Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Información general sobre cómo utilizar la característica Neptune ML
La característica Neptune ML de Amazon Neptune proporciona un flujo de trabajo optimizado para aprovechar los modelos de machine learning dentro de una base de datos de gráficos. El proceso incluye varios pasos clave: exportar datos de Neptune a formato CSV, preprocesar los datos para prepararlos para el entrenamiento del modelo, entrenar el modelo de machine learning con Amazon SageMaker AI, crear un punto de conexión de inferencia para ofrecer predicciones y, a continuación, consultar el modelo directamente desde consultas de Gremlin. El entorno de trabajo de Neptune proporciona cómodos comandos mágicos de línea y celda para ayudar a administrar y automatizar estos pasos. Al integrar las capacidades de machine learning directamente en la base de datos de gráficos, Neptune ML permite a los usuarios obtener información valiosa y realizar predicciones a partir de la gran cantidad de datos relacionales almacenados en el gráfico de Neptune.
Inicio del flujo de trabajo para usar Neptune ML
Para empezar, el uso de la característica Neptune ML en Amazon Neptune suele implicar los cinco pasos siguientes:
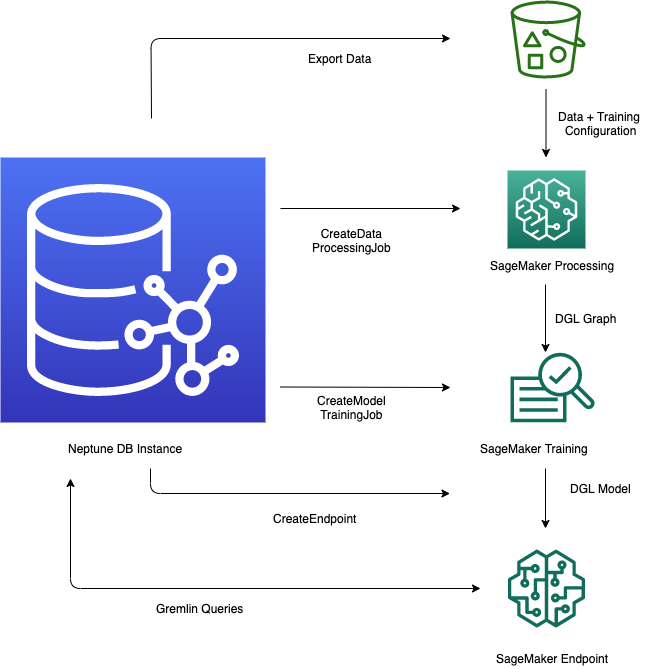
-
Configuración y exportación de datos: el paso de exportación de datos utiliza el servicio Neptune-Export o la herramienta de línea de comandos de
neptune-exportpara exportar datos de Neptune a Amazon Simple Storage Service (Amazon S3) en formato CSV. Al mismo tiempo, se genera automáticamente un archivo de configuración denominadotraining-data-configuration.json, que especifica cómo se pueden cargar los datos exportados en un gráfico entrenable. -
Preprocesamiento de datos: en este paso, el conjunto de datos exportado se procesa previamente mediante técnicas estándar para prepararlo para el entrenamiento de modelos. La normalización de características se puede realizar para datos numéricos, y las características de texto se pueden codificar mediante
word2vec. Al final de este paso, se genera un gráfico DGL a partir del conjunto de datos exportado para utilizarlo en el paso de entrenamiento de modelos.Este paso se implementa mediante un trabajo de procesamiento de SageMaker AI en la cuenta, y los datos resultantes se almacenan en la ubicación de Amazon S3 que haya especificado.
-
Entrenamiento de modelos: el paso de entrenamiento de modelos entrena el modelo de machine learning que se utilizará para las predicciones.
El entrenamiento de modelos se realiza en dos etapas:
La primera etapa utiliza un trabajo de procesamiento de SageMaker AI para generar un conjunto de configuraciones de estrategias de entrenamiento de modelos que especifica qué tipo de modelo y qué rangos de hiperparámetros del modelo se utilizarán para el entrenamiento.
La segunda etapa utiliza un trabajo de ajuste del modelo de SageMaker AI para probar diferentes configuraciones de hiperparámetros y seleccionar el trabajo de entrenamiento que produjo el modelo con el mejor rendimiento. El trabajo de ajuste ejecuta un número previamente especificado de pruebas de trabajo de entrenamiento de modelos con los datos procesados. Al final de esta etapa, se utilizan los parámetros del modelo entrenado del mejor trabajo de entrenamiento para generar artefactos del modelo para su inferencia.
-
Creación de un punto de conexión de inferencia en Amazon SageMaker AI: el punto de conexión de inferencia es una instancia de punto de conexión de SageMaker AI que se lanza con los artefactos del modelo producidos por el mejor trabajo de entrenamiento. Cada modelo está vinculado a un único punto de conexión. El punto de conexión puede aceptar las solicitudes entrantes de la base de datos de gráficos y devolver las predicciones de modelos para las entradas de las solicitudes. Una vez creado el punto de conexión, permanecerá activo hasta que lo elimine.
Consulta del modelo de machine learning mediante Gremlin: puede utilizar extensiones del lenguaje de consultas de Gremlin para consultar las predicciones desde el punto de conexión de inferencia.
nota
El entorno de trabajo de Neptune incluye un comando mágico de línea y un comando mágico de celda que pueden ahorrarle mucho tiempo en la administración de estos pasos, es decir:
