Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Kategorisieren von Text anhand der Textklassifizierung (Single-Label)
Verwenden Sie die Textklassifizierung, um Artikel und Text in vordefinierte Kategorien zu einzuteilen. Sie können beispielsweise die Textklassifizierung verwenden, um die in einer Rezension vermittelte Stimmung oder die Emotionen zu identifizieren, die einem Textabschnitt zugrunde liegen. Verwenden Sie die Textklassifizierung von Amazon SageMaker Ground Truth, damit Mitarbeiter Text in von Ihnen definierte Kategorien sortieren. Sie erstellen einen Auftrag zur Kennzeichnung der Textklassifizierung mithilfe des Ground Truth-Bereichs der Amazon SageMaker AI-Konsole oder der CreateLabelingJobOperation.
Wichtig
Wenn Sie manuell eine Eingabemanifestdatei erstellen, verwenden Sie "source", um den Text zu identifizieren, den Sie beschriften möchten. Weitere Informationen finden Sie unter Eingabedaten.
Erstellen einer Labeling-Aufgabe für die Textklassifizierung (Konsole)
Sie können den Anweisungen folgenErstellen eines Kennzeichnungsauftrags (Konsole), um zu erfahren, wie Sie einen Job zur Textklassifizierung in der SageMaker AI-Konsole erstellen. Wählen Sie in Schritt 10 im Dropdown-Menü Aufgabenkategorie die Option Text und wählen Sie als Aufgabentyp Textklassifizierung (einzelne Beschriftung)“ aus.
Ground Truth stellt für die Labeling-Aufgaben eine Auftragnehmer-Benutzeroberfläche ähnlich der folgenden bereit. Wenn Sie die Labeling-Aufgabe mit der Konsole erstellen, müssen Sie Anweisungen bereitstellen, damit die Worker die Aufgabe ausführen können, und Kennzeichnungen, aus denen die Worker auswählen können.
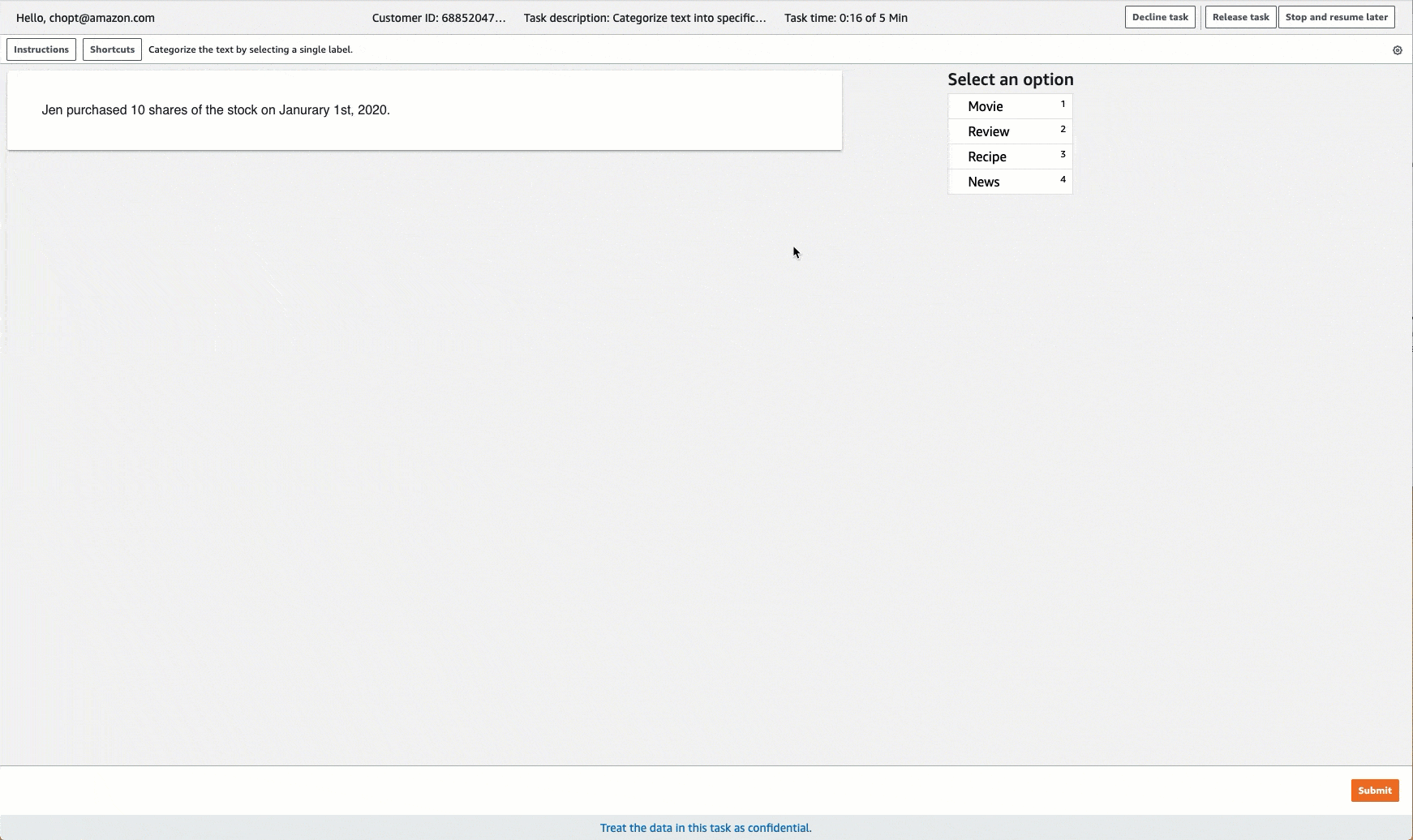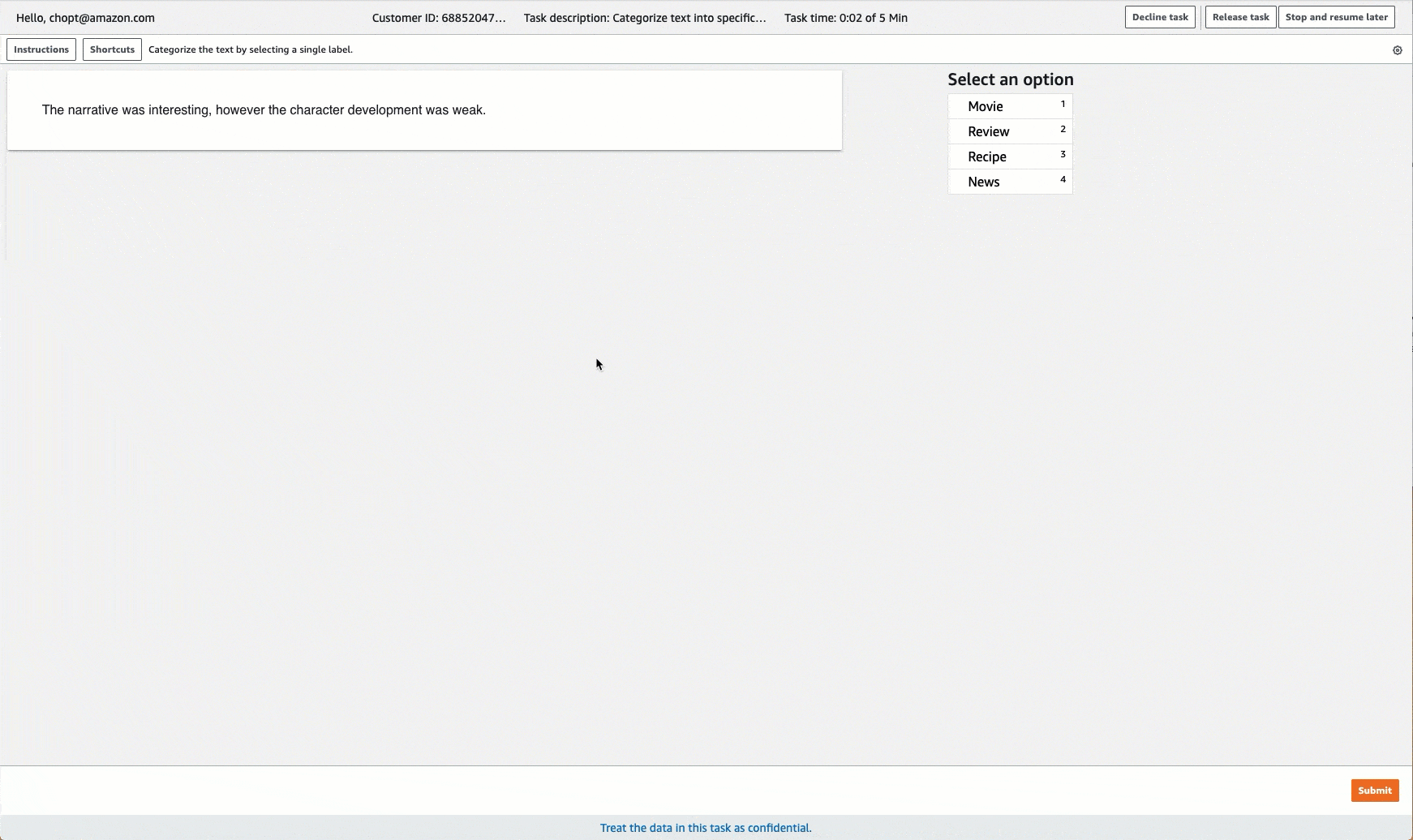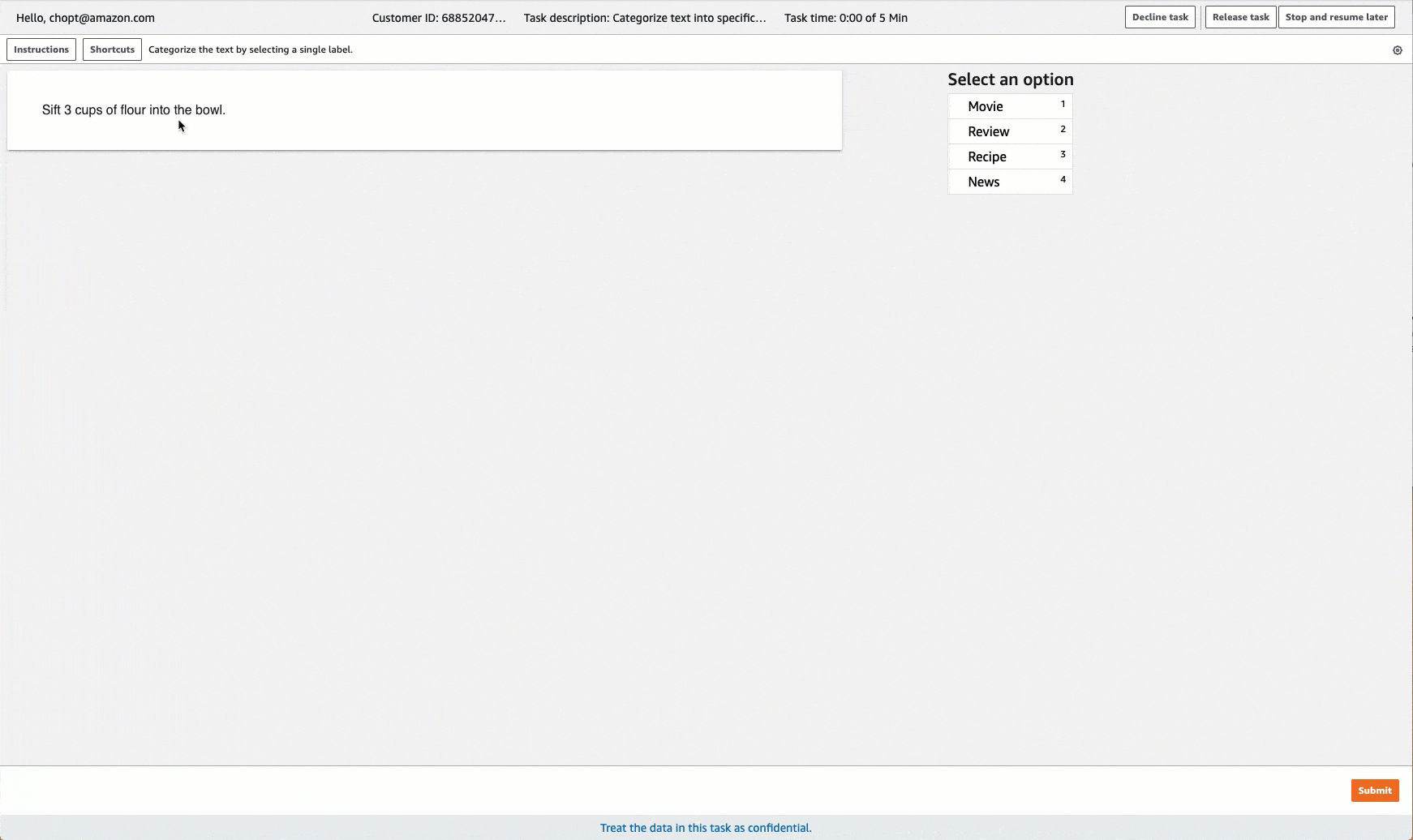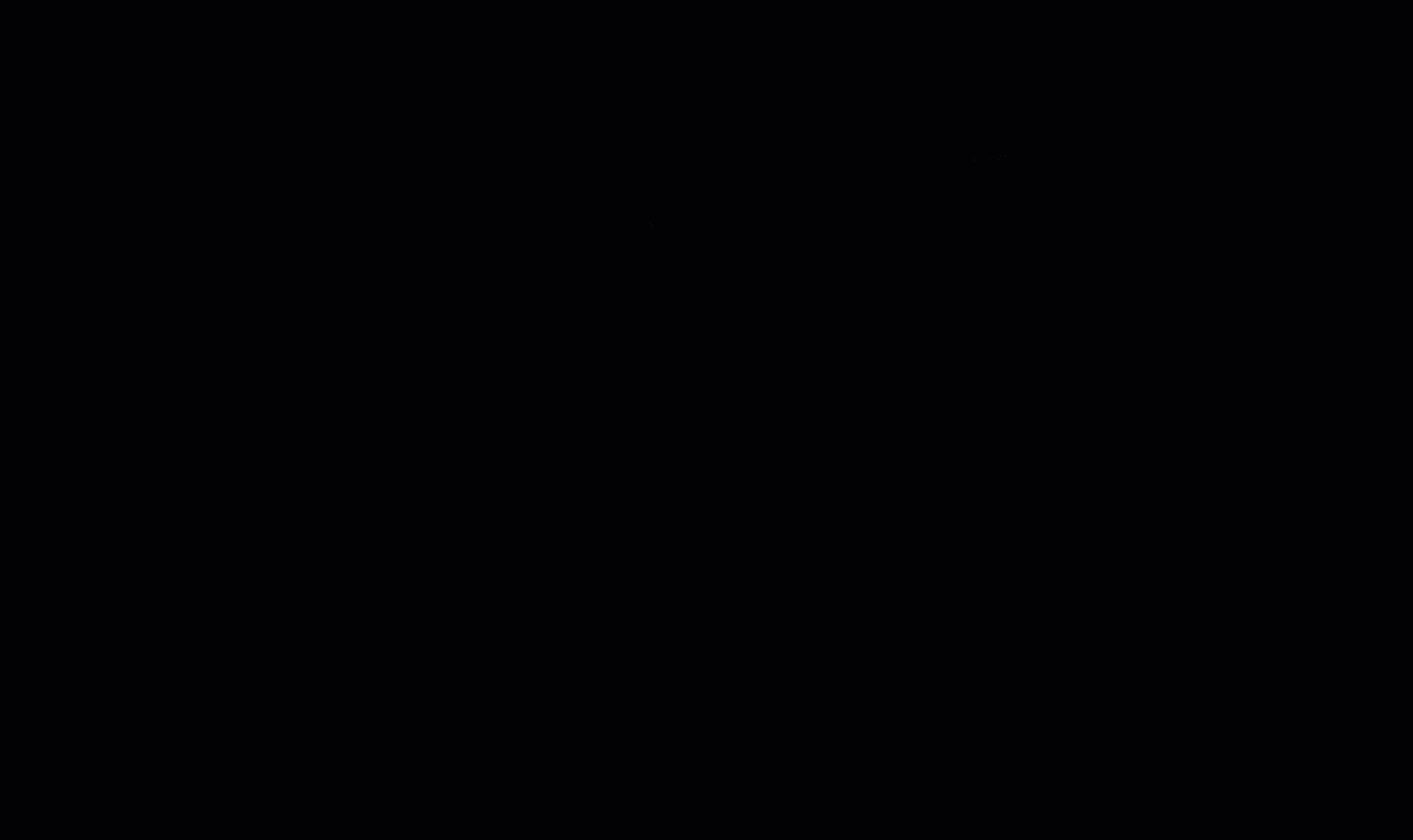
Erstellen einer Labeling-Aufgabe für die Textklassifizierung (API)
