Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Elastisches Training in Amazon verwenden SageMaker HyperPod
Elastic Training ist eine neue SageMaker HyperPod Amazon-Funktion, die Trainingsjobs automatisch auf der Grundlage der Verfügbarkeit von Rechenressourcen und der Priorität der Arbeitslast skaliert. Elastic Training Jobs können mit minimalen Rechenressourcen beginnen, die für das Modelltraining erforderlich sind, und dynamisch nach oben oder unten skaliert werden, indem automatische Checkpoints und Wiederaufnahme über verschiedene Knotenkonfigurationen hinweg (Weltgröße) durchgeführt werden. Die Skalierung wird erreicht, indem die Anzahl der datenparallelen Replikate automatisch angepasst wird. In Zeiten hoher Clusterauslastung können Elastic Training Jobs so konfiguriert werden, dass sie als Reaktion auf Ressourcenanforderungen von Jobs mit höherer Priorität automatisch herunterskaliert werden, sodass Rechenleistung für kritische Workloads zur Verfügung steht. Wenn in Zeiten mit geringer Auslastung Ressourcen frei werden, werden Elastic Training Jobs automatisch wieder hochskaliert, um das Training zu beschleunigen, und dann wieder herunterskaliert, wenn Workloads mit höherer Priorität wieder Ressourcen benötigen.
Elastic Training baut auf dem HyperPod Training des Operators auf und umfasst die folgenden Komponenten:
-
Amazon SageMaker HyperPod Task Governance für die Warteschleifenbildung, Priorisierung und Planung von Jobs
-
PyTorch Distributed Checkpoint (DCP)
für skalierbares Status- und Checkpoint-Management, wie DCP
Unterstützte Frameworks
-
PyTorch mit Distributed Data Parallel (DDP) und Fully Sharded Data Parallel (FSDP)
-
PyTorch Verteilter Checkpoint (DCP)
Voraussetzungen
SageMaker HyperPod EKS-Cluster
Sie müssen über einen laufenden SageMaker HyperPod Cluster mit Amazon EKS-Orchestrierung verfügen. Informationen zum Erstellen eines HyperPod EKS-Clusters finden Sie unter:
SageMaker HyperPod Schulung des Bedieners
Elastic Training wird in Training Operator Version 1.2 und höher unterstützt.
Informationen zur Installation des Training Operators als EKS-Add-on finden Sie unter: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Empfohlen) Installieren und konfigurieren Sie Task Governance und Warteschlange
Wir empfehlen, Kueue über HyperPod Task Governance zu installieren und zu konfigurieren, um Workload-Prioritäten mit elastischem Training festzulegen. Kueue bietet ein effizienteres Workload-Management mit Warteschlangen, Priorisierung, Gruppenplanung, Ressourcenverfolgung und automatischem Preemption, die für den Betrieb in Trainingsumgebungen mit mehreren Mandanten unerlässlich sind.
-
Die Gruppenplanung stellt sicher, dass alle erforderlichen Gruppen eines Schulungsjobs gemeinsam beginnen. Dadurch wird verhindert, dass einige Pods starten, während andere noch ausstehen, was zu einer Verschwendung von Ressourcen führen könnte.
-
Durch das sanfte Preemption-Verfahren können elastische Jobs mit niedrigerer Priorität Ressourcen für Workloads mit höherer Priorität bereitstellen. Elastic Jobs können problemlos herunterskaliert werden, ohne dass sie gewaltsam entfernt werden müssen, wodurch die allgemeine Clusterstabilität verbessert wird.
Wir empfehlen die Konfiguration der folgenden Kueue-Komponenten:
-
PriorityClasses um die relative Bedeutung der Arbeit zu definieren
-
ClusterQueues um die globale gemeinsame Nutzung von Ressourcen und Kontingente zwischen Teams oder Workloads zu verwalten
-
LocalQueues um Jobs von einzelnen Namespaces an die entsprechenden weiterzuleiten ClusterQueue
Für fortgeschrittenere Setups können Sie auch Folgendes integrieren:
-
Fair-share Richtlinien zur ausgewogenen Nutzung der Ressourcen durch mehrere Teams
-
Benutzerdefinierte Präemptionsregeln zur Durchsetzung organisatorischer SLAs oder Kostenkontrollen
Weitere Informationen finden Sie unter:
(Empfohlen) Richten Sie Benutzernamespaces und Ressourcenkontingente ein
Bei der Bereitstellung dieser Funktion auf Amazon EKS empfehlen wir, eine Reihe grundlegender Konfigurationen auf Clusterebene anzuwenden, um Isolation, Ressourcengerechtigkeit und betriebliche Konsistenz zwischen den Teams sicherzustellen.
