Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen einer benutzerdefinierte Vorlage für Auftragnehmeraufgaben
Um einen benutzerdefinierten Kennzeichnungsauftrag zu erstellen, müssen Sie die Worker-Aufgabenvorlage aktualisieren, die Eingabedaten aus Ihrer Manifestdatei den in der Vorlage verwendeten Variablen zuordnen und die Ausgabedaten Amazon S3 zuordnen. Weitere Informationen zu erweiterten Features, die Liquid-Automatisierung verwenden, finden Sie unter Hinzufügen von Automation mit Liquid.
In den folgenden Abschnitten wird jeder erforderliche Schritt beschrieben.
Worker-Aufgabenvorlage
Eine Vorlage für Auftragnehmeraufgaben ist eine Datei, die Ground Truth zur Anpassung der Worker-Benutzeroberfläche (UI) verwendet. Sie können eine Worker-Aufgabenvorlage mit HTML, CSS JavaScript, der Liquid-Vorlagensprache
In den folgenden Themen erfahren Sie, wie Sie eine Worker-Aufgabenvorlage erstellen können. Ein Repository mit Beispielvorlagen für Ground Truth Worker-Aufgaben finden Sie unter GitHub
Verwenden Sie die Base-Worker-Aufgabenvorlage in der SageMaker AI-Konsole
Mithilfe eines Vorlageneditors in der Ground-Truth-Konsole können Sie eine Vorlage erstellen. Dieser Editor enthält eine Reihe von vorgefertigten Basisvorlagen. Er unterstützt das automatische Ausfüllen von HTML- und Crowd-HTML-Elementcode.
So greifen Sie auf den Ground-Truth-Editor für benutzerdefinierte Vorlagen zu:
-
Folgen Sie den Anweisungen in Erstellen eines Kennzeichnungsauftrags (Konsole).
-
Wählen Sie dann Benutzerdefiniert für den Aufgabentyp des Kennzeichnungsauftrags aus.
-
Wählen Sie Weiter aus. Anschließend können Sie im Abschnitt Einrichtung der benutzerdefinierten Labeling-Aufgabe auf den Vorlageneditor und die Basisvorlagen zugreifen.
-
(Optional) Wählen Sie im Dropdown-Menü unter Vorlagen eine Basisvorlage aus. Wenn Sie eine Vorlage lieber von Grund auf neu erstellen möchten, wählen Sie im Dropdown-Menü die Option Benutzerdefiniert aus, um ein minimales Vorlagengerüst zu erhalten.
Im folgenden Abschnitt erfahren Sie, wie Sie eine in der Konsole entwickelte Vorlage lokal visualisieren können.
Lokales Visualisieren Ihrer Worker-Aufgabenvorlagen
Sie müssen die Konsole verwenden, um zu testen, wie Ihre Vorlage eingehende Daten verarbeitet. Um das Erscheinungsbild der HTML- und benutzerdefinierten Elemente Ihrer Vorlage zu testen, können Sie Ihren Browser verwenden.
Anmerkung
Variablen werden nicht analysiert. Möglicherweise müssen Sie sie durch Beispielinhalte ersetzen, während Sie Ihre Inhalte lokal anzeigen.
Der folgende Beispielcodeausschnitt lädt den erforderlichen Code zum Rendern der benutzerdefinierten HTML-Elemente. Verwenden Sie dies, wenn Sie das Erscheinungsbild Ihrer Vorlage lieber in Ihrem bevorzugten Editor und nicht in der Konsole entwickeln möchten.
Beispiel
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
Erstellen eines einfachen HTML-Aufgabenbeispiels
Da Sie nun über die Basis-Worker-Aufgabenvorlage verfügen, können Sie dieses Thema verwenden, um eine einfache HTML-based Aufgabenvorlage zu erstellen.
Es folgt ein Beispieleintrag aus einer Eingabemanifestdatei.
