Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
SageMaker Schulung: Compiler-Fehlerbehebung
Wichtig
Amazon Web Services (AWS) gibt bekannt, dass es keine neuen Releases oder Versionen von SageMaker Training Compiler geben wird. Sie können SageMaker Training Compiler weiterhin über die vorhandenen AWS Deep Learning Containers (DLCs) für SageMaker Schulungen verwenden. Es ist wichtig zu beachten, dass auf die vorhandenen DLCs zwar weiterhin zugegriffen werden kann, sie jedoch gemäß der Support-Richtlinie für AWS Deep Learning Containers Framework keine Patches oder Updates mehr erhalten. AWS
Wenn Sie auf einen Fehler stoßen, können Sie anhand der folgenden Liste versuchen, Fehler in Ihrem Trainingsauftrag zu beheben. Wenn Sie weitere Unterstützung benötigen, wenden Sie sich über den SageMaker AWS Support
Der Trainingsauftrag konvergiert im Vergleich zum nativen Framework-Trainingsauftrag nicht erwartungsgemäß
Konvergenzprobleme reichen von „Das Modell lernt nicht, wenn der SageMaker Training Compiler aktiviert ist“ bis hin zu „Das Modell lernt, aber langsamer als das native Framework“. In diesem Leitfaden zur Problembehebung gehen wir davon aus, dass Ihre Konvergenz ohne SageMaker Training Compiler (im nativen Framework) in Ordnung ist, und betrachten dies als Grundlage.
Wenn Sie mit solchen Konvergenzproblemen konfrontiert werden, ist der erste Schritt, festzustellen, ob das Problem auf verteiltes Training beschränkt ist oder auf das Training mit nur einer GPU zurückzuführen ist. Das verteilte Training mit SageMaker Training Compiler ist eine Erweiterung des Einzel-GPU-Trainings mit zusätzlichen Schritten.
-