Namespace- und Zugriffskonfiguration
Organisieren Sie Ihre Workloads mithilfe separater Namespaces für jedes Team oder Projekt. Auf diese Weise können Sie eine fein abgestufte Isolierung und Steuerung anwenden. Wir empfehlen außerdem, die RBAC-Zuordnung von AWS IAM zu Kubernetes zu konfigurieren, um einzelne IAM-Benutzer oder -Rollen ihren entsprechenden Namespaces zuzuordnen.
Zu den wichtigsten Praktiken gehören:
-
Ordnen Sie mithilfe von IAM-Rollen für Dienstkonten (IRSA) IAM-Rollen Kubernetes-Dienstkonten zu, wenn Workloads Berechtigungen benötigen. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Wenden Sie RBAC-Richtlinien an, um Benutzer nur auf ihre zugewiesenen Namespaces zu beschränken (z. B.
Role/RoleBindingstatt clusterweiter Berechtigungen).
Ressourcen- und Recheneinschränkungen
Um Ressourcenkonflikte zu vermeiden und eine faire Planung zwischen den Teams zu gewährleisten, sollten Sie Kontingente und Limits auf Namespace-Ebene einrichten:
-
ResourceQuotas um die Gesamtzahl der CPU-, Arbeitsspeicher-, Speicher- und Objektzahlen (Pods, PVCs, Dienste usw.) zu begrenzen.
-
LimitRanges um Standard- und Höchstgrenzen für CPU und Speicher pro Pod oder Container durchzusetzen.
-
PodDisruptionBudgets (PDBs) nach Bedarf, um die Erwartungen an die Ausfallsicherheit zu definieren.
-
Optional: Einschränkungen in der Namespace-level Warteschlange (z. B. über Task Governance oder Warteschlange), um zu verhindern, dass Benutzer zu viele Jobs einreichen.
Diese Einschränkungen tragen zur Aufrechterhaltung der Clusterstabilität bei und unterstützen eine vorhersehbare Planung verteilter Trainingsworkloads.
Auto-scaling
SageMaker HyperPod on EKS unterstützt die automatische Clusterskalierung über Karpenter. Wenn Karpenter oder ein ähnlicher Resource Provisioner zusammen mit elastischem Training verwendet wird, können sowohl der Cluster als auch der elastische Trainingsjob automatisch skaliert werden, nachdem ein elastischer Trainingsjob einmal eingereicht wurde. Das liegt daran, dass der Elastic Training Operator einen gierigen Ansatz verfolgt und immer mehr als die verfügbaren Rechenressourcen abfragt, bis die vom Job festgelegte Höchstgrenze erreicht ist. Dies liegt daran, dass der Elastic Training-Operator im Rahmen der Ausführung von Elastic Jobs kontinuierlich zusätzliche Ressourcen anfordert, was die Bereitstellung von Knoten auslösen kann. Continuous Resource Provisioner wie Karpenter bearbeiten die Anfragen, indem sie den Compute-Cluster skalieren.
Um diese Skalierungen vorhersehbar und unter Kontrolle zu halten, empfehlen wir, die Namespace-Ebene in den ResourceQuotas Namespaces zu konfigurieren, in denen elastische Trainingsjobs erstellt werden. ResourceQuotas helfen dabei, die maximale Anzahl an Ressourcen zu begrenzen, die Jobs anfordern können, wodurch ein unbegrenztes Clusterwachstum verhindert und dennoch elastisches Verhalten innerhalb definierter Grenzen ermöglicht wird.
Ein Beispiel ResourceQuota für 8 ml.p5.48xlarge-Instances hat das folgende Format:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Trainingscontainer erstellen
HyperPod Der Trainingsoperator arbeitet mit einem benutzerdefinierten PyTorch Launcher, der über das Python-Paket von HyperPod Elastic Agent (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun Befehl durch hyperpodrun to launch training ersetzen. Weitere Informationen finden Sie unter:
Ein Beispiel für einen Trainingscontainer:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Änderung des Trainingscodes
SageMaker HyperPod stellt eine Reihe von Rezepten bereit, die bereits für die Ausführung mit Elastic Policy konfiguriert wurden.
