Esta página es solo para los clientes actuales del servicio Amazon Glacier que utilizan Vaults y la API de REST original de 2012.
Si busca soluciones de almacenamiento de archivos, se recomienda que utilice las clases de almacenamiento de Amazon Glacier en Amazon S3, S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval y S3 Glacier Deep Archive. Para obtener más información sobre estas opciones de almacenamiento, consulte las clases de almacenamiento de Amazon Glacier
Amazon Glacier (servicio original independiente basado en bóveda) ya no acepta nuevos clientes. Amazon Glacier es un servicio independiente con sus propias API que almacena datos en almacenes y es distinto de las clases de almacenamiento Amazon S3 y Amazon S3 Glacier. Sus datos actuales permanecerán seguros y accesibles en Amazon Glacier de forma indefinida. No hay que hacer migraciones. Para un almacenamiento de archivos a largo plazo y de bajo costo, AWS recomienda las clases de almacenamiento Amazon S3 Glacier
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Recuperación de sumas de comprobación al descargar datos
Cuando se recupera un archivo con la API Initiate Job (consulte Inicialización de trabajos (POST trabajos)), puede especificar un intervalo del archivo, si así lo desea. Del mismo modo, si los datos se descargan utilizando la API Get Job Output (consulte Obtención de la salida del trabajo (GET output)), tiene la opción de especificar el intervalo de datos que se van a descargar. Hay dos características de estos intervalos que es importante conocer cuando se recuperan y se descargan datos de un archivo. Es necesario que el intervalo que se va a recuperar esté alineado en megabytes con el archivo. Tanto el intervalo que se va a recuperar como el intervalo que se va a descargar deben estar alineados con un hash en árbol para poder obtener los valores de la suma de comprobación al descargar los datos. La definición de estos dos tipos de alineaciones de intervalos es la siguiente:
-
Alineado en megabytes: un rango [StartByte, EndBytes] es un megabyte (1024*1024) alineado cuando StartByteses divisible entre 1 MB y EndBytesmás 1 es divisible entre 1 MB o es igual al final del archivo especificado (tamaño de byte de archivo menos 1). Es necesario que, si se especifica un intervalo en la API Initiate Job, este intervalo esté alineado en megabytes.
-
Alineado con un hash de árbol: un rango [StartBytes, EndBytes] es un hash de árbol alineado con respecto a un archivo si y solo si la raíz del hash de árbol creado sobre el rango es equivalente a un nodo en el hash de árbol de todo el archivo. Tanto el intervalo que se va a recuperar como el intervalo que se va a descargar deben estar alineados con un algoritmo hash en árbol para poder obtener los valores de la suma de comprobación de los datos que se van a descargar. Para ver un ejemplo de intervalos y su relación con el hash en árbol de un archivo, consulte Ejemplo de hash en árbol: recuperación de un intervalo de archivo que está alineado con un hash en árbol.
Tenga en cuenta que los intervalos alineados con un hash en árbol también están alineados en megabytes. Sin embargo, los intervalos alineados en megabytes no tienen por qué estar alineados necesariamente con un hash en árbol.
A continuación, se indican los casos en los que se obtiene el valor de una suma de comprobación al descargar los datos del archivo:
-
Si no se especifica el intervalo que se va a recuperar en la solicitud Initiate Job y se descarga todo el archivo con una solicitud Get Job.
-
Si no se especifica el intervalo que se quiere recuperar en la solicitud Initiate Job, pero sí se especifica el intervalo alineado con un hash en árbol que se quiere descargar en la solicitud Get Job.
-
Si se especifica el intervalo alineado con un hash en árbol que se quiere recuperar en la solicitud Initiate Job y se descarga todo el intervalo con una solicitud Get Job.
-
Si se especifica el intervalo alineado con un hash en árbol que se quiere recuperar en la solicitud Initiate Job y también se especifica el intervalo alineado con un hash en árbol que se quiere descargar en la solicitud Get Job.
Si se especifica el intervalo que se quiere recuperan en la solicitud Initiate Job pero este intervalo no está alineado con el hash en árbol, podrá recuperar los datos del archivo, pero no se devolverán los valores de la suma de comprobación cuando se descarguen los datos con la solicitud Get Job.
Ejemplo de hash en árbol: recuperación de un intervalo de archivo que está alineado con un hash en árbol
Supongamos que tiene un archivo de 6,5 MB en el almacén y que desea recuperar 2 MB del archivo. El modo en que especifique el intervalo de 2 MB en la solicitud Initiate Job determinará si va a recibir los valores de la suma de comprobación de datos al descargar los datos. En el siguiente diagrama, se ilustran dos intervalos de 2 MB del archivo de 6,5 MB que podría descargar. Los dos intervalos están alineados en megabytes, pero solo uno de ellos está alineado con el hash en árbol.
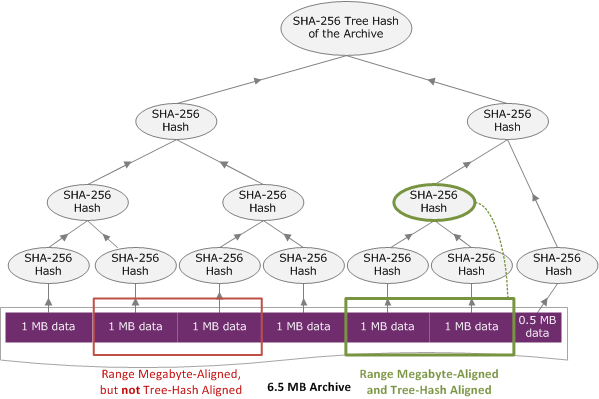
Especificación de un intervalo alienado con un hash en árbol
En esta sección se explica la especificación exacta de lo que constituye un intervalo alineado con un hash en árbol. Los intervalos alineados con un hash en árbol son importantes cuando se descarga una parte de un archivo y se especifica el intervalo de datos que se va a recuperar y el intervalo de los datos recuperados que se va a descargar. Si los dos intervalos están alienados con un hash en árbol, recibirá la suma de comprobación cuando descargue los datos.
Un intervalo [A, B] está alineado con un hash en árbol respecto a un archivo si y solo si, cuando se crea un nuevo hash en árbol sobre [A, B], la raíz del hash en árbol de ese intervalo es igual que un nodo del hash en árbol de todo el archivo. Puede ver una ilustración de esto en el diagrama de Ejemplo de hash en árbol: recuperación de un intervalo de archivo que está alineado con un hash en árbol. En esta sección, vamos a explicar la especificación de la alineación con hash en árbol.
Imagine que [P, Q) es la consulta del intervalo de un archivo con N megabytes (MB) y que P y Q son múltiplos de 1 MB. Tenga en cuenta que el intervalo inclusivo real es [P MB, Q MB – 1 byte], aunque, por simplicidad, lo representaremos como [P, Q). Teniendo en cuenta estas consideraciones, ocurre que
-
Si P es un número impar, solo hay un intervalo alineado con un hash en árbol posible: [P, P + 1 MB).
-
Si P es un número par y k es el número máximo, donde P puede especificarse como 2k * X, habrá como mucho k intervalos alineados de hash en árbol que comiencen con P. X es un entero mayor que 0. Los intervalos alineados con un hash en árbol pueden clasificarse en las categorías siguientes:
-
En cada i, donde (0 <= i <= k) y donde P + 2i < N, then [P, Q + 2i) es un rango alineado con un hash en árbol.
-
P = 0 es un caso especial, donde A = 2[lgN]*0
-