Richten Sie einen Cluster mit mehreren Instances oder GPUs ein.
-
Verteilen Sie die Eingabedaten an alle Auftragnehmer.
-
Synchronisieren Sie die Modellaktualisierungen von allen Auftragnehmern.
Daher überträgt sich jedes Konvergenzproblem bei dem Training mit nur einer GPU auf verteilte Trainings mit mehreren Auftragnehmern.
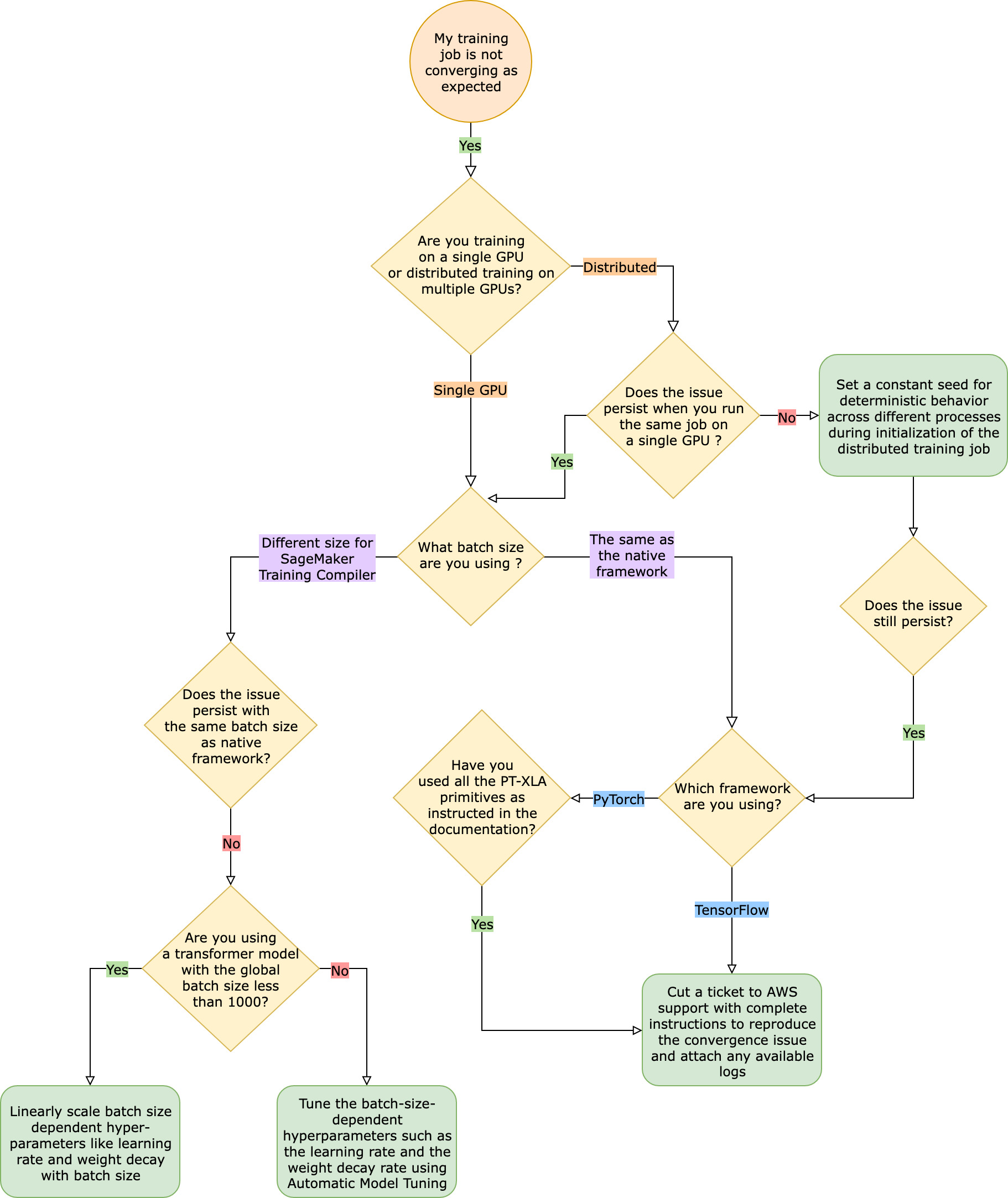
Konvergenzprobleme, die bei Trainings mit nur einer GPU auftreten
Wenn Ihr Konvergenzproblem auf das Training mit nur einer GPU zurückzuführen ist, sind der wahrscheinliche Grund falsche Einstellungen für Hyperparameter oder torch_xla APIs.
Überprüfen Sie die Hyperparameter
Das Training mit dem SageMaker Training Compiler führt zu einer Änderung des Speicherbedarfs eines Modells. Der Compiler vermittelt intelligent zwischen Wiederverwendung und Neuberechnung, was zu einer entsprechenden Zu- oder Abnahme des Speicherverbrauchs führt. Um diese Vorteile nutzen zu können, müssen bei der Migration eines Trainingsjobs zum Training Compiler unbedingt die Batchgröße und die zugehörigen Hyperparameter neu eingestellt werden. SageMaker Falsche Einstellungen für die Hyperparameter führen allerdings häufig zu Schwankungen beim Trainingsverlust und in der Folge ggf. zu langsamerer Konvergenz. In seltenen Fällen können aggressive Hyperparameter dazu führen, dass das Modell nicht lernt (die Metrik zum Trainingsverlust nimmt nicht ab oder gibt NaN zurück). Um festzustellen, ob das Konvergenzproblem auf die Hyperparameter zurückzuführen ist, führen Sie einen Paralleltest von zwei Trainingsjobs mit und ohne SageMaker Training Compiler durch, wobei alle Hyperparameter gleich bleiben.
