind. Diese Erkenntnisse helfen Ihnen bei der Entscheidung, Auto Scaling zu aktivieren und die Konfigurationen zu optimieren. Weitere Informationen finden Sie unter Überwachung mitÜberwachung mit AWS Glue-Beobachtbarkeitsmetriken.
-
glue.driver. ExecutorAllocationManager. Testamentsvollstrecker. numberAllExecutors
-
Klebertreiber. ExecutorAllocationManager. Testamentsvollstrecker. numberMaxNeededTestamentsvollstrecker
Weitere Informationen zu diesen Metriken finden Sie unter Überwachung für die DPU-Kapazitätsplanung.
Anmerkung
CloudWatch Executor-Metriken sind für interaktive Sitzungen nicht verfügbar.
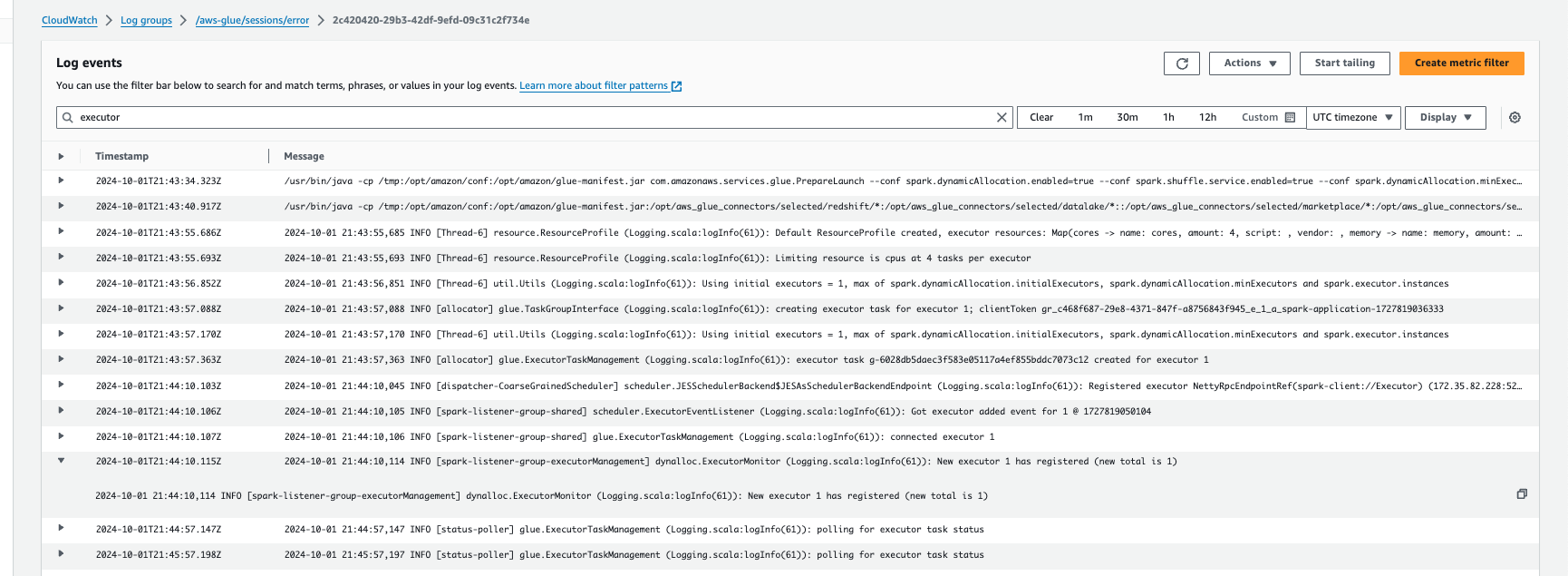
Überwachung von Auto Scaling mit Amazon CloudWatch Logs
Wenn Sie interaktive Sitzungen verwenden, können Sie die Anzahl der Executors überwachen, indem Sie kontinuierlich Amazon CloudWatch Logs aktivieren und in den Protokollen nach „Executor“ suchen, oder indem Sie die Spark-Benutzeroberfläche verwenden. Verwenden Sie dazu die %%configure-Magics, um die kontinuierliche Protokollierung zusammen mit enable auto scaling zu aktivieren.
