Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Multi-model Endpunkte
Multi-model Endgeräte bieten eine skalierbare und kostengünstige Lösung für die Bereitstellung einer großen Anzahl von Modellen. Sie verwenden dieselbe Flotte von Ressourcen und einen gemeinsamen Server-Container, um alle Ihre Modelle zu hosten. Dies reduziert Hosting-Kosten, indem die Endpunktauslastung gegenüber der Verwendung von Einzelmodell-Endpunkten verbessert wird. Es reduziert auch den Bereitstellungsaufwand, da Amazon SageMaker AI das Laden von Modellen im Speicher und deren Skalierung auf der Grundlage der Datenverkehrsmuster zu Ihrem Endpunkt verwaltet.
Das folgende Diagramm zeigt, wie Multimodell-Endpunkte im Vergleich zu Einzelmodell-Endpunkten funktionieren.
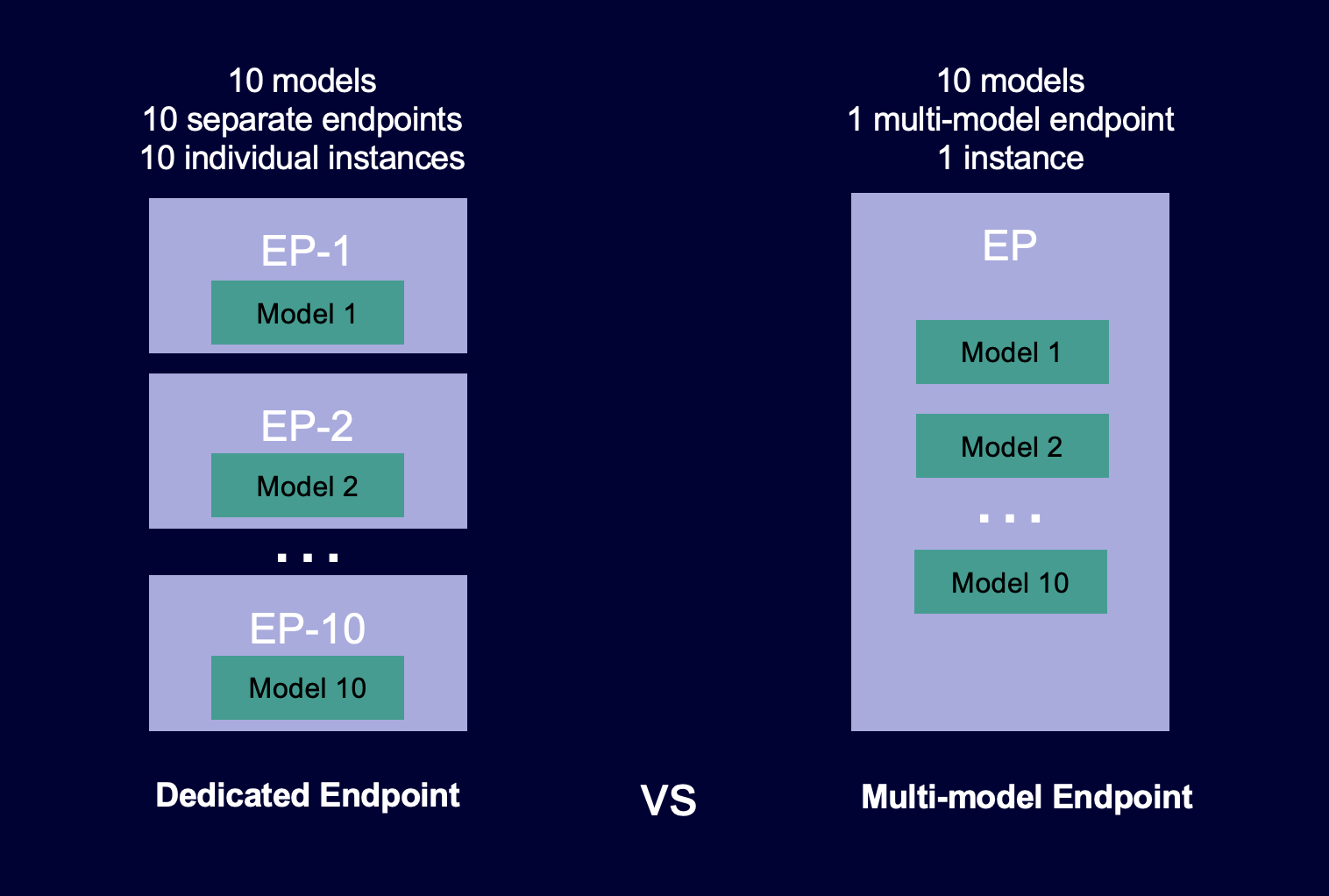
Multi-model Endgeräte eignen sich ideal für das Hosten einer großen Anzahl von Modellen, die dasselbe ML-Framework auf einem gemeinsam genutzten Serving-Container verwenden. Wenn Sie eine Mischung von Modellen haben, auf die häufig bzw. selten zugegriffen wird, kann ein Multimodell-Endpunkt diesen Datenverkehr mit weniger Ressourcen und höheren Kosteneinsparungen effizient bedienen. Ihre Anwendung sollte gelegentlich auftretende Latenzeinbußen im durch Kaltstarts tolerieren, die beim Aufrufen selten verwendeter Modelle auftreten.
Multi-model Endgeräte unterstützen das Hosten von Modellen mit CPU- und GPU-Unterstützung. Durch die Verwendung von GPU-gestützten Modellen können Sie die Kosten für die Modellbereitstellung senken, indem Sie den Endpunkt und die zugrunde liegenden beschleunigten Cpmputing-Instances stärker auslasten.
Multi-model Endpunkte ermöglichen auch die gemeinsame Nutzung von Speicherressourcen zwischen Ihren Modellen. Dies funktioniert am besten, wenn die Modelle in Größe und Aufruflatenz recht ähnlich sind. In diesem Fall können Multimodell-Endpunkte Instances effektiv über alle Modelle hinweg verwenden. Wenn Sie Modelle mit deutlich höheren Transaktionen pro Sekunde (TPS) oder Latenzanforderungen haben, empfehlen wir Ihnen, diese auf dedizierten Endpunkten zu hosten.
Sie können Multimodell-Endpunkte mit den folgenden Features verwenden:
-
AWS PrivateLinkund VPCs
-
Serielle Inference Pipelines (es kann jedoch nur ein multimodell-fähiger Container in einer Inference-Pipeline enthalten sein)
-
A/B testen
Sie können die AWS SDK für Python (Boto) oder die SageMaker AI-Konsole verwenden, um einen Endpunkt mit mehreren Modellen zu erstellen. Für CPU-gestützte Multimodell-Endpunkte können Sie Ihren Endpunkt mit benutzerdefinierten Containern erstellen, indem Sie die Multimodell-Server
Themen
Unterstützte Algorithmen, Frameworks und Instances für Multimodell-Endpunkte
Instance-Empfehlungen für Bereitstellungen von Multimodell-Endpunkten
Erstellen Sie Ihren eigenen Container für SageMaker KI-Endpunkte Multi-Model
CloudWatch Metriken für Multi-Model Endpunktbereitstellungen
Legen Sie das SageMaker Caching-Verhalten für KI-Endpunktmodelle mit mehreren Modellen fest
Auto Scaling Scaling-Richtlinien für Multi-Model Endpunktbereitstellungen festlegen
Funktionsweise von Multimodell-Endpunkten
SageMaker KI verwaltet den Lebenszyklus von Modellen, die auf Endpunkten mit mehreren Modellen im Speicher des Containers gehostet werden. Anstatt alle Modelle von einem Amazon S3 S3-Bucket in den Container herunterzuladen, wenn Sie den Endpunkt erstellen, lädt SageMaker KI sie dynamisch und speichert sie im Cache, wenn Sie sie aufrufen. Wenn SageMaker AI eine Aufrufanfrage für ein bestimmtes Modell erhält, geht sie wie folgt vor:
-
Er leitet die Anforderung an eine Instance hinter dem Endpunkt weiter.
-
Er lädt das Modell aus dem S3-Bucket auf das Speicher-Volume dieser Instance herunter.
-
Lädt das Modell in den Speicher des Containers (CPU oder GPU, je nachdem, ob Sie über CPU- oder GPU-gestützte Instances verfügen) auf dieser beschleunigten Computing-Instance. Wenn das Modell bereits im Speicher des Containers geladen ist, ist der Aufruf schneller, da SageMaker KI es nicht herunterladen und laden muss.
SageMaker KI leitet Anfragen für ein Modell weiterhin an die Instanz weiter, in der das Modell bereits geladen ist. Wenn das Modell jedoch viele Aufrufanfragen empfängt und es zusätzliche Instanzen für den Endpunkt mit mehreren Modellen gibt, leitet SageMaker KI einige Anfragen an eine andere Instanz weiter, um den Datenverkehr zu berücksichtigen. Wenn das Modell noch nicht auf die zweite Instance geladen wurde, wird das Modell auf das Speicher-Volume dieser Instance heruntergeladen und in den Speicher des Containers geladen.
Wenn die Speicherauslastung einer Instanz hoch ist und SageMaker KI ein anderes Modell in den Speicher laden muss, werden ungenutzte Modelle aus dem Container dieser Instanz entladen, um sicherzustellen, dass genügend Speicher zum Laden des Modells vorhanden ist. Entfernte Modelle verbleiben auf dem Speicher-Volume der Instance und können später in den Speicher des Containers geladen werden, ohne dass sie erneut aus dem S3-Bucket heruntergeladen werden müssen. Wenn das Speichervolumen der Instance seine Kapazität erreicht, löscht SageMaker AI alle ungenutzten Modelle aus dem Speichervolume.
Um ein Modell zu löschen, beenden Sie das Senden von Anfragen und löschen Sie es aus dem S3-Bucket. SageMaker KI bietet Endpunktfunktionen für mehrere Modelle in einem Serving-Container. Das Hinzufügen von Modellen zu einem Multimodell-Endpunkt und ihr Löschen erfordert keine Aktualisierung des Endpunkts selbst. Um ein Modell hinzuzufügen, laden Sie es in den S3-Bucket hoch und rufen Sie es auf. Um sie verwenden zu können, sind keine Codeänderungen erforderlich.
Anmerkung
Wenn Sie einen Multimodell-Endpunkt aktualisieren, kann es bei Aufrufanfragen auf dem Endpunkt zunächst zu höheren Latenzen kommen, da sich Smart Routing auf Multimodell-Endpunkten an das Muster Ihres Datenverkehrs anpasst. Sobald es allerdings das Muster Ihres Datenverkehrs kennt, kann es bei den am häufigsten verwendeten Modellen zu niedrigen Latenzen kommen. Bei weniger häufig verwendeten Modellen kann es zu Kaltstart-Latenzen kommen, da die Modelle dynamisch in eine Instance geladen werden.
Beispiel-Notebooks für Multimodell-Endpunkte
Weitere Informationen zur Verwendung von Multimodell-Endpunkten finden Sie evtl. in den folgenden Beispiel-Notebooks:
-
Beispiele für Multimodell-Endpunkte, die CPU-gestützte Instances verwenden:
-
Multi-Model XGBoost-Beispielnotizbuch für Endgeräte
— Dieses Notizbuch zeigt, wie Sie mehrere XGBoost-Modelle auf einem Endpunkt bereitstellen. -
Multi-Model BYOC-Beispielnotizbuch für Endgeräte — Dieses Notizbuch
zeigt, wie Sie einen Kundencontainer einrichten und bereitstellen, der Endgeräte mit mehreren Modellen in KI unterstützt. SageMaker
-
-
Beispiel für Multimodell-Endpunkte, die GPU-gestützte Instances verwenden:
-
Führen Sie mehrere Deep-Learning-Modelle auf GPUs mit Amazon SageMaker Multi-model AI-Endpunkten (MME)
aus — Dieses Notizbuch zeigt, wie Sie einen NVIDIA Triton Inference-Container verwenden, um Modelle auf einem Endpunkt mit mehreren ResNet-50 Modellen bereitzustellen.
-
Anweisungen zum Erstellen und Zugreifen auf Jupyter-Notebook-Instances, mit denen Sie die vorherigen Beispiele in KI ausführen können, finden Sie unter. SageMaker SageMaker Amazon-Notebook-Instanzen Nachdem Sie eine Notebook-Instanz erstellt und geöffnet haben, wählen Sie den Tab SageMaker KI-Beispiele, um eine Liste aller KI-Beispiele zu sehen. SageMaker Die Notebooks für Multimodell-Endpunkte finden Sie im Abschnitt ADVANCED FUNCTIONALITY. Zum Öffnen eines Notebooks wählen Sie die Registerkarte Verwenden und dann Kopie erstellen aus.
Weitere Informationen zu Anwendungsfällen für Multimodell-Endpunkte finden Sie in den folgenden Blogs und Ressourcen:
