Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Trainieren eines Modells
In diesem Schritt wählen Sie einen Trainingsalgorithmus aus und führen einen Trainingsjob für das Modell aus. Das Amazon SageMaker Python SDK
Auswählen des Trainingsalgorithmus
Um den richtigen Algorithmus für Ihren Datensatz auszuwählen, müssen Sie in der Regel verschiedene Modelle auswerten, um die für Ihre Daten am besten geeigneten Modelle zu finden. Der Einfachheit halber wird in diesem Tutorial der XGBoost-Algorithmus mit Amazon AI SageMaker integrierte SageMaker KI-Algorithmus verwendet, ohne dass Modelle vorab evaluiert werden müssen.
Tipp
Wenn Sie möchten, dass SageMaker KI ein geeignetes Modell für Ihren tabellarischen Datensatz findet, verwenden Sie Amazon SageMaker Autopilot, das eine Machine-Learning-Lösung automatisiert. Weitere Informationen finden Sie unter SageMaker Autopilot.
Erstellen und Ausführen eines Trainingsauftrags
Nachdem Sie herausgefunden haben, welches Modell Sie verwenden sollen, beginnen Sie mit der Erstellung eines SageMaker KI-Schätzers für das Training. In diesem Tutorial wird der integrierte XGBoost-Algorithmus für den generischen KI-Schätzer verwendet. SageMaker
So führen Sie einen Modelltrainingsauftrag aus
-
Importieren Sie das Amazon SageMaker Python SDK
und rufen Sie zunächst die Basisinformationen aus Ihrer aktuellen SageMaker KI-Sitzung ab. import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Dies gibt folgende Informationen zurück:
-
region— Die aktuelle AWS Region, in der die SageMaker AI-Notebook-Instance ausgeführt wird. -
role– Die von der Notebook-Instance verwendete IAM-Rolle.
Anmerkung
Überprüfen Sie die SageMaker Python-SDK-Version, indem Sie Folgendes ausführen
sagemaker.__version__. Dieses Tutorial basiert aufsagemaker>=2.20. Wenn das SDK veraltet ist, installieren Sie die neueste Version, indem Sie den folgenden Befehl ausführen:! pip install -qU sagemakerWenn Sie diese Installation in Ihren bestehenden SageMaker Studio- oder Notebook-Instanzen ausführen, müssen Sie den Kernel manuell aktualisieren, um die Installation des Versionsupdates abzuschließen.
-
-
Erstellen Sie mithilfe der
sagemaker.estimator.EstimatorKlasse einen XGBoost-Schätzer. Im folgenden Beispielcode wird der XGBoost-Schätzerxgb_modelbenannt.from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Um den SageMaker AI-Schätzer zu erstellen, geben Sie die folgenden Parameter an:
-
image_uri– Geben Sie den Image-URI des Trainingscontainers an. In diesem Beispiel wird der SageMaker AI XGBoost-Trainingscontainer-URI mit angegeben.sagemaker.image_uris.retrieve -
role— Die AWS Identity and Access Management (IAM-) Rolle, die SageMaker KI verwendet, um Aufgaben in Ihrem Namen auszuführen (z. B. Trainingsergebnisse lesen, Modellartefakte von Amazon S3 aufrufen und Trainingsergebnisse in Amazon S3 schreiben). -
instance_countundinstance_type– Typ und Anzahl der für das Modelltraining zu verwendenden Amazon-EC2-ML-Compute-Instances. Für diese Trainingsübung verwenden Sie eine einzelneml.m4.xlargeInstance mit 4 CPUs, 16 GB Arbeitsspeicher, einem Amazon Elastic Block Store (Amazon EBS)-Speicher und einer hohen Netzwerkleistung. Weitere Informationen zu EC2-Rechen-Instance-Typen finden Sie unter Amazon-EC2-Instance-Typen. Weitere Informationen zur Abrechnung finden Sie unter SageMaker Amazon-Preise . -
volume_size– Die Größe des EBS-Speichervolumens (in GB), das an das Trainings-Instance angefügt werden soll. Diese muss groß genug sein, um Trainingsdaten speichern zu können, wenn Sie denFile-Modus verwenden (derFile-Modus ist der Standardwert). Wenn Sie diesen Parameter nicht angeben, ist sein Wert standardmäßig 30. -
output_path— Der Pfad zum S3-Bucket, in dem SageMaker KI das Modellartefakt und die Trainingsergebnisse speichert. -
sagemaker_session— Das Sitzungsobjekt, das Interaktionen mit SageMaker API-Vorgängen und anderen AWS Diensten verwaltet, die der Trainingsjob verwendet. -
rules— Geben Sie eine Liste der integrierten SageMaker Debugger-Regeln an. In diesem Beispiel erstellt diecreate_xgboost_report()Regel einen XGBoost-Bericht, der Einblicke in den Trainingsfortschritt und die Ergebnisse bietet, und dieProfilerReport()Regel erstellt einen Bericht über die Nutzung der EC2-Rechenressourcen. Weitere Informationen finden Sie unter SageMaker Interaktiver Debugger-Bericht für XGBoost.
