Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Visualice los tensores de salida de Amazon SageMaker Debugger en TensorBoard
importante
Esta página está en desuso en favor de Amazon SageMaker AI with TensoBoard, que proporciona una TensorBoard experiencia integral integrada con la SageMaker formación y las funcionalidades de control de acceso del dominio SageMaker AI. Para obtener más información, consulte TensorBoard en Amazon SageMaker AI.
Utilice SageMaker Debugger para crear archivos tensoriales de salida que sean compatibles con. TensorBoard Cargue los archivos para visualizar TensorBoard y analizar sus trabajos de SageMaker entrenamiento. Debugger genera automáticamente archivos tensoriales de salida compatibles con. TensorBoard Para cualquier configuración de gancho que personalice para guardar los tensores de salida, Debugger tiene la flexibilidad de crear resúmenes escalares, distribuciones e histogramas a los que puede importar. TensorBoard
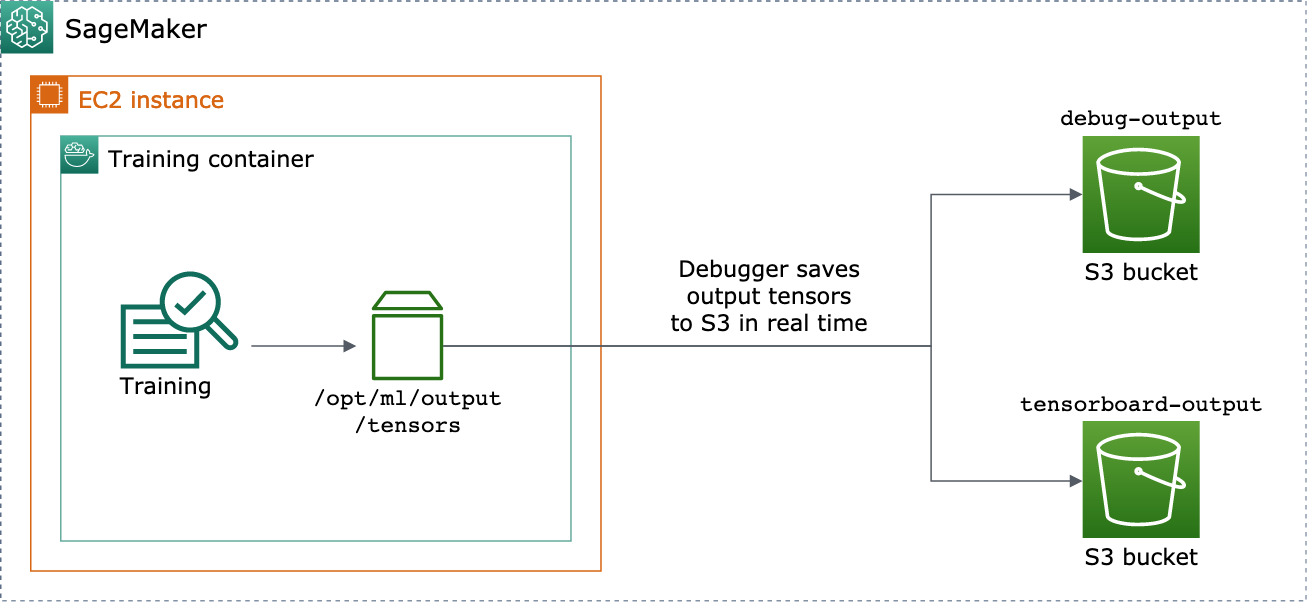
Puede habilitar esto pasando los objetos DebuggerHookConfig y TensorBoardOutputConfig a un estimator.
El siguiente procedimiento explica cómo guardar los escalares, los pesos y los sesgos como tensores, histogramas y distribuciones completos con los que se pueden visualizar. TensorBoard El depurador los guarda en la ruta local del contenedor de entrenamiento (la ruta predeterminada es /opt/ml/output/tensors) y los sincroniza con las ubicaciones de Amazon S3 transferidas a través de los objetos de configuración de salida del depurador.