Um Elastic Training für benutzerdefinierte PyTorch Trainingsskripte zu aktivieren, müssen Sie kleinere Änderungen an Ihrer Trainingsschleife vornehmen. Dieser Leitfaden führt Sie durch die notwendigen Änderungen, die erforderlich sind, um sicherzustellen, dass Ihr Trainingsjob auf elastische Skalierungsereignisse reagiert, die auftreten, wenn sich die Verfügbarkeit von Rechenressourcen ändert. Bei allen elastischen Ereignissen (z. B. wenn Knoten verfügbar sind oder Knoten gesperrt werden), empfängt der Trainingsjob ein elastisches Event-Signal, das verwendet wird, um ein ordnungsgemäßes Herunterfahren zu koordinieren, indem ein Checkpoint gespeichert wird, und das Training wieder aufgenommen, indem es von diesem gespeicherten Checkpoint aus mit einer neuen Weltkonfiguration neu gestartet wird. Um Elastic Training mit benutzerdefinierten Trainingsskripten zu aktivieren, müssen Sie:
Elastic Scaling-Ereignisse erkennen
Suchen Sie in Ihrer Trainingsschleife bei jeder Iteration nach elastischen Ereignissen:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Implementieren Sie Checkpoint Saving und Checkpoint Loading
Hinweis: Wir empfehlen die Verwendung von PyTorch Distributed Checkpoint (DCP) zum Speichern von Modell- und Optimiererstatus, da DCP die Wiederaufnahme von einem Checkpoint mit unterschiedlichen Weltgrößen unterstützt. Andere Checkpoint-Formate unterstützen möglicherweise das Laden von Checkpoints auf verschiedenen Weltgrößen nicht. In diesem Fall müssen Sie eine benutzerdefinierte Logik implementieren, um dynamische Änderungen der Weltgröße zu handhaben.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Optional) Verwenden Sie Stateful-Dataloader
Wenn Sie nur für eine einzelne Epoche trainieren (d. h. einen einzigen Durchgang durch den gesamten Datensatz), muss das Modell jede Datenprobe genau einmal betrachten. Wenn der Trainingsjob in der Mitte der Epoche beendet und mit einer anderen Weltgröße wieder aufgenommen wird, werden zuvor verarbeitete Datenproben wiederholt, sofern der Dataloader-Status nicht dauerhaft ist. Ein Stateful-Dataloader verhindert dies, indem er die Position des Dataloaders speichert und wiederherstellt und so sicherstellt, dass wieder aufgenommene Läufe ab dem Elastic Scaling-Ereignis fortgesetzt werden, ohne dass Stichproben erneut verarbeitet werden. Wir empfehlen die Verwendung eines Systems StatefulDataLoadertorch.utils.data.DataLoader diese Erweiterungen state_dict() und load_state_dict() Methoden dient und das Checkpoint des Datenladevorgangs mitten in der Entwicklungsphase ermöglicht.
Elastic Training-Jobs einreichen
HyperPod Der Trainingsoperator definiert einen neuen Ressourcentyp -hyperpodpytorchjob. Elastic Training erweitert diesen Ressourcentyp und fügt die unten hervorgehobenen Felder hinzu:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Verwenden von kubectl
Anschließend können Sie das elastische Training mit dem folgenden Befehl starten.
