Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de una canalización OpenSearch de ingestión con aprendizaje automático e inferencia por lotes fuera de línea
Las canalizaciones de OpenSearch Amazon Ingestion (OSI) admiten el procesamiento de inferencias por lotes fuera de línea con aprendizaje automático (ML) para enriquecer de manera eficiente grandes volúmenes de datos a bajo costo. Utilice la inferencia en lotes sin conexión siempre que tenga conjuntos de datos grandes que puedan procesarse de forma asíncrona. La inferencia de lotes sin conexión funciona con Amazon Bedrock y SageMaker sus modelos. Esta función está disponible en todos los dominios Regiones de AWS compatibles con OpenSearch Ingestion with OpenSearch Service 2.17 o más.
nota
Para el procesamiento de inferencias en tiempo real, utilice Conectores Amazon OpenSearch Service ML para plataformas de terceros.
El procesamiento de inferencias por lotes fuera de línea aprovecha una función llamada ML Commons. OpenSearch ML Commons proporciona algoritmos de ML mediante llamadas a la API de REST y de transporte. Esas llamadas eligen los nodos y los recursos correctos para cada solicitud de ML y supervisan las tareas de ML para garantizar el tiempo de actividad. De esta manera, ML Commons le permite aprovechar los algoritmos de ML de código abierto existentes y reducir el esfuerzo necesario para desarrollar nuevas características de ML. Para obtener más información sobre ML Commons, consulte Aprendizaje automático
Funcionamiento
Puede crear una canalización de inferencias por lotes sin conexión en OpenSearch Ingestion añadiendo un procesador de inferencias de aprendizaje automático
OpenSearch Ingestion utiliza el ml_inference procesador con ML Commons para crear trabajos de inferencia por lotes sin conexión a Internet. A continuación, ML Commons utiliza la API batch_predict
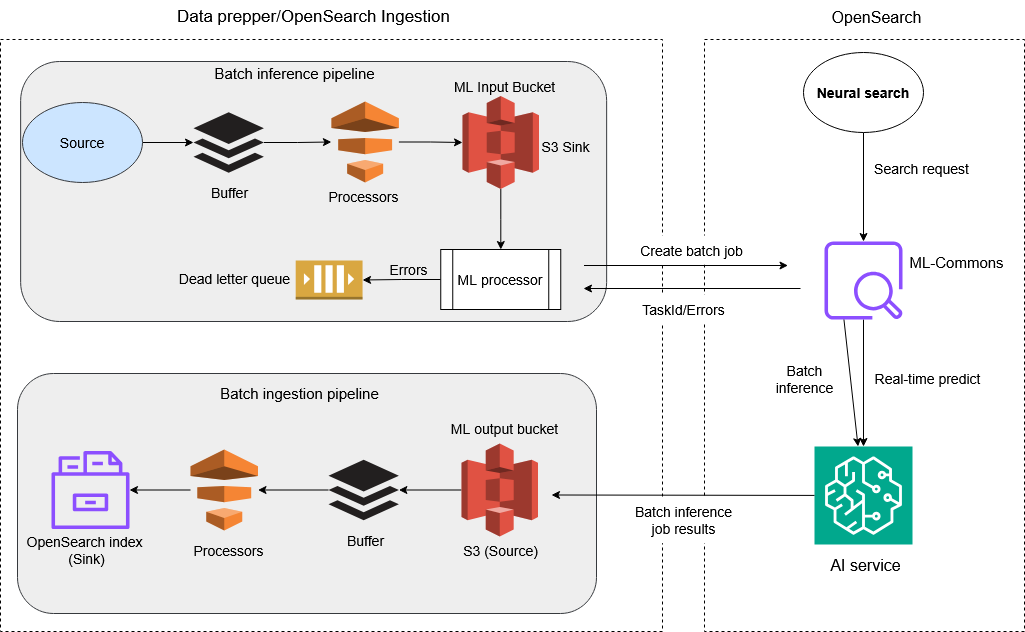
Los componentes de la canalización funcionan de la siguiente manera:
Canalización 1 (Preparación y transformación de datos)*:
-
Fuente: los datos se escanean desde una fuente externa compatible con Ingestion. OpenSearch
-
Procesadores de datos: los datos sin procesar se procesan y transforman al formato correcto para su inferencia en lotes en el servicio de IA integrado.
