Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurieren von Provisioned Concurrency für eine Funktion
In Lambda beschreibt die Gleichzeitigkeit die Anzahl der In-Flight-Anfragen, die Ihre Funktion gleichzeitig bearbeitet. Es gibt zwei Arten von Gleichzeitigkeitskontrollen:
-
Reservierte Gleichzeitigkeit – Hiermit wird sowohl die maximale als auch die minimale Anzahl der gleichzeitigen Instances festgelegt, die Ihrer Funktion zugewiesen sind. Wenn für eine Funktion Gleichzeitigkeit reserviert ist, kann keine andere Funktion diese Gleichzeitigkeit nutzen. Reservierte Gleichzeitigkeit ist nützlich, um sicherzustellen, dass Ihre kritischsten Funktionen immer genügend Gleichzeitigkeit haben, um eingehende Anfragen zu bearbeiten. Darüber hinaus kann reservierte Gleichzeitigkeit verwendet werden, um die Gleichzeitigkeit einzuschränken, und so zu verhindern, dass nachgelagerte Ressourcen wie Datenbankverbindungen überlastet werden. Die reservierte Gleichzeitigkeit dient sowohl als Untergrenze als auch als Obergrenze. Sie reserviert die angegebene Kapazität ausschließlich für Ihre Funktion und verhindert gleichzeitig, dass sie über diese Grenze hinaus skaliert wird. Für die Konfiguration reservierter Gleichzeitigkeit für eine Funktion wird keine zusätzliche Gebühr erhoben.
-
Die bereitgestellte Gleichzeitigkeit beschreibt die Anzahl der vorinitialisierten Ausführungsumgebungen, die Ihrer Funktion zugewiesen sind. Diese Ausführungsumgebungen sind bereit, sofort auf eingehende Funktionsanforderungen zu reagieren. Bereitgestellte Gleichzeitigkeit ist nützlich, um Kaltstartlatenzen für Funktionen zu reduzieren, und wurde entwickelt, um Funktionen mit Antwortzeiten im zweistelligen Millisekundenbereich verfügbar zu machen. Im Allgemeinen profitieren interaktive Workloads am meisten von diesem Feature. Dabei handelt es sich um Anwendungen, bei denen Benutzer Anfragen initiieren, wie z. B. Web- und Mobilanwendungen und sie reagieren am empfindlichsten auf Latenz. Asynchrone Workloads, wie Datenverarbeitungspipelines, reagieren häufig weniger empfindlich auf Latenz und benötigen daher in der Regel keine bereitgestellte Gleichzeitigkeit. Für die Konfiguration der bereitgestellten Parallelität fallen zusätzliche Gebühren für Sie an. AWS-Konto
In diesem Thema wird beschrieben, wie Sie bereitgestellte Gleichzeitigkeit verwalten und konfigurieren. Eine konzeptionelle Übersicht über diese beiden Arten von Gleichzeitigkeitssteuerungen finden Sie unter Reservierte Gleichzeitigkeit und bereitgestellte Gleichzeitigkeit. Weitere Informationen zur Konfiguration der reservierten Gleichzeitigkeit finden Sie unter Konfigurieren reservierter Gleichzeitigkeit für eine Funktion.
Anmerkung
Lambda-Funktionen, die mit einer Amazon-MQ-Ereignisquellenzuordnung verknüpft sind, haben standardmäßig die maximale Gleichzeitigkeit. Für Apache Active MQ ist die maximale Anzahl der gleichzeitigen Instances 5. Für Rabbit MQ ist die maximale Anzahl der gleichzeitigen Instances 1. Wenn Sie für Ihre Funktion eine reservierte oder bereitgestellte Parallelität festlegen, werden diese Grenzwerte nicht geändert. Um eine Erhöhung der standardmäßigen maximalen Parallelität bei der Verwendung von Amazon MQ zu beantragen, wenden Sie sich an. Support
Sections
Konfigurieren von Provisioned Concurrency
Sie können die Einstellungen der bereitgestellten Gleichzeitigkeit für eine Funktion mit der Lambda-Konsole oder mit der Lambda-API konfigurieren.