kubectl apply -f elastic-training-job.yaml
SageMaker Rezepte verwenden
Elastische Trainingsjobs können über SageMaker HyperPod Rezepte
Anmerkung
Wir haben 46 elastische Rezepte für SFO - und DPO-Jobs auf Hyperpod Recipe hinzugefügt. Benutzer können diese Jobs starten, indem sie eine Zeile über dem vorhandenen statischen Launcher-Skript ändern:
++recipes.elastic_policy.is_elastic=true
Zusätzlich zu den statischen Rezepten fügen elastische Rezepte die folgenden Felder hinzu, um das elastische Verhalten zu definieren:
Elastische Richtlinie
Das elastic_policy Feld definiert die Konfiguration auf Jobebene für den Elastic Training-Job. Es hat die folgenden Konfigurationen:
-
is_elastic:bool- wenn es sich bei diesem Job um einen elastischen Job handelt -
min_nodes:int- die Mindestanzahl von Knoten, die für elastisches Training verwendet werden -
max_nodes:int- die maximale Anzahl von Knoten, die für elastisches Training verwendet werden -
replica_increment_step:int- Erhöhen Sie die Anzahl der Pods in Gruppen mit fester Größe. Dieses Feld schließt sich gegenseitig aus, wasscale_configwir später definieren. -
use_graceful_shutdown:bool- Wenn Sie bei Skalierungsereignissen die Option „Graceful Shutdown“ verwenden, ist dies standardmäßig der Fall.true -
scaling_timeout:int- Die Wartezeit in Sekunden während des Skalierungsereignisses vor dem Timeout -
graceful_shutdown_timeout:int- Die Wartezeit bis zum ordnungsgemäßen Herunterfahren
Im Folgenden finden Sie eine Beispieldefinition für dieses Feld. Sie finden sie auch im Hyperpod Recipe Repo im Rezept: recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Config skalieren
Das scale_config Feld definiert übergeordnete Konfigurationen für jede spezifische Skala. Es ist ein Schlüssel-Werte-Wörterbuch, wobei Schlüssel eine Ganzzahl ist, die die Zielskala darstellt, und Wert eine Teilmenge des Basisrezepts ist. Bei <key> Scale verwenden wir das, <value> um die spezifischen Konfigurationen im Rezept zu aktualisieren. base/static Im Folgenden wird ein Beispiel für dieses Feld gezeigt:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
Die obige Konfiguration definiert die Trainingskonfiguration auf den Skalen 2 und 3. In beiden Fällen verwenden wir die Lernrate4e-4, die Chargengröße von128. Aber auf Skala 2 verwenden wir einen Wert micro_train_batch_size von 8, während wir bei Skala 3 eine ungleichmäßige Chargengröße verwenden, da die Chargengröße des Zuges nicht gleichmäßig auf 3 Knoten aufgeteilt werden kann.
Ungleichmäßige Chargengröße
In diesem Feld wird das Verhalten der Stapelverteilung definiert, wenn die globale Stapelgröße nicht gleichmäßig durch die Anzahl der Ränge aufgeteilt werden kann. Es ist nicht spezifisch für elastisches Training, ermöglicht aber eine feinere Skalierungsgranularität.
-
use_uneven_batch:bool- wenn eine ungleichmäßige Chargenverteilung verwendet wird -
num_dp_groups_with_small_batch_size:int- Bei einer ungleichmäßigen Chargenverteilung verwenden einige Ränge eine kleinere lokale Chargengröße, während die anderen eine größere Chargengröße verwenden. Die globale Chargengröße sollte gleich seinsmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- Dieser Wert ist die kleinere lokale Batchgröße -