Prüfen Sie, ob die torch_xla APIs für das Training mit einer GPU korrekt eingerichtet sind
Wenn das Konvergenzproblem bei den Ausgangshyperparametern weiterhin besteht, müssen Sie überprüfen, ob die torch_xla APIs nicht ordnungsgemäß verwendet werden, insbesondere die für die Aktualisierung des Modells erforderlichen. Im Grunde sammelt torch_xla laufend Befehle (dabei wird die Ausführung in Form eines Diagramms solange verzögert, bis es ausdrücklich angewiesen wird, das akkumulierte Diagramm auszuführen. Die Funktion torch_xla.core.xla_model.mark_step() erleichtert die Ausführung des akkumulierten Graphen. Die Ausführung des Diagramms sollte mit Hilfe dieser Funktion nach jeder Modellaktualisierung und vor dem Drucken und Protokollieren von Variablen synchronisiert werden. Fehlt der Synchronisationsschritt, verwendet das Modell beim Drucken, Protokollieren und den nachfolgenden Vorwärtsdurchgängen ggf. alte Werte aus dem Speicher, anstatt die neuesten Werte zu verwenden, die nach jeder Iteration und Modellaktualisierung synchronisiert werden müssen.
Dies kann komplizierter sein, wenn der SageMaker Training Compiler mit Gradientenskalierung (möglicherweise aufgrund von AMP) oder Gradientenclipping-Techniken verwendet wird. Die korrekte Reihenfolge der Steigungsberechnung mit AMP lautet wie folgt.
-
Steigungsberechnung mit Skalierung
-
Aufheben der Skalierung von Steigungen, Beschneiden von Steigungen und anschließendes Skalieren
-
Modell-Update
-
Synchronisieren der Ausführung des Graphen mit
mark_step()
Die richtigen APIs für die in der Liste aufgeführten Operationen finden Sie in der Anleitung zur Migration Ihres Trainingsskripts zum SageMaker Training Compiler.
Erwägen Sie die Verwendung der automatischen Modelloptimierung
Wenn das Konvergenzproblem bei der Neuabstimmung der Batchgröße und der zugehörigen Hyperparameter wie der Lernrate bei der Verwendung des SageMaker Training Compilers auftritt, sollten Sie die automatische Modelloptimierung zur Optimierung Ihrer Hyperparameter in Betracht ziehen. Sie können sich auf das Beispiel-Notizbuch zur Optimierung von Hyperparametern mit dem Training Compiler
Konvergenzprobleme, die bei dem verteilten Training auftreten
Wenn Ihr Konvergenzproblem bei dem verteilten Training weiterhin besteht, ist dies wahrscheinlich auf falsche Einstellungen für die Initialisierung der Gewichtung oder die torch_xla APIs zurückzuführen.
Überprüfen Sie die Initialisierung der Gewichtung aller Auftragnehmer
Wenn das Konvergenzproblem bei der Durchführung eines verteilten Trainingsauftrags mit mehreren Auftragnehmern auftritt, stellen Sie sicher, dass für alle Auftragnehmer ein einheitliches deterministisches Verhalten zur Anwendung kommt, indem Sie ggf. einen konstanten Anfangswert festlegen. Vorsicht bei Techniken wie der Initialisierung der Gewichtung, die eine Randomisierung beinhaltet. In Ermangelung eines konstanten Anfangswertes könnte es sein, dass jeder Auftragnehmer ein anderes Modell schult.
Prüfen Sie, ob die torch_xla APIs für das verteilte Training korrekt eingerichtet sind.
Wenn das Problem weiterhin besteht, ist dies wahrscheinlich auf eine unsachgemäße Verwendung der torch_xla APIs für das verteilte Training zurückzuführen. Stellen Sie sicher, dass Sie Ihrem Estimator Folgendes hinzufügen, um einen Cluster für verteiltes Training mit SageMaker Training Compiler einzurichten.
distribution={'torchxla': {'enabled': True}}
Dies sollte von einer Funktion _mp_fn(index) in Ihrem Trainingsskript begleitet werden, die einmal pro Auftragnehmer aufgerufen wird. Ohne die mp_fn(index) Funktion könnten Sie am Ende jeden der Auftragnehmer das Modell unabhängig voneinander trainieren lassen, ohne Modellaktualisierungen gemeinsam zu nutzen.