-
S3 (receptor): los datos procesados se almacenan en un bucket de Amazon S3 y están listos para servir como entrada para ejecutar tareas de inferencia en lotes en el servicio de IA integrado.
Canalización 2 (Activar batch_inference de ML):
-
Origen: detección automática de eventos de S3 de nuevos archivos creados por la salida de la Canalización 1.
-
Procesador ml_inference: procesador que genera inferencias de ML mediante una tarea en lotes asíncrona. Se conecta a los servicios de IA a través del conector de IA configurado que se ejecuta en el dominio de destino.
-
ID de tarea: cada tarea en lotes está asociada a un ID de tarea en ml-commons para su seguimiento y administración.
-
OpenSearch ML Commons: ML Commons, que aloja el modelo de búsqueda neuronal en tiempo real, gestiona los conectores a los servidores remotos de IA y sirve APIs para la inferencia de lotes y la gestión de trabajos.
-
Servicios de IA: OpenSearch ML Commons interactúa con servicios de IA como Amazon Bedrock y Amazon SageMaker para realizar inferencias por lotes de los datos, produciendo predicciones o información. Los resultados se guardan de forma asíncrona en un archivo S3 independiente.
Canalización 3 (Ingesta masiva):
-
S3 (origen): los resultados de las tareas en lotes se almacenan en S3, que es el origen de esta canalización.
-
Procesadores de transformación de datos: el procesamiento y la transformación adicionales se aplican al resultado de la inferencia en lotes antes de la ingesta. Esto garantiza que los datos estén mapeados correctamente en el índice. OpenSearch
-
OpenSearch índice (sumidero): los resultados procesados se indexan OpenSearch para almacenarlos, buscarlos y analizarlos más a fondo.
nota
* El proceso descrito en Canalización 1 es opcional. Si lo prefiere, puede omitir ese proceso y solo cargar los datos preparados en el receptor de S3 para crear tareas en lotes.
Acerca del procesador ml_inference
OpenSearch Ingestion utiliza una integración especializada entre la fuente de S3 Scan y el procesador de inferencias ML para el procesamiento por lotes. El S3 Scan funciona solo en modo de metadatos para recopilar de manera eficiente la información de los archivos S3 sin leer el contenido real del archivo. El ml_inference procesador utiliza el archivo S3 URLs para coordinarse con ML Commons para el procesamiento por lotes. Este diseño optimiza el flujo de trabajo de inferencia en lotes al minimizar la transferencia de datos innecesaria durante la fase de digitalización. El procesador ml_inference se define mediante parámetros. A continuación se muestra un ejemplo:
processor: - ml_inference: # The endpoint URL of your OpenSearch domain host: "https://AWS test-offlinebatch-123456789abcdefg.us-west-2.es.amazonaws.com" # Type of inference operation: # - batch_predict: for batch processing # - predict: for real-time inference action_type: "batch_predict" # Remote ML model service provider (Amazon Bedrock or SageMaker) service_name: "bedrock" # Unique identifier for the ML model model_id: "AWS TestModelID123456789abcde" # S3 path where batch inference results will be stored output_path: "s3://amzn-s3-demo-bucket/" # Supports ISO_8601 notation strings like PT20.345S or PT15M # These settings control how long to keep your inputs in the processor for retry on throttling errors retry_time_window: "PT9M" # AWS configuration settings aws: # Región de AWS where the Lambda function is deployed region: "us-west-2" # IAM role ARN for Lambda function execution sts_role_arn: "arn:aws::iam::account_id:role/Admin" # Dead-letter queue settings for storing errors dlq: s3: region: us-west-2 bucket: batch-inference-dlq key_path_prefix: bedrock-dlq sts_role_arn: arn:aws:iam::account_id:role/OSI-invoke-ml# Conditional expression that determines when to trigger the processor # In this case, only process when bucket matches "amzn-s3-demo-bucket" ml_when: /bucket == "amzn-s3-demo-bucket"
Mejoras en el rendimiento de la ingesta mediante el procesador ml_inference
El ml_inference procesador OpenSearch de ingestión mejora considerablemente el rendimiento de la ingesta de datos para las búsquedas habilitadas para ML. El procesador es ideal para casos de uso que requieren datos generados por modelos de machine learning, como la búsqueda semántica, la búsqueda multimodal, el enriquecimiento de documentos y la comprensión de consultas. En la búsqueda semántica, el procesador puede acelerar la creación e ingesta de vectores de gran volumen y alta dimensión en un orden de magnitud.