Para guardar archivos de tensores de salida compatibles mediante Debugger TensorBoard
-
Configure un objeto
tensorboard_output_configde configuración para guardar la TensorBoard salida mediante la claseTensorBoardOutputConfigDebugger. Para els3_output_pathparámetro, especifique el depósito de S3 predeterminado de la sesión de SageMaker IA actual o el depósito de S3 preferido. Este ejemplo no se añade el parámetrocontainer_local_output_path, sino que se establece en la ruta local/opt/ml/output/tensorspredeterminada.import sagemaker from sagemaker.debugger import TensorBoardOutputConfig bucket = sagemaker.Session().default_bucket() tensorboard_output_config = TensorBoardOutputConfig( s3_output_path='s3://{}'.format(bucket) )Para obtener información adicional, consulte la
TensorBoardOutputConfigAPI Debugger en el SDK de Amazon SageMaker Python. -
Configure el enlace del depurador y personalice los valores de los parámetros del enlace. Por ejemplo, el siguiente código configura un enlace de depuración para guardar todas las salidas escalares cada 100 pasos en las fases de entrenamiento y 10 pasos en las fases de validación, los parámetros
weightscada 500 pasos (el valorsave_intervalpredeterminado para guardar las colecciones de tensores es 500) y los parámetrosbiascada 10 pasos globales hasta que el paso global llegue a 500.from sagemaker.debugger import CollectionConfig, DebuggerHookConfig hook_config = DebuggerHookConfig( hook_parameters={ "train.save_interval": "100", "eval.save_interval": "10" }, collection_configs=[ CollectionConfig("weights"), CollectionConfig( name="biases", parameters={ "save_interval": "10", "end_step": "500", "save_histogram": "True" } ), ] )Para obtener más información sobre las API de configuración del depurador, consulte el depurador
CollectionConfigyDebuggerHookConfiglas API del SDK de Amazon SageMaker Python. -
Cree un estimador de SageMaker IA con los parámetros del depurador que pasen por los objetos de configuración. La siguiente plantilla de ejemplo muestra cómo crear un estimador de IA genérico SageMaker . Puede sustituir
estimatory porEstimatorlas clases principales y estimadoras de otros marcos de SageMaker IA. Los estimadores del marco de SageMaker IA disponibles para esta funcionalidad son, y.TensorFlowPyTorchMXNetfrom sagemaker.estimatorimportEstimatorestimator =Estimator( ... # Debugger parameters debugger_hook_config=hook_config, tensorboard_output_config=tensorboard_output_config ) estimator.fit()El
estimator.fit()método inicia un trabajo de entrenamiento y Debugger escribe los archivos tensoriales de salida en tiempo real en la ruta de salida del Debugger S3 y en la ruta de salida S3. TensorBoard Para recuperar las rutas de salida, utilice los siguientes métodos de estimador:-
Para la ruta de salida del depurador S3, utilice
estimator.latest_job_debugger_artifacts_path(). -
Para la ruta de salida de TensorBoard S3, utilice.
estimator.latest_job_tensorboard_artifacts_path()
-
-
Una vez finalizado el entrenamiento, compruebe los nombres de los tensores de salida guardados:
from smdebug.trials import create_trial trial = create_trial(estimator.latest_job_debugger_artifacts_path()) trial.tensor_names() -
Compruebe los datos TensorBoard de salida en Amazon S3:
tensorboard_output_path=estimator.latest_job_tensorboard_artifacts_path() print(tensorboard_output_path) !aws s3 ls {tensorboard_output_path}/ -
Descargue los datos TensorBoard de salida a la instancia de su notebook. Por ejemplo, el siguiente AWS CLI comando descarga los TensorBoard archivos
/logs/fiten el directorio de trabajo actual de su instancia de notebook.!aws s3 cp --recursive {tensorboard_output_path}./logs/fit -
Comprima el directorio de archivos en un archivo TAR para descargarlo en su máquina local.
!tar -cf logs.tar logs -
Descarga y extrae el archivo TAR de Tensorboard en un directorio de tu dispositivo, inicia un servidor de cuadernos de Jupyter, abre un cuaderno nuevo y ejecuta la aplicación. TensorBoard
!tar -xf logs.tar %load_ext tensorboard %tensorboard --logdir logs/fit
La siguiente captura de pantalla animada ilustra los pasos 5 a 8. Muestra cómo descargar el archivo TensorBoard TAR del Debugger y cómo cargarlo en un bloc de notas de Jupyter en tu dispositivo local.