Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Prozessbegleitende Wiederherstellung und Training ohne Kontrollpunkte
HyperPod Checkpointless-Training nutzt Modellredundanz, um fehlertolerantes Training zu ermöglichen. Das Kernprinzip besteht darin, dass Modell- und Optimizer-Status über mehrere Knotengruppen hinweg vollständig repliziert werden, wobei Gewichtungsaktualisierungen und Optimizer-Statusänderungen innerhalb jeder Gruppe synchron repliziert werden. Wenn ein Fehler auftritt, schließen fehlerfreie Replikate ihre Optimierungsschritte ab und übertragen die aktualisierten Zustände an wiederherstellende Replikate. model/optimizer
Dieser auf Modellredundanz basierende Ansatz ermöglicht mehrere Mechanismen zur Fehlerbehandlung:
-
Prozessbegleitende Wiederherstellung: Prozesse bleiben trotz Fehlern aktiv, wobei alle Modell- und Optimierungsstatus im GPU-Speicher mit den neuesten Werten beibehalten werden
-
Reibungslose Behandlung von Abbrüchen: kontrollierte Abbrüche und Bereinigung der Ressourcen bei betroffenen Vorgängen
-
Neuausführung von Codeblöcken: Nur die betroffenen Codesegmente innerhalb eines wiederausführbaren Codeblocks (RCB) werden erneut ausgeführt
-
Wiederherstellung ohne Kontrollpunkt ohne verlorenen Trainingsfortschritt: Da die Prozesse andauern und die Zustände im Speicher verbleiben, geht kein Trainingsfortschritt verloren. Wenn ein Fehler auftritt, wird das Training mit dem vorherigen Schritt fortgesetzt, im Gegensatz zum letzten gespeicherten Checkpoint
Konfigurationen ohne Checkpoint
Hier ist der Kernausschnitt des Checkpointless-Trainings.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Alle Ränge warten auf die Ranginformationen von der Infrastruktur. HyperpodTrainingOperatorHPWrapper: Python-Funktionswrapper, der Neustartfunktionen für einen wiederausführbaren Codeblock (RCB) ermöglicht. Die Implementierung verwendet einen Kontextmanager anstelle eines Python-Dekorators, da Dekoratoren die Anzahl der zur Laufzeit RCBs zu überwachenden Objekte nicht bestimmen können.CudaHealthCheck: Stellt sicher, dass sich der CUDA-Kontext für den aktuellen Prozess in einem fehlerfreien Zustand befindet, indem es mit der GPU synchronisiert wird. Verwendet das in der Umgebungsvariablen LOCAL_RANK angegebene Gerät oder verwendet standardmäßig das CUDA-Gerät des Haupt-Threads, wenn LOCAL_RANK nicht gesetzt ist.HPAgentK8sAPIFactory: Diese API ermöglicht ein Training ohne Checkpoint, um den Trainingsstatus anderer Pods im Kubernetes-Trainingscluster abzufragen. Sie bietet auch eine Barriere auf Infrastrukturebene, die sicherstellt, dass alle Ränge den Abbruch erfolgreich abschließen und die Operationen neu starten, bevor sie fortfahren.CheckpointManager: Verwaltet die Checkpoints und die Wiederherstellung im Speicher und sorgt so für Fehlertoleranz ohne Checkpoints. peer-to-peer Es hat die folgenden Kernaufgaben:In-Memory-Checkpoint-Management: Speichert und verwaltet NeMo Modell-Checkpoints im Arbeitsspeicher für eine schnelle Wiederherstellung ohne Festplatte I/O bei Wiederherstellungsszenarien ohne Checkpoint.
Überprüfung der Durchführbarkeit der Wiederherstellung: Ermittelt, ob eine Wiederherstellung ohne Checkpoint möglich ist, indem die globale Schrittkonsistenz, der Rangstatus und die Integrität des Modellstatus überprüft werden.
Peer-to-Peer Orchestrierung der Wiederherstellung: Koordiniert die Checkpoint-Übertragung zwischen fehlerfreien und ausgefallenen Rängen mithilfe verteilter Kommunikation für eine schnelle Wiederherstellung.
RNG State Management: Behält die Zustände des Zufallszahlengenerators in Python,, und Megatron bei und stellt sie wieder her NumPy PyTorch, um eine deterministische Wiederherstellung zu ermöglichen.
[Optional] Checkpoint-Offload: Verlagerung im Speicher-Checkpoint auf die CPU, wenn die GPU nicht über genügend Speicherkapazität verfügt.
PEFTCheckpointManager: Es wird erweitert,CheckpointManagerindem die Gewichte des Basismodells für die PEFT-Feinabstimmung beibehalten werden.CheckpointlessAbortManager: Verwaltet Abbruchvorgänge in einem Hintergrund-Thread, wenn ein Fehler auftritt. Standardmäßig werden Checkpointing TransformerEngine, TorchDistributed und abgebrochen. DataLoader Benutzer können bei Bedarf benutzerdefinierte Abbruch-Handler registrieren. Nach Abschluss des Abbruchs muss die gesamte Kommunikation beendet und alle Prozesse und Threads müssen beendet werden, um Ressourcenlecks zu verhindern.CheckpointlessFinalizeCleanup: Führt die letzten Bereinigungsvorgänge im Haupt-Thread für Komponenten durch, die im Hintergrundthread nicht sicher abgebrochen oder bereinigt werden können.CheckpointlessMegatronStrategy: Das erbtMegatronStrategyvon der Form in Nemo. Beachten Sie, dass für das Training ohne Checkpoint mindestens 2 erforderlich sindnum_distributed_optimizer_instances, damit die Optimizer-Replikation durchgeführt werden kann. Die Strategie kümmert sich auch um die Registrierung wichtiger Attribute und die Initialisierung von Prozessgruppen, z. B. ohne Wurzeln.CheckpointlessCallback: Lightning-Rückruf, der das NeMo Training in das Fehlertoleranzsystem des Checkpointless-Trainings integriert. Es hat die folgenden Kernaufgaben:Lebenszyklusmanagement für Trainingsschritte: Verfolgt den Trainingsfortschritt und koordiniert je ParameterUpdateLock nach Trainingsstatus (erster Schritt im Vergleich zu nachfolgenden Schritten) die Wiederherstellung enable/disable ohne Checkpoint.
Koordination des Checkpoint-Zustands: Verwaltet das Speichern/Wiederherstellen von Checkpoints im PEFT-Basismodell im Arbeitsspeicher.
CheckpointlessCompatibleConnector: Eine PTLCheckpointConnector, die versucht, die Checkpoint-Datei vorab in den Speicher zu laden, wobei der Quellpfad in dieser Priorität festgelegt wird:versuchen Sie es mit einer Wiederherstellung ohne Checkpoint
Wenn checkpointless None zurückgibt, wird auf parent.resume_start () zurückgegriffen
Sehen Sie sich das Beispiel an, um Codes Trainingsfunktionen ohne Checkpoint
Konzepte
In diesem Abschnitt werden Trainingskonzepte ohne Checkpoint vorgestellt. Checkpointless-Schulungen bei Amazon SageMaker HyperPod unterstützen die Wiederherstellung während des Prozesses. Diese API-Schnittstelle folgt einem ähnlichen Format wie die. NVRx APIs
Konzept — Wiederausführbarer Codeblock (RCB)
Wenn ein Fehler auftritt, bleiben gesunde Prozesse am Leben, aber ein Teil des Codes muss erneut ausgeführt werden, um die Trainingszustände und Python-Stacks wiederherzustellen. Ein wiederausführbarer Codeblock (RCB) ist ein bestimmtes Codesegment, das bei der Wiederherstellung nach einem Fehler erneut ausgeführt wird. Im folgenden Beispiel umfasst der RCB das gesamte Trainingsskript (d. h. alles, was unter main () steht), was bedeutet, dass bei jeder Wiederherstellung nach einem Fehler das Trainingsskript neu gestartet wird, wobei das In-Memory-Modell und der Optimizer-Status beibehalten werden.
