Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einrichtung von Trainingsjobs für den Zugriff auf Datensätze
Wenn Sie einen Trainingsjob erstellen, geben Sie den Speicherort von Trainingsdatensätzen in einem Datenspeicher Ihrer Wahl und den Dateneingabemodus für den Job an. Amazon SageMaker AI unterstützt Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) und Amazon FSx for Lustre. Sie können einen der Eingabemodi wählen, um den Datensatz in Echtzeit zu streamen oder den gesamten Datensatz zu Beginn des Trainingsjobs herunterzuladen.
Anmerkung
Ihr Datensatz muss sich im selben Verzeichnis befinden AWS-Region wie der Ausbildungsjob.
SageMaker KI-Eingabemodi und AWS Cloud-Speicheroptionen
Dieser Abschnitt bietet einen Überblick über die Dateieingabemodi, die von SageMaker für in Amazon EFS und Amazon FSx for Lustre gespeicherte Daten unterstützt werden.
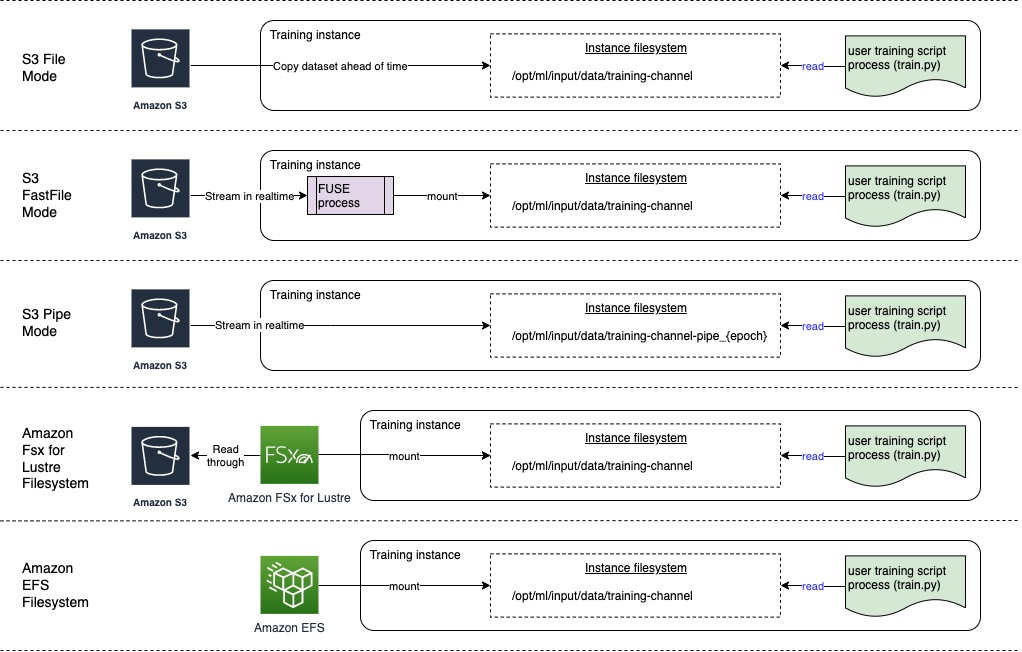
-
Im Dateimodus wird dem Trainingscontainer eine Dateisystemansicht des Datensatzes präsentiert. Dies ist der Standard-Eingabemodus, wenn Sie nicht explizit eine der beiden anderen Optionen angeben. Wenn Sie den Dateimodus verwenden, lädt SageMaker AI die Trainingsdaten vom Speicherort in ein lokales Verzeichnis im Docker-Container herunter. Das Training beginnt, nachdem der gesamte Datensatz heruntergeladen wurde. Im Dateimodus muss die Trainings-Instance über genügend Speicherplatz für den gesamten Datensatz verfügen. Die Downloadgeschwindigkeit im Dateimodus hängt von der Größe des Datensatzes, der durchschnittlichen Größe der Dateien und der Anzahl der Dateien ab. Sie können den Datensatz für den Dateimodus konfigurieren, indem Sie entweder ein Amazon S3-Präfix, eine Manifestdatei oder eine erweiterte Manifestdatei bereitstellen. Sie sollten ein S3-Präfix verwenden, wenn sich alle Ihre Datensatzdateien in einem gemeinsamen S3-Präfix befinden. Der Dateimodus ist mit dem lokalen SageMaker KI-Modus
kompatibel (interaktives Starten eines SageMaker Trainingscontainers innerhalb von Sekunden). Für verteiltes Training können Sie den Datensatz mit der ShardedByS3KeyOption auf mehrere Instances verteilen. -
Der schnelle Dateimodus bietet Dateisystemzugriff auf eine Amazon S3-Datenquelle und nutzt gleichzeitig den Leistungsvorteil des Pipe-Modus. Zu Beginn des Trainings identifiziert der schnelle Dateimodus die Datendateien, lädt sie jedoch nicht herunter. Das Training kann beginnen, ohne auf das Herunterladen des gesamten Datensatzes zu warten. Das bedeutet, dass der Trainingsstart weniger Zeit in Anspruch nimmt, wenn weniger Dateien im bereitgestellten Amazon S3-Präfix vorhanden sind.
