Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Demostraciones y visualización avanzadas del depurador
Las siguientes demostraciones explican los casos de uso avanzados y los scripts de visualización con el depurador.
Temas
Entrenar y depurar modelos con Amazon SageMaker Experiments y Debugger
Dra. Nathalie Rauschmayr, científica AWS aplicada | Duración: 49 minutos 26 segundos
Descubra cómo Amazon SageMaker Experiments y Debugger pueden simplificar la administración de sus trabajos de formación. Amazon SageMaker Debugger proporciona una visibilidad transparente de los trabajos de formación y guarda las métricas de formación en su bucket de Amazon S3. SageMaker Experiments le permite denominar la información de formación como pruebas a través de SageMaker Studio y permite visualizar el trabajo de formación. Esto le ayuda a mantener la calidad del modelo a la vez que reduce los parámetros menos importantes en función del rango de importancia.
En este vídeo se muestra una técnica de poda de modelos que hace que ResNet 50 AlexNet modelos previamente entrenados sean más livianos y asequibles, a la vez que se mantienen altos estándares de precisión de los modelos.
SageMaker AI Estimator entrena los algoritmos proporcionados por el zoológico de PyTorch modelos en un AWS Deep Learning Containers with PyTorch framework, y Debugger extrae las métricas de entrenamiento del proceso de entrenamiento.
El vídeo también muestra cómo configurar una regla personalizada del Debugger para comprobar la precisión de un modelo reducido, activar un CloudWatch evento de Amazon y una AWS Lambda función cuando la precisión alcanza un umbral y detener automáticamente el proceso de depuración para evitar iteraciones redundantes.
Los objetivos de aprendizaje son los siguientes:
-
Aprenda a usar la SageMaker IA para acelerar el entrenamiento de modelos de aprendizaje automático y mejorar la calidad de los modelos.
-
Aprenda a gestionar las iteraciones de entrenamiento con SageMaker Experiments capturando automáticamente los parámetros de entrada, las configuraciones y los resultados.
