Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Reparaciones de clústeres para corregir errores en la GPU
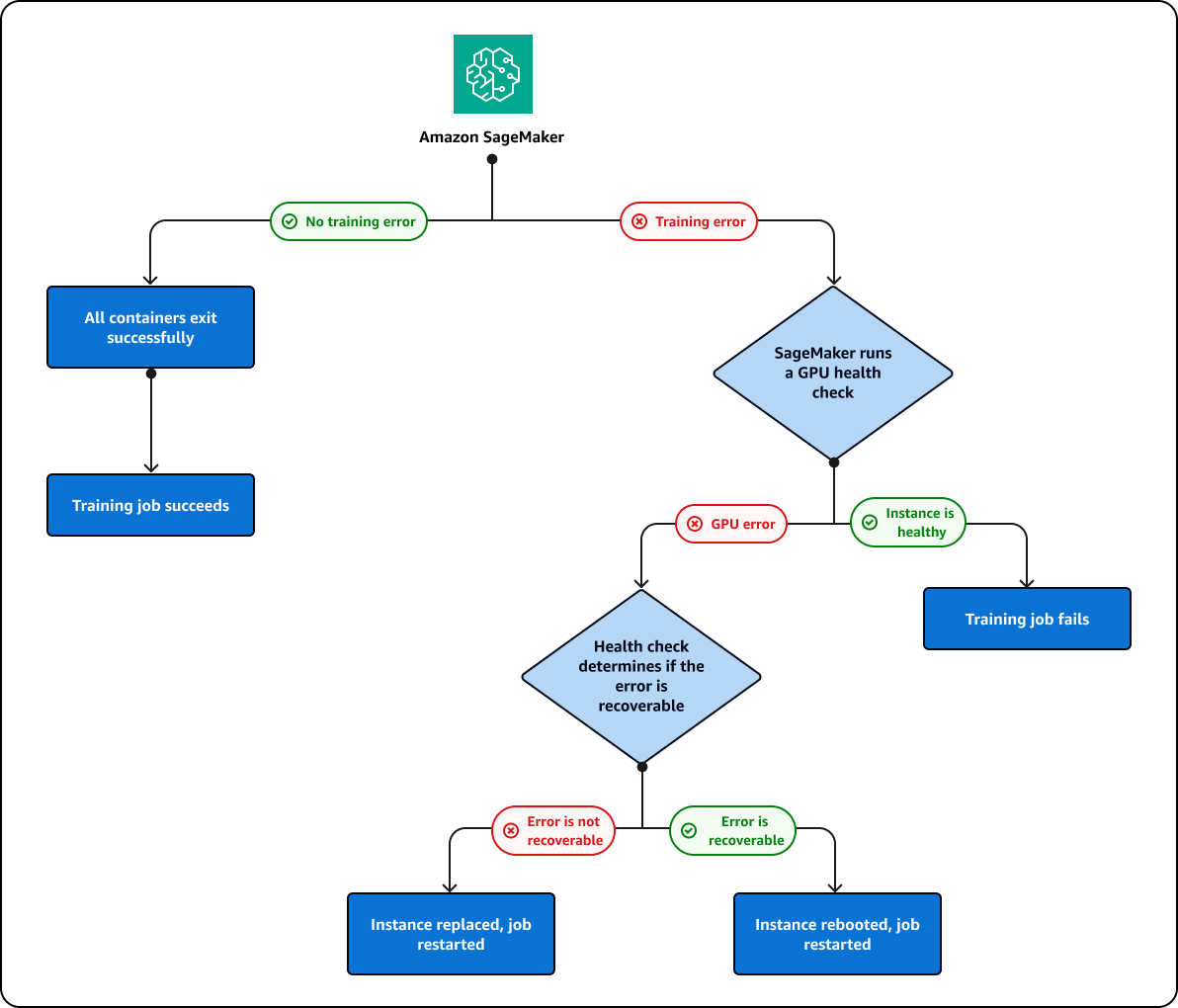
Si estás realizando un trabajo de entrenamiento que falla en una GPU, la SageMaker IA realizará una comprobación del estado de la GPU para comprobar si el fallo está relacionado con un problema con la GPU. SageMaker La IA toma las siguientes medidas en función de los resultados de las comprobaciones de estado:
Si el error se puede recuperar y se puede corregir reiniciando la instancia o restableciendo la GPU, SageMaker AI reiniciará la instancia.
Si el error no se puede recuperar y se debe a la necesidad de sustituir una GPU, la IA sustituirá la instancia. SageMaker
La instancia se reemplaza o se reinicia como parte de un proceso de reparación del clúster de SageMaker IA. Durante este proceso, aparecerá el siguiente mensaje en el estado del trabajo de entrenamiento:
Repairing training cluster due to hardware failure
SageMaker La IA intentará reparar el clúster varias veces. 10 Si la reparación del clúster se realiza correctamente, la SageMaker IA reiniciará automáticamente el trabajo de formación desde el punto de control anterior. Si se produce un error en la reparación del clúster, también se producirá un error en el trabajo de entrenamiento. No se le cobrará por el proceso de reparación del clúster. Las reparaciones de los clústeres no se iniciarán a no ser que se produzca un error en el trabajo de entrenamiento. Si se detecta un problema con la GPU en un clúster de grupo en caliente, el clúster pasará al modo de reparación para reiniciar o reemplazar la instancia errónea. Tras la reparación, el clúster podrá seguir utilizándose como clúster de grupo en caliente.
El proceso de reparación de clústeres e instancias que se ha descrito anteriormente se representa en el siguiente diagrama: