Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Automatische semantische Anreicherung für Serverless
-Übersicht
Die automatische Funktion zur semantischen Anreicherung kann dazu beitragen, die Suchrelevanz gegenüber der lexikalischen Suche um bis zu 20% zu verbessern. Durch die automatische semantische Anreicherung entfällt der undifferenzierte Aufwand, der mit der Verwaltung Ihrer eigenen ML-Modellinfrastruktur (maschinelles Lernen) und der Integration in die Suchmaschine verbunden ist. Die Funktion ist für alle drei serverlosen Erfassungstypen verfügbar: Search, Time Series und Vector.
Konzepte der semantischen Suche
Herkömmliche Suchmaschinen setzen bei der Suche nach Ergebnissen für Suchanfragen auf einen Wort-zu-Wort-Abgleich (die so genannte lexikalische Suche). Diese Methode eignet sich zwar gut für spezifische Suchanfragen wie Modellnummern von Fernsehgeräten, liefert aber bei abstrakteren Suchanfragen möglicherweise keine relevanten Ergebnisse. Wenn Sie beispielsweise nach „Strandschuhen“ suchen, werden bei einer lexikalischen Suche lediglich einzelne Wörter wie „Schuhe“, „Strand“, „für“ und „der“ in Katalogartikeln gefunden, sodass möglicherweise relevante Produkte wie „wasserfeste Sandalen“ oder „Surfschuhe“ fehlen, die nicht die genauen Suchbegriffe enthalten.
Die semantische Suche gibt Abfrageergebnisse zurück, die nicht nur die Suche nach Schlüsselwörtern, sondern auch die Absicht und die kontextuelle Bedeutung der Suche des Benutzers berücksichtigen. Wenn ein Benutzer beispielsweise nach „Wie behandelt man Kopfschmerzen“ sucht, gibt ein semantisches Suchsystem möglicherweise die folgenden Ergebnisse zurück:
-
Mittel gegen Migräne
-
Techniken zur Schmerzbehandlung
-
Over-the-counter Schmerzmittel
Modelldetails und Leistungsbenchmark
Diese Funktion bewältigt zwar die technische Komplexität hinter den Kulissen, ohne das zugrunde liegende Modell zu enthüllen, aber die folgende Modellbeschreibung und die Benchmark-Ergebnisse helfen Ihnen, fundierte Entscheidungen über die Einführung von Funktionen bei Ihren kritischen Workloads zu treffen.
Bei der automatischen semantischen Anreicherung wird ein vom Service verwaltetes, vorab trainiertes Sparse-Modell verwendet, das effektiv funktioniert, ohne dass eine individuelle Feinabstimmung erforderlich ist. Das Modell analysiert die von Ihnen angegebenen Felder und erweitert sie auf der Grundlage von erlernten Assoziationen aus verschiedenen Trainingsdaten zu spärlichen Vektoren. Die erweiterten Begriffe und ihre Signifikanzgewichte werden für einen effizienten Abruf im systemeigenen Lucene-Indexformat gespeichert. Wir haben diesen Prozess für den Modus „Nur Dokumente“ optimiert, bei dem die Kodierung nur
Bei der Leistungsvalidierung während der Merkmalsentwicklung wurde der MS MARCO-Datensatz
-
Englische Sprache — Verbesserung der Relevanz um 20% gegenüber der lexikalischen Suche. Außerdem wurde die Latenz der P90-Suche gegenüber der lexikalischen Suche um 7,7% gesenkt (BM25 ist 26 ms und die automatische semantische Anreicherung 24 ms).
-
Multi-lingual - Verbesserung der Relevanz gegenüber der lexikalischen Suche um 105%, wohingegen die Latenz bei der P90-Suche gegenüber der lexikalischen Suche um 38,4% zunahm (BM25 beträgt 26 ms und die automatische semantische Anreicherung 36 ms).
Da die einzelnen Workloads einzigartig sind, können Sie diese Funktion in Ihrer Entwicklungsumgebung anhand Ihrer eigenen Benchmarking-Kriterien bewerten, bevor Sie Entscheidungen zur Implementierung treffen.
Unterstützte Sprachen
Die Funktion unterstützt Englisch. Darüber hinaus unterstützt das Modell auch Arabisch, Bengali, Chinesisch, Finnisch, Französisch, Hindi, Indonesisch, Japanisch, Koreanisch, Persisch, Russisch, Spanisch, Suaheli und Telugu.