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
Suchen Sie in den Amazon CloudWatch Logs-Ereignissen in den Protokollen nach „Executor“:
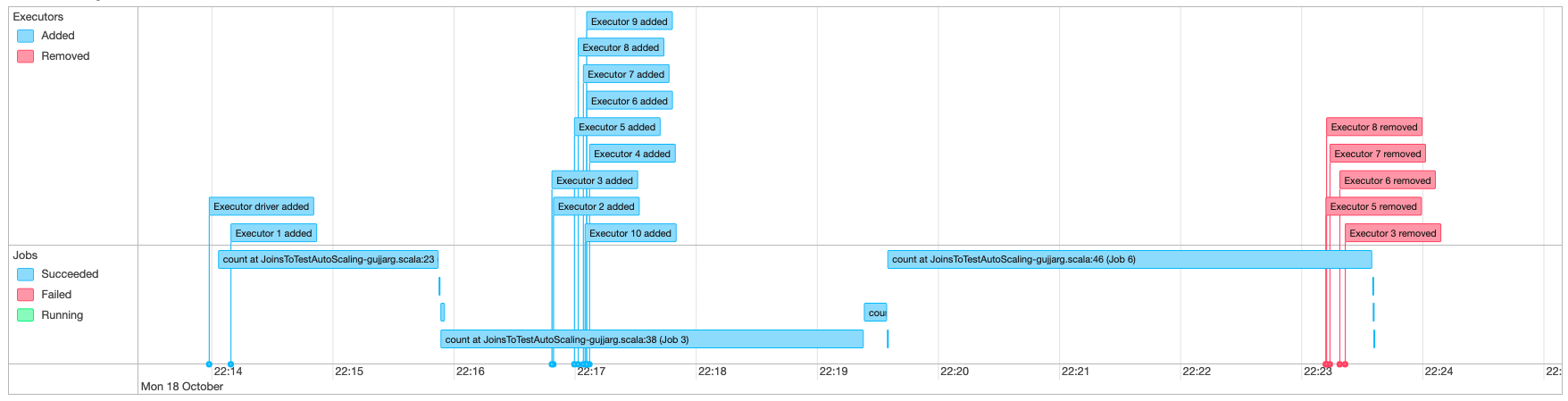
Überwachen von Auto Scaling mit der Spark-Benutzeroberfläche
Wenn Auto Scaling aktiviert ist, können Sie auch die hinzugefügten und entfernten Executors mit dynamischer Hochskalierung und Herunterskalierung basierend auf der Nachfrage in Ihren AWS Glue-Aufträgen mithilfe der Glue-Spark-Benutzeroberfläche überwachen. Weitere Informationen finden Sie unter Aktivieren der Apache-Spark-Webbenutzeroberfläche für AWS Glue-Aufgaben.
Wenn Sie interaktive Sitzungen von Jupyter Notebook aus verwenden, können Sie die folgende Magic ausführen, um Auto Scaling zusammen mit der Spark-Benutzeroberfläche zu aktivieren:
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
Überwachen der DPU-Nutzung bei der Auto-Scaling-Auftragsausführung
Sie können die Ansicht AWS Glue Studio -Auftragsausführung verwenden, um die DPU-Nutzung Ihrer Auto-Scaling-Aufträge zu überprüfen.
-
Wählen Sie im AWS Glue Studio Navigationsbereich die Option Monitoring aus. Die Seite „Monitoring“ (Überwachung) wird angezeigt.
-
Scrollen Sie nach unten zur Tabelle „Job runs“ (Auftragsausführungen).
-
Navigieren Sie zur gewünschten Auftragsausführung und scrollen Sie zur Spalte „DPU hours“ (DPU-Stunden), um die Nutzungswerte für die entsprechende Ausführung zu prüfen.
Einschränkungen
AWS GlueStreaming Auto Scaling unterstützt derzeit keinen DataFrame Streaming-Join mit einer außerhalb von DataFrame erstellten StatikForEachBatch. Eine innerhalb DataFrame von erstellte Statik ForEachBatch funktioniert erwartungsgemäß.
