Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conceptos de paralelismo de modelos
El paralelismo de modelos es un método de entrenamiento distribuido en el que el modelo de aprendizaje profundo (DL) se divide en varias GPU e instancias. La biblioteca paralela de SageMaker modelos v2 (SMP v2) es compatible con las PyTorch API y capacidades nativas. Esto le permite adaptar cómodamente su script de entrenamiento de PyTorch Fully Sharded Data Parallel (FSDP) a la plataforma de SageMaker entrenamiento y aprovechar la mejora del rendimiento que ofrece el SMP v2. Esta página de introducción proporciona una descripción general sobre el paralelismo de modelos y cómo puede ayudar a superar los problemas que surgen al entrenar modelos de aprendizaje profundo (DL) que suelen ser de gran tamaño. También proporciona ejemplos de lo que ofrece la biblioteca paralela de SageMaker modelos para ayudar a gestionar las estrategias paralelas de los modelos y el consumo de memoria.
¿Qué es el paralelismo de modelos?
Al aumentar el tamaño de los modelos de aprendizaje profundo (capas y parámetros), se obtiene mayor precisión en tareas complejas, como la visión artificial y el procesamiento del lenguaje natural. Sin embargo, existe un límite en el tamaño máximo de modelo que puede caber en una sola GPU. Al entrenar modelos de DL, las limitaciones de memoria de la GPU pueden ser cuellos de botella de las siguientes maneras:
-
Limitan el tamaño del modelo que se puede entrenar, ya que el consumo de memoria de un modelo se amplía proporcionalmente al número de parámetros.
-
Limitan el tamaño del lote por GPU durante el entrenamiento, lo que reduce el uso de la GPU y la eficiencia del entrenamiento.
Para superar las limitaciones asociadas con el entrenamiento de un modelo en una sola GPU, la SageMaker IA proporciona la biblioteca de modelos parallel para ayudar a distribuir y entrenar los modelos DL de manera eficiente en varios nodos de cómputo. Además, con la biblioteca, puede lograr un entrenamiento distribuido optimizado mediante EFA-supported dispositivos, lo que mejora el rendimiento de la comunicación entre nodos con baja latencia, alto rendimiento y elusión del sistema operativo.
Cálculo de los requisitos de memoria antes de utilizar el paralelismo de modelos
Antes de utilizar la biblioteca de SageMaker modelos parallel, tenga en cuenta lo siguiente para hacerse una idea de los requisitos de memoria necesarios para el entrenamiento de modelos DL de gran tamaño.
Para un trabajo de entrenamiento que utilice precisión mixta optimizada como los optimizadores float16 (FP16) o bfloat16 (BF16) y Adam, la memoria de GPU necesaria por parámetro es de unos 20 bytes, que podemos desglosar de la siguiente manera:
-
Un parámetro FP16 o BF16: ~2 bytes
-
Un gradiente de FP16 o BF16: ~2 bytes
-
Un optimizador FP32 tiene un estado de ~8 bytes basado en los optimizadores Adam
-
Una copia FP32 del parámetro de ~4 bytes [necesaria para la operación
optimizer apply(OA)] -
Una copia FP32 del gradiente de ~4 bytes (necesaria para la operación OA)
Incluso para un modelo DL relativamente pequeño con 10 000 millones de parámetros, puede requerir al menos 200 GB de memoria, mucho más que la memoria típica de una GPU (por ejemplo, la NVIDIA A100 con 40GB/80GB memoria) disponible en una sola GPU. Además de los requisitos de memoria para los estados del modelo y del optimizador, hay otros consumidores de memoria, como las activaciones que se generan en la transferencia directa. La memoria requerida puede superar con creces los 200 GB.
Para el entrenamiento distribuido, le recomendamos que utilice instancias P4 y P5 de Amazon EC2 que tengan GPU NVIDIA A100 y H100 Tensor Core, respectivamente. Para obtener más información sobre especificaciones como los núcleos de la CPU, la RAM, el volumen de almacenamiento adjunto y el ancho de banda de la red, consulte la sección Computación acelerada de la página Tipos de instancias de Amazon EC2
Incluso con las instancias de computación acelerada, los modelos con unos 10 000 millones de parámetros, como Megatron-LM la T5, e incluso los modelos más grandes con cientos de miles de millones de parámetros GPT-3, no caben réplicas de modelos en cada dispositivo de GPU.
