Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren Sie Apache Spark-Programme zu AWS Glue
Apache Spark ist eine Open-Source-Plattform für verteilte Rechenlasten, die für große Datenmengen ausgeführt werden. AWS Glue nutzt die Fähigkeiten von Spark, um ein optimiertes ETL-Erlebnis zu bieten. Sie können Spark-Programme zu migrieren AWS Glue , um unsere Funktionen zu nutzen. AWS Glue bietet dieselben Leistungsverbesserungen, die Sie von Apache Spark auf Amazon EMR erwarten würden.
Spark-Code ausführen
Nativer Spark-Code kann standardmäßig in einer AWS Glue Umgebung ausgeführt werden. Skripte werden oft entwickelt, indem ein Teil des Codes iterativ geändert wird, ein Workflow, der für eine interaktive Sitzung geeignet ist. Bestehender Code eignet sich jedoch besser für die Ausführung in einem AWS Glue Job, sodass Sie Protokolle und Metriken für jeden Skriptlauf planen und konsistent abrufen können. Sie können ein vorhandenes Skript über die Konsole hochladen und bearbeiten.
-
Eignen Sie sich die Quelle Ihres Skripts an. In diesem Beispiel verwenden Sie ein Beispielskript aus dem Apache Spark-Repository. Binarizer-Beispiel
-
Erweitern Sie in der AWS Glue Konsole den linken Navigationsbereich und wählen Sie ETL > Jobs
Wählen Sie im Feld Erstellen von Aufträgen Spark-Script-Editor aus. Es wird ein Optionen-Abschnitt erscheinen. Wählen Sie unter Optionen Upload und Bearbeiten eines vorhandenes Skripts aus.
Es wird ein Datei-Upload-Abschnitt erscheinen. Klicken Sie unter Datei-Upload auf Datei auswählen. Ihre Systemdateiauswahl wird erscheinen. Navigieren Sie zu dem Speicherort, an dem Sie
binarizer_example.pygespeichert haben, wählen Sie es aus und bestätigen Sie Ihre Auswahl.Eine Schaltfläche für Erstellen wird in der Kopfzeile des Fensters Erstellen von Aufträgen erscheinen. Klicken Sie darauf.
-
Ihr Browser navigiert zum Skript-Editor. Klicken Sie in der Kopfzeile auf die Registerkarte Auftragsdetails. Legen Sie den Namen und die IAM-Rolle fest. Anleitungen zu AWS Glue IAM-Rollen finden Einrichten von IAM-Berechtigungen für AWS Glue Sie unter.
Optional – setzen Sie Angeforderte Anzahl der Worker auf
2und die Anzahl der Wiederholungen auf1. Diese Optionen sind nützlich, wenn Sie Produktionsaufträge ausführen, aber wenn Sie sie ablehnen, optimieren Sie Ihre Erfahrung beim Testen eines Features.Klicken Sie in der Titelleiste auf Save (Speichern) und dann auf Run (Ausführen)
-
Navigieren Sie zur Registerkarte Ausführungen. Sie sehen ein Panel, das Ihrer Auftragsausführung entspricht. Warten Sie ein paar Minuten und die Seite sollte automatisch aktualisiert werden um Erfolgreich im Run status (Ausführungsstatus) anzuzeigen.