-
Descubrir cómo el depurador aporta transparencia al proceso de entrenamiento al capturar automáticamente datos de tensores en tiempo real de métricas como ponderaciones, gradientes y salidas de activación de redes neuronales convolucionales.
-
Se utiliza CloudWatch para activar Lambda cuando el depurador detecta problemas.
-
Domine el proceso de SageMaker formación con SageMaker Experiments y Debugger.
Puede encontrar los cuadernos y los guiones de entrenamiento utilizados en este vídeo de SageMaker Debugger PyTorch Iterative Model Pruning
La siguiente imagen muestra cómo el proceso de depuración del modelo iterativo reduce el tamaño al eliminar los 100 filtros menos significativos en función del rango de importancia evaluado mediante los gradientes y los resultados de activación. AlexNet
El proceso de poda redujo los 50 millones de parámetros iniciales a 18 millones. También redujo el tamaño estimado del modelo de 201 MB a 73 MB.
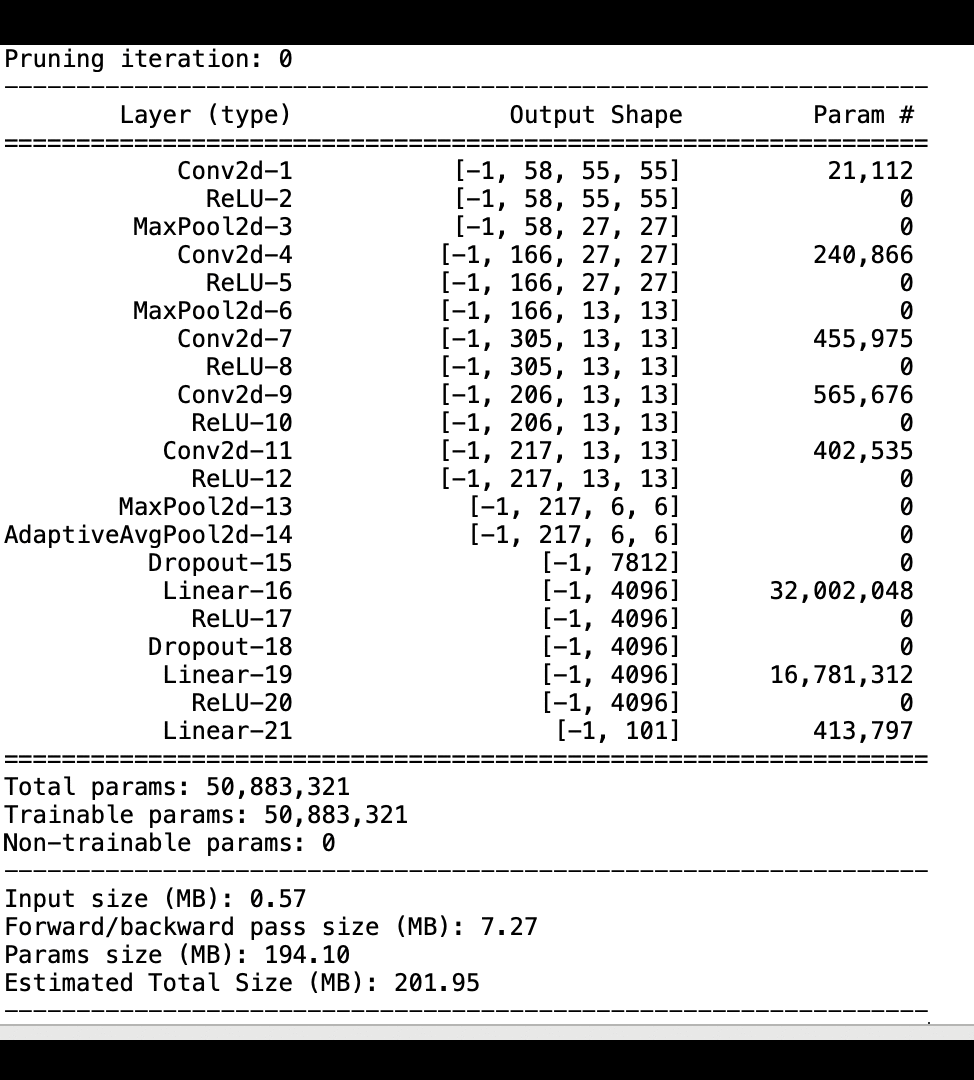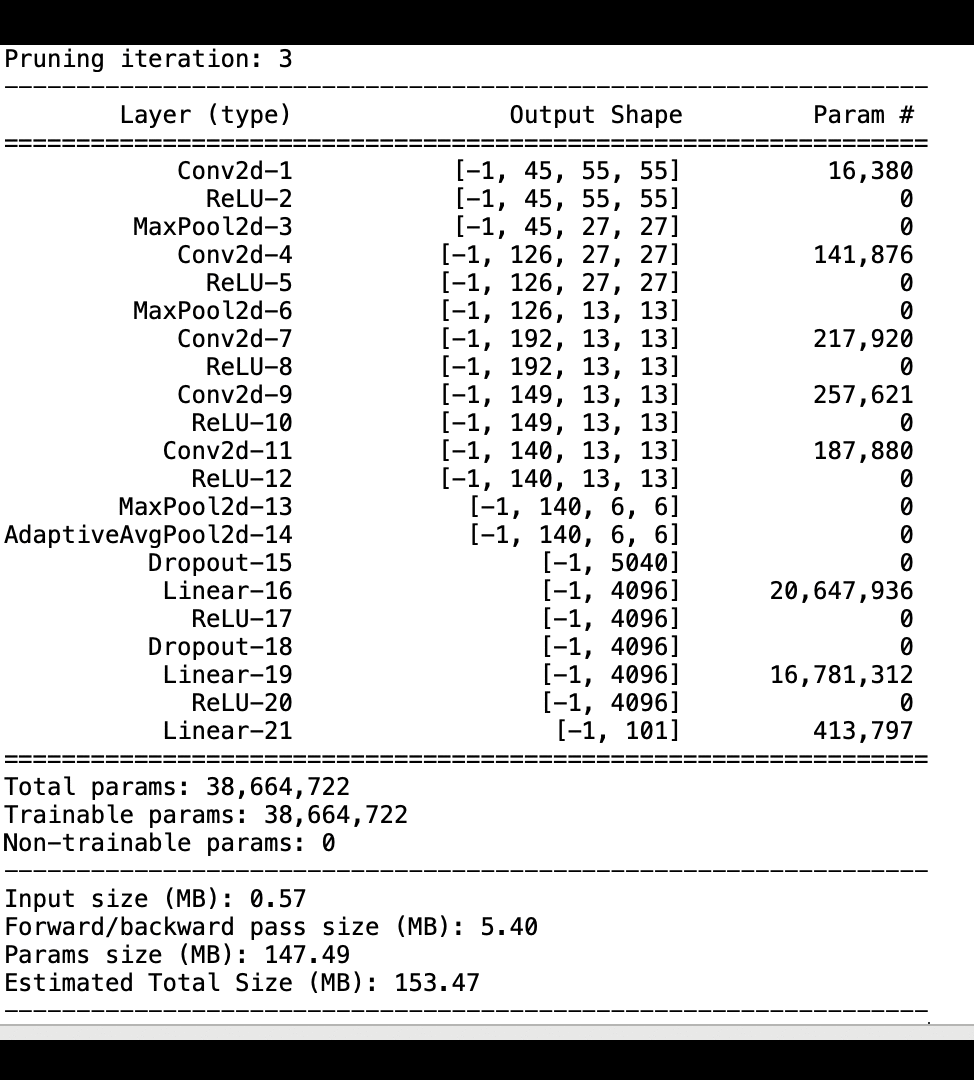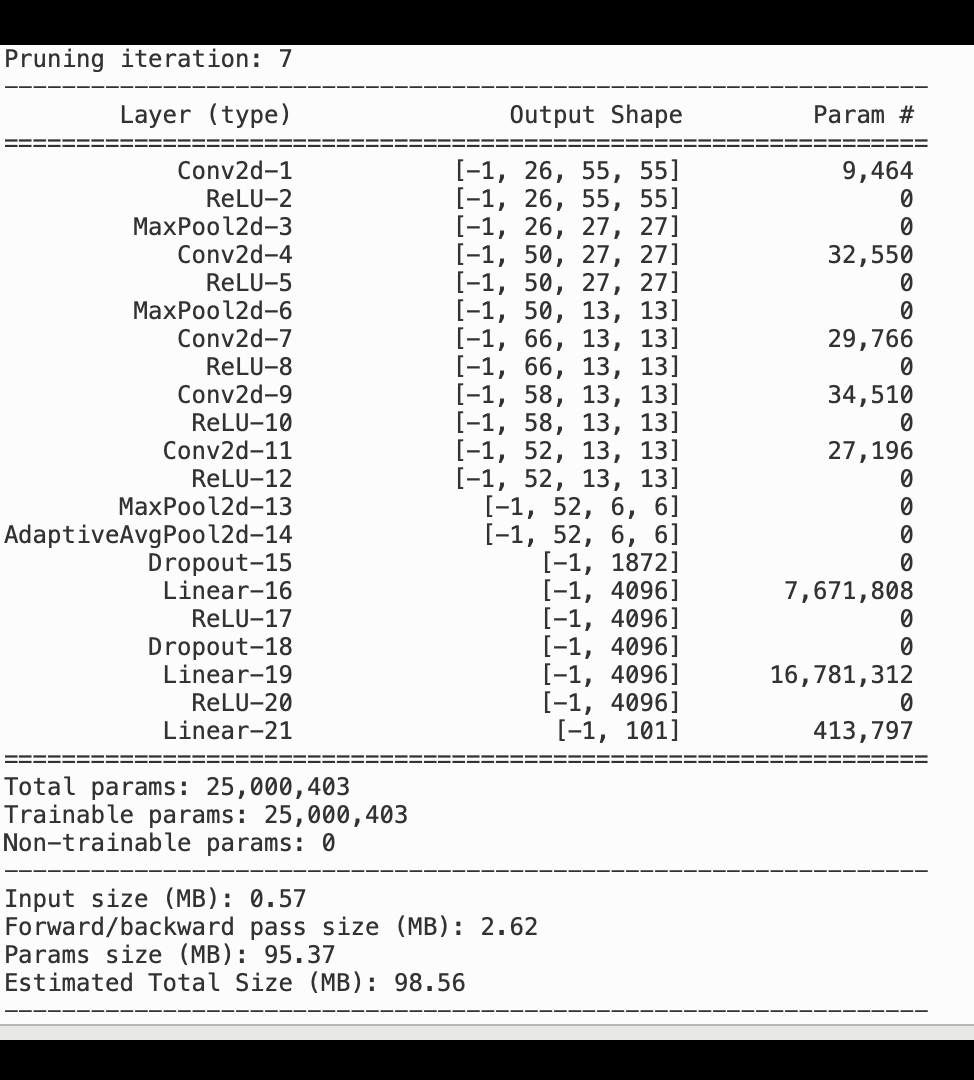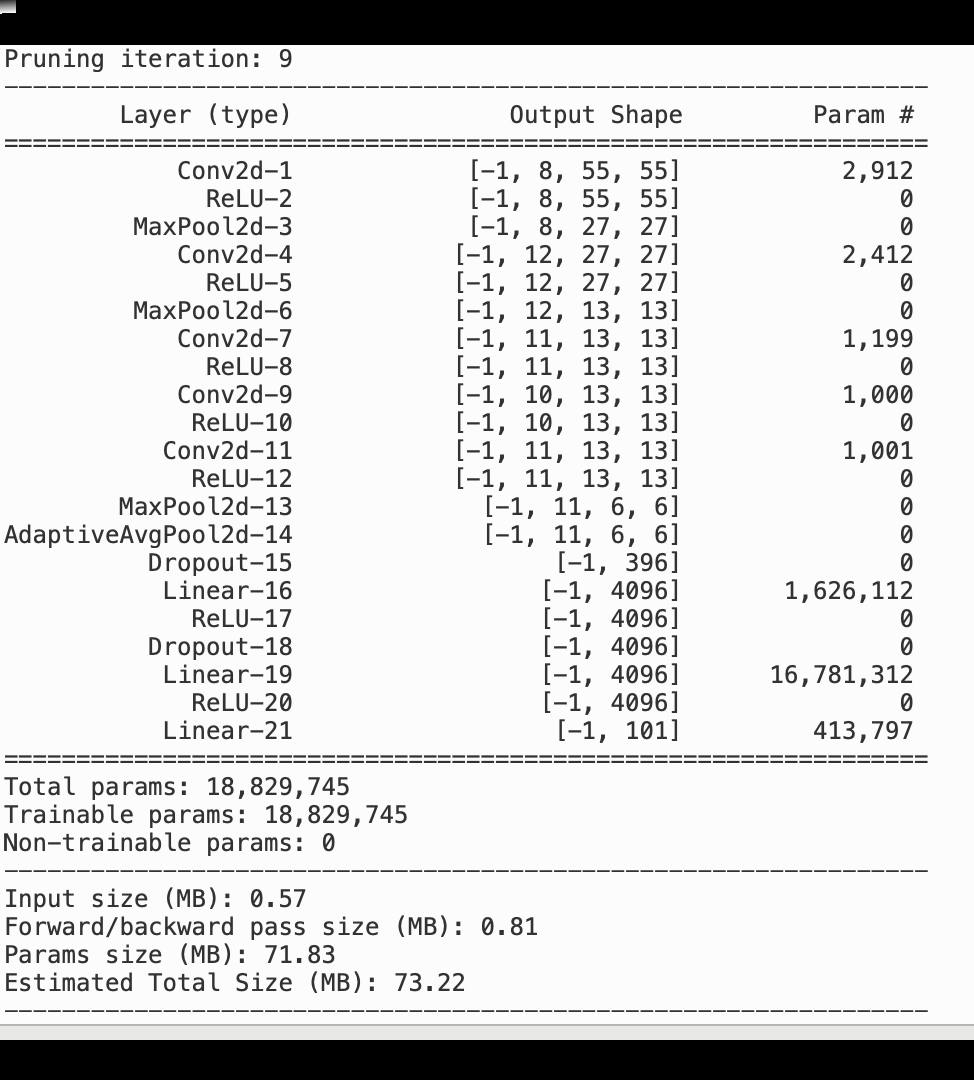
También es necesario realizar un seguimiento de la precisión del modelo, y en la siguiente imagen se muestra cómo se puede trazar el proceso de depuración del modelo para visualizar los cambios en la precisión del modelo en función del número de parámetros de SageMaker Studio.

En SageMaker Studio, seleccione la pestaña Experimentos, seleccione una lista de tensores guardados por Debugger durante el proceso de depuración y, a continuación, cree un panel con una lista de componentes de prueba. Seleccione las diez iteraciones y elija Agregar gráfico para crear un Gráfico de componentes de prueba. Una vez que haya decidido qué modelo desea implementar, elija el componente de prueba y un menú para realizar una acción o elija Implementar el modelo.
nota
Para implementar un modelo en SageMaker Studio utilizando el siguiente ejemplo de cuaderno, añade una línea al final de la train función en el train.py script.
