Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cargador de datos mapeado en memoria
Otra sobrecarga de reinicio se debe a la carga de datos: el clúster de entrenamiento permanece inactivo mientras el cargador de datos se inicializa, descarga datos de sistemas de archivos remotos y los procesa en lotes.
Para solucionar este problema, presentamos el cargador de datos con mapas de memoria DataLoader (MMAP), que almacena en caché los lotes precargados en la memoria persistente, lo que garantiza que permanezcan disponibles incluso después de un reinicio provocado por un error. Este enfoque elimina el tiempo de configuración del cargador de datos y permite reanudar inmediatamente el entrenamiento utilizando lotes en caché, mientras que el cargador de datos se reinicializa simultáneamente y recupera los datos subsiguientes en segundo plano. La caché de datos se encuentra en cada rango que requiere datos de entrenamiento y mantiene dos tipos de lotes: los lotes consumidos recientemente que se han utilizado para el entrenamiento y los lotes precargados listos para su uso inmediato.
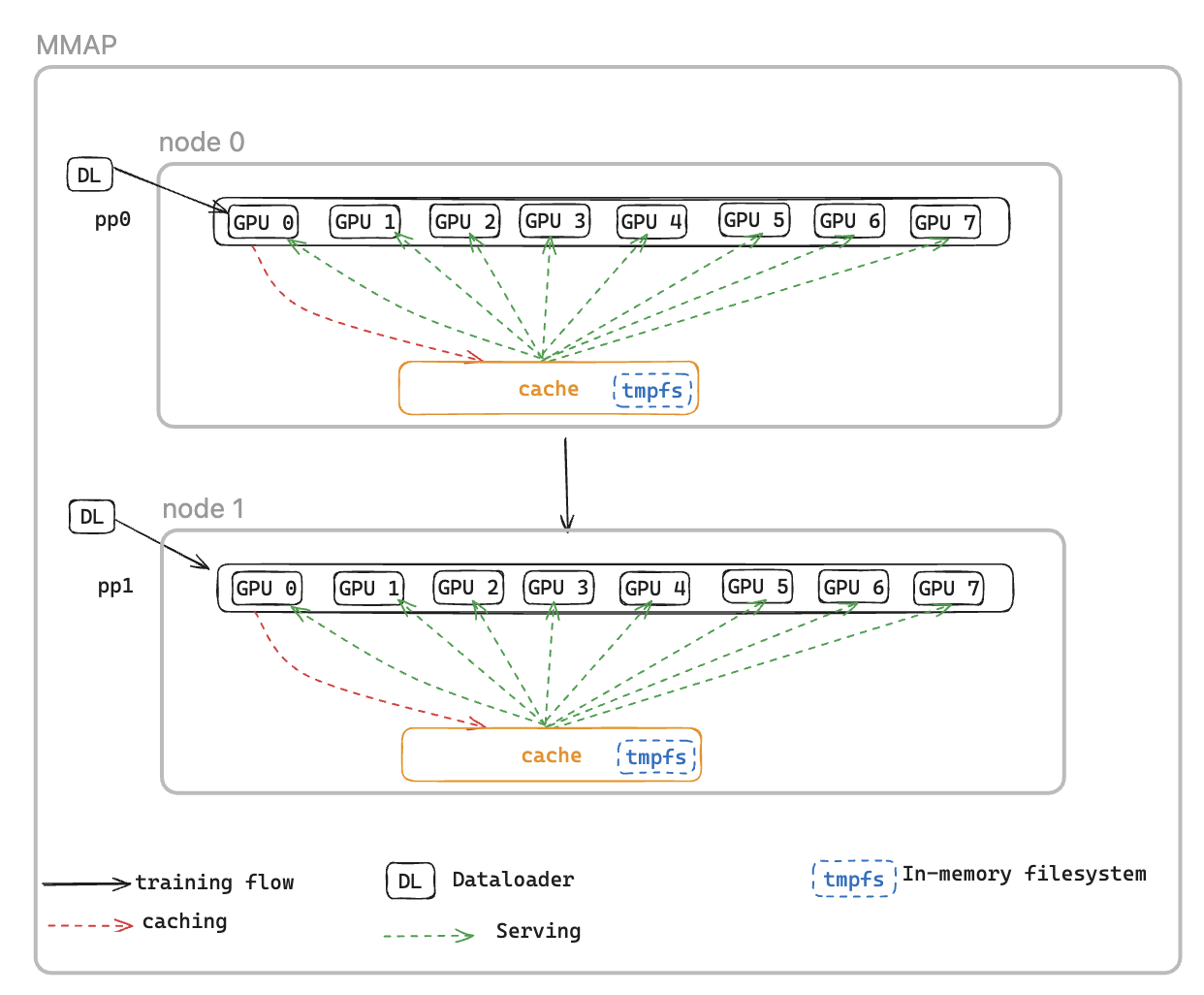
El cargador de datos MMAP ofrece las dos funciones siguientes:
Obtención previa de datos: recupera y almacena en caché de forma proactiva los datos generados por el cargador de datos
Almacenamiento en caché persistente: almacena los lotes consumidos y precargados en un sistema de archivos temporal que sobrevive a los reinicios del proceso
Al utilizar la memoria caché, el trabajo de formación se beneficiará de:
Menor consumo de memoria: aprovecha la memoria mapeada I/O para mantener una única copia compartida de los datos en la memoria de la CPU del host, lo que elimina las copias redundantes en los procesos de la GPU (por ejemplo, reduce de 8 copias a 1 en una instancia p5 con 8 GPU)
Recuperación más rápida: reduce el tiempo medio de reinicio (MTTR) al permitir que la formación se reanude inmediatamente a partir de los lotes almacenados en caché, lo que elimina la espera a que se reinicialice el cargador de datos y se genere el primer lote
Configuraciones MMAP
Para usar MMAP, simplemente pase el módulo de datos original a MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: Los parámetros del cargador de datos MMAP controlan la ubicación del directorio de la memoria caché, los límites de tamaño y la delegación de captura de datos. De forma predeterminada, solo el TP de rango 0 por nodo recupera los datos de la fuente, mientras que los demás clasificados en el mismo grupo de replicación de datos leen desde la caché compartida, lo que elimina las transferencias redundantes.
MMAPDataModule: Envuelve el módulo de datos original y devuelve el cargador de datos mmap para su procesamiento y validación.
Consulte el ejemplo
Referencia de la API