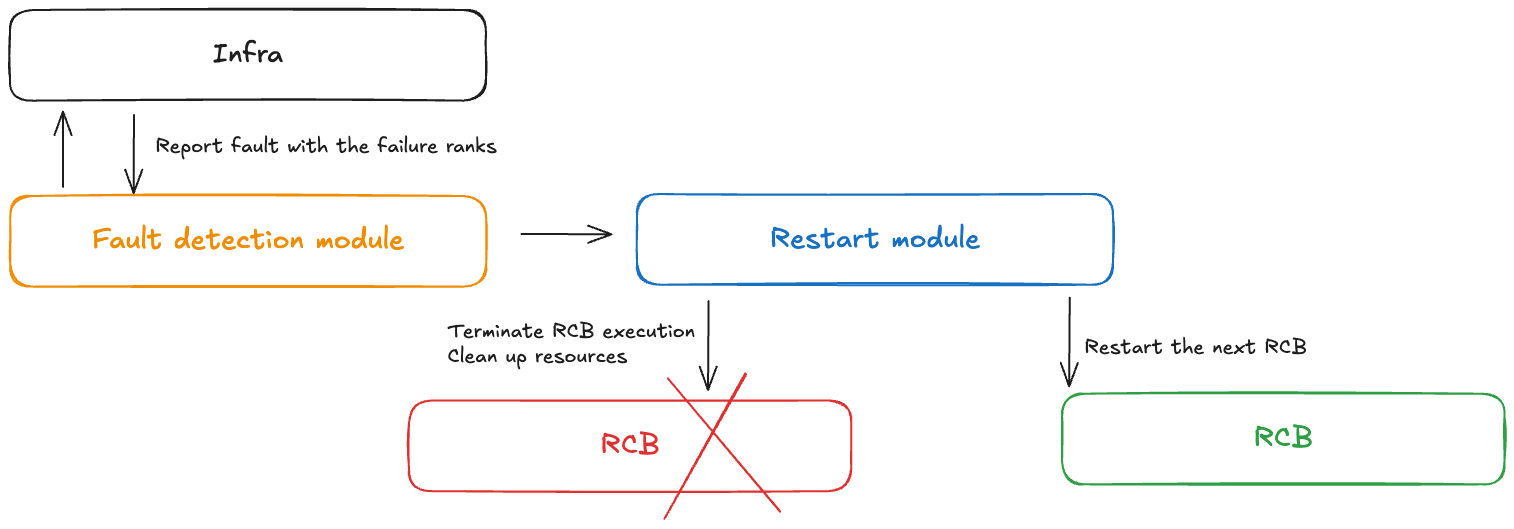
Konzept — Fehlerkontrolle
Ein Fault Controller-Modul erhält Benachrichtigungen, wenn beim Training ohne Checkpoint Fehler auftreten. Dieser Fehlercontroller umfasst die folgenden Komponenten:
Fehlererkennungsmodul: Empfängt Benachrichtigungen über Infrastrukturfehler
RCB-Definition APIs: Ermöglicht es Benutzern, den wiederausführbaren Codeblock (RCB) in ihrem Code zu definieren
Neustartmodul: Beendet den RCB, bereinigt Ressourcen und startet den RCB neu
Konzept — Modellredundanz
Das Training großer Modelle erfordert normalerweise eine ausreichend große Datenparallelgröße, um Modelle effizient zu trainieren. Bei herkömmlicher Datenparallelität wie PyTorch DDP und Horovod wird das Modell vollständig repliziert. Fortgeschrittenere Techniken der Shard-Datenparallelität wie DeepSpeed ZerO Optimizer und FSDP unterstützen auch den Hybrid-Sharding-Modus, der das Sharding der Status innerhalb der Sharding-Gruppe und die vollständige Replikation zwischen Replikationsgruppen ermöglicht. model/optimizer NeMo verfügt über diese Hybrid-Sharding-Funktion auch über ein Argument num_distributed_optimizer_instances, das Redundanz ermöglicht.
Das Hinzufügen von Redundanz bedeutet jedoch, dass das Modell nicht vollständig auf den gesamten Cluster verteilt wird, was zu einer höheren Speicherauslastung des Geräts führt. Die Menge des redundanten Speichers hängt von den spezifischen Model-Sharding-Techniken ab, die der Benutzer implementiert. Die Gewichtungen, Gradienten und der Aktivierungsspeicher des Modells mit niedriger Genauigkeit werden nicht beeinträchtigt, da sie aufgrund der Modellparallelität fragmentiert werden. Das hochpräzise Master-Modell weights/gradients und der Optimizer-Status werden davon beeinflusst. Durch das Hinzufügen eines redundanten Modellreplikats erhöht sich die Speicherauslastung des Geräts um etwa die Größe eines DCP-Checkpoints.
Beim Hybrid-Sharding werden die Kollektive der gesamten DP-Gruppen in relativ kleinere Kollektive aufgeteilt. Bisher gab es in der gesamten DP-Gruppe ein Prinzip zur Reduzierung der Streuung und ein All-Gathering. Nach dem Hybrid-Sharding läuft die Methode zur Reduzierung der Streuung nur innerhalb der einzelnen Modellreplikate, und es wird eine All-Reduce-Methode für alle Modellreplikatgruppen geben. Das All-Gather-System wird auch innerhalb jeder Modellreplikation ausgeführt. Dadurch bleibt das gesamte Kommunikationsvolumen in etwa unverändert, aber die Kollektive arbeiten mit kleineren Gruppen, sodass wir mit einer besseren Latenz rechnen.
Konzept — Fehler- und Neustarttypen
In der folgenden Tabelle sind verschiedene Fehlertypen und zugehörige Wiederherstellungsmechanismen aufgeführt. Beim Checkpointless-Training wird zunächst versucht, Fehler mithilfe einer prozessinternen Wiederherstellung zu beheben, gefolgt von einem Neustart auf Prozessebene. Nur im Falle eines schwerwiegenden Fehlers (z. B. wenn mehrere Knoten gleichzeitig ausfallen), wird auf einen Neustart auf Jobebene zurückgegriffen.