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
In der HTML-Aufgabenvorlage müssen die Variablen aus der Eingabemanifestdatei der Vorlage zugeordnet werden. Die Variable aus dem Beispiel-Eingabemanifest würde anhand der folgenden Syntax zugeordnet: task.input.source, task.input.labels und task.input.header.
Im Folgenden finden Sie ein einfaches Beispiel für eine HTML-Worker-Aufgabenvorlage für die Tweet-Analyse. Alle Aufgaben beginnen und enden mit den <crowd-form> </crowd-form>-Elementen. Wie bei Standard-HTML-<form>-Elementen sollte der gesamte Formularcode zwischen ihnen platziert werden. Ground Truth generiert die Aufgaben der Auftragnehmer direkt aus dem in der Vorlage angegebenen Kontext, es sei denn, Sie implementieren ein Lambda mit Vorverarbeitung. Das von Ground Truth zurückgegebene taskInput-Objekt oder Pre-annotation Lambda ist das task.input-Objekt in Ihren Vorlagen.
Für eine einfache Tweet-Analyseaufgabe verwenden Sie das <crowd-classifier>-Element. Es erfordert die folgenden Attribute:
name – der Name Ihrer Ausgabevariablen. Anmerkungen von Auftragnehmern werden unter diesem Variablennamen in Ihrem Ausgabemanifest gespeichert.
categories (Kategorien) – ein JSON-formatiertes Array der möglichen Antworten.
header (Header) – ein Titel für das Anmerkungstool.
Das <crowd-classifier>-Element benötigt mindestens die drei folgenden untergeordneten Elemente.
<classification-target> – der Text, den der Auftragnehmer basierend auf den Optionen klassifiziert, die im
categories-Attribut oben angegeben wurden<full-instructions> – Anweisungen, die über den Link „Vollständige Anweisungen anzeigen“ im Tool verfügbar sind Dies kann leer bleiben, aber es wird empfohlen, dass Sie gute Anweisungen geben, um bessere Ergebnisse zu erzielen.
<short-instructions> – eine kurze Beschreibung der Aufgabe, die in der Seitenleiste des Tools angezeigt wird Dies kann leer bleiben, aber es wird empfohlen, dass Sie gute Anweisungen geben, um bessere Ergebnisse zu erzielen.
Eine einfache Version dieses Tools würde wie folgt aussehen. Die Variable {{ task.input.source }} gibt die Quelldaten aus Ihrer Eingabemanifestdatei an. {{ task.input.labels | to_json }} ist ein Beispiel für einen variablen Filter, durch den das Array in eine JSON-Darstellung umgewandelt wird. Das categories-Attribut muss JSON sein.
Beispiel zur Verwendung von Crowd-Classifier mit dem Beispiel-Eingabemanifest json
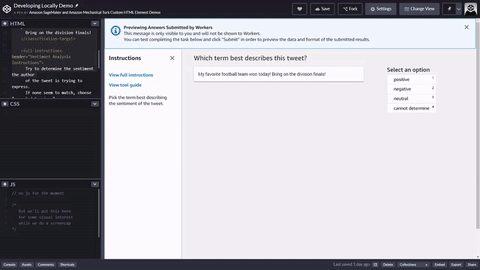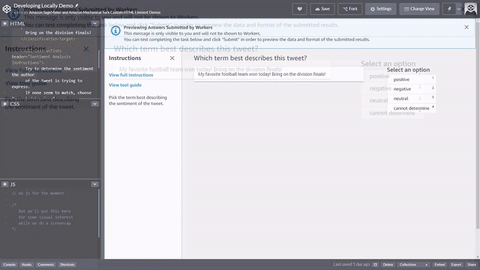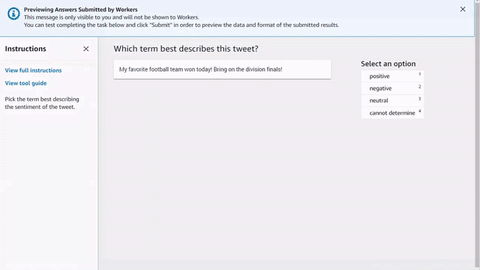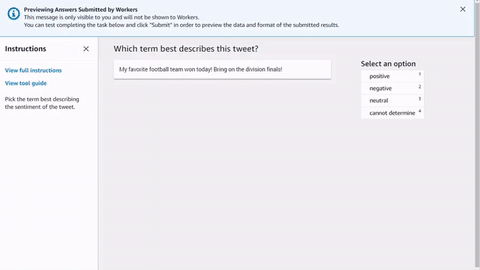
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
Sie können den Code kopieren und in den Editor des Workflows zur Erstellung von Ground Truth Labeling-Jobs einfügen, um eine Vorschau des Tools anzuzeigen, oder eine Demo dieses Codes ausprobieren CodePen.
