Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden einer OpenSearch Ingestion-Pipeline mit Offline-Batch-Inferenz für maschinelles Lernen
Amazon OpenSearch Ingestion (OSI) -Pipelines unterstützen die Offline-Batch-Inferenzverarbeitung für maschinelles Lernen (ML), um große Datenmengen effizient und kostengünstig anzureichern. Verwenden Sie Offline-Batch-Inferenz immer dann, wenn Sie über große Datensätze verfügen, die asynchron verarbeitet werden können. Offline-Batch-Inferenz funktioniert mit Amazon Bedrock und SageMaker Modellen. Diese Funktion ist in allen Domains verfügbar AWS-Regionen , die OpenSearch Ingestion mit OpenSearch Service 2.17+ unterstützen.
Anmerkung
Verwenden Sie für die Verarbeitung von Inferenzen in Echtzeit. Amazon OpenSearch Service ML-Konnektoren für Plattformen von Drittanbietern
Die Offline-Batch-Inferenzverarbeitung nutzt eine Funktion OpenSearch namens ML Commons. ML Commons stellt ML-Algorithmen über Transport- und REST-API-Aufrufe bereit. Diese Aufrufe wählen die richtigen Knoten und Ressourcen für jede ML-Anfrage aus und überwachen ML-Aufgaben, um die Verfügbarkeit sicherzustellen. Auf diese Weise können Sie mit ML Commons bestehende Open-Source-ML-Algorithmen nutzen und den Aufwand für die Entwicklung neuer ML-Funktionen reduzieren. Weitere Informationen zu ML Commons finden Sie unter Maschinelles Lernen
Funktionsweise
Sie können eine Offline-Batch-Inferenz-Pipeline bei OpenSearch Ingestion erstellen, indem Sie einer Pipeline einen Inferenzprozessor für maschinelles Lernen hinzufügen
OpenSearch Ingestion verwendet den ml_inference Prozessor mit ML Commons, um Offline-Batch-Inferenzjobs zu erstellen. ML Commons verwendet dann die batch_predict-API
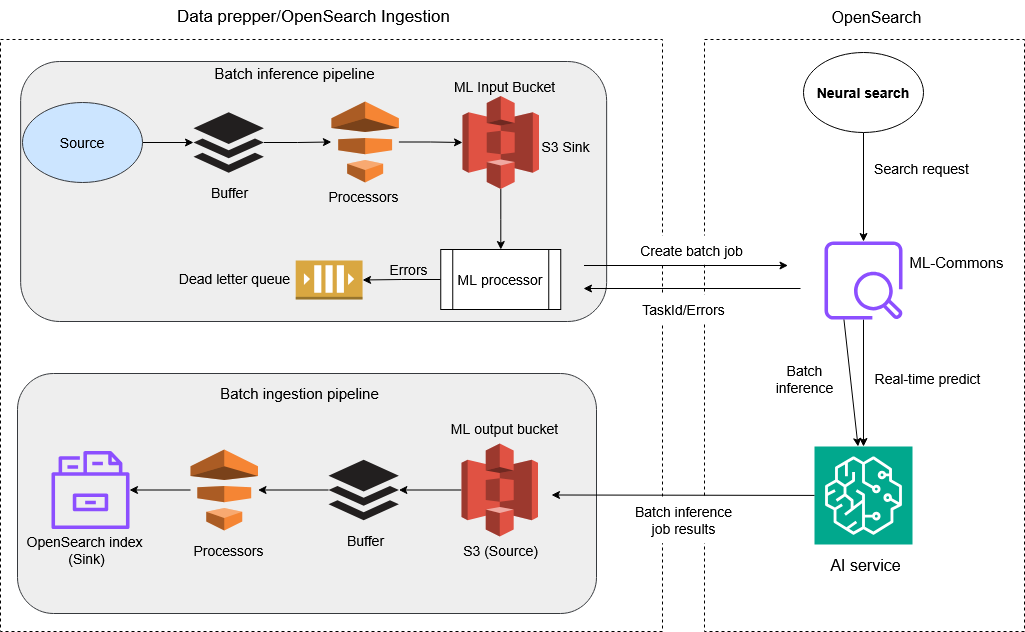
Die Pipeline-Komponenten funktionieren wie folgt:
Pipeline 1 (Datenaufbereitung und Transformation) *:
-
Quelle: Die Daten werden von Ihrer externen Quelle gescannt, die von OpenSearch Ingestion unterstützt wird.
-
Datenprozessoren: Die Rohdaten werden verarbeitet und im integrierten KI-Service in das richtige Format für Batch-Inferenzen umgewandelt.
-
S3 (Sink): Die verarbeiteten Daten werden in einem Amazon S3-Bucket bereitgestellt, sodass sie als Eingabe für die Ausführung von Batch-Inferenzjobs auf dem integrierten AI-Service dienen können.
Pipeline 2 (Trigger ML batch_inference):
-
Quelle: Automatisierte S3-Ereigniserkennung neuer Dateien, die durch die Ausgabe von Pipeline 1 erstellt wurden.
-
ML_Inference-Prozessor: Prozessor, der ML-Inferenzen durch einen asynchronen Batch-Job generiert. Er stellt über den konfigurierten AI-Konnektor, der auf Ihrer Zieldomäne ausgeführt wird, eine Verbindung zu KI-Diensten her.
-
Aufgaben-ID: Jeder Batch-Job ist zur Nachverfolgung und Verwaltung mit einer Aufgaben-ID in ml-commons verknüpft.
-
OpenSearch ML Commons: ML Commons, das das Modell für die neuronale Echtzeitsuche hostet, verwaltet die Konnektoren zu entfernten KI-Servern und APIs dient der Batch-Inferenz und der Auftragsverwaltung.
-
KI-Dienste: OpenSearch ML Commons interagiert mit KI-Diensten wie Amazon Bedrock und Amazon, SageMaker um Batch-Inferenzen aus den Daten durchzuführen und Vorhersagen oder Erkenntnisse zu gewinnen. Die Ergebnisse werden asynchron in einer separaten S3-Datei gespeichert.
Pipeline 3 (Massenaufnahme):
-
S3 (Quelle): Die Ergebnisse der Batch-Jobs werden in S3 gespeichert, der Quelle dieser Pipeline.
-
Prozessoren für die Datentransformation: Die weitere Verarbeitung und Transformation werden vor der Aufnahme auf die Batch-Inferenzausgabe angewendet. Dadurch wird sichergestellt, dass die Daten im Index korrekt zugeordnet werden. OpenSearch
-
OpenSearch Index (Sink): Die verarbeiteten Ergebnisse werden OpenSearch zur Speicherung, Suche und weiteren Analyse indexiert.
Anmerkung
*Der in Pipeline 1 beschriebene Prozess ist optional. Wenn Sie möchten, können Sie diesen Vorgang überspringen und einfach Ihre vorbereiteten Daten in die S3-Senke hochladen, um Batch-Jobs zu erstellen.
Über den ml_inference-Prozessor
OpenSearch Ingestion verwendet eine spezielle Integration zwischen der S3-Scan-Quelle und dem ML-Inferenzprozessor für die Stapelverarbeitung. Der S3-Scan arbeitet nur im Metadatenmodus, um S3-Dateiinformationen effizient zu sammeln, ohne den eigentlichen Dateiinhalt lesen zu müssen. Der ml_inference Prozessor verwendet die S3-Datei URLs , um die Stapelverarbeitung mit ML Commons zu koordinieren. Dieses Design optimiert den Batch-Inferenz-Workflow, indem unnötige Datenübertragungen während der Scanphase minimiert werden. Sie definieren den ml_inference Prozessor mithilfe von Parametern. Ein Beispiel:
processor: - ml_inference: # The endpoint URL of your OpenSearch domain host: "https://AWS test-offlinebatch-123456789abcdefg.us-west-2.es.amazonaws.com" # Type of inference operation: # - batch_predict: for batch processing # - predict: for real-time inference action_type: "batch_predict" # Remote ML model service provider (Amazon Bedrock or SageMaker) service_name: "bedrock" # Unique identifier for the ML model model_id: "AWS TestModelID123456789abcde" # S3 path where batch inference results will be stored output_path: "s3://amzn-s3-demo-bucket/" # Supports ISO_8601 notation strings like PT20.345S or PT15M # These settings control how long to keep your inputs in the processor for retry on throttling errors retry_time_window: "PT9M" # AWS configuration settings aws: # AWS-Region where the Lambda function is deployed region: "us-west-2" # IAM role ARN for Lambda function execution sts_role_arn: "arn:aws::iam::account_id:role/Admin" # Dead-letter queue settings for storing errors dlq: s3: region: us-west-2 bucket: batch-inference-dlq key_path_prefix: bedrock-dlq sts_role_arn: arn:aws:iam::account_id:role/OSI-invoke-ml# Conditional expression that determines when to trigger the processor # In this case, only process when bucket matches "amzn-s3-demo-bucket" ml_when: /bucket == "amzn-s3-demo-bucket"
Leistungsverbesserungen bei der Aufnahme mithilfe des ml_inference-Prozessors
Der OpenSearch ml_inference Ingestion-Prozessor verbessert die Datenaufnahmeleistung bei ML-fähiger Suche erheblich. Der Prozessor eignet sich ideal für Anwendungsfälle, in denen modellgenerierte Daten für maschinelles Lernen erforderlich sind, darunter semantische Suche, multimodale Suche, Anreicherung von Dokumenten und Verständnis von Abfragen. Bei der semantischen Suche kann der Prozessor die Erstellung und Aufnahme von großvolumigen, hochdimensionalen Vektoren um eine Größenordnung beschleunigen.