So weisen Sie einer Funktion bereitgestellte Gleichzeitigkeit zu (Konsole)
Öffnen Sie die Seite Funktionen
der Lambda-Konsole. -
Wählen Sie die Funktion aus, der Sie bereitgestellte Gleichzeitigkeit zuweisen möchten.
-
Wählen Sie Konfiguration und anschließend Gleichzeitigkeit aus.
-
Wählen Sie unter Provisioned concurrency configurations (Bereitgestellte Gleichzeitigkeitskonfigurationen) die Option Add (Hinzufügen) aus.
-
Wählen Sie den Qualifizierungstyp und den Alias oder die Version aus.
Anmerkung
Sie können die bereitgestellte Gleichzeitigkeit nicht mit der $LATEST-Version einer Funktion verwenden.
Wenn Ihre Funktion eine Ereignisquelle hat, müssen Sie sicherstellen, dass die Ereignisquelle auf den richtigen Funktionsalias bzw. die richtige Funktionsversion verweist. Anderenfalls verwendet Ihre Funktion keine bereitgestellten Gleichzeitigkeitsumgebungen.
-
Geben Sie unter Bereitgestellte Gleichzeitigkeit eine Zahl ein.
-
Wählen Sie Speichern.
Sie können in Ihrem Konto Gleichzeitigkeit bis zur nicht reservierten Konto-Gleichzeitigkeit minus 100 konfigurieren. Die verbleibenden 100 Gleichzeitigkeitseinheiten sind für Funktionen bestimmt, die keine reservierte Gleichzeitigkeit verwenden. Wenn Ihr Konto beispielsweise einen Gleichzeitigkeitsgrenzwert von 1 000 aufweist und Sie keiner anderen Funktion reservierte oder bereitgestellte Gleichzeitigkeit zugewiesen haben, können Sie maximal 900 bereitgestellte Gleichzeitigkeitseinheiten für eine einzelne Funktion konfigurieren.
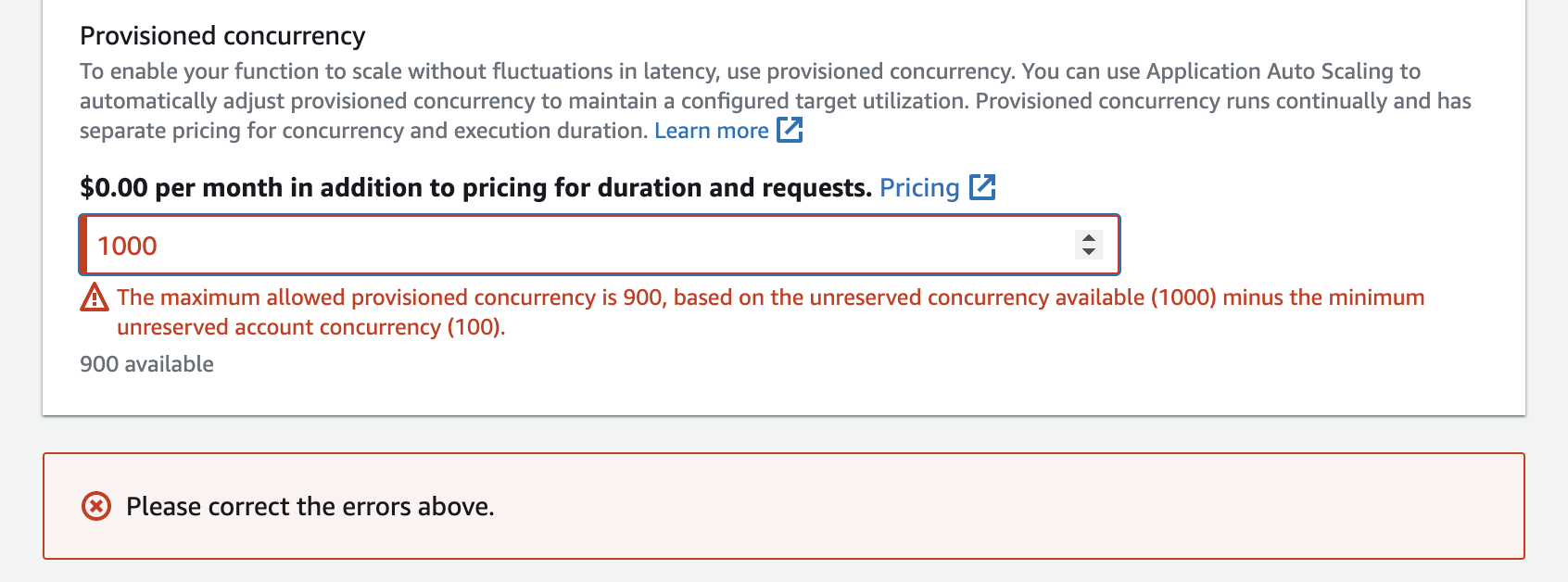
Die Konfiguration der bereitgestellten Gleichzeitigkeit für eine Funktion wirkt sich auf den Pool für die Gleichzeitigkeit aus, der für andere Funktionen verfügbar ist. Wenn Sie beispielsweise 100 bereitgestellte Gleichzeitigkeitseinheiten für function-a konfigurieren, müssen sich andere Funktionen in Ihrem Konto die verbleibenden 900 Gleichzeitigkeitseinheiten teilen. Das gilt auch, wenn function-a nicht alle 100 Einheiten verwendet.