Im Gegensatz zum Pipe-Modus arbeitet der schnelle Dateimodus mit zufälligem Zugriff auf die Daten. Er funktioniert jedoch am besten, wenn Daten sequentiell gelesen werden. Der schnelle Dateimodus unterstützt keine erweiterten Manifestdateien.
Im schnellen Dateimodus werden S3-Objekte über eine POSIX-compliant Dateisystemschnittstelle verfügbar gemacht, als ob die Dateien auf der lokalen Festplatte Ihrer Trainingsinstanz verfügbar wären. Er streamt S3-Inhalte bei Bedarf, während Ihr Trainingsskript Daten verbraucht. Das bedeutet, dass Ihr Datensatz nicht mehr als Ganzes in den Speicherplatz der Trainings-Instance passen muss, und Sie müssen nicht warten, bis der Datensatz in die Trainings-Instance heruntergeladen wurde, bevor das Training beginnt. Der schnelle Dateimodus unterstützt derzeit nur S3-Präfixe (Manifest und erweitertes Manifest werden nicht unterstützt). Der schnelle Dateimodus ist mit dem lokalen SageMaker AI-Modus kompatibel.
Anmerkung
Die Verwendung des Fast File-Modus kann zu erhöhten CloudTrail Kosten führen, da Folgendes zusätzlich protokolliert wird:
-
Amazon S3 S3-Datenereignisse (falls aktiviert in CloudTrail).
-
AWS KMS Entschlüsselungsereignisse beim Zugriff auf Amazon S3 S3-Objekte, die mit AWS KMS Schlüsseln verschlüsselt sind.
-
Verwaltungsereignisse im Zusammenhang mit AWS KMS Vorgängen.
Prüfen Sie Ihre Kosten für CloudTrail Konfiguration und Überwachung, wenn Sie die CloudTrail Protokollierung für diese Ereignistypen aktiviert haben.
-
-
Der Pipe-Modus streamt Daten direkt von einer Amazon S3-Datenquelle. Das Streamen kann schnellere Startzeiten und einen besseren Durchsatz als der Dateimodus bieten.
Wenn Sie die Daten direkt streamen, können Sie die Größe der von der Trainings-Instance verwendeten Amazon EBS-Volumes reduzieren. Der Pipe-Modus benötigt nur so viel Speicherplatz, dass die endgültigen Modellartefakte gespeichert werden können.