La capacidad de inferencia en lotes sin conexión del procesador ofrece claras ventajas en comparación con la invocación de modelos en tiempo real. Si bien el procesamiento en tiempo real requiere un servidor modelo en vivo con limitaciones de capacidad, la inferencia en lotes escala de forma dinámica los recursos de cómputo bajo demanda y procesa los datos en paralelo. Por ejemplo, cuando la canalización de OpenSearch ingestión recibe mil millones de solicitudes de datos de origen, crea 100 archivos S3 para la entrada de inferencias por lotes de aprendizaje automático. A continuación, el ml_inference procesador inicia un trabajo SageMaker por lotes con 100 instancias de ml.m4.xlarge Amazon Elastic Compute Cloud (Amazon EC2) y completa la vectorización de mil millones de solicitudes en 14 horas, una tarea que sería prácticamente imposible de realizar en tiempo real.
Configurar el procesador ml_inference de modo que ingiera las solicitudes de datos para una búsqueda semántica
Los siguientes procedimientos explican el proceso de instalación y configuración del ml_inference procesador de OpenSearch ingestión para procesar mil millones de solicitudes de datos con fines de búsqueda semántica mediante un modelo de incrustación de texto.
Temas
Paso 1: Cree conectores y registre modelos en OpenSearch
Para el siguiente procedimiento, utilice el batch_inference_sagemaker_connector_blueprint de ML Commons para crear
Para crear conectores y registrar modelos en OpenSearch
-
Cree un modelo ML de Deep Java Library (DJL) SageMaker para la transformación por lotes. Para ver otros modelos de DJL, consulte Semantic_Search_With_CFN_Template_for_SageMaker
en: GitHub POST https://api.sagemaker.us-east-1.amazonaws.com/CreateModel { "ExecutionRoleArn": "arn:aws:iam::123456789012:role/aos_ml_invoke_sagemaker", "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "PrimaryContainer": { "Environment": { "SERVING_LOAD_MODELS" : "djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2" }, "Image": "763104351884.dkr.ecr.us-east-1.amazonaws.com/djl-inference:0.29.0-cpu-full" } } -
Cree un conector con
batch_predictcomo el nuevo tipoactionen el campoactions:POST /_plugins/_ml/connectors/_create { "name": "DJL Sagemaker Connector: all-MiniLM-L6-v2", "version": "1", "description": "The connector to sagemaker embedding model all-MiniLM-L6-v2", "protocol": "aws_sigv4", "credential": { "roleArn": "arn:aws:iam::111122223333:role/SageMakerRole" }, "parameters": { "region": "us-east-1", "service_name": "sagemaker", "DataProcessing": { "InputFilter": "$.text", "JoinSource": "Input", "OutputFilter": "$" }, "MaxConcurrentTransforms": 100, "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "TransformInput": { "ContentType": "application/json", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://offlinebatch/msmarcotests/" } }, "SplitType": "Line" }, "TransformJobName": "djl-batch-transform-1-billion", "TransformOutput": { "AssembleWith": "Line", "Accept": "application/json", "S3OutputPath": "s3://offlinebatch/msmarcotestsoutputs/" }, "TransformResources": { "InstanceCount": 100, "InstanceType": "ml.m4.xlarge" }, "BatchStrategy": "SingleRecord" }, "actions": [ { "action_type": "predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://runtime.sagemaker.us-east-1.amazonaws.com/endpoints/OpenSearch-sagemaker-060124023703/invocations", "request_body": "${parameters.input}", "pre_process_function": "connector.pre_process.default.embedding", "post_process_function": "connector.post_process.default.embedding" }, { "action_type": "batch_predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/CreateTransformJob", "request_body": """{ "BatchStrategy": "${parameters.BatchStrategy}", "ModelName": "${parameters.ModelName}", "DataProcessing" : ${parameters.DataProcessing}, "MaxConcurrentTransforms": ${parameters.MaxConcurrentTransforms}, "TransformInput": ${parameters.TransformInput}, "TransformJobName" : "${parameters.TransformJobName}", "TransformOutput" : ${parameters.TransformOutput}, "TransformResources" : ${parameters.TransformResources}}""" }, { "action_type": "batch_predict_status", "method": "GET", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/DescribeTransformJob", "request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}""" }, { "action_type": "cancel_batch_predict", "method": "POST", "headers": { "content-type": "application/json" }, "url": "https://api.sagemaker.us-east-1.amazonaws.com/StopTransformJob", "request_body": """{ "TransformJobName" : "${parameters.TransformJobName}"}""" } ] } -
Utilice el ID de conector devuelto para registrar el modelo: SageMaker
POST /_plugins/_ml/models/_register { "name": "SageMaker model for batch", "function_name": "remote", "description": "test model", "connector_id": "example123456789-abcde" } -
Invoque el modelo con el tipo de acción
batch_predict:POST /_plugins/_ml/models/teHr3JABBiEvs-eod7sn/_batch_predict { "parameters": { "TransformJobName": "SM-offline-batch-transform" } }La respuesta contiene un identificador de tarea para la tarea en lotes:
{ "task_id": "exampleIDabdcefd_1234567", "status": "CREATED" } -
Compruebe el estado de la tarea en lotes llamando a la API Get Task con el ID de tarea:
GET /_plugins/_ml/tasks/exampleIDabdcefd_1234567La respuesta contiene el estado de la tarea:
{ "model_id": "nyWbv5EB_tT1A82ZCu-e", "task_type": "BATCH_PREDICTION", "function_name": "REMOTE", "state": "RUNNING", "input_type": "REMOTE", "worker_node": [ "WDZnIMcbTrGtnR4Lq9jPDw" ], "create_time": 1725496527958, "last_update_time": 1725496527958, "is_async": false, "remote_job": { "TransformResources": { "InstanceCount": 1, "InstanceType": "ml.c5.xlarge" }, "ModelName": "DJL-Text-Embedding-Model-imageforjsonlines", "TransformOutput": { "Accept": "application/json", "AssembleWith": "Line", "KmsKeyId": "", "S3OutputPath": "s3://offlinebatch/output" }, "CreationTime": 1725496531.935, "TransformInput": { "CompressionType": "None", "ContentType": "application/json", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": "s3://offlinebatch/sagemaker_djl_batch_input.json" } }, "SplitType": "Line" }, "TransformJobArn": "arn:aws:sagemaker:us-east-1:111122223333:transform-job/SM-offline-batch-transform15", "TransformJobStatus": "InProgress", "BatchStrategy": "SingleRecord", "TransformJobName": "SM-offline-batch-transform15", "DataProcessing": { "InputFilter": "$.content", "JoinSource": "Input", "OutputFilter": "$" } } }
(Procedimiento alternativo) Paso 1: Cree conectores y modelos mediante una plantilla de CloudFormation integración
Si lo prefiere, puede utilizarlos AWS CloudFormation para crear automáticamente todos los SageMaker conectores y modelos de Amazon necesarios para la inferencia de aprendizaje automático. Este enfoque simplifica la configuración mediante el uso de una plantilla preconfigurada disponible en la consola de Amazon OpenSearch Service. Para obtener más información, consulte Se utiliza CloudFormation para configurar la inferencia remota para la búsqueda semántica.
Para implementar una CloudFormation pila que cree todos los SageMaker conectores y modelos necesarios
-
Abre la consola OpenSearch de Amazon Service.
-
En el panel de navegación, elija Integraciones.
-
En el campo de búsqueda, introduce y
SageMaker, a continuación, selecciona Integración con modelos de incrustación de texto a través de Amazon SageMaker. -
Seleccione Configurar dominio y, a continuación, seleccione Configurar dominio de VPC o Configurar dominio público.