Sie können für eine Funktion sowohl reservierte als auch bereitgestellte Gleichzeitigkeit festlegen. In solchen Fällen darf die bereitgestellte Gleichzeitigkeit die reservierte Gleichzeitigkeit nicht überschreiten.
Dieser Grenzwert gilt auch für Funktionsversionen. Die maximale Menge an bereitgestellter Gleichzeitigkeit, die Sie einer bestimmten Funktionsversion zuweisen können, entspricht der reservierten Gleichzeitigkeit der Funktion abzüglich der in anderen Funktionsversionen bereitgestellten Gleichzeitigkeit.
Verwenden Sie für die Konfiguration der bereitgestellten Gleichzeitigkeit mithilfe der Lambda-API die folgenden API-Operationen:
Verwenden Sie beispielsweise den Befehl, um die bereitgestellte Parallelität mit der AWS Command Line Interface (CLI) zu konfigurieren. put-provisioned-concurrency-config Der folgende Befehl weist 100 Einheiten bereitgestellter Gleichzeitigkeit für den Alias BLUE einer Funktion namens my-function zu:
aws lambda put-provisioned-concurrency-config --function-name my-function \ --qualifier BLUE \ --provisioned-concurrent-executions 100
Die Ausgabe sollte ungefähr wie folgt aussehen:
{ "Requested ProvisionedConcurrentExecutions": 100, "Allocated ProvisionedConcurrentExecutions": 0, "Status": "IN_PROGRESS", "LastModified": "2023-01-21T11:30:00+0000" }
Genaue Schätzung der erforderlichen bereitgestellten Gleichzeitigkeit für eine Funktion
Sie können die Parallelitätsmetriken jeder aktiven Funktion mithilfe von Metriken anzeigen. CloudWatch Insbesondere zeigt Ihnen die ConcurrentExecutions-Metrik die Anzahl der gleichzeitigen Aufrufe für Funktionen in Ihrem Konto.
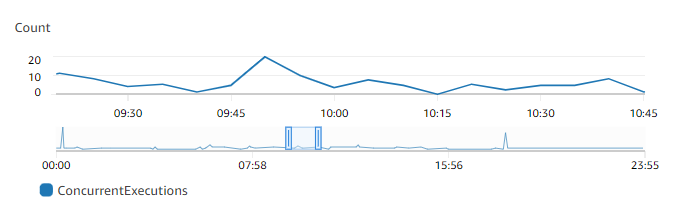
Aus dem vorstehenden Diagramm geht hervor, dass diese Funktion jederzeit im Durchschnitt 5 bis 10 gleichzeitige Anforderungen verarbeitet und Spitzenwerte von 20 Anforderungen erreicht. Angenommen, Ihr Konto enthält viele andere Funktionen. Wenn diese Funktion für Ihre Anwendung von entscheidender Bedeutung ist und Sie bei jedem Aufruf eine Reaktion mit geringer Latenz wünschen, legen Sie für die bereitgestellte Gleichzeitigkeit eine Zahl fest, die größer oder gleich 20 ist.