Die Offline-Batch-Inferenzfunktion des Prozessors bietet deutliche Vorteile gegenüber dem Modellaufruf in Echtzeit. Während für die Echtzeitverarbeitung ein Live-Model-Server mit Kapazitätsbeschränkungen erforderlich ist, skaliert Batch-Inferenz die Rechenressourcen dynamisch bei Bedarf und verarbeitet Daten parallel. Wenn die OpenSearch Ingestion-Pipeline beispielsweise eine Milliarde Quelldatenanfragen empfängt, erstellt sie 100 S3-Dateien für die Eingabe von ML-Batch-Inferenzen. Der ml_inference Prozessor initiiert dann einen SageMaker Batch-Job unter Verwendung von 100 ml.m4.xlarge Amazon Elastic Compute Cloud (Amazon EC2) -Instances und schließt die Vektorisierung von einer Milliarde Anfragen innerhalb von 14 Stunden ab — eine Aufgabe, die im Echtzeitmodus praktisch unmöglich zu bewerkstelligen wäre.
Konfigurieren Sie den ml_inference-Prozessor so, dass er Datenanfragen für eine semantische Suche aufnimmt
Die folgenden Verfahren führen Sie durch den Prozess der Einrichtung und Konfiguration des OpenSearch ml_inference Ingestion-Prozessors für die Aufnahme von einer Milliarde Datenanfragen für die semantische Suche mithilfe eines Texteinbettungsmodells.
Themen
Schritt 1: Konnektoren erstellen und Modelle registrieren in OpenSearch
Verwenden Sie für das folgende Verfahren den ML Commons batch_inference_sagemaker_connector_blueprint
So erstellen Sie Konnektoren und registrieren Modelle in OpenSearch
-
Erstellen Sie ein ML-Modell der Deep Java Library (DJL) SageMaker für die Batch-Transformation. Weitere DJL-Modelle finden Sie unter Semantic_Search_with_CFN_Template_for_SageMaker
auf: GitHub POST https://api.sagemaker.us-east-1.amazonaws.com/CreateModel { "ExecutionRoleArn": "arn:aws:iam::123456789012:role/aos_ml_invoke_sagemaker", "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "PrimaryContainer": { "Environment": { "SERVING_LOAD_MODELS" : "djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2" }, "Image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.29.0-cpu-full" } } -
Erstellen Sie
batch_predicteinenactionKonnektor mit dem neuen Typ im Feld:actionsPOST /_plugins/_ml/connectors/_create { "name": "DJL Sagemaker Connector: all-MiniLM-L6-v2", "version": "1", "description": "The connector to sagemaker embedding model all-MiniLM-L6-v2", "protocol": "aws_sigv4", "credential": { "roleArn": "arn:aws:iam::111122223333:role/SageMakerRole" }, "parameters": { "region": "us-east-1", "service_name": "sagemaker", "DataProcessing": { "InputFilter": "$.text", "JoinSource": "Input", "OutputFilter": "$" }, "MaxConcurrentTransforms": 100, "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "TransformInput": { "ContentType": "application/json", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://offlinebatch/msmarcotests/" } }, "SplitType": "Line" }, "TransformJobName": "djl-batch-transform-1-billion", "TransformOutput": { "AssembleWith": "Line", "Accept": "application/json", "S3OutputPath": "s3://offlinebatch/msmarcotestsoutputs/" }, "TransformResources": { "InstanceCount": 100, "InstanceType": "ml.m4.xlarge" }, "BatchStrategy": "SingleRecord" }, "actions": [ { "action_type": "predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://runtime.sagemaker.us-east-1.amazonaws.com/endpoints/OpenSearch-sagemaker-060124023703/invocations", "request_body": "${parameters.input}", "pre_process_function": "connector.pre_process.default.embedding", "post_process_function": "connector.post_process.default.embedding" }, { "action_type": "batch_predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/CreateTransformJob", "request_body": """{ "BatchStrategy": "${parameters.BatchStrategy}", "ModelName": "${parameters.ModelName}", "DataProcessing" : ${parameters.DataProcessing}, "MaxConcurrentTransforms": ${parameters.MaxConcurrentTransforms}, "TransformInput": ${parameters.TransformInput}, "TransformJobName" : "${parameters.TransformJobName}", "TransformOutput" : ${parameters.TransformOutput}, "TransformResources" : ${parameters.TransformResources}}""" }, { "action_type": "batch_predict_status", "method": "GET", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/DescribeTransformJob", "request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}""" }, { "action_type": "cancel_batch_predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/StopTransformJob", "request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}""" } ] } -
Verwenden Sie die zurückgegebene Connector-ID, um das SageMaker Modell zu registrieren:
POST /_plugins/_ml/models/_register { "name": "SageMaker model for batch", "function_name": "remote", "description": "test model", "connector_id": "example123456789-abcde" } -
Rufen Sie das Modell mit dem
batch_predictAktionstyp auf:POST /_plugins/_ml/models/teHr3JABBiEvs-eod7sn/_batch_predict { "parameters": { "TransformJobName": "SM-offline-batch-transform" } }Die Antwort enthält eine Aufgaben-ID für den Batch-Job:
{ "task_id": "exampleIDabdcefd_1234567", "status": "CREATED" } -
Überprüfen Sie den Status des Batch-Jobs, indem Sie die Get Task API mit der Task-ID aufrufen:
GET /_plugins/_ml/tasks/exampleIDabdcefd_1234567Die Antwort enthält den Aufgabenstatus:
{ "model_id": "nyWbv5EB_tT1A82ZCu-e", "task_type": "BATCH_PREDICTION", "function_name": "REMOTE", "state": "RUNNING", "input_type": "REMOTE", "worker_node": [ "WDZnIMcbTrGtnR4Lq9jPDw" ], "create_time": 1725496527958, "last_update_time": 1725496527958, "is_async": false, "remote_job": { "TransformResources": { "InstanceCount": 1, "InstanceType": "ml.c5.xlarge" }, "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "TransformOutput": { "Accept": "application/json", "AssembleWith": "Line", "KmsKeyId": "", "S3OutputPath": "s3://offlinebatch/output" }, "CreationTime": 1725496531.935, "TransformInput": { "CompressionType": "None", "ContentType": "application/json", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://offlinebatch/sagemaker_djl_batch_input.json" } }, "SplitType": "Line" }, "TransformJobArn": "arn:aws:sagemaker:us-east-1:111122223333:transform-job/SM-offline-batch-transform15", "TransformJobStatus": "InProgress", "BatchStrategy": "SingleRecord", "TransformJobName": "SM-offline-batch-transform15", "DataProcessing": { "InputFilter": "$.content", "JoinSource": "Input", "OutputFilter": "$" } } }
(Alternatives Verfahren) Schritt 1: Erstellen Sie Konnektoren und Modelle mithilfe einer CloudFormation Integrationsvorlage
Wenn Sie möchten, können Sie AWS CloudFormation damit automatisch alle erforderlichen SageMaker Amazon-Konnektoren und -Modelle für ML-Inferenz erstellen. Dieser Ansatz vereinfacht die Einrichtung, indem er eine vorkonfigurierte Vorlage verwendet, die in der Amazon OpenSearch Service-Konsole verfügbar ist. Weitere Informationen finden Sie unter Wird verwendet CloudFormation , um Remote-Inferenz für die semantische Suche einzurichten.
Um einen CloudFormation Stack bereitzustellen, der alle erforderlichen SageMaker Konnektoren und Modelle erstellt
-
Öffnen Sie die Amazon OpenSearch Service-Konsole.
-
Wählen Sie im Navigationsbereich Integrationen aus.
-
Geben Sie
SageMakerim Suchfeld den Text ein und wählen Sie dann Integration mit Modellen zur Texteinbettung über Amazon SageMaker aus. -
Wählen Sie Domain konfigurieren und dann VPC-Domain konfigurieren oder Öffentliche Domain konfigurieren.
