Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Wie funktioniert SageMaker Smart Sifting
Das Ziel von SageMaker Smart Sifting besteht darin, Ihre Trainingsdaten während des Trainingsprozesses zu sichten und dem Modell nur aussagekräftigere Stichproben zuzuführen. Während eines typischen Trainings mit PyTorch werden Daten iterativ stapelweise an die Trainingsschleife und an Beschleunigergeräte (wie GPUs oder Trainium-Chips) gesendet. PyTorchDataLoader
Das folgende Diagramm zeigt einen Überblick darüber, wie der SageMaker Smart-Sifting-Algorithmus konzipiert ist.
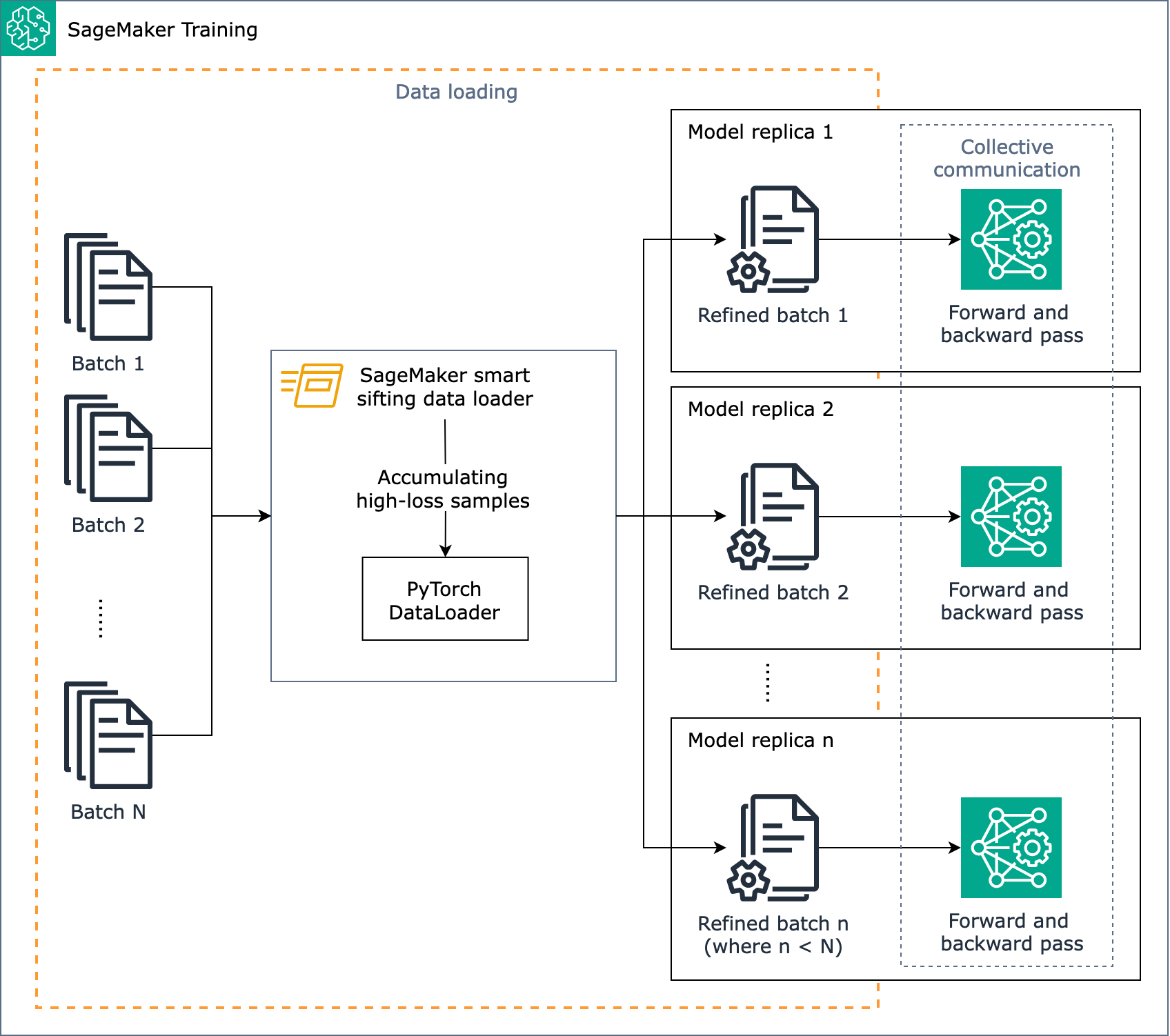
Kurz gesagt, SageMaker Smart Sifting funktioniert während des Trainings, wenn Daten geladen werden. Der Algorithmus für SageMaker intelligentes Sieben berechnet den Verlust anhand der Chargen und sortiert Daten, die sich nicht verbessern, vor dem Vorwärts- und Rückwärtsdurchlauf jeder Iteration heraus. Der verfeinerte Datenstapel wird dann für den Vorwärts- und Rückwärtsdurchlauf verwendet.
Anmerkung
Beim intelligenten Sieben von SageMaker KI-Daten werden zusätzliche Vorwärtsdurchläufe verwendet, um deine Trainingsdaten zu analysieren und zu filtern. Im Gegenzug gibt es weniger Rückwärtsdurchläufe, da Daten mit geringerer Aussagekraft aus Ihrem Trainingsjob ausgeschlossen werden. Aus diesem Grund führt Smart Sifting bei Modellen mit langen oder aufwändigen Rückwärtsdurchläufen zu den größten Effizienzsteigerungen. Dauert der Vorwärtsdurchlauf Ihres Modells jedoch länger als der Rückwärtsdurchlauf, kann der Mehraufwand die Gesamttrainingszeit erhöhen. Um zu messen, wie viel Zeit für jeden Durchlauf aufgewendet wird, können Sie einen Pilot-Trainingsjob ausführen und Protokolle sammeln, in denen die Dauer der Prozesse aufgezeichnet wird. Erwägen Sie auch die Verwendung von SageMaker Profiler, der Tools zur Profilerstellung und Benutzeroberflächenanwendungen bereitstellt. Weitere Informationen hierzu finden Sie unter Amazon SageMaker Profiler.
SageMaker Smart Sifting eignet sich für PyTorch-based Trainingsaufgaben mit klassischer verteilter Datenparallelität, bei der Modellreplikate auf jedem GPU-Worker erstellt und ausgeführt werden. AllReduce Es funktioniert mit PyTorch DDP und der SageMaker AI Distributed Data Parallel Library.
