Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bereitstellen von Modellen mit Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference ist eine speziell entwickelte Inferenzoption, mit der Sie ML-Modelle bereitstellen und skalieren können, ohne die zugrunde liegende Infrastruktur konfigurieren oder verwalten zu müssen. On-demand Serverless Inference ist ideal für Workloads, bei denen es zwischen den einzelnen Datenverkehrsspitzen Leerlaufzeiten gibt, und die Kaltstarts tolerieren können. Serverless Endpunkte starten automatisch Rechenressourcen und skalieren sie je nach Datenverkehr ein- und auswärts, sodass Sie keine Instance-Typen auswählen oder Skalierungsrichtlinien verwalten müssen. Dadurch entfällt die undifferenzierte Schwerstarbeit bei der Auswahl und Verwaltung von Servern. Serverless Inference lässt sich mit AWS Lambda integrieren und bietet Ihnen Hochverfügbarkeit, integrierte Fehlertoleranz und automatische Skalierung. Mit einem Pay-per-Use-Modell ist Serverless Inference eine kostengünstige Option, wenn Sie ein seltenes oder unvorhersehbares Datenverkehrsmuster haben. In Zeiten, in denen keine Anfragen vorliegen, skaliert Serverless Inference Ihren Endpunkt auf 0 herunter und hilft Ihnen so, Ihre Kosten zu minimieren. Weitere Informationen zu den Preisen für serverlose On-Demand-Inferenz finden Sie unter SageMaker Amazon-Preise
Optional können Sie auch Provisioned Concurrency mit Serverless Inference verwenden. Serverlose Inferenz mit bereitgestellter Parallelität ist eine kostengünstige Option, wenn Sie vorhersehbare Datenverkehrsspitzen haben. Mit Provisioned Concurrency können Sie Modelle auf serverlosen Endpunkten mit vorhersehbarer Leistung und hoher Skalierbarkeit bereitstellen, indem Ihre Endgeräte warm gehalten werden. SageMaker KI stellt sicher, dass für die Anzahl von Provisioned Concurrency, die Sie zuweisen, die Rechenressourcen initialisiert werden und innerhalb von Millisekunden bereit sind, zu reagieren. Bei Serverless Inference with Provisioned Concurrency zahlen Sie für die Rechenkapazität, die zur Verarbeitung von Inferenzanfragen verwendet wird, die pro Millisekunde abgerechnet wird, und für die Menge der verarbeiteten Daten. Sie zahlen auch für die Nutzung von Provisioned Concurrency auf der Grundlage des konfigurierten Speichers, der Bereitstellungsdauer und der Anzahl der aktivierten Parallelität. Weitere Informationen zu den Preisen für Serverless Inference with Provisioned Concurrency finden Sie unter Amazon-Preise. SageMaker
Sie können Serverless Inference in Ihre MLOps-Pipelines integrieren, um Ihren ML-Workflow zu optimieren, und Sie können einen Serverless Endpunkt verwenden, um ein bei Model Registry registriertes Modell zu hosten.
Serverless Inference ist generell in 21 AWS Regionen verfügbar: USA Ost (Nord-Virginia), USA Ost (Ohio), USA West (Nordkalifornien), USA West (Oregon), Afrika (Kapstadt), Asien-Pazifik (Hongkong), Asien-Pazifik (Mumbai), Asien-Pazifik (Tokio), Asien-Pazifik (Seoul), Asien-Pazifik (Osaka), Asien-Pazifik (Singapur), Asien-Pazifik (Sydney), Kanada (Zentral), Europa (Frankfurt), Europa (Irland), Europa (London), Europa (Paris), Europa (Stockholm), Europa (Mailand), Naher Osten (Bahrain), Südamerika (São Paulo). Weitere Informationen zur regionalen Verfügbarkeit von Amazon SageMaker AI finden Sie in der Liste der AWS regionalen Dienste
Funktionsweise
Das folgende Diagramm zeigt den Arbeitsablauf von serverloser On-Demand-Inferenz und die Vorteile der Verwendung eines Serverless Endpunkts.
