Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
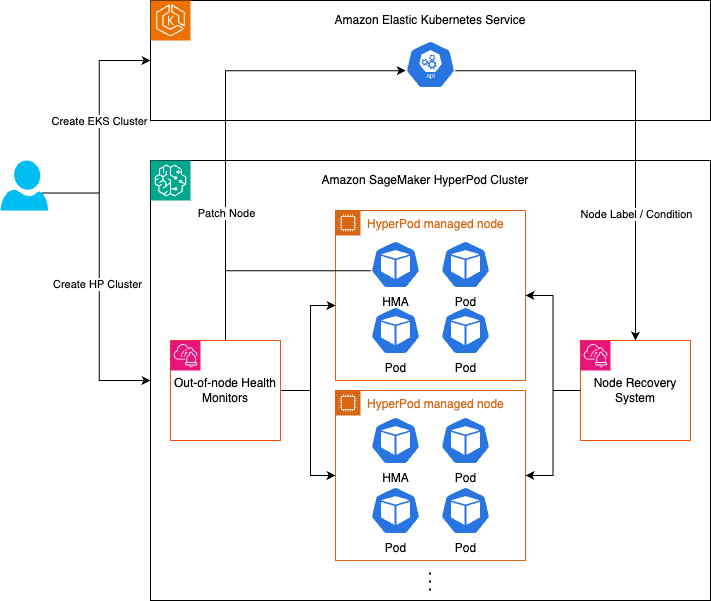
System zur Gesundheitsüberwachung
SageMaker HyperPod Das System zur Gesundheitsüberwachung besteht aus zwei Komponenten
-
In Ihren Knoten installierte Monitoring-Agenten, zu denen der Health Monitoring Agent (HMA), der als Systemmonitor auf dem Host dient, und eine Reihe von Gesundheitsmonitoren außerhalb des Knotens gehören.
-
Node Recovery System, verwaltet von. SageMaker HyperPod Das System zur Zustandsüberwachung überwacht den Zustand des Knotens kontinuierlich über Überwachungsagenten und ergreift dann automatisch Maßnahmen, wenn mithilfe des Node Recovery Systems ein Fehler erkannt wird.
Gesundheitschecks, die vom SageMaker HyperPod Gesundheitsüberwachungsbeauftragten durchgeführt werden
Der Beauftragte für die SageMaker HyperPod Gesundheitsüberwachung überprüft Folgendes.
NVIDIA-GPUs
-
Fehler in der Ausgabe
nvidia-smi -
Verschiedene Fehler in den Protokollen, die von der Amazon Elastic Compute Cloud (EC2) -Plattform generiert wurden
-
Überprüfung der GPU-Anzahl — Wenn zwischen der erwarteten Anzahl von GPUs in einem bestimmten Instance-Typ (z. B. 8 GPUs im Instance-Typ ml.p5.48xlarge) und der von zurückgegebenen Anzahl eine Diskrepanz besteht, startet HMA den Knoten neu
nvidia-smi
AWS Trainium
-
Fehler in der Ausgabe des AWS Neuron-Monitors
-
Vom Neuron-Knoten-Problemdetektor generierte Ausgaben (Weitere Informationen zum AWS Neuron-Knoten-Problemdetektor finden Sie unter Erkennung und Wiederherstellung von Knotenproblemen für AWS Neuron-Knoten in Amazon EKS-Clustern
.) -
Verschiedene Fehler in den von der Amazon EC2-Plattform generierten Protokollen
-
Überprüfung der Anzahl neuronaler Geräte — Wenn die tatsächliche Anzahl der neuronalen Geräte in einem bestimmten Instance-Typ und der von
neuron-lszurückgegebenen Anzahl nicht übereinstimmt, startet HMA den Knoten neu
Die oben genannten Prüfungen sind passiv. Die Zustandsprüfungen im Hintergrund werden kontinuierlich auf Ihren Knoten HyperPod ausgeführt. Zusätzlich zu diesen Prüfungen werden während der Erstellung und Aktualisierung von HyperPod Clustern gründliche (oder aktive) Zustandsprüfungen durchgeführt. HyperPod Erfahren Sie mehr über Deep Health Checks.