Tipp
Wenn Sie ein verteiltes Training von großen Deep-Learning-Modellen wie Convolutional Neural Networks (CNN) und Natural Language Processing (NLP) -Modellen (Natural Language Processing) durchführen möchten, verwenden Sie SageMaker AI Distributed für Daten- oder Modellparallelität. Weitere Informationen finden Sie unter Verteilte Schulungen in Amazon SageMaker AI.
-
-
Legen Sie die Hyperparameterwerte für den XGBoost-Algorithums fest, indem Sie die
set_hyperparameters-Methode des Schätzers aufrufen. Eine vollständige Liste der XGBoost-Hyperparameter finden Sie unter XGBoost-Hyperparameter.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )Tipp
Sie können die Hyperparameter auch mithilfe der AI-Hyperparameter-Optimierungsfunktion optimieren. SageMaker Weitere Informationen finden Sie unter Automatische Modelloptimierung mit KI SageMaker.
-
Verwenden Sie die
TrainingInputKlasse, um einen Dateneingabefluss für das Training zu konfigurieren. Der folgende Beispielcode zeigt, wie SieTrainingInputObjekte für die Verwendung der Trainings- und Validierungsdatensätze konfigurieren, die Sie im Teilen Sie den Datensatz in Trainings-, Validierungs- und Testdatensätze auf Abschnitt auf Amazon S3 hochgeladen haben.from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Um das Modelltraining zu starten, rufen Sie die
fitMethode des Schätzers mit den Trainings- und Validierungsdatensätzen auf. Wenn Siewait=Trueeinstellen, zeigt diefitMethode Fortschrittsprotokolle an und wartet, bis das Training abgeschlossen ist.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Weitere Informationen zum Modelltraining finden Sie unter Trainiere ein Modell mit Amazon SageMaker. Dieser Tutorial-Trainingsjob kann bis zu 10 Minuten dauern.
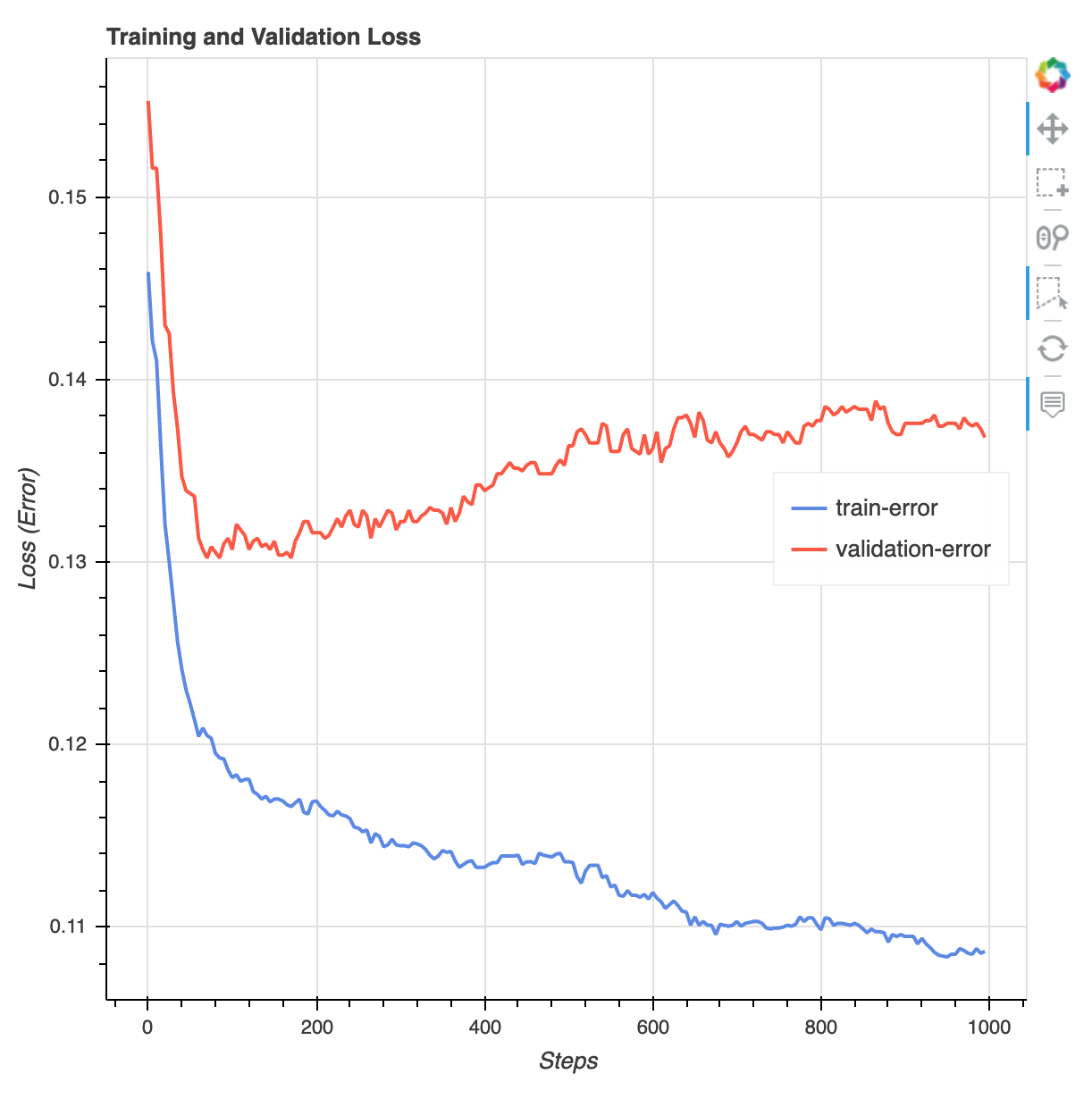
Nach Abschluss des Trainingsjobs können Sie einen XGBoost-Trainingsbericht und einen vom Debugger generierten Profilerstellungsbericht herunterladen. SageMaker Der XGBoost-Trainingsbericht bietet Ihnen Einblicke in den Trainingsfortschritt und die Ergebnisse, z. B. die Verlustfunktion in Bezug auf die Iteration, die Bedeutung der Merkmale, die Konfusionsmatrix, Genauigkeitskurven und andere statistische Ergebnisse des Trainings. Im XGBoost-Trainingsbericht finden Sie zum Beispiel die folgende Verlustkurve, die deutlich darauf hinweist, dass ein Überfitnessproblem vorliegt.