-
Ingrese la información en los campos de la plantilla. En Habilitar la inferencia en lotes sin conexión, elija true para aprovisionar recursos para el procesamiento en lotes sin conexión.
-
Selecciona Crear para crear la CloudFormation pila.
-
Una vez creada la pila, abra la pestaña Salidas en la CloudFormation consola y busque el connector_id y el model_id. Necesitará estos valores más adelante cuando configure la canalización.
Paso 2: Cree una canalización de OpenSearch ingestión para la inferencia de lotes fuera de línea de ML
Utilice el siguiente ejemplo para crear una canalización de OpenSearch ingestión para la inferencia de lotes de ML sin conexión. Para obtener más información sobre la creación de una canalización para OpenSearch Ingestion, consulte. Creación de canalizaciones OpenSearch de Amazon Ingestion
Antes de empezar
En el siguiente ejemplo, se especifica un ARN de rol de IAM para el parámetro sts_role_arn. Utilice el siguiente procedimiento para comprobar que este rol está asignado al rol de backend que tiene acceso a ml-commons en. OpenSearch
-
Navegue hasta el complemento OpenSearch Dashboards de su dominio de servicio. OpenSearch Puedes encontrar el punto de conexión del panel de control en el panel de control de tu dominio, en la consola de OpenSearch servicio.
-
En el menú principal, seleccione Seguridad, Roles y seleccione el rol ml_full_access.
-
Seleccione Usuarios asignados, Administrar mapeo.
-
En Roles de backend, escriba el ARN del rol de Lambda que necesita permiso para llamar a su dominio. Este es un ejemplo: arn:aws:iam: ::role/
111122223333lambda-role -
Seleccione Asignar y confirme que el usuario o el rol aparecen en Usuarios asignados.
Ejemplo de creación de una canalización de ingestión para la inferencia de lotes offline de ML OpenSearch
version: '2' extension: osis_configuration_metadata: builder_type: visual sagemaker-batch-job-pipeline: source: s3: acknowledgments: true delete_s3_objects_on_read: false scan: buckets: - bucket: name:namedata_selection: metadata_only filter: include_prefix: - sagemaker/sagemaker_djl_batch_input exclude_suffix: - .manifest - bucket: name:namedata_selection: data_only filter: include_prefix: - sagemaker/output/ scheduling: interval: PT6M aws: region:namedefault_bucket_owner:account_IDcodec: ndjson: include_empty_objects: false compression: none workers: '1' processor: - ml_inference: host: "https://search-AWStest-offlinebatch-123456789abcdef.us-west-2.es.amazonaws.com" aws_sigv4: true action_type: "batch_predict" service_name: "sagemaker" model_id: "model_ID" output_path: "s3://AWStest-offlinebatch/sagemaker/output" aws: region: "us-west-2" sts_role_arn: "arn:aws:iam::account_ID:role/Admin" ml_when: /bucket == "AWStest-offlinebatch" dlq: s3: region:us-west-2bucket:batch-inference-dlqkey_path_prefix:bedrock-dlqsts_role_arn: arn:aws:iam::account_ID:role/OSI-invoke-ml- copy_values: entries: - from_key: /text to_key: chapter - from_key: /SageMakerOutput to_key: chapter_embedding - delete_entries: with_keys: - text - SageMakerOutput sink: - opensearch: hosts: ["https://search-AWStest-offlinebatch-123456789abcdef.us-west-2.es.amazonaws.com"] aws: serverless: false region: us-west-2 routes: - ml-ingest-route index_type: custom index: test-nlp-index routes: - ml-ingest-route: /chapter != null and /title != null
Paso 3: preparar los datos para la ingesta
Para preparar los datos para el procesamiento de inferencias por lotes de aprendizaje automático fuera de línea, prepare los datos usted mismo con sus propias herramientas o procesos o utilice el OpenSearch Data Prepper.