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
Uso de SageMaker Debugger para supervisar el entrenamiento de un modelo de autocodificador convolucional
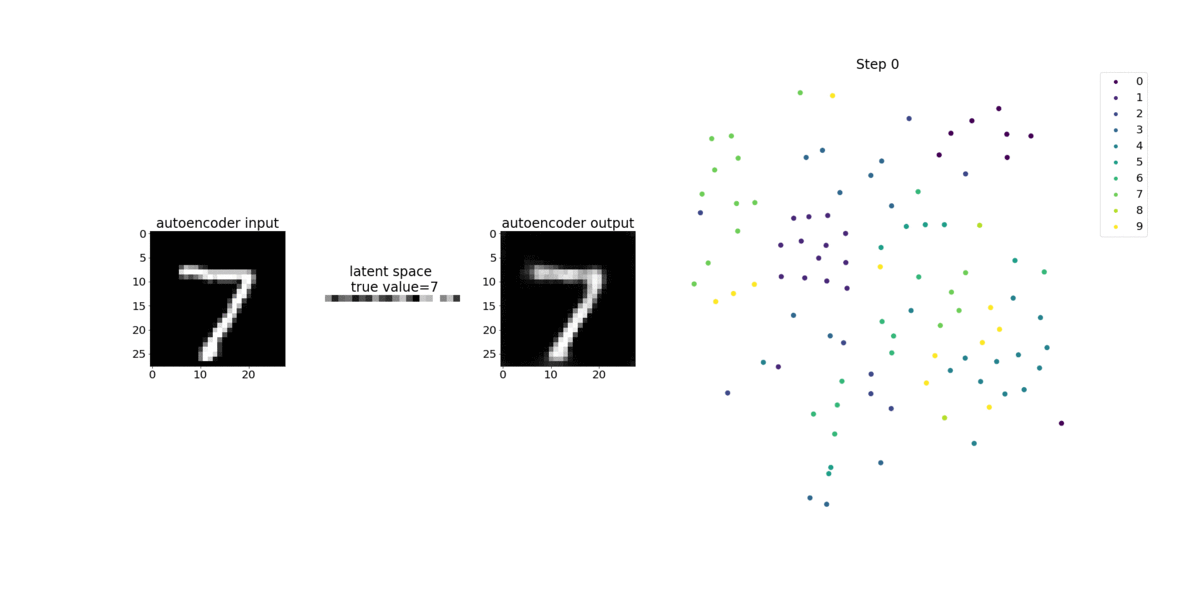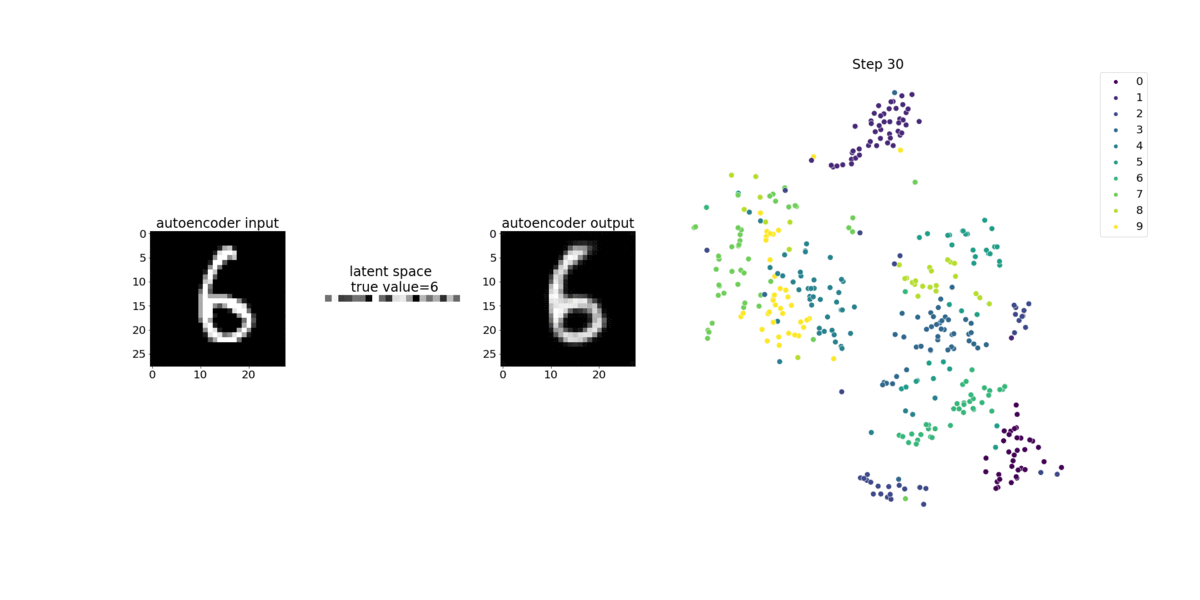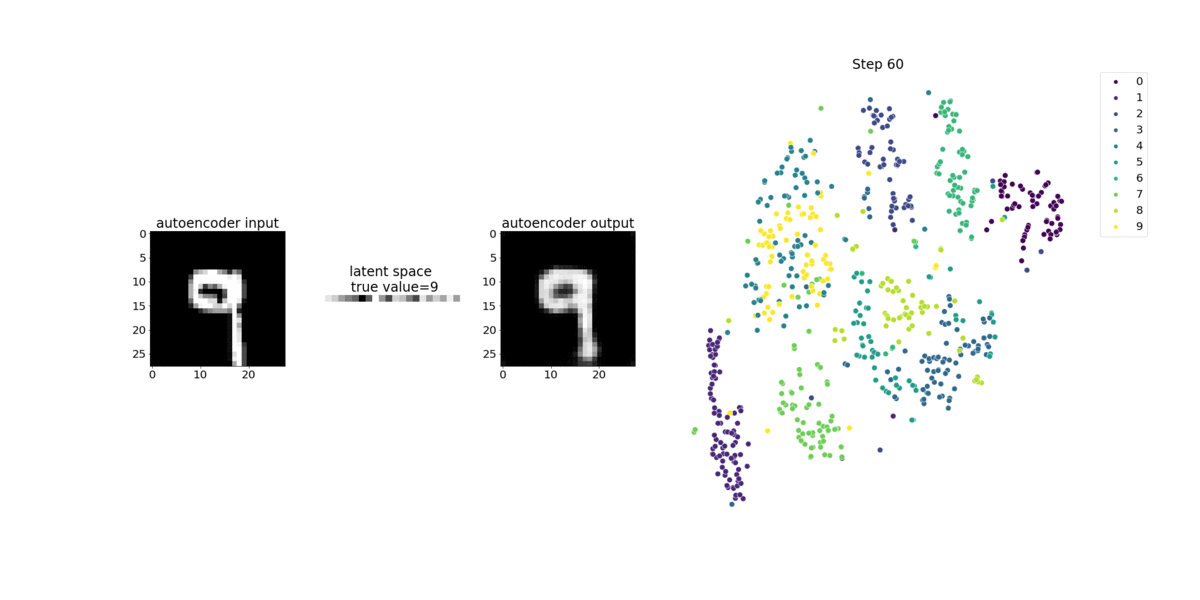