-
Geben Sie Informationen in die Vorlagenfelder ein. Wählen Sie für Offline-Batch-Inferenz aktivieren die Option true aus, um Ressourcen für die Offline-Batchverarbeitung bereitzustellen.
-
Wählen Sie Create, um den CloudFormation Stack zu erstellen.
-
Öffnen Sie nach der Erstellung des Stacks die Registerkarte Outputs in der CloudFormation Konsole. Suchen Sie nach Connector_ID und Model_ID. Sie benötigen diese Werte später, wenn Sie die Pipeline konfigurieren.
Schritt 2: Erstellen Sie eine OpenSearch Ingestion-Pipeline für ML-Offline-Batch-Inferenz
Verwenden Sie das folgende Beispiel, um eine OpenSearch Ingestion-Pipeline für ML-Offline-Batchinferenz zu erstellen. Weitere Informationen zum Erstellen einer Pipeline für OpenSearch Ingestion finden Sie unter. Amazon OpenSearch Ingestion-Pipelines erstellen
Bevor Sie beginnen
Im folgenden Beispiel geben Sie einen IAM-Rollen-ARN für den sts_role_arn Parameter an. Verwenden Sie das folgende Verfahren, um zu überprüfen, ob diese Rolle der Backend-Rolle zugeordnet ist, die Zugriff auf ml-commons in hat. OpenSearch
-
Navigieren Sie zum OpenSearch Dashboards-Plugin für Ihre Service-Domain. OpenSearch Sie finden den Dashboard-Endpunkt in Ihrem Domain-Dashboard in der OpenSearch Service-Konsole.
-
Wählen Sie im Hauptmenü Sicherheit, Rollen und dann die Rolle ml_full_access aus.
-
Wählen Sie Zugeordnete Benutzer, Mapping verwalten.
-
Geben Sie unter Backend-Rollen den ARN der Lambda-Rolle ein, für die eine Berechtigung zum Aufrufen Ihrer Domain erforderlich ist. Hier ist ein Beispiel: arn:aws:iam: :role/
111122223333lambda-role -
Wählen Sie Zuordnen und bestätigen Sie, dass der Benutzer oder die Rolle unter Zugeordnete Benutzer angezeigt wird.
Beispiel zum Erstellen einer Ingestion-Pipeline für ML-Offline-Batch-Inferenz OpenSearch
version: '2' extension: osis_configuration_metadata: builder_type: visual sagemaker-batch-job-pipeline: source: s3: acknowledgments: true delete_s3_objects_on_read: false scan: buckets: - bucket: name:namedata_selection: metadata_only filter: include_prefix: - sagemaker/sagemaker_djl_batch_input exclude_suffix: - .manifest - bucket: name:namedata_selection: data_only filter: include_prefix: - sagemaker/output/ scheduling: interval: PT6M aws: region:namedefault_bucket_owner:account_IDcodec: ndjson: include_empty_objects: false compression: none workers: '1' processor: - ml_inference: host: "https://search-AWStest-offlinebatch-123456789abcdef.us-west-2.es.amazonaws.com" aws_sigv4: true action_type: "batch_predict" service_name: "sagemaker" model_id: "model_ID" output_path: "s3://AWStest-offlinebatch/sagemaker/output" aws: region: "us-west-2" sts_role_arn: "arn:aws:iam::account_ID:role/Admin" ml_when: /bucket == "AWStest-offlinebatch" dlq: s3: region:us-west-2bucket:batch-inference-dlqkey_path_prefix:bedrock-dlqsts_role_arn: arn:aws:iam::account_ID:role/OSI-invoke-ml- copy_values: entries: - from_key: /text to_key: chapter - from_key: /SageMakerOutput to_key: chapter_embedding - delete_entries: with_keys: - text - SageMakerOutput sink: - opensearch: hosts: ["https://search-AWStest-offlinebatch-123456789abcdef.us-west-2.es.amazonaws.com"] aws: serverless: false region: us-west-2 routes: - ml-ingest-route index_type: custom index: test-nlp-index routes: - ml-ingest-route: /chapter != null and /title != null
Schritt 3: Bereiten Sie Ihre Daten für die Aufnahme vor
Um Ihre Daten für die maschinelle Offline-Batch-Inferenzverarbeitung vorzubereiten, bereiten Sie die Daten entweder selbst mit Ihren eigenen Tools oder Prozessen vor oder verwenden Sie den OpenSearch Data Prepper.
