Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entwerfen von Lambda-Anwendungen
Eine gut konzipierte ereignisgesteuerte Anwendung verwendet eine Kombination aus AWS Diensten und benutzerdefiniertem Code, um Anfragen und Daten zu verarbeiten und zu verwalten. Dieses Kapitel konzentriert sich auf Lambda-specific Themen des Anwendungsdesigns. Bei der Entwicklung von Anwendungen für stark frequentierte Produktionssysteme gibt es viele wichtige Überlegungen für Serverless-Architekten.
Viele der bewährten Verfahren, die für die Softwareentwicklung und verteilte Systeme gelten, gelten auch für die Entwicklung Serverless-Anwendungen. Das übergeordnete Ziel besteht darin, Workloads zu entwickeln, die:
-
zuverlässig sind: Sie bieten Ihren Endnutzern ein hohes Maß an Verfügbarkeit. AWS -Serverless-Dienste sind zuverlässig, weil sie auch für Ausfälle ausgelegt sind.
-
langlebig sind: Sie bieten Speicheroptionen, die den Anforderungen an die Haltbarkeit Ihrer Workloads gerecht werden.
-
sicher sind: Befolgen Sie bewährte Verfahren und verwenden Sie die bereitgestellten Tools, um den Zugriff auf Workloads zu sichern und den Explosionsradius zu begrenzen.
-
leistungsstark sind: effiziente Nutzung von Rechenressourcen und Erfüllung der Leistungsanforderungen Ihrer Endbenutzer.
-
Cost-efficient— Entwicklung von Architekturen, die unnötige Kosten vermeiden, die ohne Mehrausgaben skaliert werden können und die auch ohne nennenswerten Mehraufwand außer Betrieb genommen werden können.
Die folgenden Designprinzipien können Ihnen dabei helfen, Workloads zu erstellen, die diese Ziele erfüllen. Nicht jedes Prinzip lässt sich auf jede Architektur anwenden, aber sie sollten Ihnen bei allgemeinen Architekturentscheidungen als Leitfaden dienen.
Themen
Verwendung von Diensten anstelle von benutzerdefiniertem Code
Serverlose Anwendungen bestehen normalerweise aus mehreren AWS Diensten, die mit benutzerdefiniertem Code integriert sind, der in Lambda-Funktionen ausgeführt wird. Lambda kann zwar in die meisten AWS Dienste integriert werden, aber die Dienste, die in serverlosen Anwendungen am häufigsten verwendet werden, sind:
| Kategorie | AWS Dienst |
|---|---|
|
Datenverarbeitung |
AWS Lambda |
|
Datenspeicher |
Amazon S3 Amazon DynamoDB Amazon RDS |
|
API |
Amazon API Gateway |
|
Integration von Anwendungen |
Amazon EventBridge Amazon SNS Amazon SQS |
|
Orchestrierung |
Langlebige Lambda-Funktionen AWS Step Functions |
|
Streaming-Daten und Analysen |
Amazon Data Firehose |
Anmerkung
Viele Serverless-Dienste bieten Replikation und Support für mehrere Regionen, einschließlich DynamoDB und Amazon S3. Lambda-Funktionen können als Teil einer Bereitstellungspipeline in mehreren Regionen bereitgestellt werden und API Gateway kann so konfiguriert werden, dass es diese Konfiguration unterstützt. Sehen Sie sich diese Beispielarchitektur
Es gibt viele etablierte, gängige Muster in verteilten Architekturen, die Sie selbst erstellen oder mithilfe von Diensten implementieren können. AWS Für die meisten Kunden ist es wirtschaftlich nicht sinnvoll, Zeit in die Entwicklung dieser Muster zu investieren. Wenn Ihre Anwendung eines dieser Muster benötigt, verwenden Sie den entsprechenden AWS Dienst:
| Muster | AWS Dienst |
|---|---|
|
Warteschlange |
Amazon SQS |
|
Ereignisbus |
Amazon EventBridge |
|
Publish/subscribe (Fanout) |
Amazon SNS |
|
Orchestrierung |
Langlebige Lambda-Funktionen AWS Step Functions |
|
API |
Amazon API Gateway |
|
Ereignis-Streams |
Amazon Kinesis |
Diese Dienste sind für die Integration mit Lambda konzipiert und Sie können Infrastructure as Code (IaC) verwenden, um Ressourcen in den Diensten zu erstellen und zu verwerfen. Sie können jeden dieser Dienste über das AWS SDK
Informationen zu Lambda-Abstraktionsebenen
Der Lambda-Dienst beschränkt Ihren Zugriff auf die zugrunde liegenden Betriebssysteme, Hypervisoren und Hardware, auf denen Ihre Lambda-Funktionen ausgeführt werden. Der Dienst wird ständig verbessert und die Infrastruktur verändert, um neue Features hinzuzufügen, die Kosten zu senken und den Dienst leistungsfähiger zu machen. Ihr Code sollte kein Wissen darüber voraussetzen, wie Lambda aufgebaut ist und keine Hardware-Affinität voraussetzen.
