Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Dataloader mit Speicherzuweisung
Ein weiterer Mehraufwand beim Neustart ist auf das Laden von Daten zurückzuführen: Der Trainingscluster bleibt inaktiv, während der Dataloader initialisiert, Daten von Remote-Dateisystemen herunterlädt und sie stapelweise verarbeitet.
Um dieses Problem zu lösen, führen wir den Memory Mapped DataLoader (MMAP) Dataloader ein, der vorab abgerufene Batches im persistenten Speicher zwischenspeichert und so sicherstellt, dass sie auch nach einem fehlerbedingten Neustart verfügbar bleiben. Dieser Ansatz macht die Einrichtung des Dataloaders überflüssig und ermöglicht es, das Training mithilfe zwischengespeicherter Batches sofort wieder aufzunehmen, während der Dataloader gleichzeitig die nachfolgenden Daten im Hintergrund neu initialisiert und abruft. Der Datencache befindet sich in jedem Rang, der Trainingsdaten benötigt, und verwaltet zwei Arten von Batches: kürzlich verbrauchte Batches, die für das Training verwendet wurden, und vorab abgerufene Batches, die sofort verwendet werden können.
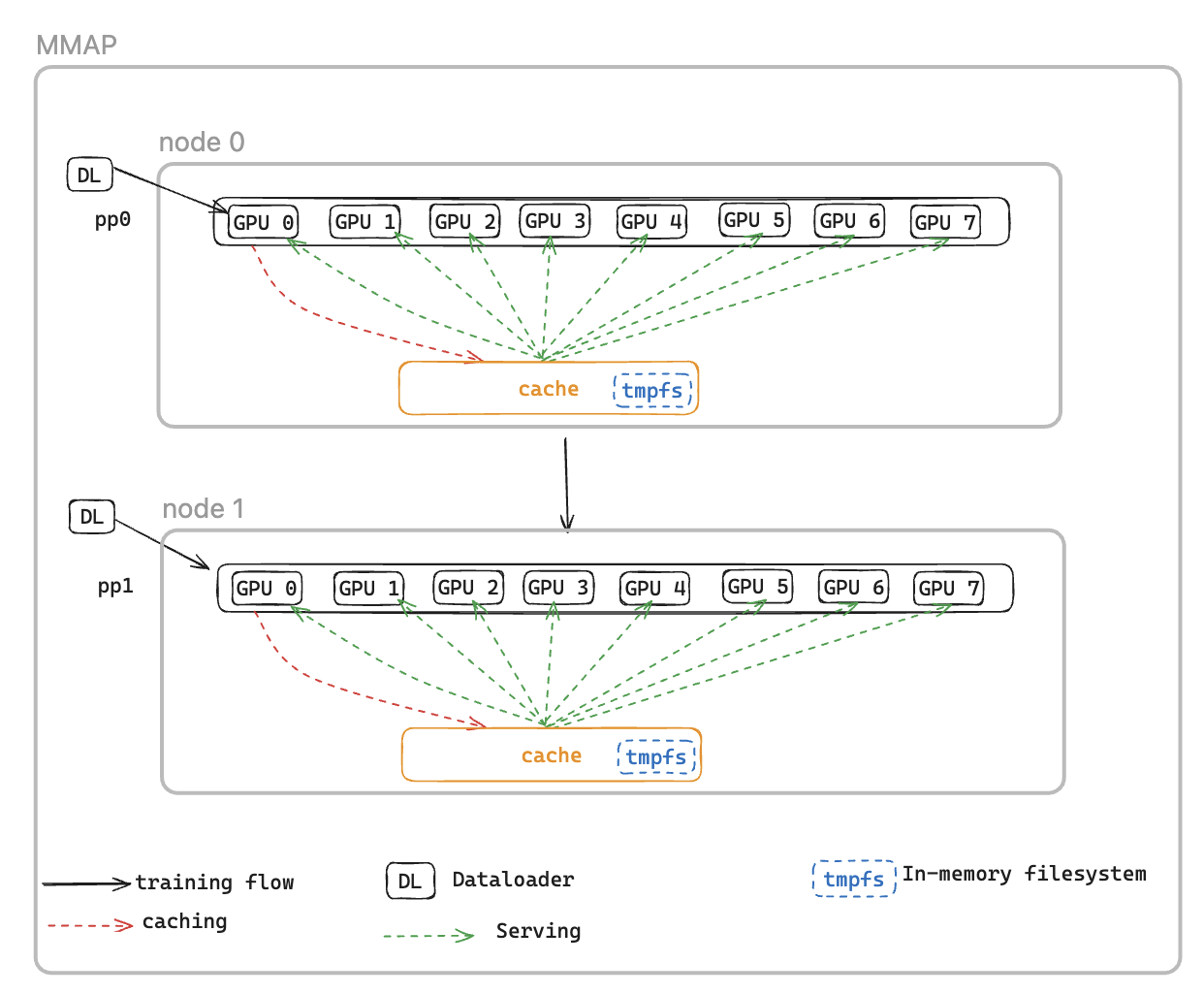
Der MMAP-Dataloader bietet zwei folgende Funktionen:
Datenvorabruf — Ruft proaktiv vom Dataloader generierte Daten ab und speichert sie im Cache
Persistentes Caching — Speichert sowohl verbrauchte als auch vorab abgerufene Batches in einem temporären Dateisystem, das Prozessneustarts übersteht
Durch die Verwendung des Caches profitiert der Trainingsjob von folgenden Vorteilen:
Reduzierter Speicherbedarf — Nutzt die Speicherzuweisung, I/O um eine einzige gemeinsam genutzte Kopie der Daten im Host-CPU-Speicher zu verwalten, wodurch redundante Kopien zwischen GPU-Prozessen vermieden werden (z. B. Reduzierung von 8 Kopien auf 1 bei einer P5-Instance mit 8) GPUs
Schnellere Wiederherstellung — Reduziert die mittlere Zeit bis zum Neustart (MTTR), da das Training sofort nach zwischengespeicherten Batches wieder aufgenommen werden kann. Somit entfällt das Warten auf die Neuinitialisierung des Dataloaders und die Generierung des ersten Batches
MMAP-Konfigurationen
Um MMAP zu verwenden, übergeben Sie einfach Ihr ursprüngliches Datenmodul an MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: Die MMAP-Dataloader-Parameter steuern den Speicherort des Cache-Verzeichnisses, die Größenbeschränkungen und die Delegierung des Datenabrufs. Standardmäßig ruft nur der TP-Rang 0 pro Knoten Daten aus der Quelle ab, während andere Ränge in derselben Datenreplikationsgruppe aus dem gemeinsam genutzten Cache lesen, wodurch redundante Übertragungen vermieden werden.
MMAPDataModule: Es umschließt das ursprüngliche Datenmodul und gibt den MMAP-Dataloader sowohl zum Trainieren als auch zur Validierung zurück.
Sehen Sie sich das Beispiel für die Aktivierung von MMAP an