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Clase de configuración para la funcionalidad del cargador de datos mapeado en memoria caché (MMAP) en un entrenamiento sin puntos de control. HyperPod
Esta configuración permite una carga de datos eficiente con capacidades de almacenamiento en caché y recuperación previa, lo que permite reanudar el entrenamiento rápidamente después de los fallos al mantener los lotes de datos en caché en archivos mapeados en memoria.
Parámetros
-
cache_dir (str, opcional): ruta de directorio para almacenar lotes de datos en caché. Predeterminado: «//pdl_cache» dev/shm
-
prefetch_length (int, opcional): número de lotes que se deben cargar previamente durante el entrenamiento. Valor predeterminado: 10
-
val_prefetch_length (int, opcional): número de lotes que se van a recuperar previamente durante la validación. Valor predeterminado: 10
-
lookback_length (int, opcional): número de lotes utilizados anteriormente que se deben guardar en la caché para su posible reutilización. Valor predeterminado: 2
-
checkpoint_frequency (int, opcional): frecuencia de los pasos de los puntos de control del modelo. Se utiliza para optimizar el rendimiento de la memoria caché. Valor predeterminado: none
-
model_parallel_group (objeto, opcional): grupo de procesos para el paralelismo de modelos. Si es Ninguno, se creará automáticamente. Valor predeterminado: none
-
enable_batch_encryption (bool, opcional): indica si se debe habilitar el cifrado de los datos por lotes almacenados en caché. Valor predeterminado: False
Métodos
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Crea y devuelve una instancia de cargador de datos MMAP configurada.
Parámetros
-
dataloader_init_callable (Callable): función para inicializar el cargador de datos subyacente
-
parallel_state_util (object): utilidad para administrar el estado paralelo en todos los procesos
-
step (int): el paso de datos desde el que continuar durante el entrenamiento
-
is_data_loading_rank (Callable): función que devuelve True si el rango actual debe cargar datos
-
create_model_parallel_group_callable (Callable): función para crear un modelo de grupo de procesos paralelos
-
name (str, opcional): identificador de nombre para el cargador de datos. Predeterminado: «Tren»
-
is_val (bool, opcional): indica si se trata de un cargador de datos de validación. Valor predeterminado: False
-
cached_len (int, opcional): longitud de los datos en caché si se reanudan desde la caché existente. Predeterminado: 0
Devuelve CacheResumePrefetchedDataLoader oCacheResumeReadDataLoader: instancia de cargador de datos MMAP configurada
Se genera ValueError si el parámetro de paso es. None
Ejemplo
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Notas
-
El directorio de caché debe tener suficiente espacio y un I/O rendimiento rápido (por ejemplo,/dev/shm para el almacenamiento en memoria).