Führen Sie den folgenden Code aus, um den S3-Bucket-URI anzugeben, unter dem die Debugger-Trainingsberichte generiert werden, und überprüfen Sie, ob die Berichte vorhanden sind.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveLaden Sie die Debugger-XGBoost-Trainings- und Profilerstellungsberichte in den aktuellen Workspace herunter:
! aws s3 cp {rule_output_path} ./ --recursiveFühren Sie das folgende IPython-Skript aus, um den Dateilink des XGBoost-Trainingsberichts abzurufen:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))Das folgende IPython-Skript gibt den Dateilink des Debugger-Profilerstellungsberichts zurück, der Zusammenfassungen und Details zur Ressourcenauslastung der EC2-Instance, zu den Ergebnissen der Erkennung von Systemengpässen und zur Profilerstellung für Python-Operationen enthält:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))Tipp
Wenn die HTML-Berichte in der JupyterLab Ansicht keine Diagramme rendern, müssen Sie oben in den Berichten die Option HTML vertrauen auswählen.
Um Trainingsprobleme wie Überanpassung, verschwindende Gradienten und andere Probleme zu identifizieren, die die Konvergenz Ihres Modells verhindern, verwenden Sie den SageMaker Debugger und ergreifen Sie automatisierte Maßnahmen, während Sie Prototypen erstellen und Ihre ML-Modelle trainieren. Weitere Informationen finden Sie unter SageMaker Amazon-Debugger. Eine vollständige Analyse der Modellparameter finden Sie im Beispielnotizbuch Explainability with Amazon SageMaker Debugger
.
Sie haben jetzt ein trainiertes XGBoost-Modell. SageMaker AI speichert das Modellartefakt in Ihrem S3-Bucket. Um die Position des Modellartefakts zu ermitteln, führen Sie den folgenden Code aus, um das model_data-Attribut des xgb_model Schätzers auszudrucken:
xgb_model.model_data
Tipp
Verwenden SageMaker Sie Clarify, um Verzerrungen zu messen, die in jeder Phase des ML-Lebenszyklus (Datenerfassung, Modelltraining und -optimierung sowie Überwachung von ML-Modellen, die zur Vorhersage eingesetzt werden) auftreten können. Weitere Informationen finden Sie unter Erklärbarkeit des Modells. Ein ausführliches Beispiel finden Sie im Beispielnotizbuch Fairness and Explainability with SageMaker
