Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurieren Sie einen Schulungsjob mit einem heterogenen Cluster in Amazon AI SageMaker
Dieser Abschnitt enthält Anweisungen zum Ausführen eines Trainingsauftrags mit einem heterogenen Cluster, der aus mehreren Instance-Typen besteht.
Bevor Sie beginnen, beachten Sie Folgendes.
-
Alle Instance-Gruppen verwenden dasselbe Docker-Image und dasselbe Trainingsskript. Daher sollte Ihr Trainingsskript so geändert werden, dass erkannt wird, zu welcher Instance-Gruppe es gehört, und die Ausführung entsprechend aufgeteilt werden.
-
Die Funktion für heterogene Cluster ist nicht mit dem lokalen SageMaker KI-Modus kompatibel.
-
Die CloudWatch Amazon-Protokollstreams eines heterogenen Cluster-Trainingsjobs sind nicht nach Instanzgruppen gruppiert. Sie müssen anhand der Protokolle herausfinden, welche Knoten zu welcher Gruppe gehören.
Option 1: Verwenden des SageMaker Python-SDK
Folgen Sie den Anweisungen zur Konfiguration von Instanzgruppen für einen heterogenen Cluster mithilfe des SageMaker Python-SDK.
-
Verwenden Sie die
sagemaker.instance_group.InstanceGroupKlasse, um Instance-Gruppen eines heterogenen Clusters für einen Trainingsauftrages zu konfigurieren. Sie können für jede Instance-Gruppe einen benutzerdefinierten Namen, den Instance-Typ und die Anzahl der Instances für jede Instance-Gruppe angeben. Weitere Informationen finden Sie unter sagemaker.instance_group. InstanceGroupin der SageMaker AI Python SDK-Dokumentation. Anmerkung
Weitere Informationen zu verfügbaren Instanztypen und der maximalen Anzahl von Instanzgruppen, die Sie in einem heterogenen Cluster konfigurieren können, finden Sie in der InstanceGroupAPI-Referenz.
Das folgende Codebeispiel zeigt, wie Sie zwei Instanzgruppen einrichten, die aus zwei benannten
ml.c5.18xlargeCPU-only Instanzeninstance_group_1und einer benanntenml.p3dn.24xlargeGPU-Instanz besteheninstance_group_2, wie im folgenden Diagramm dargestellt.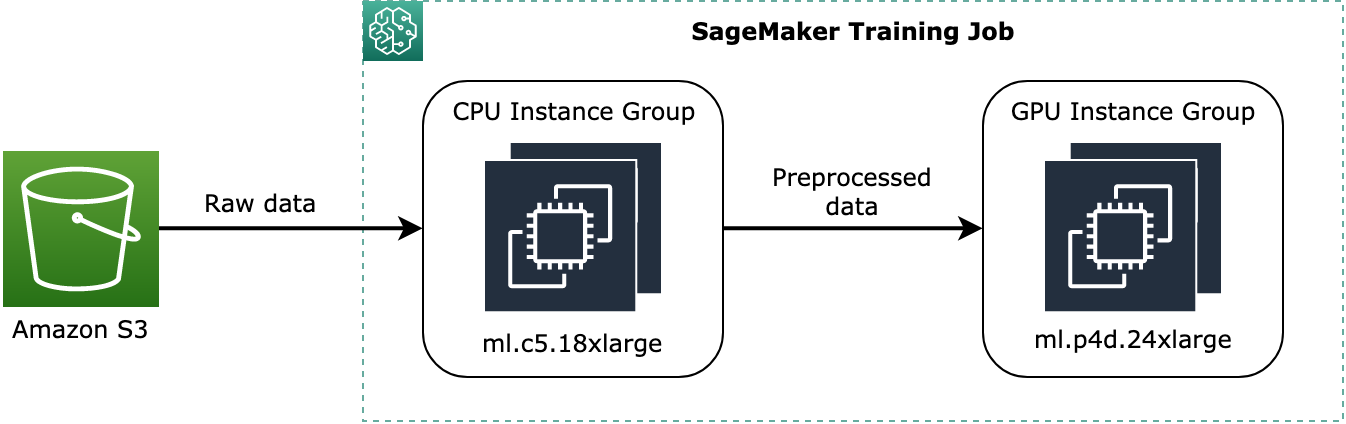
Das obige Diagramm zeigt ein konzeptionelles Beispiel dafür, wie Prozesse vor dem Training, wie z. B. die Datenvorverarbeitung, der CPU-Instance-Gruppe zugewiesen und die vorverarbeiteten Daten an die GPU-Instance-Gruppe gestreamt werden können.
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
Richten Sie mithilfe der Instanzgruppenobjekte Trainingseingabekanäle ein und weisen Sie den Kanälen mithilfe des
instance_group_namesArguments sagemaker.inputs Instanzgruppen zu. TrainingInputKlasse. Das instance_group_names-Argument akzeptiert eine Liste von Strings mit Instance-Gruppennamen.Das folgende Beispiel zeigt, wie zwei Trainingseingangskanäle eingerichtet und die im Beispiel des vorherigen Schritts erstellten Instance-Gruppen zugewiesen werden. Sie können auch Amazon-S3-Bucket-Pfade für das
s3_data-Argument angeben, damit die Instance-Gruppen Daten für Ihre Verwendungszwecke verarbeiten.from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )Weitere Informationen zu den Argumenten von
TrainingInput, finden Sie unter den folgenden Links.-
Die Sagemaker.inputs. TrainingInput
Klasse in der SageMaker Python SDK-Dokumentation -
Die S3DataSourceAPI in der SageMaker AI-API-Referenz
-
-
Konfigurieren Sie einen SageMaker AI-Schätzer mit dem
instance_groupsArgument, wie im folgenden Codebeispiel gezeigt. Dasinstance_groups-Argument akzeptiert eine Liste vonInstanceGroup-Objekten.Anmerkung
Die Funktion für heterogene Cluster ist in den Klassen SageMaker AI PyTorch
und TensorFlow Framework Estimator verfügbar. Unterstützte Frameworks sind PyTorch v1.10 oder höher und TensorFlow v2.6 oder höher. Eine vollständige Liste der verfügbaren Framework-Container, Framework-Versionen und Python-Versionen finden Sie unter SageMaker AI Framework Containers im AWS Deep Learning GitHub Container-Repository. Anmerkung
Das
instance_typeinstance_countArgumentpaar und dasinstance_groupsArgument der SageMaker AI-Schätzerklasse schließen sich gegenseitig aus. Verwenden Sie für ein homogenes Clusterttraining das Argumentpaarinstance_typeundinstance_count. Verwenden Sieinstance_groupsfür heterogenes Clustertraining.Anmerkung
Eine vollständige Liste der verfügbaren Framework-Container, Framework-Versionen und Python-Versionen finden Sie unter SageMaker AI Framework Containers
im AWS Deep Learning GitHub Container-Repository. -
Konfigurieren Sie die
estimator.fitMethode mit den Trainingseingabekanälen, die mit den Instance-Gruppen konfiguriert sind, und starten Sie den Trainingsaufträge.estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
Option 2: Verwendung der Low-Level-APIs SageMaker
Wenn Sie das AWS Command Line Interface oder verwenden AWS SDK für Python (Boto3) und SageMaker Low-Level-APIs verwenden möchten, um eine Trainingsanfrage mit einem heterogenen Cluster einzureichen, finden Sie weitere Informationen in den folgenden API-Referenzen.