Denken Sie daran, dass Sie die Gleichzeitigkeit auch mit der folgenden Formel berechnen können:
Concurrency = (average requests per second) * (average request duration in seconds)
Um abzuschätzen, wie viel Gleichzeitigkeit Sie benötigen, multiplizieren Sie die durchschnittlichen Anfragen pro Sekunde mit der durchschnittlichen Anfragedauer in Sekunden. Sie können die durchschnittlichen Anfragen pro Sekunde anhand der Invocation-Metrik und die durchschnittliche Anfragedauer in Sekunden anhand der Duration-Metrik schätzen.
Beim Konfigurieren der bereitgestellten Gleichzeitigkeit schlägt Lambda vor, einen Puffer von 10 % zusätzlich zu der Menge an Gleichzeitigkeit einzuplanen, die Ihre Funktion normalerweise benötigt. Wenn die Funktion normalerweise bei 200 gleichzeitigen Anforderungen Spitzenwerte erreicht, sollten Sie die bereitgestellte Gleichzeitigkeit auf 220 festlegen (200 gleichzeitige Anforderungen + 10 % = 220 bereitgestellte Gleichzeitigkeit).
Optimierung des Funktionscodes bei Verwendung der bereitgestellten Gleichzeitigkeit
Wenn Sie bereitgestellte Gleichzeitigkeit verwenden, sollten Sie Ihren Funktionscode so umstrukturieren, dass er für niedrige Latenzzeiten optimiert ist. Bei Funktionen, die bereitgestellte Gleichzeitigkeit verwenden, führt Lambda jeglichen Initialisierungscode, wie das Laden von Bibliotheken und die Instanziierung von Clients, während der Zuweisungszeit aus. Daher bietet es sich an, möglichst viele Initialisierungen außerhalb des Hauptfunktionshandlers zu verschieben, um bei tatsächlichen Funktionsaufrufen Latenzprobleme zu vermeiden. Im Gegensatz dazu bedeutet die Initialisierung von Bibliotheken oder die Instanziierung von Clients innerhalb Ihres Haupthandler-Codes, dass Ihre Funktion dies bei jedem Aufruf ausführen muss (dies geschieht unabhängig davon, ob Sie die bereitgestellte Gleichzeitigkeit verwenden).
Bei On-Demand-Aufrufen muss Lambda den Initialisierungscode möglicherweise jedes Mal neu ausführen, wenn die Funktion einen Kaltstart durchführt. In diesem Fall können Sie die Initialisierung einzelner Fähigkeiten verschieben, bis Ihre Funktion sie benötigt. Sehen Sie sich zum Beispiel den folgenden Steuerungsablauf für einen Lambda-Handler an:
def handler(event, context): ... if ( some_condition ): // Initialize CLIENT_A to perform a task else: // Do nothing
Im vorherigen Beispiel entschied sich der Entwickler dagegen, CLIENT_A außerhalb des Haupthandlers zu initialisieren, und initialisierte ihn stattdessen innerhalb der if-Anweisung. Auf diese Weise führt Lambda diesen Code nur aus, wenn die Bedingung some_condition erfüllt wird. Wenn CLIENT_A außerhalb des Haupthandlers initialisiert wird, führt Lambda diesen Code bei jedem Kaltstart aus. Das kann die Gesamtlatenz erhöhen.
Sie können Kaltstarts messen, wenn Lambda skaliert, indem Sie Ihre Funktion um eine X-Ray Überwachung erweitern. Eine Funktion, die bereitgestellte Gleichzeitigkeit verwendet, weist kein Kaltstartverhalten auf, da die Ausführungsumgebung vor dem Aufruf vorbereitet wird. Bereitgestellte Gleichzeitigkeit muss jedoch auf eine bestimmte Version oder einen Alias einer Funktion angewendet werden, nicht auf die $LATEST-Version. Falls weiterhin ein Kaltstartverhalten auftritt, stellen Sie sicher, dass Sie die Alias-Version aufrufen, für die bereitgestellte Gleichzeitigkeit konfiguriert ist.