Richten Sie einen automatischen Index zur semantischen Anreicherung für serverlose Sammlungen ein
Sie können bei der Erstellung eines neuen Indexes über die Konsole, APIs und CloudFormation Vorlagen einen Index mit aktivierter automatischer semantischer Anreicherung für Ihre Textfelder einrichten. Um ihn für einen vorhandenen Index zu aktivieren, müssen Sie den Index mit aktivierter automatischer semantischer Anreicherung für Textfelder neu erstellen.
Mit der AWS Konsole können Sie einen Index mit Feldern für die automatische semantische Anreicherung erstellen. Nachdem Sie eine Sammlung ausgewählt haben, finden Sie oben in der Konsole die Schaltfläche Index erstellen. Nachdem Sie Index erstellen ausgewählt haben, bietet die Konsole Optionen zur Definition von Feldern für die automatische semantische Anreicherung. In einem Index können Sie Kombinationen aus automatischer semantischer Anreicherung für Englisch und Mehrsprachigkeit sowie lexikalische Felder verwenden.
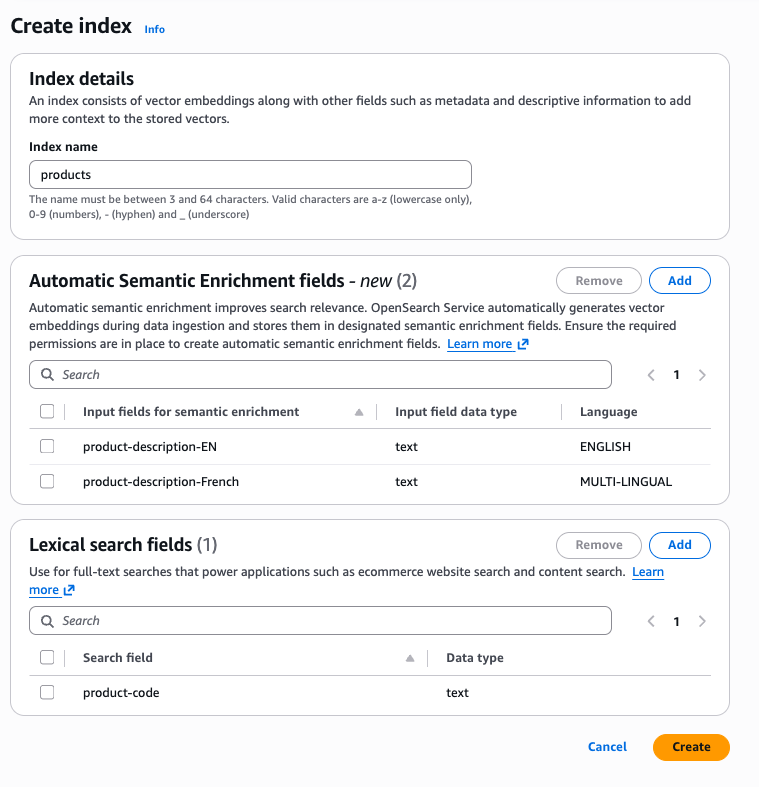
Verwenden Sie den Befehl create-index, um mit der AWS Befehlszeilenschnittstelle (AWS CLI) einen automatischen Index zur semantischen Anreicherung zu erstellen:
aws opensearchserverless create-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body] \
Im folgenden Beispiel für ein Indexschema ist für das title_semantic Feld der Feldtyp auf gesetzt text und der Parameter ist auf Status gesetzt. semantic_enrichment ENABLED Das Setzen des semantic_enrichment Parameters ermöglicht die automatische semantische Anreicherung des Felds. title_semantic Sie können das language_options Feld verwenden, um entweder oder english anzugeben. multi-lingual
aws opensearchserverless create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Verwenden Sie den folgenden Befehl, um den erstellten Index zu beschreiben:
aws opensearchserverless get-index \ --id [collection_id] \ --index-name [index_name] \
Sie können auch CloudFormation Vorlagen (Type:AWS:::OpenSearchServerless:CollectionIndex) verwenden, um eine semantische Suche sowohl während der Sammlungsbereitstellung als auch nach der Erstellung der Sammlung zu erstellen.
