Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schnellstart: Erstellen Sie eine SageMaker KI-Sandbox-Domain, um Amazon EMR-Cluster in Studio zu starten
Dieser Abschnitt führt Sie durch die schnelle Einrichtung einer vollständigen Testumgebung in Amazon SageMaker Studio. Sie werden eine neue Studio-Domain erstellen, mit der Benutzer neue Amazon EMR-Cluster direkt von Studio aus starten können. Die Schritte stellen ein Beispiel-Notebook dar, das Sie mit einem Amazon EMR-Cluster verbinden können, um mit der Ausführung von Spark Workloads zu beginnen. Mit diesem Notizbuch erstellen Sie ein Retrieval Augmented Generation System (RAG) mithilfe der verteilten Verarbeitungs- und OpenSearch Vektordatenbank Amazon EMR Spark.
Anmerkung
Melden Sie sich zunächst mit einem AWS Identity and Access Management (IAM-) Benutzerkonto mit Administratorberechtigungen bei der AWS Management Console an. Informationen darüber, wie Sie sich für ein AWS -Konto registrieren und einen Benutzer mit Administratorzugriff erstellen, finden Sie unter Vollständige Amazon SageMaker AI-Voraussetzungen.
So richten Sie Ihre Studio-Testumgebung ein und starten die Ausführung von Spark Jobs:
Schritt 1: Erstellen Sie eine SageMaker KI-Domain für den Start von Amazon EMR-Clustern in Studio
In den folgenden Schritten wenden Sie einen CloudFormation Stack an, um automatisch eine neue SageMaker KI-Domain zu erstellen. Der Stack erstellt auch ein Benutzerprofil und konfiguriert die erforderliche Umgebung und die erforderlichen Berechtigungen. Die SageMaker AI-Domain ist so konfiguriert, dass Sie Amazon EMR-Cluster direkt von Studio aus starten können. In diesem Beispiel werden die Amazon EMR-Cluster im selben AWS
Konto wie SageMaker AI ohne Authentifizierung erstellt. Zusätzliche CloudFormation Stacks, die verschiedene Authentifizierungsmethoden wie Kerberos unterstützen, finden Sie im Repository getting_started.
Anmerkung
SageMaker AI erlaubt standardmäßig 5 Studio-Domains pro Konto. AWS AWS-Region Stellen Sie sicher, dass Ihr Konto nicht mehr als 4 Domains in Ihrer Region hat, bevor Sie Ihren Stack erstellen.
Gehen Sie wie folgt vor, um eine SageMaker KI-Domain für den Start von Amazon EMR-Clustern von Studio aus einzurichten.
-
Laden Sie die Rohdatei dieser CloudFormation Vorlage
aus dem sagemaker-studio-emrGitHub Repository herunter. -
Gehe zur CloudFormation Konsole: https://console.aws.amazon.com/cloudformation
-
Wählen Sie Stack erstellen und dann Mit neuen Ressourcen aus dem Dropdown-Menü aus.
-
In Schritt 1:
-
Wählen Sie im Abschnitt Vorlage vorbereiten die Option Bestehende Vorlage auswählen aus.
-
Wählen Sie im Abschnitt Specify template (Vorlage angeben) die Option Upload a template file (Vorlagendatei hochladen) aus.
-
Laden Sie die heruntergeladene CloudFormation Vorlage hoch und wählen Sie Weiter.
-
-
Geben Sie in Schritt 2 einen Stack-Namen ein und wählen Sie SageMakerDomainNamedann Weiter.
-
Behalten Sie in Schritt 3 alle Standardwerte bei und wählen Sie Weiter.
-
Markieren Sie in Schritt 4 das Kästchen zur Bestätigung der Ressourcenerstellung und wählen Sie Stapel erstellen aus. Dadurch wird eine Studio-Domain in Ihrem Konto und Ihrer Region erstellt.
Schritt 2: Starten Sie einen neuen Amazon EMR-Cluster über die Studio-Benutzeroberfläche
In den folgenden Schritten erstellen Sie einen neuen Amazon EMR-Cluster über die Studio-Benutzeroberfläche.
-
Gehen Sie zur SageMaker AI-Konsole unter https://console.aws.amazon.com/sagemaker/
und wählen Sie im linken Menü Domains aus. -
Klicken Sie auf Ihren Domainnamen GenerativeAIDomain, um die Seite mit den Domaindetails zu öffnen.