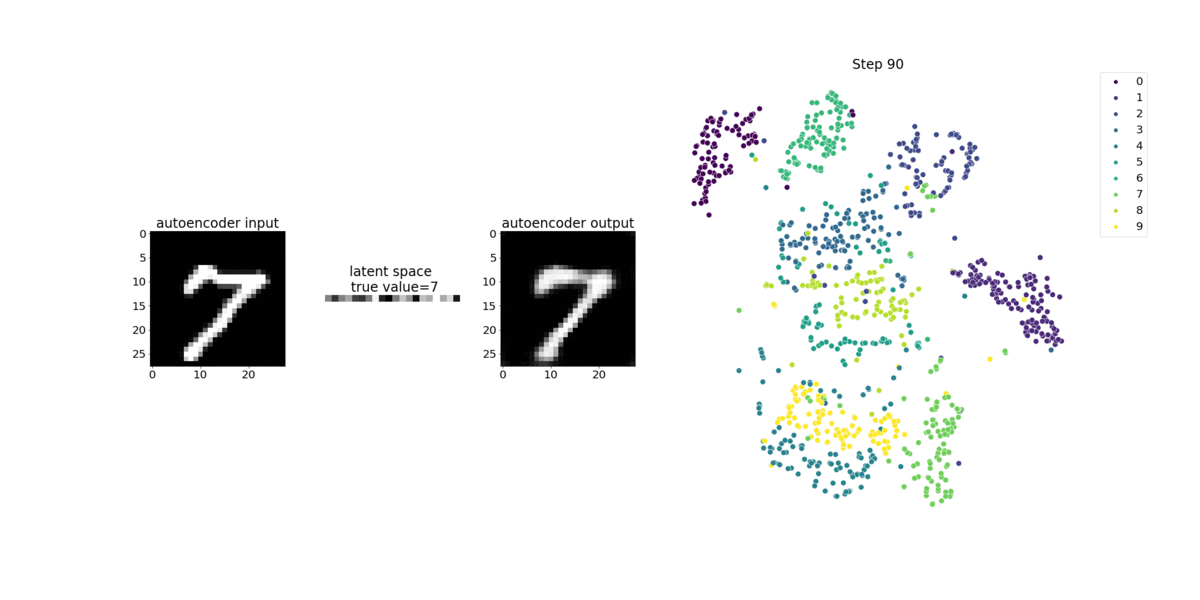
Este cuaderno muestra cómo SageMaker Debugger visualiza los tensores de un proceso de aprendizaje no supervisado (o autosupervisado) en un conjunto de datos de imágenes del MNIST de números escritos a mano.