Verwendung von Umgebungsvariablen zur Anzeige und Steuerung des bereitgestellten Gleichzeitigkeitsverhaltens
Es ist möglich, dass Ihre Funktion die gesamte bereitgestellte Gleichzeitigkeit verbraucht. Lambda verwendet On-Demand-Instances, um zusätzlichen Datenverkehr zu verarbeiten. Um festzustellen, welche Art von Initialisierung Lambda für eine bestimmte Umgebung verwendet hat, überprüfen Sie den Wert der Umgebungsvariable AWS_LAMBDA_INITIALIZATION_TYPE. Diese Variable hat zwei mögliche Werte: provisioned-concurrency oder on-demand. Der Wert von AWS_LAMBDA_INITIALIZATION_TYPE ist unveränderlich und bleibt während der gesamten Lebensdauer der Umgebung konstant. Um den Wert einer Umgebungsvariablen in Ihrem Funktionscode zu überprüfen, finden Sie unter Abrufen von Lambda-Umgebungsvariablen.
Bei Verwendung der .NET 8-Laufzeit können Sie die Umgebungsvariable AWS_LAMBDA_DOTNET_PREJIT konfigurieren, um die Latenz für Funktionen zu verbessern, auch wenn diese keine bereitgestellte Gleichzeitigkeit verwenden. Die .NET-Laufzeitumgebung führt für jede Bibliothek, die der Code zum ersten Mal aufruft, eine verzögerte Kompilierung und Initialisierung durch. Daher kann der erste Aufruf einer Lambda-Funktion länger dauern als nachfolgende Aufrufe. Um dies zu verhindern, können Sie einen von drei Werten für AWS_LAMBDA_DOTNET_PREJIT wählen:
-
ProvisionedConcurrency: Lambda führt für alle Umgebungen, die bereitgestellte Gleichzeitigkeit verwenden, eine zeitliche JIT-Kompilierung durch. Dies ist der Standardwert. -
Always: Lambda führt für jede Umgebung eine zeitliche JIT-Kompilierung durch, auch wenn die Funktion keine bereitgestellte Gleichzeitigkeit verwendet. -
Never: Lambda deaktiviert die JIT-Kompilierung für alle Umgebungen vorab.
Verstehen des Protokollierungs- und Abrechnungsverhaltens bei bereitgestellter Gleichzeitigkeit
Für bereitgestellte Gleichzeitigkeitsumgebungen wird der Initialisierungscode Ihrer Funktion während der Zuordnung und alle paar Stunden ausgeführt, da Lambda aktive Instances Ihrer Umgebung recycelt. Lambda rechnet die Initialisierung auch dann ab, wenn die Umgebungs-Instance niemals eine Anforderung verarbeitet. Die bereitgestellte Gleichzeitigkeit wird laufend ausgeführt und getrennt von den Initialisierungs- und Aufrufkosten in Rechnung gestellt. Weitere Einzelheiten finden Sie unter AWS Lambda -Preise
Wenn Sie eine Lambda-Funktion mit bereitgestellter Gleichzeitigkeit konfigurieren, initialisiert Lambda diese Ausführungsumgebung vor, sodass sie vor Aufrufanforderungen verfügbar ist. Lambda protokolliert bei jeder Initialisierung der Umgebung das Feld Initialisierungsdauer der Funktion in einem platform-initReport-Protokollereignis im JSON-Protokollierungsformat. Um dieses Protokollereignis zu sehen, konfigurieren Sie Ihre JSON-Protokollebene auf mindestens INFO. Sie können die Telemetrie-API auch verwenden, um Plattformereignisse zu verarbeiten, bei denen das Feld „Initialisierungsdauer“ gemeldet wird.
Auto Scaling von Anwendungen zur Automatisierung der Verwaltung von Gleichzeitigkeit bei der Bereitstellung
Application Auto Scaling ermöglicht es Ihnen, die bereitgestellte Gleichzeitigkeit nach einem Zeitplan oder basierend auf der Auslastung zu verwalten. Wenn Sie vorhersehbare Auslastungsmuster für Ihre Funktion beobachten, verwenden Sie die geplante Skalierung. Wenn Sie möchten, dass Ihre Funktion einen bestimmten Auslastungsprozentsatz beibehält, verwenden Sie eine Richtlinie für die Zielverfolgungsskalierung.
