Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Descarga del informe de entrenamiento XGBoost del depurador
Descargue el informe de formación de Debugger XGBoost mientras se esté ejecutando el trabajo de formación o una vez finalizado el trabajo con el SDK y ( AWS Command Line Interface
CLI) de Amazon SageMaker Python
- Download using the SageMaker Python SDK and AWS CLI
-
-
Compruebe el URI base de salida de S3 predeterminado del trabajo actual.
estimator.output_path -
Compruebe el nombre del trabajo actual.
estimator.latest_training_job.job_name -
El informe XGBoost del depurador se guarda en
<default-s3-output-base-uri>/<training-job-name>/rule-output. Configure la ruta de salida de reglas de la siguiente manera:rule_output_path = estimator.output_path + "/" + estimator.latest_training_job.job_name + "/rule-output" -
Para comprobar si el informe se ha generado correctamente, enumere los directorios y archivos de forma recursiva en
rule_output_pathutilizandoaws s3 lscon la opción--recursive.! aws s3 ls {rule_output_path} --recursiveEsto debería devolver una lista completa de los archivos de las carpetas generadas automáticamente con el nombre
CreateXgboostReportyProfilerReport-1234567890. El informe de entrenamiento de XGBoost se guarda enCreateXgboostReporty el informe de creación de perfiles se guarda en la carpetaProfilerReport-1234567890. Para obtener más información sobre el informe de creación de perfiles generado de forma predeterminada con el trabajo de entrenamiento de XGBoost, consulte SageMaker Informe interactivo sobre el depurador.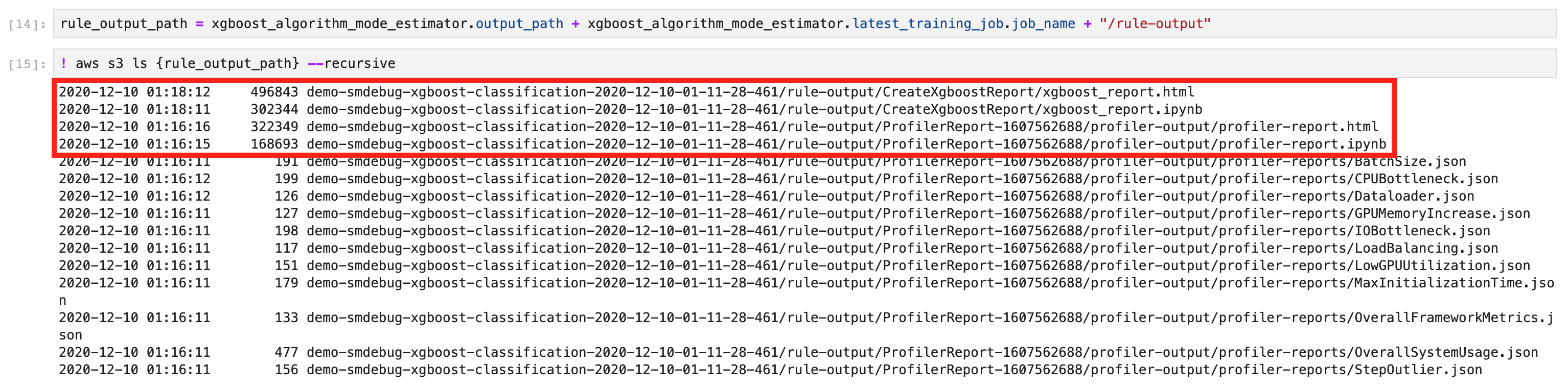
El
xgboost_report.htmles un informe de entrenamiento de XGBoost generado automáticamente por el depurador. Elxgboost_report.ipynbes un cuaderno de Jupyter que se utiliza para agregar los resultados del entrenamiento al informe. Puede descargar todos los archivos, examinar el archivo de informe HTML y modificar el informe con el cuaderno. -
Descargue los archivos de forma recursiva utilizando
aws s3 cp. El siguiente comando guarda todos los archivos de salida de las reglas en la carpetaProfilerReport-1234567890del directorio de trabajo actual.! aws s3 cp {rule_output_path}./--recursivesugerencia
Si utiliza un servidor del cuaderno de Jupyter, ejecute
!pwdpara comprobar el directorio de trabajo actual. -
En el directorio
/CreateXgboostReport, abraxgboost_report.html. Si lo está utilizando JupyterLab, elija Confiar en HTML para ver el informe de formación de Debugger generado automáticamente.
-
Abra el archivo
xgboost_report.ipynbpara ver cómo se genera el informe. Puede personalizar y ampliar el informe de entrenamiento mediante el archivo de cuaderno de Jupyter.