Dies ist ein weiterer Streaming-Modus, der weitgehend durch den neueren und einfacher zu bedienenden schnellen Dateimodus ersetzt wird. Im Pipe-Modus werden Daten mit hoher Parallelität und hohem Durchsatz vorab von Amazon S3 abgerufen und in eine Named Pipe gestreamt, die aufgrund ihres Verhaltens auch als First-In-First-Out (FIFO) -Pipe bezeichnet wird. Jede Pipe darf nur von einem einzigen Prozess gelesen werden. Eine SageMaker KI-spezifische Erweiterung zur TensorFlow bequemen Integration des Pipe-Modus in den nativen TensorFlow Datenlader
für Streaming-Text-, TFRecords- oder RecordIo-Dateiformate. Der Pipe-Modus unterstützt auch verwaltetes Sharding und Shuffling von Daten. -
Amazon S3 Express One Zone ist eine leistungsstarke Speicherklasse mit einer einzigen Availability Zone, die einen konsistenten Datenzugriff im einstelligen Millisekundenbereich für die latenzempfindlichsten Anwendungen, einschließlich Modelltraining, ermöglicht. SageMaker Amazon S3 Express One Zone ermöglicht es Kunden, ihre Objektspeicher- und Rechenressourcen in einer einzigen AWS Availability Zone zusammenzufassen und so sowohl die Rechenleistung als auch die Kosten bei erhöhter Datenverarbeitungsgeschwindigkeit zu optimieren. Um die Zugriffsgeschwindigkeit weiter zu erhöhen und Hunderttausende von Anfragen pro Sekunde zu unterstützen, werden Daten in einem neuen Bucket-Typ gespeichert: einem Amazon-S3-Verzeichnis-Bucket.
SageMaker Das KI-Modelltraining unterstützt leistungsstarke Amazon S3 Express One Zone-Verzeichnis-Buckets als Dateneingabeort für den Dateimodus, den Schnelldateimodus und den Pipe-Modus. Um Amazon S3 Express One Zone zu verwenden, geben Sie den Speicherort des Verzeichnis-Buckets von Amazon S3 Express One Zone anstelle eines Amazon-S3-Buckets ein. Stellen Sie den ARN für die IAM-Rolle mit den erforderlichen Zugriffskontroll- und Berechtigungsrichtlinien bereit. Weitere Einzelheiten finden Sie unter AmazonSageMakerFullAccesspolicy. Sie können Ihre SageMaker KI-Ausgabedaten in Verzeichnis-Buckets nur mit serverseitiger Verschlüsselung mit verwalteten Amazon S3 S3-Schlüsseln () verschlüsseln. SSE-S3 Server-side Die Verschlüsselung mit AWS KMS Schlüsseln (SSE-KMS) wird derzeit nicht für das Speichern von SageMaker KI-Ausgabedaten in Verzeichnis-Buckets unterstützt. Weitere Informationen finden Sie unter Amazon S3 Express One Zone.
-
Amazon FSx für Lustre – FSx für Lustre kann auf Hunderte von Gigabyte Durchsatz und Millionen von IOPS skaliert werden und bietet Dateiabruf mit niedriger Latenz. Wenn Sie einen Trainingsjob starten, hängt SageMaker KI das Dateisystem FSx for Lustre in das Dateisystem der Trainingsinstanz ein und startet dann Ihr Trainingsskript. Das Mounten selbst ist ein relativ schneller Vorgang, der nicht von der Größe des in FSx for Lustre gespeicherten Datensatzes abhängt.
Um auf FSx for Lustre zugreifen zu können, muss Ihr Schulungsjob eine Verbindung zu einer Amazon Virtual Private Cloud (VPC) herstellen, was eine DevOps Einrichtung und Teilnahme erfordert. Um Datenübertragungskosten zu vermeiden, verwendet das Dateisystem eine einzige Availability Zone, und Sie müssen ein VPC-Subnetz angeben, das dieser Availability Zone ID zugeordnet ist, wenn Sie einen Trainingsauftrag ausführen.
-
Amazon EFS — Um Amazon EFS als Datenquelle verwenden zu können, müssen sich die Daten vor dem Training bereits in Amazon EFS befinden. SageMaker AI mountet das angegebene Amazon EFS-Dateisystem in die Trainingsinstanz und startet dann Ihr Trainingsskript. Ihr Trainingsauftrag muss sich mit einer VPC verbinden, um auf Amazon EFS zugreifen zu können.
Tipp
Weitere Informationen zur Spezifizierung Ihrer VPC-Konfiguration für SageMaker KI-Schätzer finden Sie unter Verwenden von Dateisystemen als Trainingseingaben
in der SageMaker AI Python SDK-Dokumentation.