Anmerkung
Wenn Sie Auto Scaling von Anwendungen verwenden, um die bereitgestellte Gleichzeitigkeit Ihrer Funktion zu verwalten, stellen Sie sicher, dass Sie zuerst einen anfänglichen Wert für die bereitgestellte Gleichzeitigkeit konfigurieren. Wenn Ihre Funktion keinen anfänglichen Gleichzeitigkeitswert hat, kann die Application Auto Scaling die Funktionsskalierung möglicherweise nicht ordnungsgemäß durchführen.
Geplante Skalierung
Application Auto Scaling ermöglicht es Ihnen, Ihren eigenen Skalierungsplan entsprechend vorhersehbarer Laständerungen festzulegen. Weitere Informationen und Beispiele finden Sie unter Geplante Skalierung für Application Auto Scaling im Application Auto Scaling Scaling-Benutzerhandbuch und Scheduling AWS Lambda Provisioned Concurrency für wiederkehrende Spitzennutzung
Zielverfolgung
Mit der Zielverfolgung erstellt und verwaltet Application Auto Scaling eine Reihe von CloudWatch Alarmen, die darauf basieren, wie Sie Ihre Skalierungsrichtlinie definieren. Wenn diese Alarme aktiviert werden, passt Application Auto Scaling mithilfe der bereitgestellten Gleichzeitigkeit automatisch die Anzahl der zugewiesenen Umgebungen an. Verwenden Sie die Zielverfolgung für Anwendungen, die keine vorhersehbaren Auslastungsmuster aufweisen.
Verwenden Sie die API-Operationen RegisterScalableTarget und PutScalingPolicy Application Auto Scaling, um die bereitgestellte Gleichzeitigkeit mithilfe der Zielverfolgung zu skalieren. Wenn Sie beispielsweise die AWS Command Line Interface (CLI) verwenden, gehen Sie wie folgt vor:
-
Registrieren Sie den Alias einer Funktion als Skalierungsziel. Im folgenden Beispiel wird der BLUE-Alias einer Funktion mit dem Namen
my-functionregistriert:aws application-autoscaling register-scalable-target --service-namespace lambda \ --resource-id function:my-function:BLUE --min-capacity 1 --max-capacity 100 \ --scalable-dimension lambda:function:ProvisionedConcurrency -
Wenden Sie eine Skalierungsrichtlinie auf das Ziel an. Im folgenden Beispiel wird Application Auto Scaling so konfiguriert, dass die bereitgestellte Gleichzeitigkeitskonfiguration für einen Alias so angepasst wird, dass die Auslastung bei 70 % liegt. Sie können jedoch jeden beliebigen Wert zwischen 10 % und 90 % anwenden.
aws application-autoscaling put-scaling-policy \ --service-namespace lambda \ --scalable-dimension lambda:function:ProvisionedConcurrency \ --resource-id function:my-function:BLUE \ --policy-name my-policy \ --policy-type TargetTrackingScaling \ --target-tracking-scaling-policy-configuration '{ "TargetValue": 0.7, "PredefinedMetricSpecification": { "PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization" }}'
Die Ausgabe sollte in etwa wie folgt aussehen:
{ "PolicyARN": "arn:aws:autoscaling:us-east-2:123456789012:scalingPolicy:12266dbb-1524-xmpl-a64e-9a0a34b996fa:resource/lambda/function:my-function:BLUE:policyName/my-policy", "Alarms": [ { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7" }, { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66" } ] }
Application Auto Scaling erstellt zwei Alarme in CloudWatch. Der erste Alarm wird ausgelöst, wenn die Auslastung der bereitgestellten Gleichzeitigkeit konstant 70 % überschreitet. In diesem Fall weist Application Auto Scaling mehr bereitgestellte Gleichzeitigkeit zu, um die Auslastung zu reduzieren. Der zweite Alarm wird ausgelöst, wenn die Auslastung konstant unter 63 % (90 % des 70-%-Ziels) liegt. In diesem Fall reduziert Application Auto Scaling wird die bereitgestellte Gleichzeitigkeit des Alias.