-
- Download using the Amazon S3 console
-
Inicie sesión en la consola de Amazon S3 AWS Management Console y ábrala en https://console.aws.amazon.com/s3/
. -
Busque el bucket base de S3. Por ejemplo, si no ha especificado ningún nombre de trabajo base, el nombre del bucket base de S3 debe tener el siguiente formato:
sagemaker-. Busque el bucket base de S3 en el campo Buscar bucket por nombre.<region>-111122223333
-
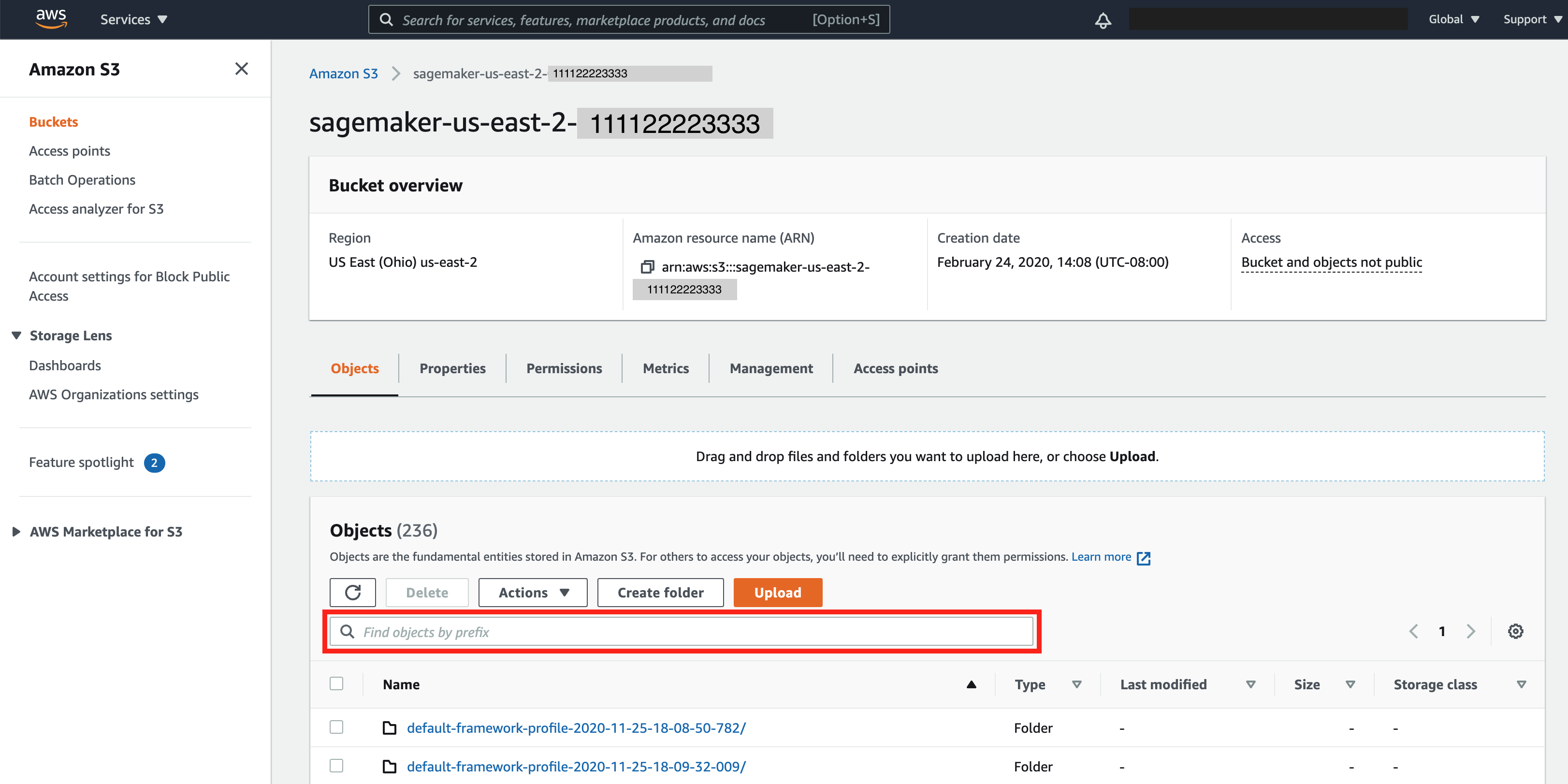
En el bucket base de S3, busque el nombre del trabajo de entrenamiento. Para ello, introduzca el prefijo del nombre del trabajo en Buscar objetos por prefijo y, a continuación, seleccione el nombre del trabajo de entrenamiento.
-
En el compartimento S3 del trabajo de entrenamiento, seleccione la subcarpeta rule-output/. Debe haber tres subcarpetas para los datos de entrenamiento recopilados por el depurador: debug-output/, profiler-output/ y rule-output/.

-
En la carpeta rule-output/, elija la carpeta/. CreateXgboostReport La carpeta contiene xbgoost_report.html (el informe generado automáticamente en html) y xbgoost_report.ipynb (un cuaderno de Jupyter con scripts que se utilizan para generar el informe).
-
Seleccione el archivo xbgoost_report.html, seleccione Acciones de descarga y, por último, seleccione Descargar.

-
Abra el archivo xbgoost_report.html descargado en un navegador web.