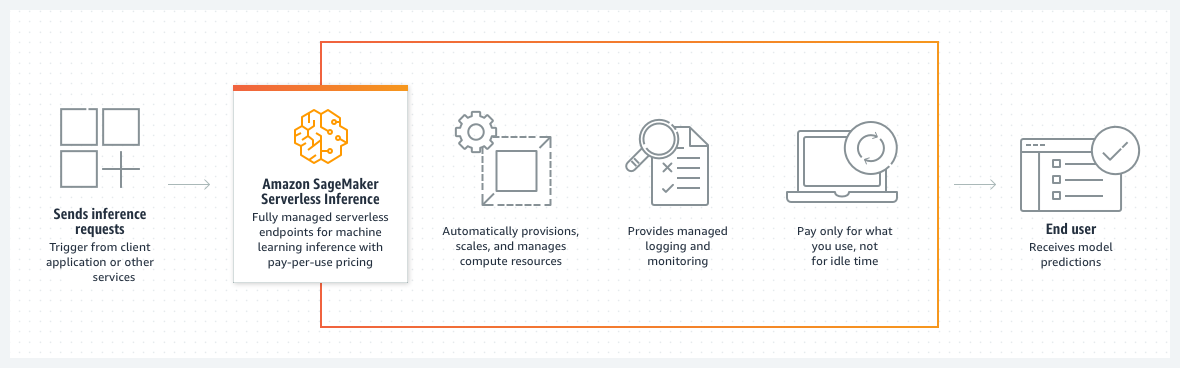
Wenn Sie einen serverlosen On-Demand-Endpunkt einrichten, SageMaker stellt KI die Rechenressourcen für Sie bereit und verwaltet sie. Anschließend können Sie Inferenzanfragen an den Endpunkt stellen und als Antwort Modellvorhersagen erhalten. SageMaker KI skaliert die Rechenressourcen je nach Bedarf hoch und runter, um Ihren Anforderungsverkehr zu bewältigen, und Sie zahlen nur für das, was Sie tatsächlich nutzen.
Für Provisioned Concurrency ist Serverless Inference auch in Application Auto Scaling integriert, sodass Sie Provisioned Concurrency auf der Grundlage einer Zielmetrik oder eines Zeitplans verwalten können. Weitere Informationen finden Sie unter Automatische Skalierung der bereitgestellten Gleichzeitigkeit für einen Serverless Endpunkt.
In den folgenden Abschnitten finden Sie zusätzliche Informationen zu Serverless Inference und seiner Funktionsweise.
Themen
Container-Support
Für Ihren Endpunkt-Container können Sie entweder einen SageMaker AI-provided Container wählen oder Ihren eigenen mitbringen. SageMaker AI bietet Container für seine integrierten Algorithmen und vorgefertigte Docker-Images für einige der gängigsten Frameworks für maschinelles Lernen wie Apache MXNet, TensorFlow PyTorch, und Chainer. Eine Liste der verfügbaren SageMaker Images finden Sie unter Verfügbare Deep Learning Containers Learning-Container-Images
Die maximale Größe des Container-Images, das Sie verwenden können, ist 10 GB. Für serverlose Endpunkte empfehlen wir, nur einen Worker im Container zu erstellen und nur eine Kopie des Modells zu laden. Beachten Sie, dass dies anders ist als bei Echtzeit-Endpunkten, bei denen einige SageMaker KI-Container möglicherweise einen Worker für jede vCPU erstellen, um Inferenzanfragen zu verarbeiten und das Modell in jeden Worker zu laden.