Im folgenden Beispiel wird der MS MARCO-Datensatz
{"_id": "1185869", "text": ")what was the immediate impact of the Paris Peace Treaties of 1947?", "metadata": {"world war 2"}} {"_id": "1185868", "text": "_________ justice is designed to repair the harm to victim, the community and the offender caused by the offender criminal act. question 19 options:", "metadata": {"law"}} {"_id": "597651", "text": "what is amber", "metadata": {"nothing"}} {"_id": "403613", "text": "is autoimmune hepatitis a bile acid synthesis disorder", "metadata": {"self immune"}} ...
Stellen Sie sich zum Testen mit dem MS MARCO-Datensatz ein Szenario vor, in dem Sie eine Milliarde Eingabeanforderungen erstellen, die auf 100 Dateien verteilt sind und jeweils 10 Millionen Anfragen enthalten. Die Dateien würden in Amazon S3 mit dem Präfix s3://offlinebatch/sagemaker/sagemaker_djl_batch_input/ gespeichert. Die OpenSearch Ingestion-Pipeline würde diese 100 Dateien gleichzeitig scannen und einen SageMaker Batch-Job mit 100 Mitarbeitern zur parallel Verarbeitung initiieren, was eine effiziente Vektorisierung und Aufnahme der eine Milliarde Dokumente ermöglicht. OpenSearch
In Produktionsumgebungen können Sie eine OpenSearch Ingestion-Pipeline verwenden, um S3-Dateien für die Batch-Inferenzeingabe zu generieren. Die Pipeline unterstützt verschiedene Datenquellen
Schritt 4: Überwachen Sie den Batch-Inferenzjob
Sie können die Batch-Inferenzjobs mit der SageMaker Konsole oder dem überwachen. AWS CLI Sie können auch die Get Task API verwenden, um Batch-Jobs zu überwachen:
GET /_plugins/_ml/tasks/_search { "query": { "bool": { "filter": [ { "term": { "state": "RUNNING" } } ] } }, "_source": ["model_id", "state", "task_type", "create_time", "last_update_time"] }
Die API gibt eine Liste der aktiven Batch-Job-Aufgaben zurück:
{ "took": 2, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 3, "relation": "eq" }, "max_score": 0.0, "hits": [ { "_index": ".plugins-ml-task", "_id": "nyWbv5EB_tT1A82ZCu-e", "_score": 0.0, "_source": { "model_id": "nyWbv5EB_tT1A82ZCu-e", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496527958, "last_update_time": 1725496527958 } }, { "_index": ".plugins-ml-task", "_id": "miKbv5EB_tT1A82ZCu-f", "_score": 0.0, "_source": { "model_id": "miKbv5EB_tT1A82ZCu-f", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496528123, "last_update_time": 1725496528123 } }, { "_index": ".plugins-ml-task", "_id": "kiLbv5EB_tT1A82ZCu-g", "_score": 0.0, "_source": { "model_id": "kiLbv5EB_tT1A82ZCu-g", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496529456, "last_update_time": 1725496529456 } } ] } }
Schritt 5: Suche ausführen
Nachdem Sie den Batch-Inferenzjob überwacht und bestätigt haben, dass er abgeschlossen ist, können Sie verschiedene Arten von KI-Suchen ausführen, darunter semantische, hybride, dialogorientierte (mit RAG), neuronale, spärliche und multimodale Suchen. Weitere Informationen zu KI-Suchen, die von OpenSearch Service unterstützt werden, finden Sie unter KI-Suche.
Verwenden Sie zur Suche nach Rohvektoren den knn Abfragetyp, geben Sie das vector Array als Eingabe an und geben Sie die k Anzahl der zurückgegebenen Ergebnisse an:
GET /my-raw-vector-index/_search { "query": { "knn": { "my_vector": { "vector": [0.1, 0.2, 0.3], "k": 2 } } } }
Verwenden Sie den neural Abfragetyp, um eine KI-gestützte Suche auszuführen. Geben Sie die query_text Eingabe, die model_id des Einbettungsmodells, das Sie in der OpenSearch Ingestion-Pipeline konfiguriert haben, und die k Anzahl der zurückgegebenen Ergebnisse an. Um Einbettungen aus den Suchergebnissen auszuschließen, geben Sie den Namen des Einbettungsfeldes im Parameter an: _source.excludes
GET /my-ai-search-index/_search { "_source": { "excludes": [ "output_embedding" ] }, "query": { "neural": { "output_embedding": { "query_text": "What is AI search?", "model_id": "mBGzipQB2gmRjlv_dOoB", "k": 2 } } } }