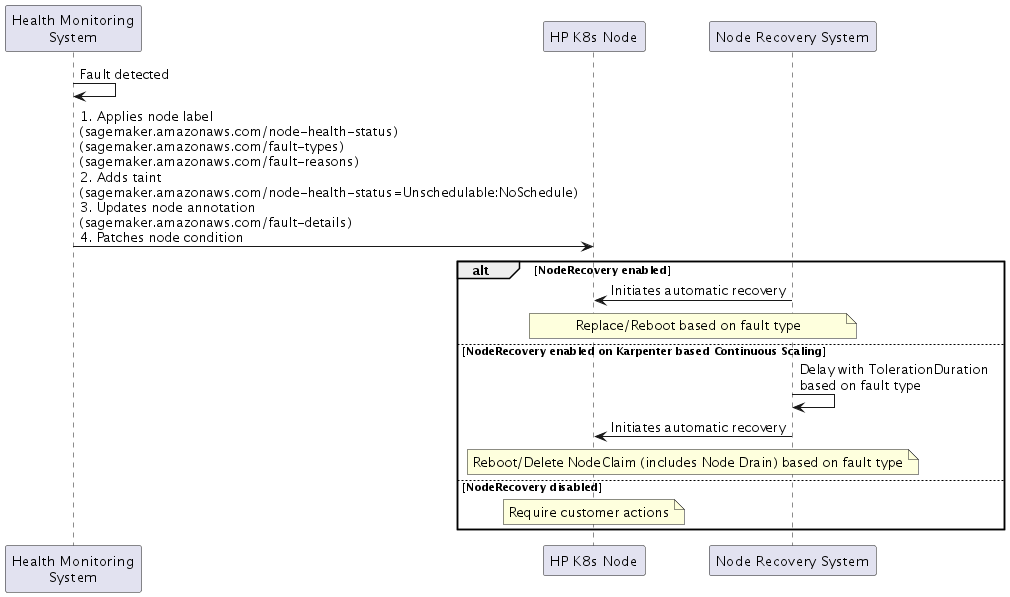
Erkennung von Fehlern
Wenn ein Fehler SageMaker HyperPod erkannt wird, wird eine vierteilige Reaktion implementiert:
-
Knotenbeschriftungen
-
Health:
sagemaker.amazonaws.com/node-health-status -
Fehlertyp:
sagemaker.amazonaws.com/fault-typesBezeichnung für eine allgemeine Kategorisierung -
Fehlergrund:
sagemaker.amazonaws.com/fault-reasonsEtikett für detaillierte Fehlerinformationen
-
-
Node Taint
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
Anmerkung zum Knoten
-
Einzelheiten zum Fehler:
sagemaker.amazonaws.com/fault-details -
Zeichnet bis zu 20 Fehler mit Zeitstempeln auf, die auf dem Knoten aufgetreten sind
-
-
Knotenbedingungen (Kubernetes-Knotenzustand
) -
Spiegelt den aktuellen Gesundheitszustand in den Knotenbedingungen wider:
-
Typ: Entspricht dem Fehlertyp
-
Status:
True -
Grund: Entspricht dem Fehlergrund
-
LastTransitionTime: Zeit des Auftretens des Fehlers
-
-
Vom SageMaker HyperPod Health Monitoring-Agenten generierte Protokolle
Der SageMaker HyperPod Health Monitoring Agent ist eine sofort einsatzbereite Funktion zur Integritätsprüfung und wird kontinuierlich auf allen Clustern ausgeführt. HyperPod Der Health Monitoring Agent veröffentlicht erkannte Integritätsereignisse auf GPU- oder Trn-Instances in der Cluster-Protokollgruppe CloudWatch . /aws/sagemaker/Clusters/
Die Erkennungsprotokolle des HyperPod Health Monitoring Agents werden als separate Protokollstreams erstellt, die SagemakerHealthMonitoringAgent nach jedem Knoten benannt sind. Sie können die Erkennungsprotokolle mithilfe von CloudWatch Log Insights wie folgt abfragen.
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
Dies sollte eine Ausgabe ähnlich der folgenden erzeugen.
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