| Art des Fehlers | Ursache | Art der Wiederherstellung | Wiederherstellungsmechanismus |
|---|---|---|---|
| Fehler im Prozess | Fehler auf Codeebene, Ausnahmen | Prozessinterne Wiederherstellung (IPR) | RCB innerhalb des bestehenden Prozesses erneut ausführen; intakte Prozesse bleiben aktiv |
| Fehler beim Neustart des Prozesses | Beschädigter CUDA-Kontext, Prozess beendet | Neustart auf Prozessebene (PLR) | SageMaker HyperPod Der geschulte Bediener startet die Prozesse neu; der Neustart des K8s-Pods wird übersprungen |
| Fehler beim Austausch des Knotens | Dauerhafter node/GPU Hardwarefehler | Neustart auf Jobebene (JLR) | Ersetzen Sie den ausgefallenen Knoten; starten Sie den gesamten Trainingsjob neu |
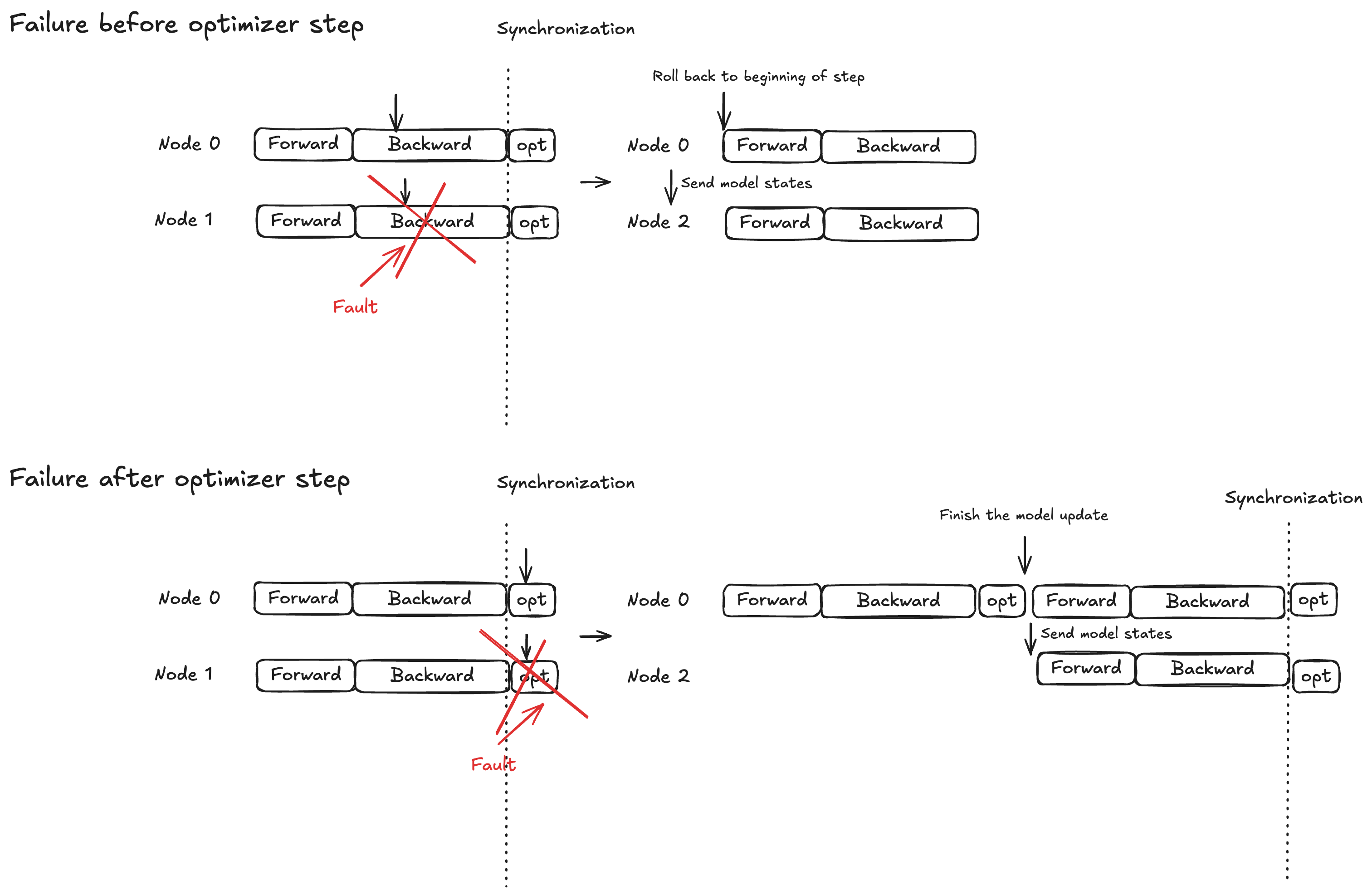
Konzept: Atomic Lock-Schutz für den Optimizer-Schritt
Die Modellausführung ist in drei Phasen unterteilt: Vorwärtsausbreitung, Rückwärtsausbreitung und Optimierungsschritt. Das Wiederherstellungsverhalten hängt vom Zeitpunkt des Fehlers ab:
Übertragung vorwärts/rückwärts: Gehen Sie zurück zum Anfang des aktuellen Trainingsschritts und senden Sie den Modellstatus an die Ersatzknoten
Optimierungsschritt: Lassen Sie fehlerfreie Replikate den Schritt unter Sperrschutz abschließen, und senden Sie dann die aktualisierten Modellstatus an die Ersatzknoten
Diese Strategie stellt sicher, dass abgeschlossene Optimizer-Updates niemals verworfen werden, wodurch die Zeit für die Fehlerbehebung reduziert wird.
Ablaufdiagramm des Checkpointless-Trainings
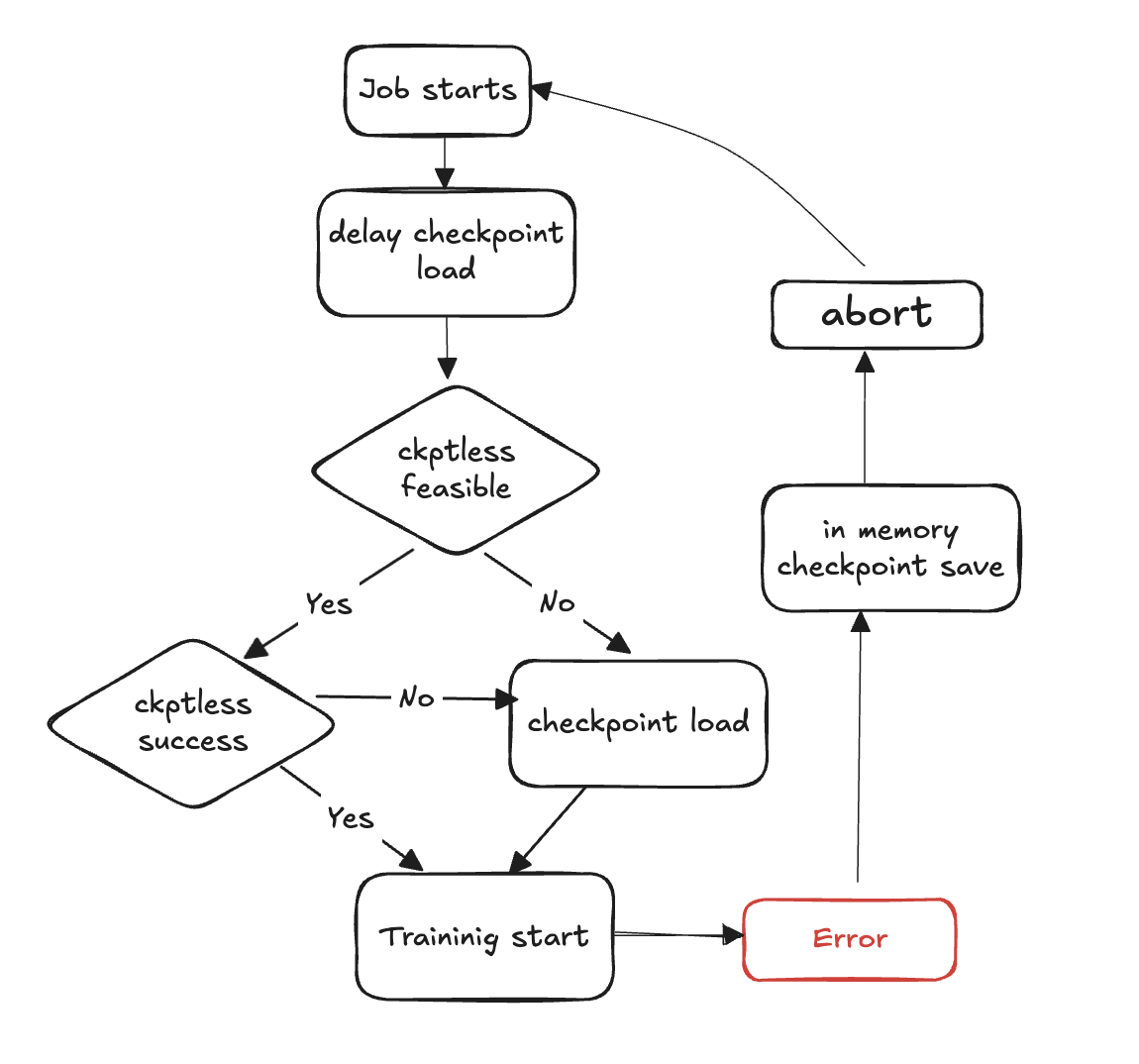
Die folgenden Schritte beschreiben den Prozess der Fehlererkennung und Wiederherstellung ohne Checkpoint:
Die Trainingsschleife beginnt
Es tritt ein Fehler auf
Prüfen Sie die Durchführbarkeit eines Lebenslaufs ohne Checkpoint
Prüfen Sie, ob es möglich ist, einen Lebenslauf ohne Kontrollpunkt durchzuführen
Falls möglich, versuchen Sie eine Wiederaufnahme ohne Checkpoint
Wenn die Wiederaufnahme fehlschlägt, greifen Sie auf das Laden am Checkpoint aus dem Speicher zurück
Wenn die Wiederaufnahme erfolgreich ist, wird das Training im wiederhergestellten Zustand fortgesetzt
Falls dies nicht möglich ist, greifen Sie auf das Laden am Checkpoint aus dem Speicher zurück
Ressourcen bereinigen — Brechen Sie alle Prozessgruppen und Backends ab und geben Sie Ressourcen frei, um den Neustart vorzubereiten.