Aktualisieren Sie einen vorhandenen Index
Sie können einen vorhandenen Index aktualisieren, um neue Felder zur semantischen Anreicherung hinzuzufügen, die semantische Anreicherung für bestehende Felder zu aktivieren oder zu deaktivieren oder nicht semantische Textfelder hinzuzufügen. Verwenden Sie den update-index Befehl und geben Sie nur die Felder an, die Sie ändern möchten. index-schema Felder, die nicht in der Anfrage enthalten sind, bleiben unverändert.
Anmerkung
Der Index settings kann nicht aktualisiert werden. Wenn Sie einen settings Block in die Anforderung aufnehmen, gibt der Vorgang einen Validierungsfehler zurück. Um die Indexeinstellungen zu ändern, müssen Sie den Index löschen und neu erstellen.
Um einen Index mit dem zu aktualisieren AWS CLI, verwenden Sie den update-index folgenden Befehl:
aws opensearchserverless update-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body]
Fügen Sie ein neues Feld zur semantischen Anreicherung hinzu
Sie können ein neues text Feld mit aktivierter semantischer Anreicherung zu einem vorhandenen Index hinzufügen. Der Dienst richtet automatisch das erforderliche ML-Modell, die Ingest-Pipeline und die Suchpipeline ein. Neue Dokumente, die nach dem Update indexiert wurden, werden automatisch angereichert.
Wichtig
Bestehende Dokumente werden nicht aufgefüllt. Um das Feld für die semantische Anreicherung vorhandener Dokumente auszufüllen, müssen Sie sie nach der Aktualisierung erneut aufnehmen. Bestehende Dokumente profitieren nicht von der semantischen Suche in dem neuen Feld, solange sie nicht erneut aufgenommen wurden.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Deaktivieren Sie die semantische Anreicherung für ein Feld
Um die semantische Anreicherung für ein Feld zu deaktivieren, für das sie derzeit aktiviert ist, setzen Sie auf. status DISABLED Das Feld wird aus den Ingest- und Such-Pipelines entfernt. Das zugrunde liegende Textfeld und das zugehörige Einbettungsfeld verbleiben im Index, werden aber nicht mehr erweitert.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Einschränkungen aktualisieren
Die folgenden Operationen werden von nicht unterstützt update-index und erfordern, dass Sie den Index löschen und neu erstellen:
-
Änderung
language_optionseines Felds, für das derzeit die semantische Anreicherung aktiviert ist. Deaktivieren Sie zuerst das Feld und aktivieren Sie es dann erneut mit der neuen Sprachoption. -
Verschachtelte Felder werden aktualisiert. Semantische Anreicherung wird nur für Felder der obersten Ebene unterstützt.
text -
Der Index wird aktualisiert.
settings
Anmerkung
Wenn der Index über eine benutzerdefinierte Aufnahme- oder Suchpipeline verfügt, die nicht durch automatische semantische Anreicherung erstellt wurde, wird der Aktualisierungsvorgang blockiert. Entfernen Sie die benutzerdefinierte Pipeline, bevor Sie Felder für die semantische Anreicherung hinzufügen.
Datenaufnahme und Suche
Nachdem Sie einen Index mit aktivierter automatischer semantischer Anreicherung erstellt haben, funktioniert die Funktion während der Datenaufnahme automatisch, sodass keine zusätzliche Konfiguration erforderlich ist.
Datenaufnahme: Wenn Sie Dokumente zu Ihrem Index hinzufügen, geht das System automatisch wie folgt vor:
-
Analysiert die Textfelder, die Sie für die semantische Anreicherung vorgesehen haben
-
Generiert semantische Kodierungen mithilfe OpenSearch des vom Service verwalteten Sparse-Modells
-
Speichert diese angereicherten Repräsentationen zusammen mit Ihren Originaldaten
Bei diesem Prozess werden OpenSearch die integrierten ML-Konnektoren und Ingest-Pipelines verwendet, die im Hintergrund automatisch erstellt und verwaltet werden.
Suche: Die Daten zur semantischen Anreicherung sind bereits indexiert, sodass Abfragen effizient ausgeführt werden können, ohne das ML-Modell erneut aufrufen zu müssen. Das bedeutet, dass Sie eine verbesserte Suchrelevanz ohne zusätzlichen Aufwand für die Suchlatenz erhalten.