large_local_batch_size:int- Dieser Wert entspricht der größeren lokalen Batchgröße
Überwachen Sie das Training auf MLflow
Hyperpod-Rezeptjobs unterstützen die Beobachtbarkeit durch MLflow. Benutzer können MLflow-Konfigurationen im Rezept angeben:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Diese Konfigurationen sind dem entsprechenden MLFlow-Setup
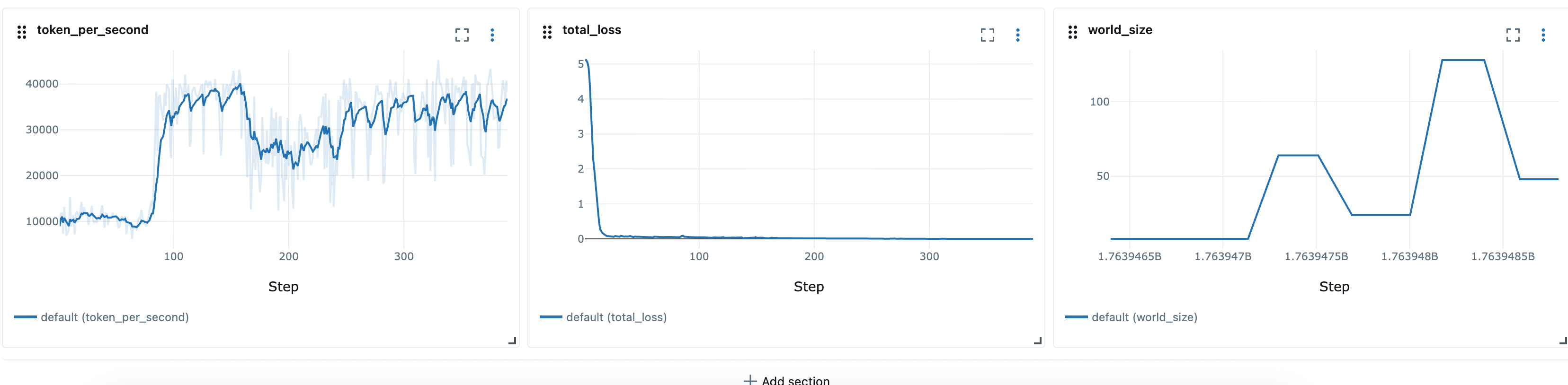
Nachdem wir die elastischen Rezepte definiert haben, können wir die Launcher-Skripte verwenden, launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh um beispielsweise einen Elastic-Training-Job zu starten. Dies ähnelt dem Starten eines statischen Jobs mit dem Hyperpod-Rezept.
Anmerkung
Der Elastic-Trainingsjob von Recipe Support wird automatisch von den letzten Checkpoints aus fortgesetzt. Standardmäßig wird jedoch bei jedem Neustart ein neues Trainingsverzeichnis erstellt. Um die Wiederaufnahme vom letzten Checkpoint aus korrekt zu ermöglichen, müssen wir sicherstellen, dass dasselbe Trainingsverzeichnis wiederverwendet wird. Dies kann durch die Einstellung erfolgen
recipes.training_config.training_args.override_training_dir=true
Use-case Beispiele und Einschränkungen
Scale-up wenn mehr Ressourcen verfügbar sind
Wenn mehr Ressourcen auf dem Cluster verfügbar werden (z. B. wenn andere Workloads abgeschlossen sind). Während dieser Veranstaltung skaliert der Trainingscontroller den Trainingsjob automatisch. Dieses Verhalten wird im Folgenden erklärt.
Um eine Situation zu simulieren, in der mehr Ressourcen verfügbar werden, können wir einen Job mit hoher Priorität einreichen und dann Ressourcen wieder freigeben, indem wir den Job mit hoher Priorität löschen.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
Erwartetes Verhalten:
-
Der Trainingsoperator erstellt einen Kueue-Workload. Wenn ein Elastic-Training-Job eine Änderung der Weltgröße anfordert, generiert der Trainingsoperator ein zusätzliches Kueue-Workload-Objekt, das die neuen Ressourcenanforderungen darstellt.
-
Kueue gibt zu, dass die Workload-Keue die Anfrage auf der Grundlage verfügbarer Ressourcen, Prioritäten und Warteschlangenrichtlinien bewertet. Nach der Genehmigung wird der Workload zugelassen.
-
Der Schulungsleiter erstellt die zusätzlichen Pods. Bei der Zulassung startet der Operator die zusätzlichen Pods, die erforderlich sind, um die neue Weltgröße zu erreichen.
-
Wenn die neuen Pods einsatzbereit sind, sendet der Schulungsleiter ein spezielles elastisches Ereignissignal an das Trainingsskript.
-
Der Trainingsjob führt Checkpoints durch, um ein ordnungsgemäßes Herunterfahren vorzubereiten. Der Trainingsprozess überprüft regelmäßig, ob das elastische Event-Signal vorliegt, indem er die Funktion elastic_event_detected () aufruft. Sobald es erkannt wurde, initiiert es einen Checkpoint. Nachdem der Checkpoint erfolgreich abgeschlossen wurde, wird der Trainingsprozess ordnungsgemäß beendet.
-
Der Schulungsoperator startet den Job mit der neuen Weltgröße neu. Der Bediener wartet, bis alle Prozesse beendet sind, und startet dann den Trainingsjob mit der aktualisierten Weltgröße und dem neuesten Checkpoint neu.