Verwenden Sie die SageMaker API-Operation, um einen Job zur Textklassifizierung zur Kennzeichnung zu erstellenCreateLabelingJob. Diese API definiert diesen Vorgang für alle AWS SDKs. Eine Liste der sprachspezifischen SDKs, die für diese Operation unterstützt werden, finden Sie im Abschnitt Siehe auch von CreateLabelingJob.
Befolgen Sie diese Anweisungen unter Erstellen eines Kennzeichnungsauftrags (API) und führen Sie die folgenden Schritte aus, während Sie Ihre Anforderung konfigurieren:
-
Pre-annotation Lambda-Funktionen für diesen Aufgabentyp enden mit
PRE-TextMultiClass. Den Lambda-ARN vor der Anmerkung für Ihre Region finden Sie unter. PreHumanTaskLambdaArn -
Annotation-consolidation Lambda-Funktionen für diesen Aufgabentyp enden mit
ACS-TextMultiClass. Den Lambda-ARN zur Annotationskonsolidierung für Ihre Region finden Sie unter. AnnotationConsolidationLambdaArn
Im Folgenden finden Sie ein Beispiel für eine AWS -Python-SDK-(Boto3)-Anforderung
response = client.create_labeling_job( LabelingJobName='example-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-TextMultiClass, 'TaskKeywords': [Text classification', ], 'TaskTitle':Text classification task', 'TaskDescription':'Carefully read and classify this text using the categories provided.', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClass' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Bereitstellen einer Vorlage für Labeling-Aufgaben für die Textklassifizierung
Wenn Sie eine Labeling-Aufgabe unter Verwendung der API erstellen, müssen Sie in UiTemplateS3Uri eine Worker-Aufgabenvorlage bereitstellen. Kopieren und ändern Sie die folgende Vorlage. Ändern Sie nur short-instructions, full-instructions und header.
Laden Sie diese Vorlage zu S3 hoch und geben Sie den S3-URI für diese Datei in UiTemplateS3Uri an.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="crowd-classifier" categories="{{ task.input.labels | to_json | escape }}" header="classify text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p><p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier> </crowd-form>
Textklassifizierungs-Ausgabedaten
Nach der Erstellung einer Labeling-Aufgabe für die Textklassifizierung befinden sich bei Verwendung der API die Ausgabedaten in dem im S3OutputPath Parameter angegebenen Amazon-S3-Bucket oder im Feld Output dataset location (Ausgabedatensatz-Speicherort) im Abschnitt Auftrag Übersicht (Aufgabenübersicht) der Konsole.
Um mehr über die von Ground Truth erzeugte Ausgabemanifestdatei und die Dateistruktur zu erfahren, die Ground Truth zum Speichern Ihrer Ausgabedaten verwendet, siehe Ausgabedaten von Kennzeichnungsaufträgen.
Ein Beispiel für Ausgabemanifestdateien für eine Labeling-Aufgabe für die Textklassifizierung mit Mehrfachkennzeichnung finden Sie unter Ausgabe des Klassifizierungsauftrags.