In ähnlicher Weise werden die Integrationen von Lambda mit anderen Diensten von verwaltet AWS, sodass Ihnen nur eine geringe Anzahl von Konfigurationsoptionen zur Verfügung steht. Bei der Interaktion zwischen API Gateway und Lambda gibt es beispielsweise kein Konzept für den Load Balancer, da dieser vollständig von den Diensten verwaltet wird. Sie haben auch keine direkte Kontrolle darüber, welche Verfügbarkeitszonen
Diese Abstraktion ermöglicht es Ihnen, sich auf die Integrationsaspekte Ihrer Anwendung, den Datenfluss und die Geschäftslogik zu konzentrieren, bei denen Ihr Workload einen Mehrwert für Ihre Endbenutzer bietet. Wenn Sie den Diensten die Verwaltung der zugrundeliegenden Mechanismen überlassen, können Sie Anwendungen schneller entwickeln und müssen weniger eigenen Code pflegen.
Implementieren der Zustandslosigkeit in Funktionen
Bei Standard-Lambda-Funktionen sollten Sie davon ausgehen, dass die Umgebung nur für einen einzigen Aufruf existiert. Die Funktion sollte beim ersten Start alle erforderlichen Zustände initialisieren. Beispielsweise kann Ihre Funktion das Abrufen von Daten aus einer DynamoDB-Tabelle erfordern. Sie sollte alle dauerhaften Datenänderungen vor dem Beenden in einem dauerhaften Speicher wie Amazon S3, DynamoDB oder Amazon SQS speichern. Sie sollte sich nicht auf bestehende Datenstrukturen oder temporäre Dateien oder auf interne Zustände stützen, die bei mehreren Aufrufen verwaltet würden.
Um Datenbankverbindungen und Bibliotheken zu initialisieren oder den Status zu laden, können Sie die statische Initialisierung nutzen. Da Ausführungsumgebungen nach Möglichkeit wiederverwendet werden, um die Leistung zu verbessern, können Sie die für die Initialisierung dieser Ressourcen benötigte Zeit über mehrere Aufrufe hinweg amortisieren. Sie sollten jedoch keine Variablen oder Daten, die in der Funktion verwendet werden, in diesem globalen Bereich speichern.
Kopplung minimieren
Die meisten Architekturen sollten viele, kürzere Funktionen den wenigen, größeren vorziehen. Der Zweck jeder Funktion sollte darin bestehen, das an die Funktion übergebene Ereignis zu verarbeiten, ohne Kenntnisse oder Erwartungen in Bezug auf den gesamten Arbeitsablauf oder das Transaktionsvolumen. Dadurch ist die Funktion unabhängig von der Quelle des Ereignisses und nur minimal mit anderen Diensten verbunden.