Eingabedaten, externe Ressourcen und Ihre Aufgabenvorlage
Die folgenden Abschnitte beschreiben die Verwendung externer Ressourcen, die Anforderungen an das Eingabedatenformat und, wann die Verwendung der Lambda-Funktionen zur Vorverarbeitung in Betracht gezogen werden sollte.
Anforderungen an das Eingabedatenformat
Wenn Sie eine Eingabemanifestdatei für Ihren benutzerdefinierten Ground-Truth-Kennzeichnungsauftrag erstellen, müssen Sie die Daten in Amazon S3 speichern. Die Eingabemanifestdateien müssen auch in derselben Datei gespeichert werden, AWS-Region in der Ihr benutzerdefinierter Ground Truth Truth-Labeling-Job ausgeführt werden soll. Darüber hinaus kann sie in jedem Amazon-S3-Bucket gespeichert werden, auf den die IAM-Servicerolle zugreifen kann, die Sie verwenden, um Ihren benutzerdefinierten Kennzeichnungsauftrag in Ground Truth auszuführen.
Eingabemanifestdateien müssen das durch Zeilenumbruch getrennte JSON- oder JSON-Zeilenformat verwenden. Jede Zeile wird durch einen Standardzeilenumbruch getrennt, \n oder \r\n. Jede Zeile muss auch ein gültiges JSON-Objekt sein.
Darüber hinaus muss jedes JSON-Objekt in der Manifestdatei einen der folgenden Schlüssel enthalten: source-ref oder source. Der Wert der Schlüssel wird wie folgt festgelegt:
-
source-ref– Die Quelle des Objekts ist das im Wert angegebene Amazon-S3-Objekt. Verwenden Sie diesen Wert, wenn es sich bei dem Objekt um ein binäres Objekt handelt, z. B. ein Bild. -
source– Die Quelle des Objekts ist der Wert. Verwenden Sie diesen Wert, wenn das Objekt ein Textwert ist.
Weitere Informationen zum Formatieren Ihrer Eingabemanifestdateien finden Sie unter Eingabemanifestdateien.
Pre-annotation Lambda-Funktion
Sie können optional eine Lambda-Funktion zur Vorverarbeitung angeben, um zu verwalten, wie Daten aus Ihrer Eingabemanifestdatei vor der Kennzeichnung behandelt werden. Wenn Sie das Schlüssel-Wert-Paar isHumanAnnotationRequired angegeben haben, müssen Sie eine Lambda-Funktion zur Vorverarbeitung verwenden. Wenn Ground Truth der Lambda-Funktion zur Vorverarbeitung eine Anforderung im JSON-Format sendet, verwendet sie die folgenden Schemas.
Beispiel Datenobjekt, das mit dem Schlüssel-Wert-Paar Source-Ref identifiziert wurde
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
Beispiel Datenobjekt, das mit dem Quell-Schlüssel-Wert-Paar identifiziert wurde
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
Es folgt die erwartete Reaktion der Lambda-Funktion, wenn isHumanAnnotationRequired verwendet wird.