Hinweis: Wenn Kueue nicht verwendet wird, überspringt der trainierende Operator die ersten beiden Schritte. Es versucht sofort, die zusätzlichen Pods zu erstellen, die für die neue Weltgröße erforderlich sind. Wenn im Cluster nicht genügend Ressourcen verfügbar sind, verbleiben diese Pods im Status Ausstehend, bis Kapazität verfügbar ist.
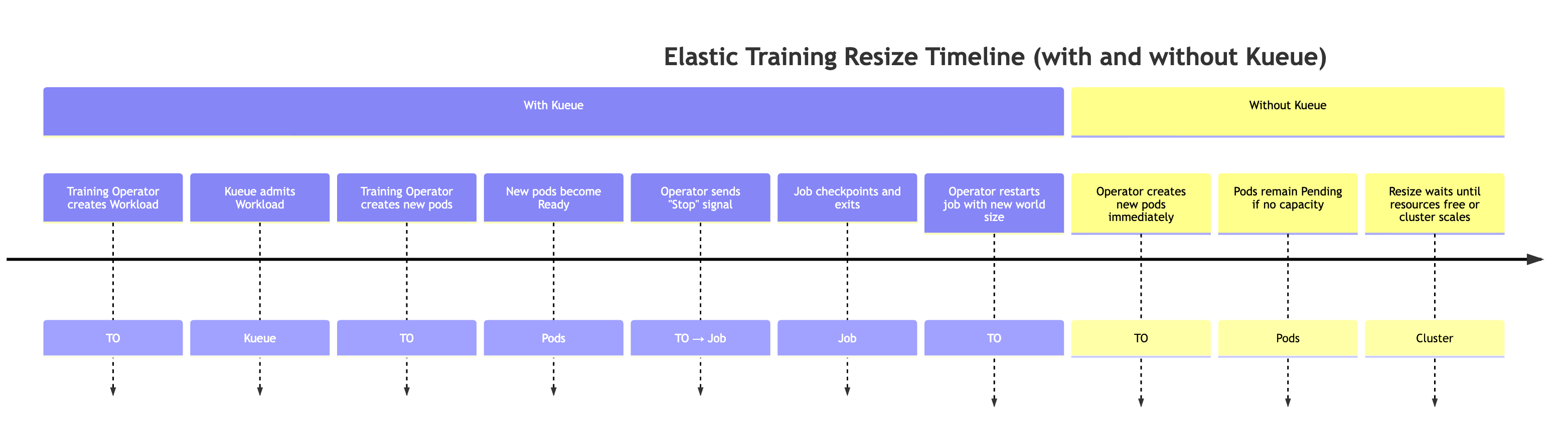
Präemption durch Aufgabe mit hoher Priorität
Elastic Jobs können automatisch herunterskaliert werden, wenn für einen Job mit hoher Priorität Ressourcen benötigt werden. Um dieses Verhalten zu simulieren, können Sie einen Elastic Training-Job einreichen, der zu Beginn des Trainings die maximale Anzahl verfügbarer Ressourcen nutzt, und anschließend einen Job mit hoher Priorität weiterleiten und das Preemption-Verhalten beobachten.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
Wenn ein Job mit hoher Priorität Ressourcen benötigt, kann Kueue Elastic Training-Workloads mit niedrigerer Priorität zuvorkommen (dem Elastic Training-Job kann mehr als ein Workload-Objekt zugeordnet sein). Der Präemptionsvorgang folgt der folgenden Reihenfolge:
-
Ein Job mit hoher Priorität wurde übermittelt. Der Job erstellt einen neuen Warteschlangenarbeitsplatz, der Workload kann jedoch aufgrund unzureichender Clusterressourcen nicht zugelassen werden.
-
Die Kueue beendet einen der Workloads des Elastic Training-Jobs. Elastische Jobs können mehrere aktive Workloads haben (einen pro Weltkonfiguration). Die Kueue wählt auf der Grundlage von Prioritäten und Warteschlangenrichtlinien eine aus, die gesperrt werden soll.
-
Der trainierende Operator sendet ein elastisches Event-Signal. Sobald die Präemption ausgelöst wurde, weist der Trainingsmitarbeiter den laufenden Trainingsprozess an, ordnungsgemäß zu beenden.
-
Der Trainingsprozess führt Checkpoints durch. Der Trainingsjob sucht regelmäßig nach elastischen Ereignissignalen. Wenn er erkannt wird, startet er einen koordinierten Checkpoint, um den Fortschritt aufrechtzuerhalten, bevor er heruntergefahren wird.