-
Starten Sie Studio vom Benutzerprofil aus
genai-user. -
Gehen Sie im linken Navigationsbereich zu Daten und dann zu Amazon EMR Clusters.
-
Wählen Sie auf der Seite mit den Amazon-EMR-Clustern Erstellen aus. Wählen Sie die Vorlage SageMaker Studio Domain No Auth EMR aus, die vom CloudFormation Stack erstellt wurde, und wählen Sie dann Weiter.
-
Geben Sie einen Namen für den neuen Amazon EMR-Cluster ein. Aktualisieren Sie optional andere Parameter wie den Instance-Typ der Core- und Master-Knoten, das Leerlauf-Timeout oder die Anzahl der Kernknoten.
-
Wählen Sie Create resource aus, um den neuen Amazon EMR-Cluster zu starten.
Nachdem Sie den Amazon EMR-Cluster erstellt haben, folgen Sie dem Status auf der Seite EMR-Cluster. Wenn sich der Status auf ändert
Running/Waiting, ist Ihr Amazon EMR-Cluster bereit, in Studio verwendet zu werden.
Schritt 3: Connect ein JupyterLab Notebook mit dem Amazon EMR-Cluster
In den folgenden Schritten verbinden Sie ein Notebook mit Ihrem laufenden Amazon EMR-Cluster. JupyterLab In diesem Beispiel importieren Sie ein Notizbuch, mit dem Sie mithilfe der verteilten Verarbeitungs- und OpenSearch Vektordatenbank Amazon EMR Spark ein RAG-System (Retrieval Augmented Generation) erstellen können.
-
Starten JupyterLab
Starten Sie die JupyterLab Anwendung von Studio aus.
-
Erstellen eines privaten Bereichs
Wenn Sie noch keinen Bereich für Ihre JupyterLab Anwendung erstellt haben, wählen Sie JupyterLab Bereich erstellen. Geben Sie einen Namen für den Bereich ein und behalten Sie den Wert Privat für den Bereich bei. Belassen Sie alle anderen Einstellungen auf ihren Standardwerten und wählen Sie dann Bereich erstellen aus.
Andernfalls führen Sie Ihren JupyterLab Bereich aus, um eine JupyterLab Anwendung zu starten.
-
Stellen Sie Ihr LLM und Ihre Einbettungsmodelle für Inferenz bereit
-
Wählen Sie im oberen Menü Datei, Neu und dann Terminal aus.
-
Führen Sie im Terminal den folgenden Befehl aus.
wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb mkdir AWSGuides cd AWSGuides wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/AmazonSageMakerDeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/EC2DeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/S3DeveloperGuide.pdfDadurch wird das
Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb-Notebook in Ihr lokales Verzeichnis abgerufen und drei PDF-Dateien werden in einen lokalenAWSGuides-Ordner heruntergeladen. -
Öffnen Sie
lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb, behalten Sie denPython 3 (ipykernel)Kernel und führen Sie jede Zelle aus.Warnung
Stellen Sie im Abschnitt Llama 2-Lizenzvereinbarung sicher, dass Sie die Llama2-EULA akzeptieren, bevor Sie fortfahren.
Das Notebook setzt zwei Modelle ein,
Llama 2undall-MiniLM-L6-v2 Models, aufml.g5.2xlargefür die Inferenz.Die Bereitstellung der Modelle und die Erstellung der Endpunkte können einige Zeit in Anspruch nehmen.
-
-
Öffnen Sie Ihr Haupt-Notebook
Öffnen Sie in JupyterLab Ihr Terminal und führen Sie den folgenden Befehl aus.