Wenn Sie bereits über einen Container für einen Echtzeit-Endpunkt verfügen, können Sie denselben Container für Ihren Serverless Endpunkt verwenden, obwohl einige Funktionen ausgeschlossen sind. Weitere Informationen zu den Container-Funktionen, die in Serverless Inference nicht unterstützt werden, finden Sie unter Exklusive Features. Wenn Sie sich dafür entscheiden, denselben Container zu verwenden, SageMaker hinterlegt KI eine Kopie Ihres Container-Images, bis Sie alle Endpunkte löschen, die das Image verwenden. SageMaker KI verschlüsselt das kopierte Bild im Ruhezustand mit einem Schlüssel. SageMaker AI-owned AWS KMS
Arbeitsspeichergröße
Ihr serverloser Endpunkt hat eine minimale RAM-Größe von 1024 MB (1 GB), und die maximale RAM-Größe, die Sie wählen können, beträgt 6144 MB (6 GB). Die Speichergrößen, die Sie wählen können, sind: 048 MB, 3 072 MB, 4 096 MB, 5 120 MB oder 6 144 MB. Serverlose Inferenz weist Rechenressourcen automatisch proportional zum ausgewählten Speicher zu. Wenn Sie eine größere Speichergröße wählen, hat Ihr Container Zugriff auf mehr vCPUs. Wählen Sie die Speichergröße Ihres Endpunkts entsprechend Ihrer Modellgröße. Im Allgemeinen sollte die Speichergröße mindestens so groß sein wie Ihre Modellgröße. Möglicherweise müssen Sie einen Benchmark durchführen, um die richtige Speicherauswahl für Ihr Modell auf der Grundlage Ihrer Latenz-SLAs auszuwählen. Eine schrittweise Anleitung zum Benchmarking finden Sie unter Einführung in das Amazon SageMaker Serverless Inference Benchmarking
Unabhängig von der ausgewählten Speichergröße stehen Ihrem Serverless Endpunkt 5 GB flüchtiger Festplattenspeicher zur Verfügung. Hilfe zu Problemen mit Containerberechtigungen bei der Arbeit mit Speicher finden Sie unter Fehlerbehebung.
Gleichzeitige Aufrufe
On-demand Serverless Inference verwaltet vordefinierte Skalierungsrichtlinien und Kontingente für die Kapazität Ihres Endpunkts. Serverlose Endgeräte haben ein Kontingent dafür, wie viele gleichzeitige Aufrufe gleichzeitig verarbeitet werden können. Wenn der Endpunkt aufgerufen wird, bevor er die Verarbeitung der ersten Anfrage abgeschlossen hat, verarbeitet er die zweite Anfrage gleichzeitig.
Die gesamte Parallelität, die Sie zwischen allen Serverless Endpunkten in Ihrem Konto teilen können, hängt von Ihrer Region ab:
-
Für die Regionen USA Ost (Ohio), USA Ost (N. Virginia), USA West (Oregon), Asien-Pazifik (Singapur), Asien-Pazifik (Sydney), Asien-Pazifik (Tokio), Europa (Frankfurt) und Europa (Irland) beträgt die Gesamtzahl der Gleichzeitigkeit, die Sie zwischen allen Serverless Endpunkten pro Region in Ihrem Konto teilen können, 1000.
-
Für die Regionen USA-West (Nordkalifornien), Afrika (Kapstadt), Asien-Pazifik (Hongkong), Asien-Pazifik (Mumbai), Asien-Pazifik (Osaka), Asien-Pazifik (Seoul), Kanada (Zentral), Europa (London), Europa (Mailand), Europa (Paris), Europa (Stockholm), Naher Osten (Bahrain) und Südamerika (São Paulo) beträgt die Gesamtzahl der Gleichzeitigkeiten pro Region auf Ihrem Konto 500.
Sie können die maximale Parallelität für einen einzelnen Endpunkt auf bis zu 200 festlegen, und die Gesamtzahl der Serverless Endpunkte, die Sie in einer Region hosten können, beträgt 50. Die maximale Parallelität für einen einzelnen Endpunkt verhindert, dass dieser Endpunkt alle für Ihr Konto zulässigen Aufrufe annimmt, und alle Endpunktaufrufen, die über das Maximum hinausgehen, werden gedrosselt.