Trainingsschleife fortsetzen — eine neue Trainingsschleife beginnt und der Vorgang kehrt zu Schritt 1 zurück.
API-Referenz
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Wartet auf Ranginformationen von der aktuellen Prozessumgebung HyperPod, ruft sie ab und aktualisiert sie anschließend mit verteilten Trainingsvariablen.
Diese Funktion ruft die richtigen Rangzuweisungen und Umgebungsvariablen für verteiltes Training ab. Sie stellt sicher, dass jeder Prozess die passende Konfiguration für seine Rolle im verteilten Trainingsjob erhält.
Parameter
Keine
Rückgabewerte
Keine
Behavior
Prozessüberprüfung: Überspringt die Ausführung, wenn sie von einem Unterprozess aus aufgerufen wird (läuft nur in) MainProcess
Umgebungsabruf: Ruft aktuelle Variablen
RANKundWORLD_SIZEaus Umgebungsvariablen abHyperPod Kommunikation: Ruft
hyperpod_wait_rank_info()zum Abrufen von Ranginformationen von HyperPodUmgebungsupdate: Aktualisiert die aktuelle Prozessumgebung mit arbeiterspezifischen Umgebungsvariablen, die von empfangen wurden HyperPod
Umgebungsvariablen
Die Funktion liest die folgenden Umgebungsvariablen:
RANK (int) — Aktueller Prozessrang (Standard: -1, falls nicht gesetzt)
WORLD_SIZE (int) — Gesamtzahl der Prozesse im verteilten Job (Standard: 0, falls nicht festgelegt)
Erhöht
AssertionError— Wenn die Antwort von nicht HyperPod das erwartete Format hat oder wenn Pflichtfelder fehlen
Beispiel
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Hinweise
Wird nur im Hauptprozess ausgeführt; Aufrufe von Unterprozessen werden automatisch übersprungen
Die Funktion blockiert, bis die Ranginformationen HyperPod bereitgestellt werden
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Python-Funktionswrapper, der Neustartfunktionen für einen reausführbaren Codeblock (RCB) beim Checkpointless-Training ermöglicht. HyperPod
Dieser Wrapper bietet Funktionen für Fehlertoleranz und automatische Wiederherstellung, indem er die Trainingsausführung überwacht und bei Ausfällen Neustarts zwischen verteilten Prozessen koordiniert. Er verwendet eher einen Context-Manager-Ansatz als einen Dekorateur, um die globalen Ressourcen während des gesamten Schulungszyklus aufrechtzuerhalten.
Parameter
abort (Abort, optional) — Die Ausführung wird asynchron abgebrochen, wenn Fehler erkannt werden. Standard:
Compose(HPAbortTorchDistributed())finalize (Finalize, optional) — Lokaler Finalisierungshandler auf Rang, der beim Neustart ausgeführt wird. Standard:
Nonehealth_check (HealthCheck, optional) — Lokale Zustandsprüfung nach Rang, die während des Neustarts ausgeführt wird. Standard:
Nonehp_api_factory (Callable, optional) — Factory-Funktion zum Erstellen einer API für die Interaktion. HyperPod HyperPod Standard:
Noneabort_timeout (float, optional) — Timeout für den Abbruch eines Aufrufs im Fehlersteuerungsthread. Standard:
Noneenabled (bool, optional) — Aktiviert die Wrapper-Funktionalität. Wenn
False, wird der Wrapper zu einem Pass-Through. Standard:Truetrace_file_path (str, optional) — Pfad zur Trace-Datei für die Profilerstellung. VizTracer Standard:
Noneasync_raise_before_abort (bool, optional) — Aktiviert das Erhöhen vor dem Abbruch im Fehlerkontroll-Thread. Standard:
Trueearly_abort_communicator (bool, optional) — Bricht den Kommunikator (NCCL/Gloo) ab, bevor der Dataloader abgebrochen wird. Standard:
Falsecheckpoint_manager (Beliebig, optional) — Manager für die Behandlung von Checkpoints während der Wiederherstellung. Standard:
Nonecheck_memory_status (bool, optional) — Aktiviert die Überprüfung und Protokollierung des Speicherstatus. Standard:
True
Methoden
def __call__(self, fn)
Schließt eine Funktion ein, um Neustartfunktionen zu aktivieren.
Parameter:
fn (Callable) — Die Funktion, die mit Neustartfunktionen umschlossen werden soll
Gibt zurück:
Aufrufbar — Umschlossene Funktion mit Neustartfunktionen oder ursprüngliche Funktion, falls deaktiviert
Beispiel
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Hinweise
Der Wrapper muss verfügbar
torch.distributedseinWenn
enabled=False, wird der Wrapper zu einem Pass-Through und gibt die ursprüngliche Funktion unverändert zurückDer Wrapper verwaltet globale Ressourcen wie die Überwachung von Threads während des gesamten Trainingszyklus
Unterstützt die VizTracer Profilerstellung, sofern sie bereitgestellt wird
trace_file_pathLässt sich HyperPod für eine koordinierte Fehlerbehandlung in verteilten Schulungen integrieren
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Überwacht und verwaltet den Status eines Restart-Codeblocks (RCB) während der Ausführung.
Diese Klasse befasst sich mit dem Lebenszyklus der RCB-Ausführung, einschließlich der Fehlererkennung, der Koordination mit anderen Rängen bei Neustarts und Bereinigungsvorgängen. Es verwaltet die verteilte Synchronisation und sorgt für eine konsistente Erholung in allen Trainingsprozessen.
Parameter
wrapper (HPWrapper) — Der übergeordnete Wrapper, der globale Einstellungen für die prozessinterne Wiederherstellung enthält
Attribute
step_upon_restart (int) — Zähler, der die Schritte seit dem letzten Neustart verfolgt und zur Bestimmung der Neustartstrategie verwendet wird
Methoden
def initialize_barrier()
Warten Sie auf die HyperPod Barrierensynchronisierung, nachdem Sie auf eine Ausnahme von RCB gestoßen sind.
def start_hp_fault_handling_thread()
Starten Sie den Fehlerbehandlungs-Thread zur Überwachung und Koordination von Fehlern.
def handle_fn_exception(call_ex)
Verarbeiten Sie Ausnahmen von der Ausführungsfunktion oder vom RCB.