cd .. wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynbSie sollten das zusätzliche
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynbNotizbuch im linken Bereich von sehen JupyterLab. -
Auswählen eines
PySpark-KernelÖffnen Sie Ihr
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb-Notebook und stellen Sie sicher, dass Sie denSparkMagic PySpark-Kernel verwenden. Sie können den Kernel oben rechts in Ihrem Notebook wechseln. Wählen Sie den aktuellen Kernelnamen, um ein Kernelauswahl-Modal zu öffnen, und wählen Sie dannSparkMagic PySpark. -
Verbinden Ihres Notebooks mit dem Cluster
-
Wählen Sie oben rechts in Ihrem Notebook die Option Cluster aus. Diese Aktion öffnet ein modales Fenster, in dem alle laufenden Cluster aufgeführt werden, auf die Sie zugreifen dürfen
-
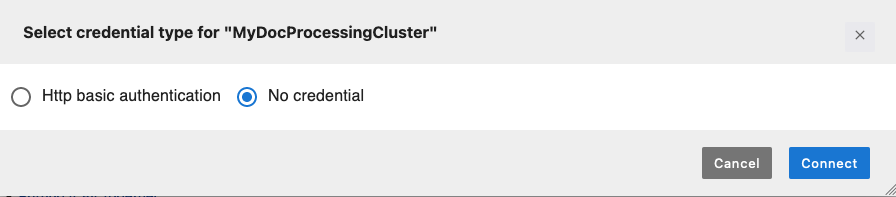
Wählen Sie Ihren Cluster und dann Connect aus. Ein neues modales Fenster zur Auswahl des Anmeldeinformationstyps wird geöffnet.
-
Wählen Sie Keine Anmeldeinformationen und anschließend Verbinden aus.
-
Eine Notebook-Zelle wird automatisch ausgefüllt und ausgeführt. Die Notebook-Zelle lädt die
sagemaker_studio_analytics_extension.magicsErweiterung, die Funktionen für die Verbindung mit dem Amazon EMR-Cluster bereitstellt. Anschließend verwendet es den%sm_analyticsmagischen Befehl, um die Verbindung zu Ihrem Amazon EMR-Cluster und der Spark-Anwendung herzustellen.Anmerkung
Stellen Sie sicher, dass für die Verbindungszeichenfolge zu Ihrem Amazon EMR-Cluster der Authentifizierungstyp auf
Noneeingestellt ist. Dies wird durch den Wert--auth-type Noneim folgenden Beispiel veranschaulicht. Sie können das Feld bei Bedarf ändern.%load_ext sagemaker_studio_analytics_extension.magics %sm_analytics emr connect --verify-certificate False --cluster-idyour-cluster-id--auth-typeNone--language python -
Sobald Sie die Verbindung erfolgreich hergestellt haben, sollte Ihre Ausgabenachricht in der Verbindungszelle Ihre
SparkSessionDetails wie Ihre Cluster-ID,YARNAnwendungs-ID und einen Link zur Spark Benutzeroberfläche zur Überwachung Ihrer Spark Jobs enthalten.
-
Sie sind bereit, das Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb Notebook zu verwenden. In diesem Beispiel-Notebook werden verteilte PySpark Workloads für den Aufbau eines RAG-Systems mit LangChain und ausgeführt. OpenSearch
Schritt 4: Säubere deine CloudFormation Stack
Wenn Sie fertig sind, stellen Sie sicher, dass Sie Ihre beiden Endgeräte beenden und Ihren CloudFormation Stack löschen, um weitere Gebühren zu vermeiden. Durch das Löschen des Stacks werden alle Ressourcen bereinigt, die vom Stack bereitgestellt wurden.
Um deine zu löschen CloudFormation stapeln Sie, wenn Sie damit fertig sind
-
Gehe zur CloudFormation Konsole: https://console.aws.amazon.com/cloudformation
-
Wählen Sie den Stack aus, den Sie löschen möchten. Sie können nach Namen oder in der Liste der Stacks suchen.
-
Klicken Sie auf die Schaltfläche Löschen, um das Löschen des Stacks abzuschließen, und klicken Sie dann erneut auf Löschen, um zu bestätigen, dass dadurch alle vom Stapel erstellten Ressourcen gelöscht werden.
Warten Sie, bis der Stack gelöscht wurde. Dies kann einige Minuten dauern. CloudFormation bereinigt automatisch alle in der Stack-Vorlage definierten Ressourcen.
-
Stellen Sie sicher, dass alle vom Stack erstellten Ressourcen gelöscht wurden. Suchen Sie beispielsweise nach übrig gebliebenen Amazon EMR-Clustern.
Um die API-Endpunkte für ein Modell zu entfernen
-
Gehe zur SageMaker AI-Konsole: https://console.aws.amazon.com/sagemaker/
. -
Wählen Sie im linken Navigationsbereich Inferenz und dann Endpunkte aus.
-
Wählen Sie den Endpunkt aus
hf-allminil6v2-embedding-epund wählen Sie dann in der Dropdownliste Aktionen die Option Löschen aus. Wiederholen Sie den Schritt für den Endpunktmeta-llama2-7b-chat-tg-ep.