Alle Konstanten mit globalem Geltungsbereich, die sich nur selten ändern, sollten als Umgebungsvariablen implementiert werden, um Aktualisierungen ohne Bereitstellungen zu ermöglichen. Alle Geheimnisse oder sensiblen Informationen sollten im AWS Systems Manager Parameter Store oder AWS Secrets Manager
Entwickeln für On-Demand-Daten statt Batches
Viele herkömmliche Systeme sind so konzipiert, dass sie periodisch laufen und Batch von Transaktionen verarbeiten, die sich im Laufe der Zeit angesammelt haben. So kann beispielsweise eine Bankanwendung stündlich laufen, um die Transaktionen von Geldautomaten in einem zentralen Hauptbuch zu verarbeiten. In Lambda-based Anwendungen sollte die benutzerdefinierte Verarbeitung durch jedes Ereignis ausgelöst werden, sodass der Dienst die Parallelität nach Bedarf skalieren kann, sodass Transaktionen nahezu in Echtzeit verarbeitet werden können.
Während Standard-Lambda-Funktionen auf eine Ausführungszeit von 15 Minuten begrenzt sind, können Durable Functions bis zu einem Jahr lang ausgeführt werden, sodass sie für länger andauernde Verarbeitungsanforderungen geeignet sind. Dennoch sollten Sie, wenn möglich, die ereignisgesteuerte Verarbeitung der Stapelverarbeitung vorziehen.
Sie können Cron-Aufgaben
So ist es beispielsweise keine optimale Vorgehensweise, einen Batch-Prozess zu verwenden, der eine Lambda-Funktion auslöst, um eine Liste neuer Amazon-S3-Objekte abzurufen. Dies liegt daran, dass der Dienst zwischen den Batches möglicherweise mehr neue Objekte erhält, als innerhalb einer 15-minütigen Lambda-Funktion verarbeitet werden können.
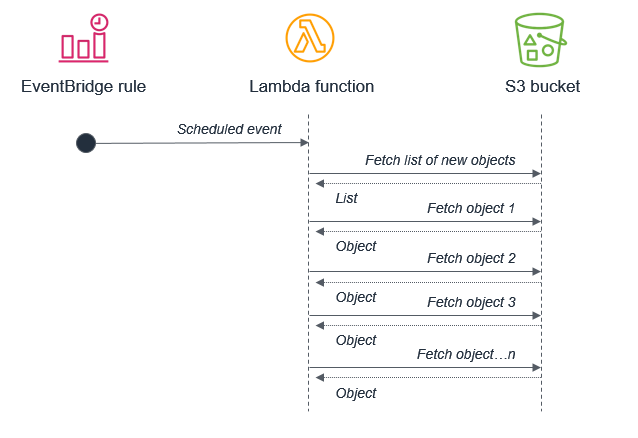
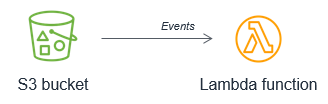
Stattdessen sollte Amazon S3 die Lambda-Funktion jedes Mal aufrufen, wenn ein neues Objekt in den Bucket gestellt wird. Dieser Ansatz ist deutlich skalierbarer und funktioniert nahezu in Echtzeit.
Wählen Sie eine Orchestrierungsoption für komplexe Workflows
Workflows, die Verzweigungslogik, verschiedene Arten von Fehlermodellen und Wiederholungslogik beinhalten, verwenden in der Regel einen Orchestrator, um den Status der Gesamtausführung zu verfolgen. Erstellen Sie keine Ad-hoc-Orchestrierung in standardmäßigen Lambda-Funktionen. Dies führt zu einer engen Kopplung, komplexem Routing-Code und keiner automatischen Statuswiederherstellung.
Verwenden Sie stattdessen eine dieser speziell entwickelten Orchestrierungsoptionen:
-
Dauerhafte Lambda-Funktionen: Application-centric Orchestrierung mithilfe von Standardprogrammiersprachen mit automatischem Checkpointing, integriertem Wiederholungsversuch und Ausführungswiederherstellung. Ideal für Entwickler, die es vorziehen, die Workflow-Logik im Code neben der Geschäftslogik in Lambda beizubehalten.