-
Sie sollten Ihre Ausgabe überprüfen, um sicherzustellen, dass das Spark-Skript wie beabsichtigt ausgeführt wurde. Dieses Apache Spark-Beispielskript sollte einen String in den Ausgabestream schreiben. Sie finden das, indem Sie zu Output logs (Ausgabeprotokolle) unter Cloudwatch-Protokolle im Panel für die erfolgreiche Auftragsausführung navigieren. Notieren Sie sich die Auftragsausführungs-ID, eine generierte ID unter dem ID-Label, das mit
jr_beginnt.Dadurch wird die CloudWatch Konsole geöffnet, die so eingestellt ist, dass sie den Inhalt der AWS Glue Standard-Protokollgruppe visualisiert
/aws-glue/jobs/output, gefiltert nach dem Inhalt der Protokollstreams für die Job-Ausführungs-ID. Jeder Worker hat einen Protokollstream generiert, der als Zeilen unter Protokollstreams dargestellt wird. Ein Worker hätte den angeforderten Code ausführen sollen. Sie müssen alle Protokollstream öffnen, um den richtigen Worker zu identifizieren. Sobald Sie den richtigen Worker gefunden haben, sollten Sie die Ausgabe des Skripts sehen, wie in der folgenden Abbildung zu sehen ist: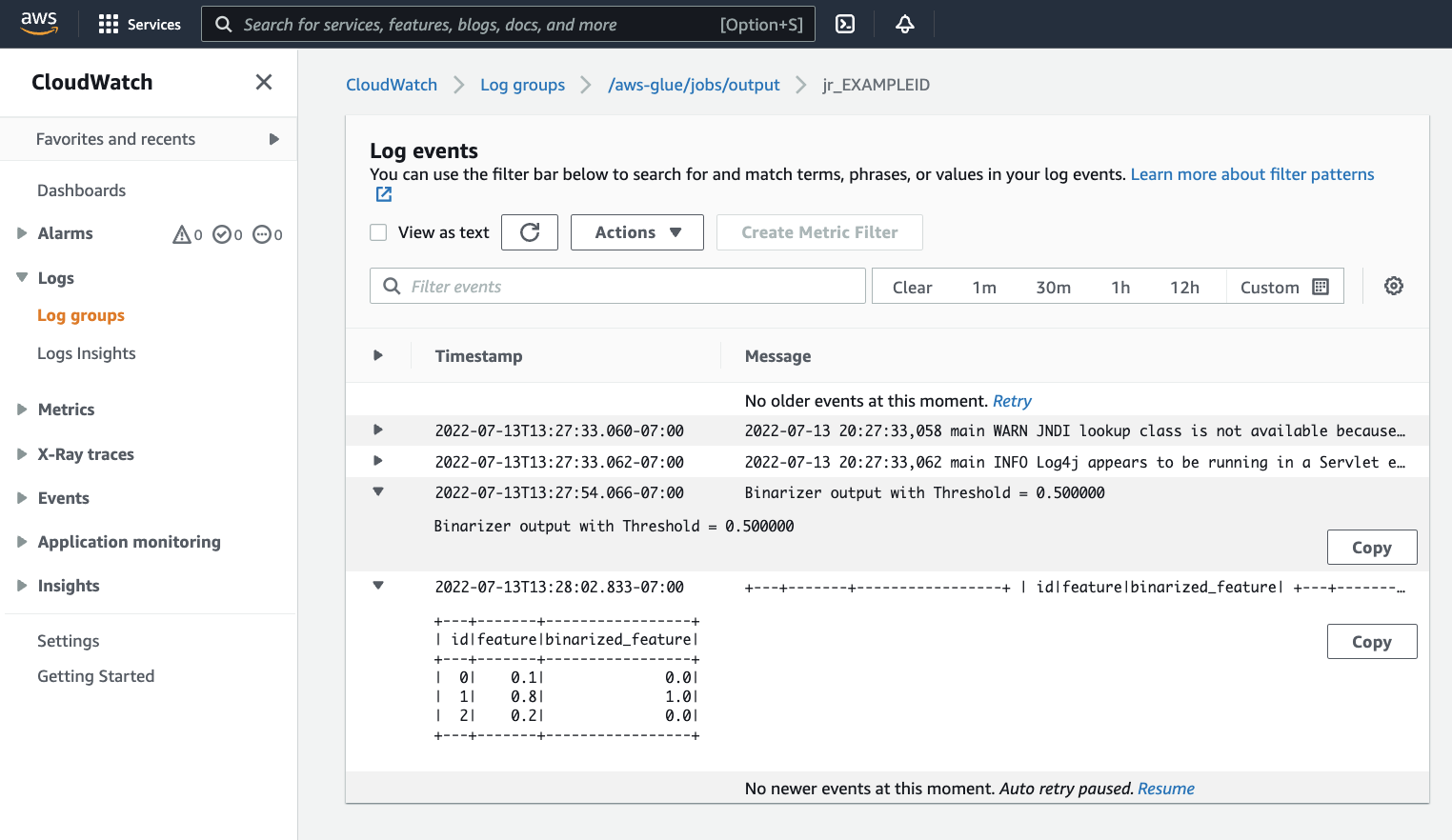
Gängige Verfahren für die Migration von Spark-Programmen
Bewerten Sie den Support der Spark-Version
AWS Glue Release-Versionen definieren die Version von Apache Spark und Python, die für den AWS Glue Job verfügbar sind. Sie finden unsere AWS Glue Versionen und was sie unterstützen unterAWS Glue Versionen. Möglicherweise müssen Sie Ihr Spark-Programm aktualisieren, um mit einer neueren Version von Spark kompatibel zu sein, um auf bestimmte AWS Glue -Features zuzugreifen.