Cómo emplea la biblioteca el paralelismo de modelos y las técnicas de ahorro de memoria
La biblioteca consta de varios tipos de funciones de paralelismo de modelos y funciones de ahorro de memoria, como la fragmentación del estado del optimizador, los puntos de control de activación y la descarga de la activación. Todas estas técnicas se pueden combinar para entrenar de manera eficiente modelos grandes que constan de cientos de miles de millones de parámetros.
Temas
Paralelismo de datos particionados
El paralelismo de datos partidos es una técnica de entrenamiento distribuido que ahorra memoria y que divide el estado de un modelo (parámetros del modelo, gradientes y estados del optimizador) entre las GPU de un grupo de paralelismo de datos.
Puede aplicar el paralelismo de datos particionados a su modelo como estrategia independiente. Además, si utilizas las instancias de GPU de mayor rendimiento equipadas con GPU NVIDIA A100 Tensor Coreml.p4de.24xlarge, ml.p4d.24xlarge puedes aprovechar la mejora de la velocidad de entrenamiento gracias a la AllGather operación que ofrece la biblioteca de paralelismo de SageMaker datos (SMDDP).
Para profundizar en el paralelismo de datos particionados y aprender a configurarlo o utilizar una combinación de paralelismo de datos particionados con otras técnicas, como paralelismo de tensores y entrenamiento de precisión mixta, consulte Paralelismo híbrido de datos particionados.
Paralelismo experto
SMP v2 se integra con NVIDIA Megatron
Un modelo de MoE es un tipo de modelo de transformador que consta de varios expertos, cada uno de los cuales se compone de una red neuronal, normalmente una red prealimentada (FFN). Una red de puertas llamada router determina qué tokens se envían a cada experto. Estos expertos se especializan en procesar aspectos específicos de los datos de entrada, lo que permite que el modelo se entrene más rápido, se reduzcan los costos de cómputo y, al mismo tiempo, se logre la misma calidad de rendimiento que su modelo denso homólogo. Además, el paralelismo experto es una técnica de paralelismo que permite dividir a los expertos de un modelo de MoE entre dispositivos de GPU.
Para obtener información sobre cómo entrenar modelos MoE con SMP v2, consulte Paralelismo experto.
Paralelismo de tensores
El paralelismo de tensores divide capas individuales, o nn.Modules, entre dispositivos, para que se ejecuten en paralelo. La siguiente figura muestra el ejemplo más simple de cómo la biblioteca de SMP divide un modelo con cuatro capas para lograr un paralelismo de tensores bidireccional ("tensor_parallel_degree": 2). En la siguiente figura, las anotaciones para el grupo de paralelismo de modelos, el grupo de paralelismo de tensores y el grupo de paralelismo de datos son MP_GROUP, TP_GROUP y DP_GROUP, respectivamente. Las capas de cada réplica del modelo están divididas en dos y distribuidas en dos GPU. La biblioteca gestiona la comunicación entre las réplicas del modelo distribuido por tensores.