-
AWS Step Functions: Visuelle Workflow-Orchestrierung mit nativen Integrationen für mehr als 220 Dienste. AWS Ideal für die Koordination mehrerer Dienste, eine wartungsfreie Infrastruktur und ein visuelles Workflow-Design.
Anleitungen zur Auswahl zwischen diesen Optionen finden Sie unter Dauerhafte Funktionen oder Step Functions.
Mit Step Functions
Es ist üblich, dass einfachere Workflows in Lambda-Funktionen mit der Zeit komplexer werden. Beim Betrieb einer serverlosen Produktionsanwendung ist es wichtig, zu ermitteln, wann dies der Fall ist, damit Sie diese Logik auf eine Zustandsmaschine oder eine dauerhafte Funktion migrieren können.
Implementieren von Idempotenz
AWS Serverlose Dienste, einschließlich Lambda, sind fehlertolerant und für den Umgang mit Ausfällen konzipiert. Wenn beispielsweise ein Dienst eine Lambda-Funktion aufruft und es zu einer Dienstunterbrechung kommt, ruft Lambda Ihre Funktion in einer anderen Verfügbarkeitszone auf. Wenn Ihre Funktion einen Fehler auslöst, wiederholt Lambda den Aufruf.
Da ein und dasselbe Ereignis mehr als einmal eintreten kann, sollten die Funktionen idempotent
Sie können Idempotenz in Lambda-Funktionen implementieren, indem Sie eine DynamoDB-Tabelle verwenden, um kürzlich verarbeitete Bezeichner zu verfolgen und festzustellen, ob die Transaktion bereits zuvor bearbeitet wurde. Die DynamoDB-Tabelle implementiert in der Regel einen TTL-Wert (Time To Live) für ablaufende Elemente, um den verwendeten Speicherplatz zu begrenzen.
Verwenden Sie mehrere AWS Konten für die Verwaltung von Kontingenten
Viele Servicekontingente AWS werden auf Kontoebene festgelegt. Das bedeutet, dass Sie bei zunehmendem Workload schnell an Ihre Grenzen stoßen können.
Eine effektive Möglichkeit, dieses Problem zu lösen, besteht darin, mehrere AWS Konten zu verwenden und jede Arbeitslast einem eigenen Konto zuzuweisen. Dadurch wird verhindert, dass Kontingente mit anderen Workloads oder Ressourcen außerhalb der Produktion geteilt werden.
Mithilfe von AWS -Organisationen
Ein gängiger Ansatz besteht darin, jedem Entwickler ein AWS Konto zur Verfügung zu stellen und dann separate Konten für die Betabereitstellungsphase und die Produktion zu verwenden:
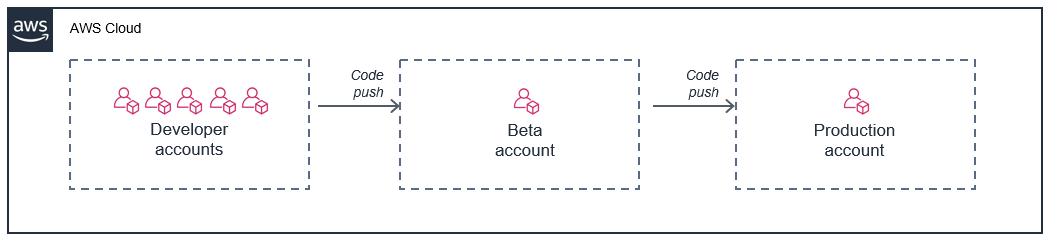
In diesem Modell hat jeder Entwickler seine eigenen Beschränkungen für das Konto, sodass sich deren Nutzung nicht auf Ihre Produktionsumgebung auswirkt. Dieser Ansatz ermöglicht es Entwicklern auch, Lambda-Funktionen lokal auf ihren Entwicklungsmaschinen anhand von Live-Cloud-Ressourcen in ihren individuellen Konten zu testen.