Anmerkung
Die bereitgestellte Parallelität, die Sie einem Serverless Endpunkt zuweisen, sollte immer kleiner oder gleich der maximalen Parallelität sein, die Sie diesem Endpunkt zugewiesen haben.
Informationen zum Festlegen der maximalen Parallelität für Ihren Endpunkt finden Sie unterEine Endpunktkonfiguration erstellen. Weitere Informationen zu Kontingenten und Limits finden Sie unter Amazon SageMaker AI-Endpunkte und Kontingente in der Allgemeine AWS-Referenz. Wenn Sie ein höheren Service-Limit anfordern möchten, kontaktieren Sie AWS -Support
Minimierung von Cold-Starts
Wenn Ihr On-Demand-Endpunkt für serverlose Inferenz eine Zeit lang keinen Datenverkehr empfängt und Ihr Endpunkt dann plötzlich neue Anfragen erhält, kann es einige Zeit dauern, bis Ihr Endpunkt die Rechenressourcen für die Verarbeitung der Anfragen aktiviert hat. Dies wird als Kaltstart bezeichnet. Da serverlose Endgeräte Rechenressourcen bei Bedarf bereitstellen, kann es bei Ihrem Endpunkt zu Kaltstarts kommen. Ein Kaltstart kann auch auftreten, wenn Ihre gleichzeitigen Anfragen die aktuelle Auslastung der gleichzeitigen Anfragen überschreiten. Die Kaltstartzeit hängt von Ihrer Modellgröße, der Dauer des Herunterladens Ihres Modells und der Startzeit Ihres Containers ab.
Um zu überwachen, wie lang Ihre Kaltstartzeit ist, können Sie die CloudWatch Amazon-Metrik verwenden, OverheadLatency um Ihren serverlosen Endpunkt zu überwachen. Diese Metrik verfolgt die Zeit, die benötigt wird, um neue Rechenressourcen für Ihren Endpunkt zu starten. Weitere Informationen zur Verwendung von CloudWatch Metriken mit serverlosen Endpunkten finden Sie unter. Alarme und Protokolle zur Verfolgung von Metriken von Serverless-Endpunkten
Sie können Kaltstarts minimieren, indem Sie Provisioned Concurrency verwenden. SageMaker KI hält den Endpunkt warm und bereit, innerhalb von Millisekunden zu reagieren, und zwar für die Anzahl von Provisioned Concurrency, die Sie zugewiesen haben.
Exklusive Features
Einige der derzeit für SageMaker AI Real-time Inference verfügbaren Funktionen werden für Serverless Inference nicht unterstützt, darunter GPUs, AWS Marketplace-Modellpakete, private Docker-Register, Multi-Model Endpunkte, VPC-Konfiguration, Netzwerkisolierung, Datenerfassung, mehrere Produktionsvarianten, Model Monitor und Inferenz-Pipelines.
Sie können Ihren instance-basierten Echtzeit-Endpunkt nicht in einen Serverless Endpunkt umwandeln. Wenn Sie versuchen, Ihren Echtzeit-Endpunkt auf Serverless Endpunkt umzustellen, erhalten Sie eine ValidationError Meldung. Sie können einen Serverless Endpunkt in einen Echtzeit-Endpunkt umwandeln, aber sobald Sie das Update vorgenommen haben, können Sie es nicht mehr auf serverlos zurücksetzen.
Erste Schritte
Sie können einen serverlosen Endpunkt mit der SageMaker AI-Konsole, den AWS SDKs, dem Amazon SageMaker Python SDK
Anmerkung
Application Auto Scaling for Serverless Inference with Provisioned Concurrency wird derzeit auf AWS CloudFormation nicht unterstützt.
Beispiele für Notebooks und Blogs
Beispiele für Jupyter Notebooks, die durchgängige Workflows für serverlose Endgeräte zeigen, finden Sie in den Beispiel-Notebooks für Serverless Inference