Parameter:
call_ex (Exception) — Ausnahme von der Überwachungsfunktion
def restart(term_ex)
Führt den Neustart-Handler aus, einschließlich Finalisierung, Garbage-Collection und Integritätsprüfungen.
Parameter:
term_ex (RankShouldRestart) — Terminierungsausnahme, die den Neustart auslöst
def launch(fn, *a, **kw)
Führt den RCB mit der richtigen Ausnahmebehandlung aus.
Parameter:
fn (Callable) — Funktion, die ausgeführt werden soll
a — Funktionsargumente
kw — Argumente für Funktionsschlüsselwörter
def run(fn, a, kw)
Hauptausführungsschleife, die Neustarts und Barrierensynchronisierung verarbeitet.
Parameter:
fn (Callable) — Funktion, die ausgeführt werden soll
a — Funktionsargumente
kw — Argumente für Funktionsschlüsselwörter
def shutdown()
Threads zur Fehlerbehandlung und Überwachung herunterfahren.
Hinweise
Behandelt automatisch
RankShouldRestartAusnahmen für eine koordinierte WiederherstellungVerwaltet die Speicherverfolgung und Abbrüche sowie die Speicherbereinigung bei Neustarts
Unterstützt sowohl In-Process-Recovery- als auch PLR-Strategien (Process-Level Restart), die auf dem Timing von Fehlern basieren
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Stellt sicher, dass sich der CUDA-Kontext für den aktuellen Prozess während der Trainingswiederherstellung ohne Checkpoint in einem fehlerfreien Zustand befindet.
Diese Integritätsprüfung wird mit der GPU synchronisiert, um sicherzustellen, dass der CUDA-Kontext nach einem Trainingsfehler nicht beschädigt ist. Es führt GPU-Synchronisierungsvorgänge durch, um Probleme zu erkennen, die eine erfolgreiche Wiederaufnahme des Trainings verhindern könnten. Die Integritätsprüfung wird ausgeführt, nachdem die verteilten Gruppen gelöscht wurden und die Finalisierung abgeschlossen ist.
Parameter
timeout (datetime.timedelta, optional) — Timeout-Dauer für GPU-Synchronisierungsvorgänge. Standard:
datetime.timedelta(seconds=30)
Methoden
__call__(state, train_ex=None)
Führen Sie die CUDA-Integritätsprüfung aus, um die Integrität des GPU-Kontexts zu überprüfen.
Parameter:
state (HPState) — Aktueller HyperPod Status, der Ranginformationen und verteilte Informationen enthält
train_ex (Ausnahme, optional) — Die ursprüngliche Trainingsausnahme, die den Neustart ausgelöst hat. Standard:
None
Gibt zurück:
Tupel — Ein Tupel, das
(state, train_ex)unverändert enthält, falls die Gesundheitsprüfung bestanden wurde
Erhöht:
TimeoutError— Wenn bei der GPU-Synchronisierung ein Timeout auftritt, was auf einen potenziell beschädigten CUDA-Kontext hindeutet
Statuserhaltung: Gibt den ursprünglichen Status und die Ausnahme unverändert zurück, wenn alle Prüfungen bestanden wurden
Beispiel
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Hinweise
Verwendet Threading, um den Timeout-Schutz für die GPU-Synchronisierung zu implementieren
Entwickelt, um beschädigte CUDA-Kontexte zu erkennen, die eine erfolgreiche Wiederaufnahme des Trainings verhindern könnten
Sollte als Teil der Fehlertoleranz-Pipeline in verteilten Trainingsszenarien verwendet werden
HPAgentK8s APIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Factory-Klasse zum Erstellen von HPAgent K8SAPI-Instanzen, die mit der HyperPod Infrastruktur kommunizieren, um die Trainingskoordination auf verteilter Ebene zu gewährleisten.
Diese Factory bietet eine standardisierte Methode zur Erstellung und Konfiguration von HPAgent K8sAPI-Objekten, die die Kommunikation zwischen Trainingsprozessen und der Steuerungsebene regeln. HyperPod Es kapselt die Erstellung des zugrunde liegenden Socket-Clients und der API-Instanz und gewährleistet so eine konsistente Konfiguration in verschiedenen Teilen des Trainingssystems.
Methoden
__call__()
Erstellen Sie eine für die Kommunikation konfigurierte HPAgent K8SAPI-Instanz und geben Sie sie zurück. HyperPod
Gibt zurück:
HPAgentk8SAPI — Konfigurierte API-Instanz für die Kommunikation mit der Infrastruktur HyperPod
Beispiel
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Hinweise
Entwickelt, um nahtlos mit HyperPod der Kubernetes-basierten Infrastruktur zusammenzuarbeiten. Es ist für die koordinierte Fehlerbehandlung und -behebung in verteilten Schulungsszenarien unerlässlich
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Verwaltet die Checkpoints und die peer-to-peer Wiederherstellung im Speicher und sorgt so für Fehlertoleranz ohne Checkpoints bei verteilten Schulungen.
Diese Klasse bietet die Kernfunktionen für das Training HyperPod ohne Checkpoints, indem sie NeMo Modell-Checkpoints im Speicher verwaltet, die Durchführbarkeit der Wiederherstellung überprüft und die Checkpoint-Übertragung zwischen fehlerfreien und ausgefallenen Rängen orchestriert peer-to-peer. Dadurch entfällt die Notwendigkeit einer Festplatte I/O bei der Wiederherstellung, wodurch die mittlere Wiederherstellungszeit (MTTR) erheblich reduziert wird.
Parameter
enable_checksum (bool, optional) — Aktiviert die Überprüfung der Modellstatus-Prüfsumme für Integritätsprüfungen während der Wiederherstellung. Standard:
Falseenable_offload (bool, optional) — Aktiviert das Checkpoint-Offloading vom GPU- in den CPU-Speicher, um die GPU-Speichernutzung zu reduzieren. Standard:
False
Attribute
global_step (int oder None) — Aktueller Trainingsschritt, der dem gespeicherten Checkpoint zugeordnet ist
rng_states (list oder None) — Gespeicherte Zufallszahlengenerator-Zustände für die deterministische Wiederherstellung
checksum_manager (MemoryChecksumManager) — Manager für die Überprüfung der Prüfsumme des Modellstatus
parameter_update_lock (ParameterUpdateLock) — Sperre zur Koordination von Parameter-Updates während der Wiederherstellung
Methoden
save_checkpoint(trainer)
Speichert den NeMo Modell-Checkpoint im Speicher für eine mögliche Wiederherstellung ohne Checkpoint.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Hinweise:
Wird am Ende des Batches oder während der Ausnahmebehandlung CheckpointlessCallback aufgerufen
Erstellt Wiederherstellungspunkte ohne I/O Festplatten-Overhead
Speichert den vollständigen Modell-, Optimizer- und Scheduler-Status
delete_checkpoint()
Löschen Sie den In-Memory-Checkpoint und führen Sie Bereinigungsvorgänge durch.