-
Der geschulte Bediener reinigt Pods und Workloads. Der Operator wartet, bis der Checkpoint abgeschlossen ist, und löscht dann die Trainings-Pods, die Teil des Workloads waren, von dem der Checkpoint ausgeschlossen wurde. Außerdem wird das entsprechende Workload-Objekt aus der Warteschlange entfernt.
-
Der Workload mit hoher Priorität wird zugelassen. Sobald die Ressourcen freigegeben sind, gibt Kueue den Job mit hoher Priorität zu, sodass er mit der Ausführung beginnen kann.
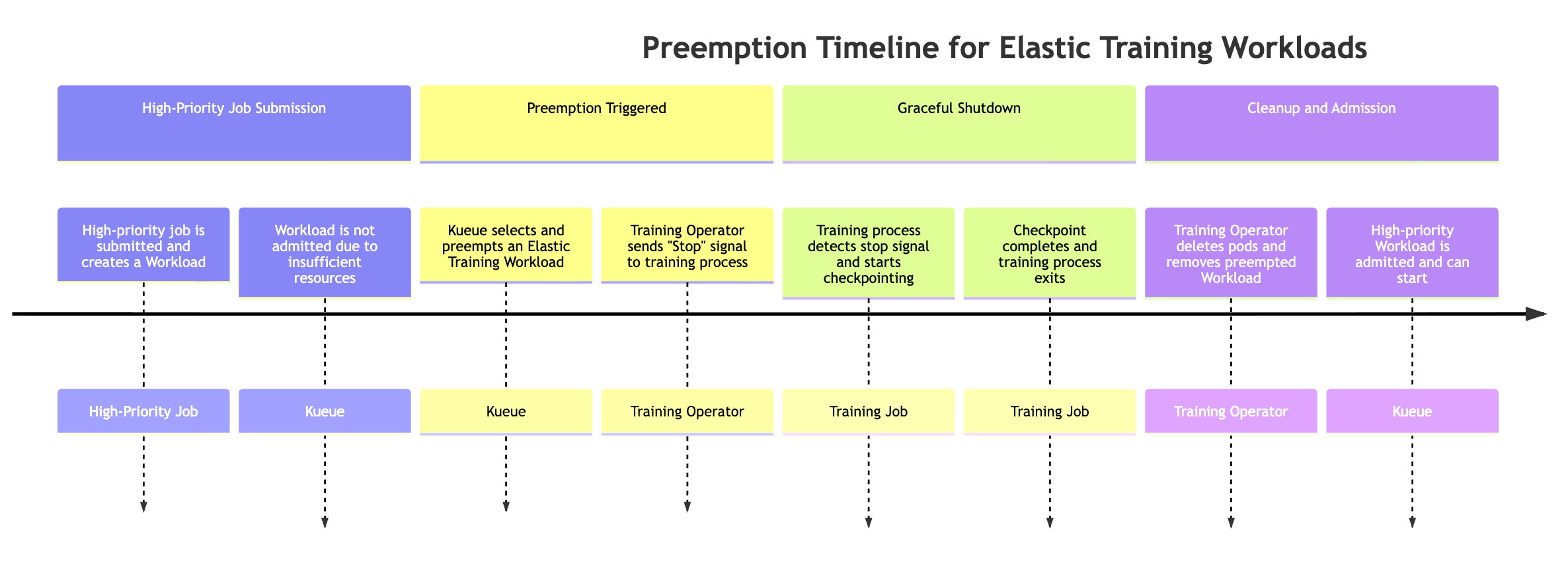
Eine Präemption kann dazu führen, dass der gesamte Trainingsjob unterbrochen wird, was möglicherweise nicht für alle Workflows wünschenswert ist. Um zu verhindern, dass die gesamte Arbeit unterbrochen wird, und gleichzeitig eine elastische Skalierung möglich ist, können Kunden innerhalb desselben Schulungsauftrags zwei verschiedene Prioritätsstufen konfigurieren, indem sie zwei Abschnitte definieren: replicaSpec
-
Eine primäre (feste) ReplicaSpec mit normaler oder hoher Priorität
-
Enthält die Mindestanzahl an Replikaten, die erforderlich sind, um den Trainingsjob am Laufen zu halten.
