Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
In-process entrenamiento de recuperación y sin puntos de control
HyperPod la formación sin puntos de control utiliza la redundancia de modelos para permitir una formación tolerante a los fallos. El principio fundamental es que los estados del modelo y del optimizador se replican completamente en varios grupos de nodos, y las actualizaciones de peso y los cambios de estado del optimizador se replican de forma sincrónica dentro de cada grupo. Cuando se produce un error, las réplicas en buen estado completan sus pasos de optimización y transmiten los estados actualizados a las réplicas en recuperación. model/optimizer
Este modelo de enfoque basado en la redundancia permite varios mecanismos de gestión de errores:
-
In-process recuperación: los procesos permanecen activos a pesar de las fallas y mantienen todos los estados del modelo y del optimizador en la memoria de la GPU con los valores más recientes
-
Gestión eficiente de las interrupciones: cancelaciones controladas y limpieza de recursos para las operaciones afectadas
-
Reejecución de bloques de código: se vuelven a ejecutar solo los segmentos de código afectados dentro de un bloque de código (RCB) Re-executable
-
Recuperación sin puntos de control sin pérdida del progreso del entrenamiento: dado que los procesos persisten y los estados permanecen en la memoria, no se pierde ningún progreso del entrenamiento; cuando ocurre un error, el entrenamiento se reanuda desde el paso anterior, en lugar de reanudarse desde el último punto de control guardado
Configuraciones sin puntos de control
Este es el fragmento principal del entrenamiento sin puntos de control.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Todos los rangos esperarán la información de clasificación de la infraestructura. HyperpodTrainingOperatorHPWrapper: contenedor de funciones de Python que habilita las capacidades de reinicio de un bloque Re-executable de código (RCB). La implementación utiliza un administrador de contexto en lugar de un decorador de Python porque los decoradores no pueden determinar la cantidad de RCB que se deben monitorear en tiempo de ejecución.CudaHealthCheck: Garantiza que el contexto CUDA del proceso actual se encuentre en buen estado mediante la sincronización con la GPU. Utiliza el dispositivo especificado por la variable de entorno LOCAL_RANK o, de forma predeterminada, es el dispositivo CUDA del hilo principal si LOCAL_RANK no está configurado.HPAgentK8sAPIFactory: Esta API permite realizar un entrenamiento sin puntos de control para consultar el estado del entrenamiento de otros pods del clúster de entrenamiento de Kubernetes. También proporciona una barrera a nivel de infraestructura que garantiza que todos los rangos completen correctamente las operaciones de abortación y reinicio antes de continuar.CheckpointManager: Gestiona los puntos de control en memoria y la recuperación punto a punto para lograr una tolerancia a los fallos sin puntos de control. Tiene las siguientes responsabilidades principales:In-Memory Administración de puntos de control: guarda y administra los puntos de control NeMo del modelo en la memoria para una recuperación rápida sin disco en situaciones de recuperación sin I/O puntos de control.
Validación de la viabilidad de la recuperación: determina si es posible realizar una recuperación sin puntos de control mediante la validación de la coherencia global de los pasos, el estado de las clasificaciones y la integridad del estado del modelo.
Peer-to-Peer Organización de la recuperación: coordina la transferencia de puntos de control entre los rangos en buen estado y los que no funcionan mediante una comunicación distribuida para una recuperación rápida.
Gestión del estado de RNG: conserva y restaura los estados de los generadores de números aleatorios en Python, NumPy PyTorch, y Megatron para una recuperación determinista.
[Opcional] Descarga del punto de control: descarga el punto de control de la memoria a la CPU si la GPU no tiene suficiente capacidad de memoria.
PEFTCheckpointManager: Se amplíaCheckpointManagermanteniendo los pesos del modelo base para ajustar el PEFT.CheckpointlessAbortManager: gestiona las operaciones de anulación en un subproceso en segundo plano cuando se produce un error. De forma predeterminada, anula TransformerEngine, Checkpoints y TorchDistributed. DataLoader Los usuarios pueden registrar controladores de cancelación personalizados según sea necesario. Una vez finalizada la interrupción, todas las comunicaciones deben cesar y todos los procesos e hilos deben terminar para evitar la pérdida de recursos.CheckpointlessFinalizeCleanup: gestiona las operaciones de limpieza final en el subproceso principal para los componentes que no pueden abortarse o limpiarse de forma segura en el subproceso de fondo.CheckpointlessMegatronStrategy: Esto se hereda de NemoMegatronStrategy. Tenga en cuenta que el entrenamiento sin puntos de control debe ser de al menos 2 personasnum_distributed_optimizer_instancespara que la replicación sea optimizada. La estrategia también se ocupa del registro de los atributos esenciales y de la inicialización de los grupos de procesos, por ejemplo, sin root.CheckpointlessCallback: Lightning Callback, que integra la NeMo formación con el sistema de tolerancia a fallos de Checkpointless Training. Tiene las siguientes responsabilidades principales:Gestión del ciclo de vida de las etapas de formación: realiza un seguimiento del progreso de la formación y coordina con ParameterUpdateLock ella una recuperación enable/disable sin puntos de control en función del estado de la formación (primer paso o pasos posteriores).