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
Verwenden externer Assets
Benutzerdefinierte Vorlagen von Amazon SageMaker Ground Truth ermöglichen das Einbetten externer Skripts und Stylesheets. Der folgende Codeblock zeigt beispielsweise, wie Sie Ihrer Vorlage ein Stylesheet hinzufügen würden, das sich unter https://www.example.com/my-enhancement-styles.css befindet.
Beispiel
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
Wenn Fehler auftreten, stellen Sie sicher, dass Ihr Ursprungsserver den richtigen MIME-Typ und die richtigen Kodierungskopfzeilen mit den Assets sendet.
MIME- und Kodierungstypen für Remote-Skripts sind beispielsweise: application/javascript;CHARSET=UTF-8.
Der MIME- und Kodierungs-Typ für Remote-Stylesheets ist: text/css;CHARSET=UTF-8.
Ausgabedaten und Ihre Aufgabenvorlage
Die folgenden Abschnitte beschreiben die Ausgabedaten eines benutzerdefinierten Kennzeichnungsauftrags und, wann die Verwendung einer Lambda-Funktion zur Vorverarbeitung in Betracht gezogen werden sollte.
Ausgabedaten
Wenn Ihr benutzerdefinierter Kennzeichnungsauftrag abgeschlossen ist, werden die Daten im Amazon-S3-Bucket gespeichert, der bei der Erstellung des Kennzeichnungsauftrags angegeben wurde. Die Daten werden in einer output.manifest-Datei gespeichert.
Anmerkung
labelAttributeNameist eine Platzhaltervariable. In Ihrer Ausgabe ist dies entweder der Name Ihres Kennzeichnungsauftrags oder der Kennzeichnungsattributname, den Sie bei der Erstellung des Kennzeichnungsauftrags angeben.
-
sourceodersource-ref– entweder die Zeichenfolge oder eine S3-URI, um deren Kennzeichnung die Auftragnehmer gebeten wurden -
labelAttributeName– ein Wörterbuch, das konsolidierte Kennzeichnungsinhalte aus der Lambda-Funktion zur Vorverarbeitung enthält. Wenn keine Lambda-Funktion zur Vorverarbeitung angegeben ist, ist dieses Wörterbuch leer. -
labelAttributeName-metadata– Metadaten aus Ihrem benutzerdefinierten Kennzeichnungsauftrag, die von Ground Truth hinzugefügt wurden -
worker-response-ref– die S3-URI des Buckets, in dem die Daten gespeichert sind. Wenn eine Lambda-Funktion zur Vorverarbeitung angegeben wird, wird dieses Schlüssel-Wert-Paar nicht angezeigt.
In diesem Beispiel wird das JSON-Objekt aus Gründen der Lesbarkeit formatiert, in der tatsächlichen Ausgabedatei befindet sich das JSON-Objekt in einer einzelnen Zeile.
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
Verwenden der Lambda-Nachbearbeitung zur Konsolidierung der Ergebnisse Ihrer Auftragnehmer
Standardmäßig speichert Ground Truth die Antworten der Auftragnehmer unbearbeitet in Amazon S3. Um eine genauere Kontrolle darüber zu haben, wie Antworten behandelt werden, können Sie eine Lambda-Funktion zur Nachbearbeitung angeben. Beispielsweise könnte eine Lambda-Funktion zur Nachbearbeitung verwendet werden, um Anmerkungen zu konsolidieren, wenn mehrere Auftragnehmer dasselbe Datenobjekt gekennzeichnet haben. Weitere Informationen zum Erstellen von Lambda-Funktionen zur Nachbearbeitung finden Sie unter Post-annotation Lambda.
Wenn Sie eine Lambda-Funktion zur Nachbearbeitung verwenden möchten, muss sie als Teil der AnnotationConsolidationConfig in einer CreateLabelingJob-Anforderung angegeben werden.
Weitere Informationen zur Funktionsweise der Konsolidierung von Anmerkungen finden Sie unter Anmerkungskonsolidierung.