-
Verwendet einen höheren Wert PriorityClass, um sicherzustellen, dass diese Replikate nie zuvor gesperrt werden.
-
Behält den Basisfortschritt bei, auch wenn der Cluster unter Ressourcenauslastung steht.
-
-
Eine elastische (skalierbare) ReplicaSpec mit niedrigerer Priorität
-
Enthält die zusätzlichen optionalen Replikate, die während der elastischen Skalierung zusätzliche Rechenleistung bieten.
-
Verwendet einen niedrigeren Wert PriorityClass, sodass Kueue diesen Replikaten zuvorkommen kann, wenn Jobs mit höherer Priorität Ressourcen benötigen.
-
Stellt sicher, dass nur der elastische Teil zurückgewonnen wird, während das Rumpftraining ohne Unterbrechung fortgesetzt wird.
-
Diese Konfiguration ermöglicht eine teilweise Präemption, bei der nur die elastische Kapazität zurückgewonnen wird. Dadurch wird die Kontinuität des Trainings aufrechterhalten und gleichzeitig eine faire Aufteilung der Ressourcen in Umgebungen mit mehreren Mandanten unterstützt. Beispiel:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
Umgehung von Pods, Pod-Abstürze und Hardwareverlust:
Der HyperPod trainierende Operator verfügt über integrierte Mechanismen, mit denen der Trainingsprozess wiederhergestellt werden kann, wenn er unerwartet unterbrochen wird. Unterbrechungen können aus verschiedenen Gründen auftreten, z. B. aufgrund von Fehlern im Trainingscode, aufgrund von Pod-Räumungen, Knotenausfällen, Hardwareabbau und anderen Laufzeitproblemen.
In diesem Fall versucht der Operator automatisch, die betroffenen Pods neu zu erstellen und das Training am letzten Checkpoint fortzusetzen. Wenn eine Wiederherstellung nicht sofort möglich ist, z. B. aufgrund unzureichender Reservekapazitäten, kann der Bediener seine Fortschritte fortsetzen, indem er die Weltgröße vorübergehend reduziert und die elastische Trainingseinheit herunterskaliert.
Wenn ein elastischer Trainingsjob abstürzt oder Replikate verloren gehen, verhält sich das System wie folgt:
-
Wiederherstellungsphase (unter Verwendung von Ersatzknoten) Der Training Controller wartet, bis
faultyScaleDownTimeoutInSecondsRessourcen verfügbar sind, und versucht, die ausgefallenen Replikate wiederherzustellen, indem er Pods auf freier Kapazität erneut bereitstellt. -
Elastisches Herunterskalieren Wenn die Wiederherstellung innerhalb des Timeout-Fensters nicht möglich ist, skaliert der Schulungsleiter den Job auf eine kleinere Weltgröße (sofern die Elastizitätsrichtlinie des Jobs dies zulässt). Das Training wird dann mit weniger Wiederholungen fortgesetzt.
-
Elastisches Skalieren Wenn wieder zusätzliche Ressourcen verfügbar sind, skaliert der Operator den Schulungsjob automatisch wieder auf die bevorzugte Weltgröße.
Dieser Mechanismus stellt sicher, dass die Schulung mit minimalen Ausfallzeiten fortgesetzt werden kann, auch wenn Ressourcen knapp sind oder die Infrastruktur teilweise ausfällt, und gleichzeitig die Vorteile der elastischen Skalierung genutzt werden.
Verwenden Sie elastisches Training mit anderen HyperPod Funktionen
Elastic Training unterstützt derzeit keine Trainingsfunktionen ohne Checkpoint, HyperPod verwaltetes mehrstufiges Checkpointing oder Spot-Instances.
Anmerkung
Wir erheben regelmäßig bestimmte aggregierte und anonymisierte Betriebskennzahlen, um die Verfügbarkeit grundlegender Dienste sicherzustellen. Die Erstellung dieser Metriken erfolgt vollautomatisch und erfordert keine Überprüfung des zugrundeliegenden Trainingsaufwands des Modells durch einen Menschen. Diese Kennzahlen beziehen sich auf einen Job und die Skalierung von Abläufen, das Ressourcenmanagement und grundlegende Servicefunktionen.