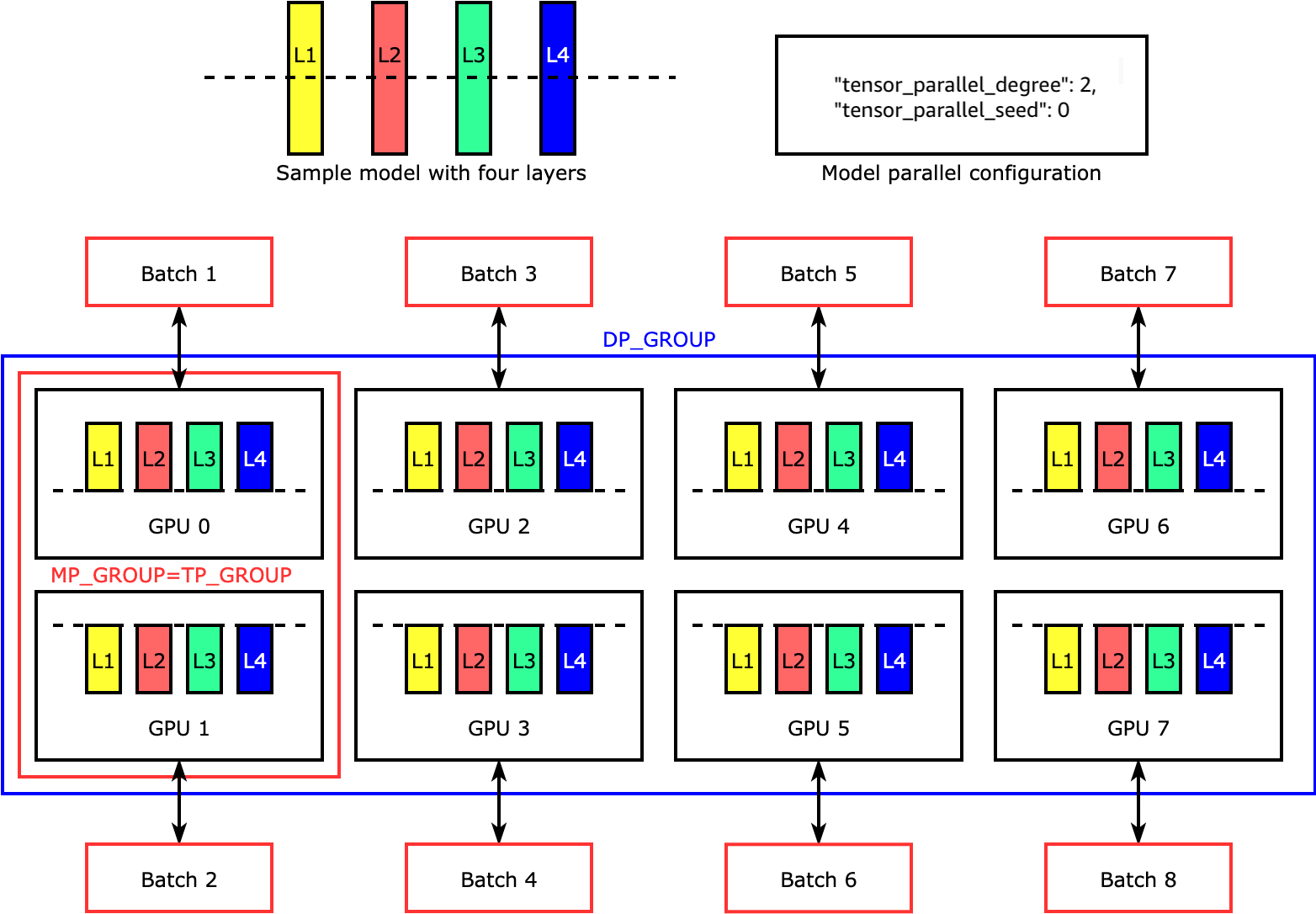
Para profundizar en el paralelismo tensorial y otras funciones que ahorran memoria y aprender a configurar una combinación de las funciones principales PyTorch, consulte. Paralelismo de tensores
Puntos de comprobación de activación y descarga
Para ahorrar memoria en la GPU, la biblioteca admite puntos de control de activación para evitar almacenar las activaciones internas en la memoria de la GPU para los módulos especificados por el usuario durante la transferencia. La biblioteca vuelve a calcular estas activaciones durante la pasada hacia atrás. Además, con la descarga de activaciones, transfiere las activaciones almacenadas a la memoria de la CPU y las recupera en la GPU durante la transferencia hacia atrás para reducir aún más el consumo de memoria de activación. Para obtener más información sobre el uso de estas características, consulte Puntos de control de activación y Descarga de activación.
Elegir las técnicas adecuadas para su modelo
Para obtener más información sobre cómo elegir las técnicas y configuraciones correctas de, consulte SageMaker mejores prácticas de paralelismo de modelos distribuidos.