Hinweise:
Löscht Checkpoint-Daten, RNG-Zustände und zwischengespeicherte Tensoren
Führt die Speicherbereinigung und die CUDA-Cache-Bereinigung durch
Wird nach erfolgreicher Wiederherstellung aufgerufen oder wenn der Checkpoint nicht mehr benötigt wird
try_checkpointless_load(trainer)
Versuchen Sie eine Wiederherstellung ohne Checkpoint, indem Sie den Status aus Peer-Rängen laden.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Gibt zurück:
dict oder None — Checkpoint wurde wiederhergestellt, falls erfolgreich, None, wenn ein Fallback auf die Festplatte erforderlich ist
Hinweise:
Wichtigster Einstiegspunkt für die Wiederherstellung ohne Checkpoint
Überprüft die Durchführbarkeit der Wiederherstellung, bevor eine P2P-Übertragung versucht wird
Bereinigt nach dem Wiederherstellungsversuch immer die In-Memory-Checkpoints
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Stellen Sie fest, ob eine Wiederherstellung ohne Checkpoint für das aktuelle Fehlerszenario möglich ist.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
include_checksum_verification (bool, optional) — Ob die Prüfsummenvalidierung eingeschlossen werden soll. Standard:
True
Gibt zurück:
bool — True, wenn eine Wiederherstellung ohne Checkpoint möglich ist, andernfalls False
Validierungskriterien:
Weltweite Kontinuität in allen gesunden Rängen
Es stehen ausreichend fehlerfreie Replikate für die Wiederherstellung zur Verfügung
Integrität der Prüfsumme für den Modellstatus (falls aktiviert)
store_rng_states()
Speichert alle Zustände des Zufallszahlengenerators für die deterministische Wiederherstellung.
Hinweise:
Erfasst Python- NumPy, PyTorch CPU/GPU- und Megatron-RNG-Zustände
Unverzichtbar für die Aufrechterhaltung des Trainingsdeterminismus nach der Erholung
load_rng_states()
Stellen Sie alle RNG-Zustände wieder her, um die deterministische Erholung fortzusetzen.
Hinweise:
Stellt alle zuvor gespeicherten RNG-Zustände wieder her
Stellt sicher, dass das Training mit identischen Zufallssequenzen fortgesetzt wird
maybe_offload_checkpoint()
Wenn Offload aktiviert ist, wird der Checkpoint von der GPU auf den CPU-Speicher verlagert.
Hinweise:
Reduziert die GPU-Speicherauslastung für große Modelle
Wird nur ausgeführt, wenn
enable_offload=TrueBehält den Zugriff auf Checkpoints für die Wiederherstellung bei
Beispiel
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Validierung: Überprüft die Checkpoint-Integrität anhand von Prüfsummen (falls aktiviert)
Hinweise
Nutzt verteilte Kommunikationsprimitive für eine effiziente P2P-Übertragung
Verarbeitet automatisch Tensor-DType-Konvertierungen und Geräteplatzierung
MemoryChecksumManager— Verwaltet die Integritätsprüfung des Modellstatus
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Verwaltet Checkpoints für PEFT (Parameter-Efficient Fine-Tuning) mit separater Basis- und Adapterverwaltung für eine optimierte Wiederherstellung ohne Checkpoints.
Dieser spezialisierte Checkpoint-Manager ermöglicht die Optimierung von PEFT-Workflows CheckpointManager , indem er die Gewichtung des Basismodells von den Adapterparametern trennt.
Parameter
Erbt alle Parameter von: CheckpointManager
enable_checksum (bool, optional) — Aktiviert die Überprüfung der Prüfsumme des Modellstatus. Standard:
Falseenable_offload (bool, optional) — Aktiviert das Checkpoint-Offloading in den CPU-Speicher. Standard:
False
Zusätzliche Attribute
params_to_save (set) — Satz von Parameternamen, die als Adapterparameter gespeichert werden sollen
base_model_weights (dict oder None) — Gewichte des Basismodells im Cache, einmal gespeichert und wiederverwendet
base_model_keys_to_extract (list oder None) — Schlüssel zum Extrahieren von Basismodell-Tensoren während der P2P-Übertragung
Methoden
maybe_save_base_model(trainer)
Speichert einmal die Gewichte des Basismodells und filtert dabei die Adapterparameter heraus.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Hinweise:
Speichert die Gewichte des Basismodells nur beim ersten Aufruf; nachfolgende Aufrufe sind keine Operationen
Filtert Adapterparameter heraus, um nur eingefrorene Basismodellgewichte zu speichern
Die Gewichte des Basismodells werden über mehrere Trainingseinheiten hinweg beibehalten
save_checkpoint(trainer)
Speichern Sie den Prüfpunkt des NeMo PEFT-Adaptermodells im Speicher für eine mögliche Wiederherstellung ohne Checkpoint.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Hinweise:
Ruft automatisch auf, wenn das Basismodell noch nicht gespeichert ist
maybe_save_base_model()Filtert den Checkpoint so, dass er nur Adapterparameter und Trainingsstatus enthält
Reduziert die Größe der Checkpoints im Vergleich zu Checkpoints des vollständigen Modells erheblich
try_base_model_checkpointless_load(trainer)
Das PEFT-Basismodell versucht, die Wiederherstellung ohne Checkpoint zu gewichten, indem der Status aus Peer-Rängen geladen wird.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Gibt zurück:
dict oder None — Der Basismodell-Checkpoint wurde wiederhergestellt, falls erfolgreich, None, wenn ein Fallback erforderlich ist
Hinweise:
Wird während der Modellinitialisierung verwendet, um die Gewichte des Basismodells wiederherzustellen
Löscht die Gewichte des Basismodells nach der Wiederherstellung nicht (wird für die Wiederverwendung aufbewahrt)
Optimiert für model-weights-only Wiederherstellungsszenarien
try_checkpointless_load(trainer)
Der PEFT-Adapter versucht, die Wiederherstellung ohne Checkpoint zu gewichten, indem er den Status aus Peer-Rängen lädt.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Gibt zurück:
dict oder None — Der Adapter-Checkpoint wurde wiederhergestellt, falls erfolgreich, None, wenn ein Fallback erforderlich ist
Hinweise:
Stellt nur Adapterparameter, Optimizer-Status und Scheduler wieder her
Lädt nach erfolgreicher Wiederherstellung automatisch den Optimizer- und Scheduler-Status
Bereinigt die Adapter-Checkpoints nach dem Wiederherstellungsversuch
is_adapter_key(key)
Prüfen Sie, ob der State-Dict-Schlüssel zu den Adapterparametern gehört.
Parameter:
key (str oder tuple) — Zu prüfender State-Dict-Schlüssel
Gibt zurück:
bool — True, wenn der Schlüssel ein Adapterparameter ist, False, wenn der Basismodellparameter
Erkennungslogik:
Prüft, ob der Schlüssel
params_to_savegesetzt istIdentifiziert Schlüssel, die „.adapter“ enthalten. substring
Identifiziert Schlüssel, die mit „.adapters“ enden
Überprüft bei Tupelschlüsseln, ob der Parameter Farbverläufe erfordert
maybe_offload_checkpoint()
Verlagert die Gewichte des Basismodells von der GPU auf den CPU-Speicher.
Hinweise:
Erweitert die übergeordnete Methode, um die Gewichtsverlagerung des Basismodells zu handhaben
Die Gewichte der Adapter sind in der Regel gering und müssen nicht entladen werden
Setzt ein internes Kennzeichen, um den Offload-Status zu verfolgen
Hinweise
Speziell für parametereffiziente Feinabstimmungsszenarien (LoRa, Adapter usw.) konzipiert
Sorgt automatisch für die Trennung von Basismodell- und Adapterparametern
Beispiel
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Factory-Klasse für die Erstellung und Verwaltung von Komponentenzusammenstellungen für fehlerfreie Prüfungen.
Diese Utility-Klasse bietet statische Methoden zum Erstellen, Anpassen und Verwalten von Zusammenstellungen von Abbruchkomponenten, die bei der Fehlerbehandlung beim Checkpointless-Training verwendet werden. HyperPod Sie vereinfacht die Konfiguration von Abbruchsequenzen, mit denen verteilte Trainingskomponenten, Datenlader und Framework-spezifische Ressourcen bei der Wiederherstellung nach einem Ausfall bereinigt werden.