El modelo de entrenamiento en este bloc de notas es un autocodificador convolucional con el marco MXNet. El autocodificador convolucional tiene una red neuronal convolucional que consta en una parte codificadora y una parte decodificadora.
El codificador de este ejemplo tiene dos capas de convolución para producir una representación comprimida (variables latentes) de las imágenes de entrada. En este caso, el codificador produce una variable latente de tamaño (1, 20) a partir de una imagen de entrada original de tamaño (28, 28) y reduce significativamente el tamaño de los datos para el entrenamiento en 40 veces.
El decodificador tiene dos capas deconvolucionales y garantiza que las variables latentes preserven la información clave mediante la reconstrucción de imágenes de salida.
El codificador convolucional potencia algoritmos de agrupamiento con menor tamaño de datos de entrada, así como el rendimiento de algoritmos de agrupamiento como k-means, k-NN y t-Distributed Stochastic Neighbor Embedding (t-SNE).
Este ejemplo de cuaderno muestra cómo visualizar las variables latentes mediante el depurador, como se muestra en la siguiente animación. También muestra cómo el algoritmo t-SNE clasifica las variables latentes en diez clústeres y las proyecta en un espacio bidimensional. El esquema de color del gráfico de dispersión en el lado derecho de la imagen refleja los valores verdaderos para mostrar lo bien que el modelo BERT y el algoritmo t-SNE organizan las variables latentes en los clústeres.
Uso de SageMaker Debugger para monitorear las atenciones en el entrenamiento con modelos BERT
Las Representaciones de codificador bidireccional de transformadores (BERT) constituyen un modelo de representación del lenguaje. Como refleja el nombre del modelo, BERT se basa en la transferencia del aprendizaje y el modelo de transformadores para el procesamiento de lenguaje natural (NLP).
El modelo BERT está preentrenado en tareas no supervisadas como predicción de palabras ausentes en una oración o predicción de la siguiente oración que seguiría naturalmente a una oración anterior. Los datos de entrenamiento contienen 3300 millones de palabras (tokens) de texto en inglés, como Wikipedia y libros electrónicos. Para un ejemplo sencillo, el modelo BERT puede prestar gran atención a los tokens de verbo o tokens de pronombre apropiados de un token de sujeto.
El modelo BERT preentrenado se puede ajustar con una capa de salida adicional para lograr un entrenamiento de modelo de vanguardia en tareas de NLP, como respuestas automatizadas a preguntas y clasificación de textos entre muchas otras.
El depurador recopila los tensores del proceso de ajuste. En el contexto de NLP, el peso de las neuronas se denomina atención.
Este cuaderno muestra cómo utilizar el modelo BERT previamente entrenado del zoológico de modelos GluonNLP en el
La representación de puntuaciones de atención y neuronas individuales en la consulta y vectores clave puede ayudar a identificar las causas de predicciones de modelos incorrectas. Con SageMaker AI Debugger, puedes recuperar los tensores y trazar la vista desde el punto de vista del cabezal de atención en tiempo real a medida que avanza el entrenamiento, así como comprender lo que aprende el modelo.
La siguiente animación muestra las puntuaciones de atención de los primeros 20 tokens de entrada para diez iteraciones en el trabajo de entrenamiento proporcionado en el ejemplo del bloc de notas.

Uso de SageMaker Debugger para visualizar los mapas de activación de clases en redes neuronales convolucionales (CNN)
Este cuaderno muestra cómo usar SageMaker Debugger para trazar mapas de activación de clases para la detección y clasificación de imágenes en redes neuronales convolucionales (CNN). En el aprendizaje profundo, una red neuronal convolucional (CNN o ConvNet) es una clase de redes neuronales profundas que se suele aplicar al análisis de imágenes visuales. Una de las aplicaciones que adopta los mapas de activación de clases son los vehículos sin conductor, que requieren detección y clasificación de imágenes instantánea como señales de tráfico, carreteras y obstáculos.