Konfiguration von Berechtigungen für die automatische semantische Anreicherung
Bevor Sie einen automatisierten Index für semantische Anreicherung erstellen, müssen Sie die erforderlichen Berechtigungen konfigurieren. In diesem Abschnitt werden die benötigten Berechtigungen und deren Einrichtung erläutert.
IAM-Richtlinienberechtigungen
Verwenden Sie die folgende AWS Identity and Access Management (IAM-) Richtlinie, um die erforderlichen Berechtigungen für die Arbeit mit der automatischen semantischen Anreicherung zu gewähren:
- Wichtige Berechtigungen
-
-
Die
aoss:*IndexBerechtigungen ermöglichen die Indexverwaltung -
Die
aoss:APIAccessAllErlaubnis ermöglicht OpenSearch API-Operationen -
Um die Berechtigungen auf eine bestimmte Sammlung zu beschränken,
"Resource": "*"ersetzen Sie sie durch den ARN der Sammlung
-
Konfigurieren Sie Datenzugriffsberechtigungen
Um einen Index für die automatische semantische Anreicherung einzurichten, benötigen Sie entsprechende Datenzugriffsrichtlinien, die Berechtigungen für den Zugriff auf Index-, Pipeline- und Modellerfassungsressourcen gewähren. Weitere Informationen zu Datenzugriffsrichtlinien finden Sie unter. Datenzugriffskontrolle für Amazon OpenSearch Serverless Das Verfahren zur Konfiguration einer Datenzugriffsrichtlinie finden Sie unterErstellen von Datenzugriffsrichtlinien (Konsole).
Datenzugriffsberechtigungen
[ { "Description": "Create index permission", "Rules": [ { "ResourceType": "index", "Resource": ["index/collection_name/*"], "Permission": [ "aoss:CreateIndex", "aoss:DescribeIndex", "aoss:UpdateIndex", "aoss:DeleteIndex" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create pipeline permission", "Rules": [ { "ResourceType": "collection", "Resource": ["collection/collection_name"], "Permission": [ "aoss:CreateCollectionItems", "aoss:DescribeCollectionItems" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create model permission", "Rules": [ { "ResourceType": "model", "Resource": ["model/collection_name/*"], "Permission": ["aoss:CreateMLResource"] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, ]
Zugriffsberechtigungen für das Netzwerk
Damit Service-APIs auf private Sammlungen zugreifen können, müssen Sie Netzwerkrichtlinien konfigurieren, die den erforderlichen Zugriff zwischen der Service-API und der Sammlung zulassen. Weitere Informationen zu Netzwerkrichtlinien finden Sie unter Netzwerkzugriff für Amazon OpenSearch Serverless.
[ { "Description":"Enable automatic semantic enrichment in a private collection", "Rules":[ { "ResourceType":"collection", "Resource":[ "collection/collection_name" ] } ], "AllowFromPublic":false, "SourceServices":[ "aoss.amazonaws.com" ], } ]
So konfigurieren Sie Netzwerkzugriffsberechtigungen für eine private Sammlung
-
Melden Sie sich bei der OpenSearch Servicekonsole an unter https://console.aws.amazon.com/aos/home
. -
Wählen Sie im linken Navigationsbereich Netzwerkrichtlinien aus. Führen Sie dann einen der folgenden Schritte aus:
-
Wählen Sie einen vorhandenen Richtliniennamen und klicken Sie auf Bearbeiten
-
Wählen Sie Netzwerkrichtlinie erstellen und konfigurieren Sie die Richtliniendetails
-
-
Wählen Sie im Bereich Zugriffstyp die Option Privat (empfohlen) und anschließend Privater AWS Dienstzugriff aus.
-
Wählen Sie im Suchfeld Service und dann aoss.amazonaws.com aus.
-
Aktivieren Sie im Bereich Ressourcentyp das Kontrollkästchen Zugriff auf Endpunkt aktivieren. OpenSearch
-
Wählen Sie für „Sammlung (en) durchsuchen“ oder geben Sie bestimmte Präfixausdrücke in das Suchfeld „Sammlungsname“ ein. Geben Sie dann den Namen der Sammlungen ein, die mit der Netzwerkrichtlinie verknüpft werden sollen, oder wählen Sie ihn aus.