Parameter
Keine (alle Methoden sind statisch)
Statische Methoden
get_default_checkpointless_abort()
Ruft die Standard-Abort-Compose-Instanz ab, die alle Standardabbruchkomponenten enthält.
Gibt zurück:
Compose — Standardmäßig erstellte Abbruchinstanz mit allen Abbruchkomponenten
Standardkomponenten:
AbortTransformerEngine() — Bereinigt Ressourcen TransformerEngine
HPCheckpointingAbort () — Führt die Bereinigung des Checkpoint-Systems durch
HPAbortTorchDistributed() — Bricht verteilte Operationen ab PyTorch
HPDataLoaderAbort() — Stoppt und bereinigt Datenlader
create_custom_abort(abort_instances)
Erstellen Sie einen benutzerdefinierten Abbruchvorgang, der nur die angegebenen Abbruchinstanzen enthält.
Parameter:
abort_instances (Abort) — Variable Anzahl von Abbruchinstanzen, die in die Erstellung aufgenommen werden sollen
Gibt zurück:
Compose — Neue komponierte Abbruchinstanz, die nur die angegebenen Komponenten enthält
Löst aus:
ValueError— Wenn keine Abbruchinstanzen bereitgestellt werden
override_abort(abort_compose, abort_type, new_abort)
Ersetzt eine bestimmte Abbruchkomponente in einer Compose-Instanz durch eine neue Komponente.
Parameter:
abort_compose (Compose) — Die ursprüngliche Compose-Instanz, die geändert werden soll
abort_type (type) — Der Typ der Abbruchkomponente, die ersetzt werden soll (z. B.)
HPCheckpointingAbortnew_abort (Abort) — Die neue Abbruchinstanz, die als Ersatz verwendet werden soll
Gibt zurück:
Compose — Neue Compose-Instanz, bei der die angegebene Komponente ersetzt wurde
Erhöht:
ValueError— Wenn abort_compose kein Attribut 'instances' hat
Beispiel
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Hinweise
Benutzerdefinierte Konfigurationen ermöglichen eine fein abgestimmte Steuerung des Bereinigungsverhaltens
Abbruchvorgänge sind für die ordnungsgemäße Bereinigung der Ressourcen bei der Fehlerbehebung von entscheidender Bedeutung
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Führt nach der Fehlererkennung eine umfassende Säuberung durch, um die Wiederherstellung während des Prozesses während einer Schulung ohne Kontrollpunkte vorzubereiten.
Dieser Finalize-Handler führt Framework-spezifische Bereinigungsvorgänge wie Megatron/TransformerEngine Abbruch, DDP-Bereinigung, erneutes Laden von Modulen und Speicherbereinigung durch, indem er die Referenzen der Trainingskomponenten zerstört. Er stellt sicher, dass die Trainingsumgebung für eine erfolgreiche Wiederherstellung während des Prozesses ordnungsgemäß zurückgesetzt wird, ohne dass der Prozess vollständig beendet werden muss.
Parameter
Keine
Attribute
trainer (pytorch_lightning.Trainer oder None) — Verweis auf die Lightning-Trainer-Instanz PyTorch
Methoden
__call__(*a, **kw)
Führen Sie umfassende Bereinigungsvorgänge aus, um die Wiederherstellung während des Prozesses vorzubereiten.
Parameter:
a — Variable Positionsargumente (von der Finalize-Schnittstelle übernommen)
kw — Variable Schlüsselwortargumente (von der Finalize-Schnittstelle übernommen)
Säuberungsvorgänge:
Megatron Framework Cleanup — Aufrufe zur Bereinigung von Megatron-spezifischen
abort_megatron()RessourcenTransformerEngine Cleanup — Aufrufe zur Bereinigung von Ressourcen
abort_te()TransformerEngineRoPE Cleanup — Aufrufe
cleanup_rope()zum Aufräumen von Ressourcen in rotierenden PositionenDDP Cleanup — Aufrufe
cleanup_ddp()zur Bereinigung von Ressourcen DistributedDataParallelModule Reloading — Aufrufe
reload_megatron_and_te()zum Neuladen von Framework-ModulenLightning-Modulbereinigung — Löscht optional das Lightning-Modul, um den GPU-Speicher zu reduzieren
Speicherbereinigung — Zerstört die Verweise der Trainingskomponenten auf freien Arbeitsspeicher
register_attributes(trainer)
Registrieren Sie die Trainer-Instanz für die Verwendung bei Bereinigungsvorgängen.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz zur Registrierung PyTorch
Integration mit CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Hinweise
Bereinigungsvorgänge werden in einer bestimmten Reihenfolge ausgeführt, um Abhängigkeitsprobleme zu vermeiden
Die Speicherbereinigung verwendet Garbage-Collection-Introspektion, um Zielobjekte zu finden
Alle Bereinigungsvorgänge sind so konzipiert, dass sie idempotent sind und sicher wiederholt werden können
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Megatron-Strategie mit integrierten Funktionen zur Wiederherstellung ohne Checkpoint für fehlertolerantes dezentrales Training.
Beachten Sie, dass für das Training ohne Checkpoints mindestens 2 erforderlich sindnum_distributed_optimizer_instances, damit eine Optimizer-Replikation durchgeführt werden kann. Die Strategie kümmert sich auch um die Registrierung wichtiger Attribute und die Initialisierung von Prozessgruppen.
Parameter
Erbt alle Parameter von: MegatronStrategy
NeMo MegatronStrategy Standard-Initialisierungsparameter
Konfigurationsoptionen für verteilte Schulungen
Einstellungen für Modellparallelität
Attribute
base_store (torch.distributed). TCPStoreoder None) — Verteilter Speicher für die Koordination von Prozessgruppen
Methoden
setup(trainer)
Initialisieren Sie die Strategie und registrieren Sie die Fehlertoleranzkomponenten beim Trainer.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Einrichtungsvorgänge:
Übergeordnetes Setup — Ruft das übergeordnete MegatronStrategy Setup auf
Registrierung von Fehlerinjektionen — Registriert HPFault InjectionCallback Hooks, falls vorhanden
Registrierung abschließen — Registriert den Trainer bei den Finalize Cleanup-Handlern
Registrierung abbrechen — Registriert den Trainer bei Abort-Handlern, die dies unterstützen
setup_distributed()
Initialisieren Sie die Prozessgruppe entweder mit Präfix oder TCPStore mit einer Verbindung ohne Wurzel.
load_model_state_dict(checkpoint, strict=True)
Lädt das Status-Diktat des Modells mit Checkpointless-Recovery-Kompatibilität.
Parameter:
checkpoint (Mapping [str, Any]) — Checkpoint-Wörterbuch, das den Modellstatus enthält
strict (bool, optional) — Ob der Abgleich von State-Dict-Schlüsseln strikt erzwungen werden soll. Standard:
True
get_wrapper()
Holen Sie sich die HPCall Wrapper-Instanz für die Koordination der Fehlertoleranz.
Gibt zurück:
HPCallWrapper — Die Wrapper-Instanz, die aus Gründen der Fehlertoleranz an den Trainer angeschlossen ist
is_peft()
Prüfen Sie, ob PEFT (Parameter-Efficient Fine-Tuning) in der Trainingskonfiguration aktiviert ist, indem Sie nach PEFT-Callbacks suchen
Gibt zurück:
bool — Wahr, wenn ein PEFT-Callback vorhanden ist, andernfalls False
teardown()
Überschreiben Sie den systemeigenen PyTorch Lightning-Teardown, um die Bereinigung an Abbruchprozeduren zu delegieren.