El siguiente ejemplo usa el conjunto de datos MS MARCO
{"_id": "1185869", "text": ")what was the immediate impact of the Paris Peace Treaties of 1947?", "metadata": {"world war 2"}} {"_id": "1185868", "text": "_________ justice is designed to repair the harm to victim, the community and the offender caused by the offender criminal act. question 19 options:", "metadata": {"law"}} {"_id": "597651", "text": "what is amber", "metadata": {"nothing"}} {"_id": "403613", "text": "is autoimmune hepatitis a bile acid synthesis disorder", "metadata": {"self immune"}} ...
Para realizar una prueba con el conjunto de datos MS MARCO, imagine un escenario en el que cree mil millones de solicitudes de entrada distribuidas en 100 archivos, cada uno con 10 millones de solicitudes. Los archivos se almacenarían en Amazon S3 con el prefijo s3://offlinebatch/sagemaker/sagemaker_djl_batch_input/. El proceso OpenSearch de ingestión escanearía estos 100 archivos simultáneamente e iniciaría un trabajo SageMaker por lotes con 100 trabajadores para su procesamiento en paralelo, lo que permitiría la vectorización y la ingestión eficientes de los mil millones de documentos en los que se encuentran. OpenSearch
En los entornos de producción, puede utilizar una canalización de OpenSearch ingestión para generar archivos S3 para la entrada de datos por lotes. La canalización admite varios orígenes de datos
Paso 4: Supervisar la tarea de inferencia en lotes
Puede supervisar los trabajos de inferencia por lotes mediante la SageMaker consola o el. AWS CLI También puede utilizar la API Get Task para supervisar tareas en lotes:
GET /_plugins/_ml/tasks/_search { "query": { "bool": { "filter": [ { "term": { "state": "RUNNING" } } ] } }, "_source": ["model_id", "state", "task_type", "create_time", "last_update_time"] }
La API devuelve una lista de tareas en lotes activas:
{ "took": 2, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 3, "relation": "eq" }, "max_score": 0.0, "hits": [ { "_index": ".plugins-ml-task", "_id": "nyWbv5EB_tT1A82ZCu-e", "_score": 0.0, "_source": { "model_id": "nyWbv5EB_tT1A82ZCu-e", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496527958, "last_update_time": 1725496527958 } }, { "_index": ".plugins-ml-task", "_id": "miKbv5EB_tT1A82ZCu-f", "_score": 0.0, "_source": { "model_id": "miKbv5EB_tT1A82ZCu-f", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496528123, "last_update_time": 1725496528123 } }, { "_index": ".plugins-ml-task", "_id": "kiLbv5EB_tT1A82ZCu-g", "_score": 0.0, "_source": { "model_id": "kiLbv5EB_tT1A82ZCu-g", "state": "RUNNING", "task_type": "BATCH_PREDICTION", "create_time": 1725496529456, "last_update_time": 1725496529456 } } ] } }
Paso 5: ejecute la búsqueda
Tras supervisar la tarea de inferencia en lotes y confirmar que se ha completado, puede ejecutar varios tipos de búsquedas de IA, incluidas las semánticas, las híbridas, las conversacionales (con RAG), las dispersas neuronales y las multimodales. Para obtener más información sobre las búsquedas de IA compatibles con el OpenSearch Servicio, consulte Búsqueda de IA
Para buscar vectores sin procesar, utilice el tipo de consulta knn, proporcione la matriz vector como entrada y especifique el k número de resultados devueltos:
GET /my-raw-vector-index/_search { "query": { "knn": { "my_vector": { "vector": [0.1, 0.2, 0.3], "k": 2 } } } }
Para ejecutar una búsqueda basada en la IA, utilice el tipo de consulta neural. Especifique la query_text entrada, el modelo model_id de incrustación que configuró en el proceso de OpenSearch ingestión y el k número de resultados devueltos. Para excluir las incrustaciones de los resultados de búsqueda, especifique el nombre del campo de incrustación en el parámetro: _source.excludes
GET /my-ai-search-index/_search { "_source": { "excludes": [ "output_embedding" ] }, "query": { "neural": { "output_embedding": { "query_text": "What is AI search?", "model_id": "mBGzipQB2gmRjlv_dOoB", "k": 2 } } } }