Anmerkung
Lambda gibt die Metrik ProvisionedConcurrencyUtilization nur aus, wenn Ihre Funktion aktiv ist und Anforderungen empfängt. In Zeiten der Inaktivität werden keine Messwerte ausgegeben, und Ihre Auto-Scaling-Alarme wechseln in den Status INSUFFICIENT_DATA. Infolgedessen kann die Anwendung von Auto Scaling die von Ihrer Funktion bereitgestellte Gleichzeitigkeit nicht anpassen. Dies kann zu einer unerwarteten Abrechnung führen.
Im folgenden Beispiel skaliert eine Funktion basierend auf der Auslastung zwischen einem minimalen und einem maximalen Umfang bereitgestellter Gleichzeitigkeit.
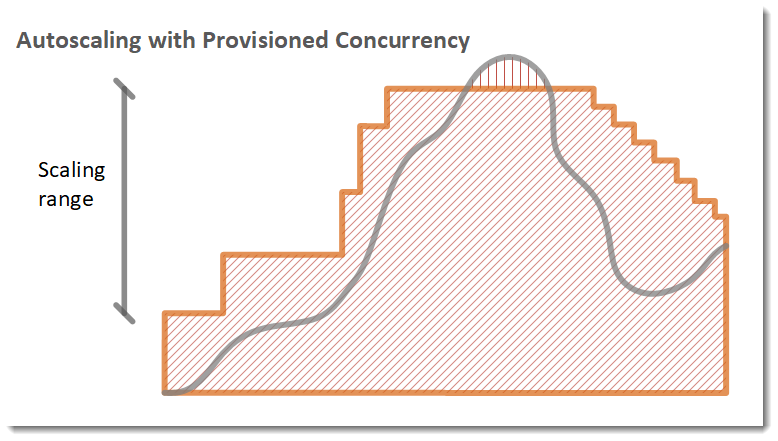
Legende
-
 Funktions-Instances
Funktions-Instances -
 Offene Anforderungen
Offene Anforderungen -
 Bereitgestellte Concurrency
Bereitgestellte Concurrency -
 Standard-Gleichzeitigkeit
Standard-Gleichzeitigkeit
Wenn die Anzahl der offenen Anforderungen zunimmt, erhöht Application Auto Scaling die bereitgestellte Gleichzeitigkeit in großen Schritten, bis sie das konfigurierte Maximum erreicht. Danach kann die Funktion weiter die standardmäßige, nicht reservierte Gleichzeitigkeit skalieren, falls das Kontogleichzeitigkeitslimit nicht erreicht ist. Wenn die Auslastung sinkt und niedrig bleibt, verringert Application Auto Scaling die bereitgestellte Gleichzeitigkeit in kleineren periodischen Schritten.
Beide Alarme für Application Auto Scaling verwenden standardmäßig die Durchschnittsstatistik. Funktionen, die in kurzen Abständen auftretende Auslastungsmuster aufweisen, lösen diese Alarme möglicherweise nicht aus. Nehmen wir zum Beispiel an, Ihre Lambda-Funktion wird schnell ausgeführt (d. h. 20–100 ms) und der Datenverkehr kommt in kurzen Schüben (Bursts). In diesem Fall übersteigt die Anzahl der Anfragen die zugewiesene, bereitgestellte Gleichzeitigkeit während eines Bursts. Beim Application Auto Scaling muss die Burst-Last jedoch mindestens 3 Minuten lang aufrechterhalten werden, um zusätzliche Umgebungen bereitzustellen. Darüber hinaus benötigen beide CloudWatch Alarme 3 Datenpunkte, die den Zieldurchschnitt erreichen, um die Auto Scaling-Richtlinie zu aktivieren. Wenn bei Ihrer Funktion ein schneller Anstieg des Datenverkehrs auftritt, kann die Verwendung der Maximum-Statistik anstelle der Durchschnittsstatistik effektiver sein, um die bereitgestellte Gleichzeitigkeit zu skalieren und Kaltstarts zu minimieren.
Weitere Informationen zu Zielverfolgungs-Skalierungsrichtlinien finden Sie unter Zielverfolgungs-Skalierungsrichtlinien für das Application Auto Scaling.