Beispiel
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Lightning-Rückruf, der das NeMo Training in das Fehlertoleranzsystem von Checkpointless-Trainings integriert.
Dieser Rückruf verwaltet die Schrittverfolgung, das Speichern von Checkpoints und die Koordination der Parameteraktualisierung für Funktionen zur Wiederherstellung während des Prozesses. Er dient als primärer Integrationspunkt zwischen PyTorch Lightning-Trainingsschleifen und Trainingsmechanismen HyperPod ohne Checkpoints und koordiniert die Fehlertoleranzoperationen während des gesamten Trainingszyklus.
Parameter
enable_inprocess (bool, optional) — Aktiviert Funktionen zur prozessinternen Wiederherstellung. Standard:
Falseenable_checkpointless (bool, optional) — Aktiviert die Wiederherstellung ohne Prüfpunkt (erforderlich).
enable_inprocess=TrueStandard:Falseenable_checksum (bool, optional) — Aktiviert die Überprüfung der Modellstatus-Prüfsumme (erforderlich).
enable_checkpointless=TrueStandard:Falseclean_tensor_hook (bool, optional) — Löscht während der Bereinigung Tensor-Hooks von allen GPU-Tensoren (teurer Vorgang). Standard:
Falseclean_lightning_module (bool, optional) — Aktiviert die Bereinigung des Lightning-Moduls, um nach jedem Neustart GPU-Speicher freizugeben. Standard:
False
Attribute
tried_adapter_checkpointless (bool) — Markierung, um nachzuverfolgen, ob versucht wurde, den Adapter ohne Checkpoint wiederherzustellen
Methoden
get_wrapper_from_trainer(trainer)
Holen Sie sich die Wrapper-Instanz vom Trainer für die Koordination der Fehlertoleranz. HPCall
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Gibt zurück:
HPCallWrapper — Die Wrapper-Instanz für Fehlertoleranzoperationen
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Wird zu Beginn jedes Trainingsstapels aufgerufen, um die Schrittverfolgung und Wiederherstellung zu verwalten.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
pl_module (pytorch_lightning). LightningModule) — Lightning-Modul wird trainiert
batch — Aktuelle Trainingsstapeldaten
batch_idx (int) — Index des aktuellen Batches
args — Zusätzliche Positionsargumente
kwargs — Zusätzliche Schlüsselwortargumente
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Geben Sie die Sperre für die Aktualisierung der Parameter am Ende jedes Trainingsstapels auf.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
pl_module (pytorch_lightning). LightningModule) — Lightning-Modul wird trainiert
outputs (STEP_OUTPUT) — Ausgaben von Trainingsschritten
batch (Any) — Aktuelle Trainingsstapeldaten
batch_idx (int) — Index des aktuellen Batches
Hinweise:
Der Zeitpunkt der Freigabe von Sperren stellt sicher, dass die Wiederherstellung ohne Checkpoint fortgesetzt werden kann, nachdem die Parameteraktualisierungen abgeschlossen sind
Wird nur ausgeführt, wenn sowohl als auch wahr sind
enable_inprocessenable_checkpointless
get_peft_callback(trainer)
Ruft den PEFT-Callback aus der Rückrufliste des Trainers ab.
Parameter:
trainer (pyTorch_Lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
Gibt zurück:
PEFT oder None — PEFT-Callback-Instanz, falls gefunden, sonst None
_try_adapter_checkpointless_restore(trainer, params_to_save)
Versuchen Sie, die PEFT-Adapterparameter ohne Checkpoint wiederherzustellen.
Parameter:
trainer (pytorch_lightning.Trainer) — Lightning-Trainer-Instanz PyTorch
params_to_save (set) — Satz von Parameternamen, die als Adapterparameter gespeichert werden sollen
Hinweise:
Wird nur einmal pro Trainingseinheit ausgeführt (wird durch das Flag gesteuert)
tried_adapter_checkpointlessKonfiguriert den Checkpoint Manager mit Adapterparameterinformationen
Beispiel
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Arbeitsspeicher-Verwaltung
clean_tensor_hook: Entfernt Tensor-Hooks während der Bereinigung (teuer, aber gründlich)
clean_lightning_module: Gibt den GPU-Speicher des Lightning-Moduls bei Neustarts frei
Beide Optionen tragen dazu bei, den Speicherbedarf bei der Fehlerbehebung zu reduzieren
Koordiniert mit ParameterUpdateLock für die Thread-sichere Nachverfolgung von Parameteraktualisierungen
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Lightning-Checkpoint-Konnektor, der die Wiederherstellung ohne Checkpoint in das herkömmliche Laden von Checkpoints auf Festplatte integriert.
Dieser Konnektor erweitert den von PyTorch _CheckpointConnector Lightning und bietet so eine nahtlose Integration zwischen der Wiederherstellung ohne Checkpoint und der standardmäßigen Checkpoint-Wiederherstellung. Es versucht zunächst eine Wiederherstellung ohne Checkpoint und greift dann auf festplattenbasiertes Laden von Checkpoints zurück, falls eine Wiederherstellung ohne Checkpoint nicht möglich ist oder fehlschlägt.
Parameter
Erbt alle Parameter von _ CheckpointConnector
Methoden
resume_start(checkpoint_path=None)
Versuchen Sie, den Checkpoint vorab mit einer Wiederherstellungspriorität ohne Checkpoint zu laden.
Parameter:
checkpoint_path (str oder None, optional) — Pfad zum Festplatten-Checkpoint für Fallback. Standard:
None
resume_end()
Schließen Sie den Checkpoint-Ladevorgang ab und führen Sie Operationen nach dem Laden durch.
Hinweise
Erweitert die interne
_CheckpointConnectorKlasse von PyTorch Lightning um Unterstützung für die Wiederherstellung ohne CheckpointBehält die volle Kompatibilität mit standardmäßigen PyTorch Lightning-Checkpoint-Workflows bei
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Wird um NeMo eine AutoResume verzögerte Einrichtung erweitert, sodass eine Überprüfung der Wiederherstellung ohne Checkpoint vor der Auflösung des Checkpoint-Pfads möglich ist.
Diese Klasse implementiert eine zweiphasige Initialisierungsstrategie, die eine Überprüfung der Wiederherstellung ohne Checkpoint ermöglicht, bevor auf das herkömmliche Laden von Checkpoints auf der Festplatte zurückgegriffen wird. Sie verzögert die AutoResume Einrichtung bedingt, um eine vorzeitige Auflösung des Checkpoint-Pfads zu verhindern, sodass zunächst geprüft werden kann, ob eine Wiederherstellung ohne Checkpoint möglich ist CheckpointManager . peer-to-peer
Parameter
Erbt alle Parameter von AutoResume
Methoden
setup(trainer, model=None, force_setup=False)
Verzögern Sie die AutoResume Einrichtung bedingt, um eine Überprüfung der Wiederherstellung ohne Checkpoint zu ermöglichen.
Parameter:
trainer (pytorch_lightning.trainer oder lightning.Fabric.Fabric) — Lightning-Trainer oder Fabric-Instanz PyTorch
model (optional) — Modellinstanz für die Einrichtung. Standard:
Noneforce_setup (bool, optional) — Bei True wird die Verzögerung umgangen und das Setup sofort ausgeführt AutoResume . Standard:
False
Beispiel
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Hinweise
Erweitert NeMo die AutoResume Klasse um einen Verzögerungsmechanismus, der eine Wiederherstellung ohne Checkpoint ermöglicht
Funktioniert in Verbindung mit
CheckpointlessCompatibleConnectorfür einen vollständigen Wiederherstellungs-Workflow