En este cuaderno, el PyTorch ResNet modelo se basa en el conjunto de datos de señales de tráfico alemán
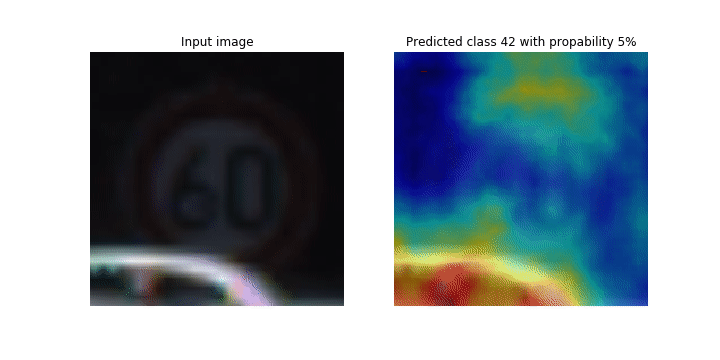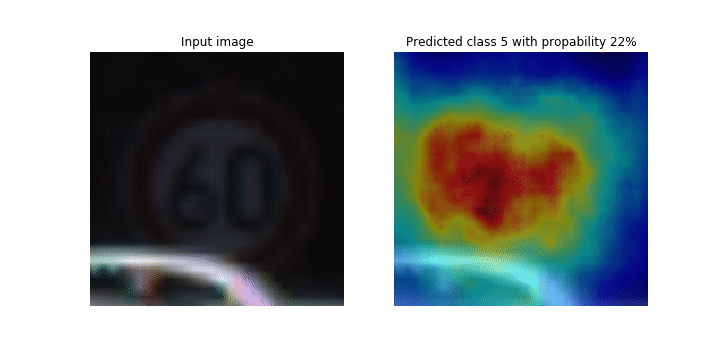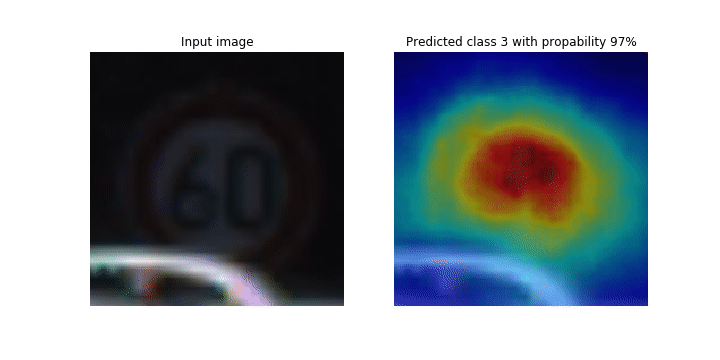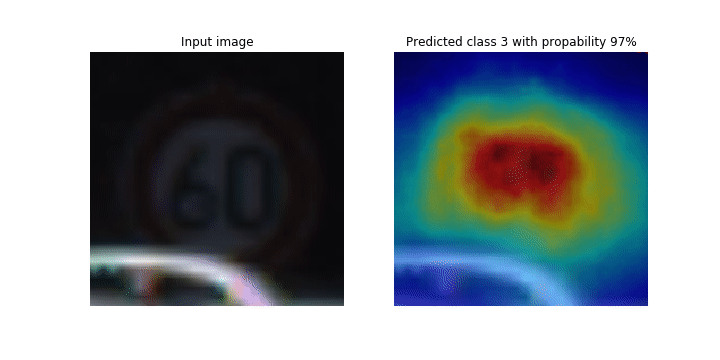
Durante el proceso de entrenamiento, SageMaker Debugger recopila tensores para trazar los mapas de activación de las clases en tiempo real. Como se muestra en la imagen animada, el mapa de activación de clases (también llamado mapa de prominencia) resalta regiones con alta activación en color rojo.
Con los tensores capturados por el depurador, puede visualizar cómo evoluciona el mapa de activación durante el entrenamiento del modelo. El modelo comienza detectando el borde en la esquina inferior izquierda al comienzo del trabajo de entrenamiento. A medida que avanza el entrenamiento, el foco se desplaza hacia el centro y detecta la señal de límite de velocidad, y el modelo predice correctamente la imagen de entrada como clase 3, que es una clase de 60km/h señales de límite de velocidad, con un nivel de confianza del 97%.