Stellen Sie als Nächstes sicher, dass Sie die torch_xla.distributed.parallel_loader.MpDeviceLoader API zusammen mit dem Distributed Data Sampler verwenden, wie in der Dokumentation zur Migration Ihres Trainingsskripts zum SageMaker Training Compiler beschrieben, wie im folgenden Beispiel.
torch.utils.data.distributed.DistributedSampler()
Dadurch wird sichergestellt, dass die Eingabedaten korrekt auf alle Auftragnehmer verteilt werden.
Und um Modellaktualisierungen von allen Auftragnehmern zu synchronisieren, können Sie mit Hilfe von torch_xla.core.xla_model._fetch_gradients Steigungen von allen Auftragnehmern sammeln und mit torch_xla.core.xla_model.all_reduce alle gesammelten Steigungen zu einer einzigen Aktualisierung zusammenfassen.
Es kann komplizierter sein, wenn Sie den SageMaker Training Compiler mit Gradientenskalierung (möglicherweise aufgrund von AMP) oder Gradientenclipping-Techniken verwenden. Die korrekte Reihenfolge der Steigungsberechnung mit AMP lautet wie folgt.
-
Steigungsberechnung mit Skalierung
-
Steigungensynchronisierung für alle Auftragnehmer
-
Aufheben der Skalierung von Steigungen, Beschneiden von Steigungen und anschließend Skalierung von Steigungen
-
Modell-Update
-
Synchronisieren der Ausführung des Graphen mit
mark_step()
Beachten Sie, dass diese Checkliste im Vergleich zur Checkliste für das Training mit nur einer GPU einen zusätzlichen Punkt für die Synchronisierung aller Auftragnehmer enthält.
Der Trainingsjob schlägt aufgrund fehlender Konfiguration fehl PyTorch/XLA
Wenn ein Trainingsauftrag mit der Missing XLA configuration Fehlermeldung fehlschlägt, liegt das ggf. an einer Fehlkonfiguration der Anzahl der GPUs pro Instance, die Sie verwenden.
XLA benötigt zusätzliche Umgebungsvariablen, um den Trainingsauftrag zu kompilieren. Die am häufigsten fehlende Umgebungsvariable ist GPU_NUM_DEVICES. Damit der Compiler korrekt funktioniert, müssen Sie diese Umgebungsvariable auf die Anzahl der GPUs pro Instance setzen.
Es gibt drei Möglichkeiten, die GPU_NUM_DEVICES Umgebungsvariable festzulegen:
-
Ansatz 1 — Verwenden Sie das
environmentArgument der SageMaker AI-Schätzerklasse. Wenn Sie z. B. eineml.p3.8xlargeInstance mit vier GPUs verwenden, gehen Sie wie folgt vor:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Ansatz 2 — Verwenden Sie das
hyperparametersArgument der SageMaker AI-Estimator-Klasse und analysieren Sie es in Ihrem Trainingsskript.-
Um die Anzahl der GPUs anzugeben, fügen Sie zum
hyperparametersArgument ein Schlüssel-Wert-Paar hinzu.Wenn Sie z. B. eine
ml.p3.8xlargeInstance mit vier GPUs verwenden, gehen Sie wie folgt vor:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
Parsen Sie in Ihrem Trainingsskript den
n_gpusHyperparameter und geben Sie ihn als Eingabe für dieGPU_NUM_DEVICESUmgebungsvariable an.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Ansatz 3 — Hard-code Die
GPU_NUM_DEVICESUmgebungsvariable in Ihrem Trainingsskript. Fügen Sie zu Ihrem Skript z. B. Folgendes hinzu, wenn Sie eine Instance mit vier GPUs verwenden.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
Tipp
Informationen zur Anzahl der GPU-Geräte bei Machine-Learning-Instances, die Sie verwenden möchten, finden Sie unter Beschleunigte Datenverarbeitung
SageMaker Der Training Compiler reduziert nicht die gesamte Trainingszeit
Wenn sich die Gesamttrainingszeit mit dem SageMaker Training Compiler nicht verringert, empfehlen wir Ihnen dringend, die SageMaker Bewährte Methoden und Überlegungen zum Training Compiler Seite durchzugehen und Ihre Trainingskonfiguration, die Polsterstrategie für die Eingabe-Tensorform und die Hyperparameter zu überprüfen.