-
Wählen Sie Erstellen für eine neue Netzwerkrichtlinie oder Aktualisieren für eine bestehende Netzwerkrichtlinie.
Die Abfrage wird neu geschrieben
Durch die automatische semantische Anreicherung werden Ihre vorhandenen „Match“ -Abfragen automatisch in semantische Suchanfragen umgewandelt, ohne dass Änderungen an der Abfrage erforderlich sind. Wenn eine Übereinstimmungsabfrage Teil einer zusammengesetzten Abfrage ist, durchsucht das System Ihre Abfragestruktur, findet Übereinstimmungsabfragen und ersetzt sie durch neuronale Abfragen mit geringer Dichte. Derzeit unterstützt die Funktion nur das Ersetzen von „Match“ -Abfragen, unabhängig davon, ob es sich um eine eigenständige Abfrage oder um einen Teil einer zusammengesetzten Abfrage handelt. „multi_match“ wird nicht unterstützt. Darüber hinaus unterstützt die Funktion alle zusammengesetzten Abfragen, um ihre verschachtelten Match-Abfragen zu ersetzen. Zu den zusammengesetzten Abfragen gehören: bool, boost, constant_score, dis_max, function_score und hybrid.
Einschränkungen der automatischen semantischen Anreicherung
Die automatische semantische Suche ist am effektivsten, wenn sie auf kleine bis mittelgroße Felder angewendet wird, die Inhalte in natürlicher Sprache enthalten, wie Filmtitel, Produktbeschreibungen, Rezensionen und Zusammenfassungen. Die semantische Suche erhöht zwar die Relevanz für die meisten Anwendungsfälle, ist aber für bestimmte Szenarien möglicherweise nicht optimal. Beachten Sie die folgenden Einschränkungen, wenn Sie entscheiden, ob Sie die automatische semantische Anreicherung für Ihren speziellen Anwendungsfall implementieren möchten.
-
Sehr lange Dokumente — Das aktuelle Sparse-Modell verarbeitet nur die ersten 8.192 Tokens jedes Dokuments für Englisch. Bei mehrsprachigen Dokumenten sind es 512 Token. Bei längeren Artikeln sollten Sie die Implementierung von Dokumentenabschnitten in Betracht ziehen, um eine vollständige Inhaltsverarbeitung sicherzustellen.
-
Workloads bei der Protokollanalyse — Semantische Anreicherung erhöht die Indexgröße erheblich, was für Protokollanalysen, bei denen eine exakte Übereinstimmung in der Regel ausreicht, unnötig sein könnte. Der zusätzliche semantische Kontext verbessert die Effektivität der Protokollsuche selten ausreichend, um die erhöhten Speicheranforderungen zu rechtfertigen.
-
Die automatische semantische Anreicherung ist nicht mit der Funktion „Abgeleitete Quellen“ kompatibel.
Preisgestaltung
Amazon OpenSearch Service berechnet die automatische semantische Anreicherung auf der Grundlage der OpenSearch Recheneinheiten (OCUs), die bei der Generierung von spärlichen Vektoren zum Zeitpunkt der Indexierung verbraucht wurden. Ihnen wird nur die tatsächliche Nutzung während der Indexierung für die Textfelder in Rechnung gestellt, für die Sie die automatische semantische Anreicherung aktiviert haben. Eine OCU für semantische Suche kann 11,1 Millionen Token für englische Inhalte verarbeiten. Um 2,4 Milliarden Token zu verarbeiten, benötigen Sie etwa 216 Semantic Search OCU-hours (2,4 Milliarden/11,10 Millionen). Bei einem Preis von 0,24$ pro semantischer Suche OCU-hour würden sich die Kosten für die Verarbeitung von 10 GB an Daten für die automatische semantische Suche auf 51$ (216 x 0$) belaufen. OCU-hours 24/OCU-Stunde). Es fallen keine zusätzlichen OCU-Gebühren für die semantische Suche während Suchvorgängen oder für die Datenspeicherung an.
Sie können diesen Verbrauch mithilfe der CloudWatch Amazon-Metrik überwachenSemanticSearchOCU. Spezifische Informationen zu den Limits für Modell-Tokens, zum Volumendurchsatz pro OCU und ein Beispiel für eine Beispielberechnung finden Sie unter OpenSearch Servicepreise