-
La configuración
checkpoint_frequencymejora el rendimiento de la caché al alinear la administración de la caché con los puntos de control del modelo -
Para los dataloaders de validación (
is_val=True), el paso se restablece en 0 y se fuerza el arranque en frío -
Se utilizan diferentes implementaciones de cargadores de datos en función de si el rango actual es responsable de la carga de datos
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
Un DataModule contenedor PyTorch Lightning que aplica las capacidades de carga de datos mapeados en memoria (MMAP) a las existentes para un entrenamiento sin puntos de control. DataModules
Esta clase combina un PyTorch Lightning existente DataModule y lo mejora con la funcionalidad MMAP, lo que permite un almacenamiento eficiente de los datos en caché y una recuperación rápida en caso de errores de entrenamiento. Mantiene la compatibilidad con la DataModule interfaz original y, al mismo tiempo, añade capacidades de entrenamiento sin puntos de control.
Parameters
- data_module (pl. LightningDataModule)
El subyacente DataModule a envolver (por ejemplo, LLMDataModule)
- mmap_config (mMapConfig)
El objeto de configuración del MMAP que define el comportamiento y los parámetros del almacenamiento en caché
parallel_state_util(MegatronParallelStateUtil, opcional)Utilidad para gestionar el estado paralelo en los procesos distribuidos. Predeterminado: MegatronParallelStateUtil ()
is_data_loading_rank(Se puede llamar, opcional)Función que devuelve True si el rango actual debe cargar datos. Si es None, el valor predeterminado es parallel_state_util.is_tp_0. Valor predeterminado: none
Atributos
global_step(int)Paso de formación global actual, que se utiliza para reanudar el entrenamiento desde los puntos de control
cached_train_dl_len(int)Longitud almacenada en caché del cargador de datos de entrenamiento
cached_val_dl_len(int)Longitud en caché del cargador de datos de validación
Métodos
setup(stage=None)
Configure el módulo de datos subyacente para la etapa de entrenamiento especificada.
stage(str, opcional)Etapa del entrenamiento («ajustar», «validar», «probar» o «predecir»). Valor predeterminado: none
train_dataloader()
Cree el entrenamiento DataLoader con el empaquetado MMAP.
Devoluciones: DataLoader — MMAP-wrapped entrenamiento DataLoader con capacidades de almacenamiento en caché y precarga
val_dataloader()
Cree la validación DataLoader con el empaquetado MMAP.
Devuelve: DataLoader — MMAP-wrapped validación DataLoader con capacidades de almacenamiento en caché
test_dataloader()
Cree la prueba DataLoader si el módulo de datos subyacente la admite.
Devuelve: DataLoader o Ninguno: prueba DataLoader desde el módulo de datos subyacente, o Ninguno si no se admite
predict_dataloader()
Cree la predicción DataLoader si el módulo de datos subyacente la admite.
Devuelve: DataLoader o ninguno: predice DataLoader a partir del módulo de datos subyacente, o ninguno si no se admite
load_checkpoint(checkpoint)
Carga la información de los puntos de control para reanudar el entrenamiento a partir de un paso específico.
- punto de control (dict)
Diccionario de puntos de control que contiene la clave 'global_step'
get_underlying_data_module()
Obtenga el módulo de datos empaquetado subyacente.
Devoluciones: pl. LightningDataModule — El módulo de datos original que estaba empaquetado
state_dict()
Obtenga el diccionario de estados del MMAP DataModule para los puntos de control.
Devuelve: dict — Diccionario que contiene las longitudes de los cargadores de datos en caché
load_state_dict(state_dict)
Cargue el diccionario de estados para restaurar el estado del MMAP. DataModule
state_dict(dictado)Diccionario estatal para cargar
Propiedades
data_sampler
Exponga el muestreador de datos del módulo de datos subyacente al NeMo marco.
Devuelve: objeto o ninguno: el muestreador de datos del módulo de datos subyacente
Ejemplo
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Notas
El contenedor delega la mayoría del acceso a los atributos al módulo de datos subyacente mediante __getattr__
Solo los rangos de carga de datos realmente inicializan y usan el módulo de datos subyacente; otros rangos usan cargadores de datos falsos
Las longitudes de los cargadores de datos en caché se mantienen para optimizar el rendimiento durante la reanudación del entrenamiento