API-Referenz
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Konfigurationsklasse für Cache-Resume-Memory-Mapped (MMAP) -Dataloader-Funktionalität beim Checkpointless-Training. HyperPod
Diese Konfiguration ermöglicht effizientes Laden von Daten mit Caching- und Prefetching-Funktionen, sodass das Training nach Ausfällen schnell wieder aufgenommen werden kann, indem zwischengespeicherte Datenstapel in Dateien mit Speicherzuweisung beibehalten werden.
Parameter
-
cache_dir (str, optional) — Verzeichnispfad zum Speichern zwischengespeicherter Datenstapel. Standard: „/_cache“ dev/shm/pdl
-
prefetch_length (int, optional) — Anzahl der Batches, die während des Trainings vorab abgerufen werden müssen. Standard: 10
-
val_prefetch_length (int, optional) — Anzahl der Batches, die während der Validierung vorab abgerufen werden sollen. Standard: 10
-
lookback_length (int, optional) — Anzahl der zuvor verwendeten Batches, die zur möglichen Wiederverwendung im Cache aufbewahrt werden sollen. Standard: 2
-
checkpoint_frequency (int, optional) — Häufigkeit der Modell-Checkpoint-Schritte. Wird zur Optimierung der Cache-Leistung verwendet. Standard: keiner
-
model_parallel_group (Objekt, optional) — Prozessgruppe für Modellparallelität. Bei None wird sie automatisch erstellt. Standard: keiner
-
enable_batch_encryption (bool, optional) — Ob die Verschlüsselung für zwischengespeicherte Batchdaten aktiviert werden soll. Standard: False
Methoden
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Erstellt eine konfigurierte MMAP-Dataloader-Instanz und gibt sie zurück.
Parameter
-
dataloader_init_callable (Callable) — Funktion zur Initialisierung des zugrunde liegenden Dataloaders
-
parallel_state_util (object) — Hilfsprogramm zur prozessübergreifenden Verwaltung des parallel Zustands
-
step (int) — Der Datenschritt, mit dem Sie während des Trainings fortfahren möchten
-
is_data_loading_rank (Callable) — Funktion, die True zurückgibt, wenn der aktuelle Rang Daten laden soll
-
create_model_parallel_group_callable (Callable) — Funktion zum Erstellen einer parallel Modellprozessgruppe
-
name (str, optional) — Namenskennung für den Dataloader. Standard: „Train“
-
is_val (bool, optional) — Ob es sich um einen Validierungs-Dataloader handelt. Standard: False
-
cached_len (int, optional) — Länge der zwischengespeicherten Daten bei Wiederaufnahme aus dem vorhandenen Cache. Standard: 0
Gibt CacheResumePrefetchedDataLoader oder — Konfigurierte MMAP-Dataloader-Instanz CacheResumeReadDataLoader zurück
ValueErrorWird ausgelöst, wenn der Schrittparameter ist. None
Beispiel
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Hinweise
-
Das Cache-Verzeichnis sollte über ausreichend Speicherplatz und eine schnelle I/O Leistung verfügen (z. B. /dev/shm für In-Memory-Speicher).
-
Durch
checkpoint_frequencydie Einstellung wird die Cache-Leistung verbessert, indem die Cache-Verwaltung auf das Modell-Checkpointing abgestimmt wird -
Für die Validierung von Dataloaders (
is_val=True) wird der Schritt auf 0 zurückgesetzt und ein Kaltstart wird erzwungen -
Je nachdem, ob der aktuelle Rang für das Laden von Daten verantwortlich ist, werden unterschiedliche Dataloader-Implementierungen verwendet
MMAPDataModul
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
Ein PyTorch DataModule Lightning-Wrapper, der Funktionen zum Laden von Memory-Mapping-Daten (MMAP) auf vorhandene Daten anwendet, sodass das Training ohne Checkpoints möglich ist. DataModules
Dieser Kurs umschließt ein vorhandenes PyTorch Lightning DataModule und erweitert es um MMAP-Funktionen, wodurch effizientes Zwischenspeichern von Daten und eine schnelle Wiederherstellung bei Trainingsausfällen ermöglicht werden. Es behält die Kompatibilität mit der ursprünglichen DataModule Oberfläche bei und bietet gleichzeitig zusätzliche Trainingsfunktionen ohne Checkpoints.
Parameters
- data_module (pl. LightningDataModule)
Der DataModule zu verpackende Basiswert (z. B. LLMData Modul)
- mmap_config () MMAPConfig
Das MMAP-Konfigurationsobjekt, das Verhalten und Parameter beim Zwischenspeichern definiert
parallel_state_util(MegatronParallelStateUtil, optional)Hilfsprogramm für die Verwaltung des parallel Zustands über verteilte Prozesse hinweg. Standard: MegatronParallelStateUtil ()
is_data_loading_rank(Aufrufbar, optional)Funktion, die True zurückgibt, wenn für den aktuellen Rang Daten geladen werden sollen. Bei None wird standardmäßig parallel_state_util.is_tp_0 verwendet. Standard: keiner
Attribute
global_step(int)Aktueller globaler Trainingsschritt, der für die Wiederaufnahme von Checkpoints verwendet wird
cached_train_dl_len(int)Länge des Trainingsdataloaders im Cache
cached_val_dl_len(int)Länge des Validierungs-Dataloaders im Cache
Methoden
setup(stage=None)
Richten Sie das zugrunde liegende Datenmodul für die angegebene Trainingsphase ein.
stage(str, optional)Phase des Trainings („fit“, „validieren“, „testen“ oder „vorhersagen“). Standard: keiner
train_dataloader()
Erstellen Sie das Training DataLoader mit MMAP-Wrapping.
Gibt zurück: DataLoader — MMAP-umschlossenes Training DataLoader mit Caching- und Prefetching-Funktionen
val_dataloader()
Erstellen Sie die Validierung mit MMAP-Wrapping. DataLoader
Gibt zurück: DataLoader — MMAP-umschlossene Validierung mit Caching-Funktionen DataLoader
test_dataloader()
Erstellen Sie den Test, DataLoader wenn das zugrunde liegende Datenmodul ihn unterstützt.
Gibt zurück: DataLoader oder None — Test DataLoader aus dem zugrunde liegenden Datenmodul, oder None, falls nicht unterstützt
predict_dataloader()
Erstellen Sie die Prognose DataLoader , wenn das zugrunde liegende Datenmodul sie unterstützt.
Gibt zurück: DataLoader oder None — Prognose DataLoader aus dem zugrunde liegenden Datenmodul, oder None, falls nicht unterstützt
load_checkpoint(checkpoint)
Lädt Checkpoint-Informationen, um das Training ab einem bestimmten Schritt fortzusetzen.
- Checkpoint (Diktat)
Checkpoint-Wörterbuch mit dem Schlüssel 'global_step'
get_underlying_data_module()
Ruft das zugrunde liegende verpackte Datenmodul ab.
Gibt zurück: pl. LightningDataModule — Das ursprüngliche Datenmodul, das verpackt wurde
state_dict()
Ruft das Statuswörterbuch der MMAP DataModule für Checkpoints ab.
Gibt zurück: dict — Wörterbuch, das zwischengespeicherte Dataloader-Längen enthält
load_state_dict(state_dict)
Lädt das Statuswörterbuch, um den MMAP-Status wiederherzustellen. DataModule
state_dict(Diktat)Staatliches Wörterbuch, das geladen werden soll
Eigenschaften
data_sampler
Stellen Sie den Datensampler des zugrunde liegenden Datenmoduls dem NeMo Framework zur Verfügung.
Gibt zurück: object oder None — Der Datensampler aus dem zugrunde liegenden Datenmodul
Beispiel
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Hinweise
Der Wrapper delegiert die meisten Attributzugriffe mit __getattr__ an das zugrunde liegende Datenmodul
Nur Ränge zum Laden von Daten initialisieren und verwenden das zugrunde liegende Datenmodul tatsächlich; andere Ränge verwenden gefälschte Dataloader
Die Längen der zwischengespeicherten Dataloader werden beibehalten, um die Leistung bei der Wiederaufnahme des Trainings zu optimieren