Bibliotheken von Drittanbietern einschließen
Viele bestehende Spark-Programme werden Abhängigkeiten haben, sowohl von privaten als auch von öffentlichen Artefakten. AWS Glue unterstützt Abhängigkeiten im JAR-Stil für Scala-Aufträge sowie Wheel- und Quell-Pure-Python-Abhängigkeiten für Python-Aufträge.
Python – Hinweise zu Python-Abhängigkeiten finden Sie unter Python-Bibliotheken mit AWS Glue verwenden
Allgemeine Python-Abhängigkeiten werden in der AWS Glue Umgebung bereitgestellt, einschließlich der häufig angeforderten Pandas-Bibliothek--additional-python-modules verwenden. Informationen über Auftragsargumente finden Sie in Verwenden von Auftragsparametern in AWS Glue-Jobs.
Sie können zusätzliche Python-Abhängigkeiten mit dem --extra-py-files-Auftragsargument liefern. Wenn Sie einen Job aus einem Spark-Programm migrieren, ist dieser Parameter eine gute Option, da er funktionell dem --py-files Flag in PySpark entspricht und denselben Einschränkungen unterliegt. Weitere Informationen zum Parameter --extra-py-files erhalten Sie unter Einschließlich Python-Dateien mit PySpark nativen Funktionen.
Für neue Jobs können Sie Python-Abhängigkeiten mit dem --additional-python-modules-Auftragsargument verwalten. Die Verwendung dieses Arguments ermöglicht ein gründlicheres Abhängigkeitsmanagement. Dieser Parameter unterstützt Abhängigkeiten im Wheel-Stil, einschließlich solcher mit nativen Codebindungen, die mit Amazon Linux 2 kompatibel sind.
Scala
Sie können zusätzliche Scala-Abhängigkeiten mit dem --extra-jars-Auftragsargument liefern. Abhängigkeiten müssen in Amazon S3 gehostet werden und der Argumentwert sollte eine kommagetrennte Liste von Amazon S3-Pfaden ohne Leerzeichen sein. Möglicherweise fällt es Ihnen leichter, Ihre Konfiguration zu verwalten, indem Sie Ihre Abhängigkeiten neu bündeln, bevor Sie sie hosten und konfigurieren. AWS Glue JAR-Abhängigkeiten enthalten Java-Bytecode, der aus jeder JVM-Sprache generiert werden kann. Sie können andere JVM-Sprachen wie Java verwenden, um benutzerdefinierte Abhängigkeiten zu schreiben.
Anmeldeinformationen für Datenquellen verwalten
Bestehende Spark-Programme können mit einer komplexen oder benutzerdefinierten Konfiguration ausgestattet sein, um Daten aus ihren Datenquellen abzurufen. Gängige Authentifizierungsabläufe für Datenquellen werden von Verbindungen unterstützt. AWS Glue Weitere Informationen zu AWS Glue -Verbindungen finden Sie unter Herstellen einer Verbindung zu Daten.
AWS Glue Verbindungen ermöglichen es, Ihren Job auf zwei Arten von Datenspeichern mit einer Vielzahl von Arten von Datenspeichern zu verbinden: durch Methodenaufrufe an unsere Bibliotheken und durch das Einrichten der zusätzlichen Netzwerkverbindung in der AWS Konsole. Sie können das AWS SDK auch von Ihrem Job aus aufrufen, um Informationen aus einer Verbindung abzurufen.
Methodenaufrufe — AWS Glue Verbindungen sind eng in den AWS Glue
Datenkatalog integriert, einen Dienst, der es Ihnen ermöglicht, Informationen über Ihre Datensätze zu kuratieren, und die verfügbaren Methoden zur Interaktion mit AWS Glue Verbindungen spiegeln dies wider. Wenn Sie über eine bestehende Authentifizierungskonfiguration verfügen, die Sie für JDBC-Verbindungen wiederverwenden möchten, können Sie auf Ihre AWS Glue Verbindungskonfiguration über die Methode auf der zugreifen. extract_jdbc_conf GlueContext Weitere Informationen finden Sie unter extract_jdbc_conf.
Konsolenkonfiguration — AWS Glue Jobs verwenden zugehörige AWS Glue Verbindungen, um Verbindungen zu Amazon VPC-Subnetzen zu konfigurieren. Wenn Sie Ihre Sicherheitsmaterialien direkt verwalten, müssen Sie in der AWS Konsole möglicherweise den NETWORK Typ Zusätzliche Netzwerkverbindung angeben, um das Routing zu konfigurieren. Weitere Informationen über die AWS Glue
-Verbindungs-API finden Sie unter Verbindungs-API
Wenn Ihre Spark-Programme über einen benutzerdefinierten oder ungewöhnlichen Authentifizierungsablauf verfügen, müssen Sie Ihre Sicherheitsmaterialien möglicherweise praxisnah verwalten. Wenn AWS Glue Verbindungen nicht gut zu passen scheinen, können Sie Sicherheitsmaterialien sicher in Secrets Manager hosten und über das Boto3 oder AWS SDK, die im Job bereitgestellt werden, darauf zugreifen.
Konfigurieren von Apache Spark
Komplexe Migrationen ändern häufig die Spark-Konfiguration, um ihre Workloads zu berücksichtigen. Moderne Versionen von Apache Spark ermöglichen die Einstellung der Laufzeitkonfiguration mit dem. SparkSession AWS Glue Es werden Jobs über 3.0 bereitgestelltSparkSession, die geändert werden können, um die Laufzeitkonfiguration festzulegen. Apache Sparkkonfiguration
Erstellen einer benutzerdefinierten Konfiguration
Migrierte Spark-Programme können so konzipiert sein, dass sie eine benutzerdefinierte Konfiguration erfordern. AWS Glue ermöglicht es, die Konfiguration über die Job-Argumente auf Job- und Job-Ausführungsebene festzulegen. Informationen über Auftragsargumente finden Sie in Verwenden von Auftragsparametern in AWS Glue-Jobs. Sie können über unsere Bibliotheken auf Job-Argumente im Kontext eines Jobs zugreifen. AWS Glue bietet eine Hilfsfunktion, um eine konsistente Ansicht zwischen den Argumenten, die im Job gesetzt wurden, und den Argumenten, die während der Jobausführung gesetzt wurden, bereitzustellen. Siehe Zugriff auf Parameter mit getResolvedOptions in Python und AWS GlueScala GlueArgParser APIs in Scala.
Migration von Java-Code
Wie in Bibliotheken von Drittanbietern einschließen erklärt, können Ihre Abhängigkeiten Klassen enthalten, die von JVM-Sprachen wie Java oder Scala generiert wurden. Ihre Abhängigkeiten können eine main-Methode einschließen. Sie können eine main Methode in einer Abhängigkeit als Einstiegspunkt für einen AWS Glue Scala-Job verwenden. Auf diese Weise können Sie Ihre main-Methode in Java schreiben oder eine main-Methode auf Ihre eigenen Bibliotheksstandards gepackt wiederverwenden.
Um eine main-Methode aus einer Abhängigkeit zu verwenden, führen Sie Folgendes aus: Löschen Sie den Inhalt des Bearbeitungsbereichs, indem Sie das standardmäßige GlueApp-Objekt angeben. Geben Sie den vollqualifizierten Namen einer Klasse in einer Abhängigkeit als Auftragsargument mit dem Schlüssel --class an. Sie sollten nun einen Auftragsausführung auslösen können.
Sie können die Reihenfolge oder Struktur der AWS Glue Argumentübergaben an die Methode nicht konfigurieren. main Wenn Ihr vorhandener Code die eingestellte Konfiguration lesen muss AWS Glue, führt dies wahrscheinlich zu einer Inkompatibilität mit dem vorherigen Code. Wenn Sie getResolvedOptions verwenden, haben Sie ebenso keinen guten Ort, um diese Methode aufzurufen. Erwägen Sie, Ihre Abhängigkeit direkt von einer Hauptmethode aufzurufen, die von AWS Glue generiert wird. Das folgende AWS Glue ETL-Skript zeigt ein Beispiel dafür.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