Coordinación del estado del punto de control: gestiona el punto de control del modelo base PEFT integrado en la memoria. saving/restoring
CheckpointlessCompatibleConnector: Un PTLCheckpointConnectorque intenta cargar previamente el archivo del punto de control en la memoria, con la ruta de origen determinada en esta prioridad:pruebe la recuperación sin puntos de control
si checkpointless devuelve None, recurra a parent.resume_start ()
Consulta el ejemplo para añadir funciones de entrenamiento sin puntos de control a los códigos
Conceptos
En esta sección se presentan los conceptos de entrenamiento sin puntos de control. La formación de Checkpointless en Amazon SageMaker HyperPod apoya la recuperación durante el proceso. Esta interfaz de API sigue un formato similar al de las API de NVRx.
Concepto: bloque Re-Executable de código (RCB)
Cuando se produce un error, los procesos en buen estado permanecen activos, pero se debe volver a ejecutar una parte del código para recuperar los estados de entrenamiento y las pilas de Python. Un bloque Re-executable de código (RCB) es un segmento de código específico que se vuelve a ejecutar durante la recuperación de errores. En el siguiente ejemplo, el RCB abarca todo el guion de entrenamiento (es decir, todo lo que aparece debajo de main ()), lo que significa que cada recuperación ante un fallo reinicia el guion de entrenamiento y, al mismo tiempo, conserva el modelo en memoria y los estados del optimizador.
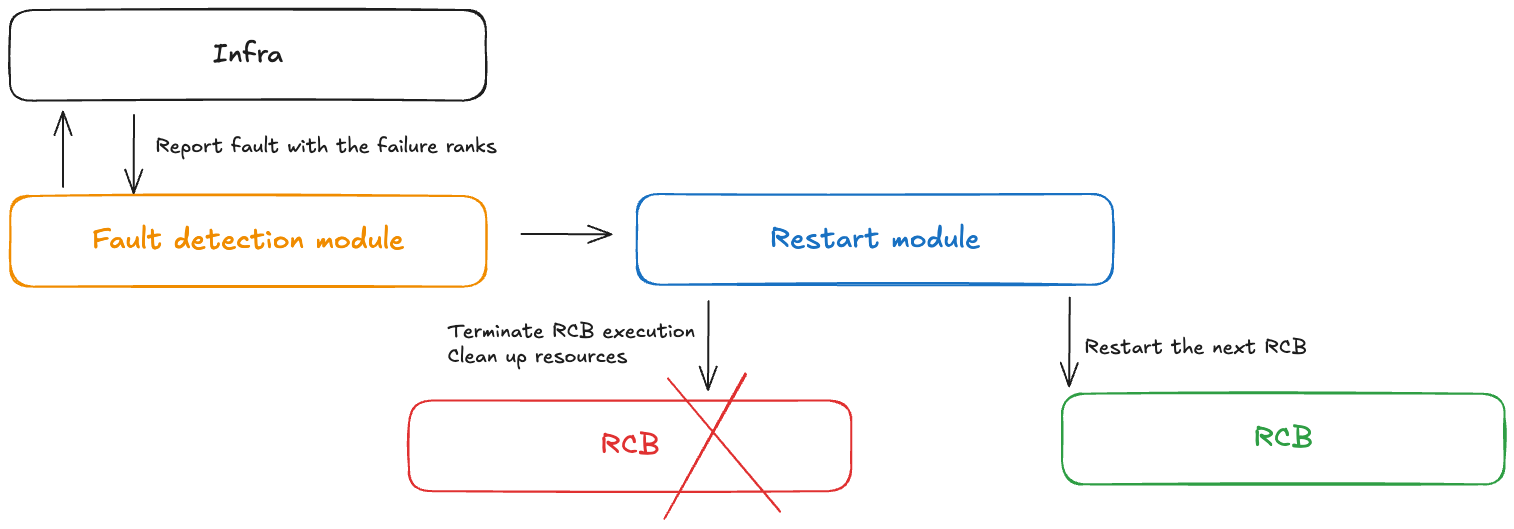
Concepto: control de fallos
Un módulo controlador de fallas recibe notificaciones cuando se producen fallas durante un entrenamiento sin puntos de control. Este controlador de fallas incluye los siguientes componentes:
Módulo de detección de fallas: recibe notificaciones de fallas en la infraestructura
API de definición de RCB: permiten a los usuarios definir el bloque de códigos reejecutable (RCB) en su código
Módulo de reinicio: finaliza el RCB, limpia los recursos y reinicia el RCB
Concepto: modelo de redundancia
El entrenamiento de modelos grandes generalmente requiere un tamaño paralelo de datos lo suficientemente grande como para entrenar modelos de manera eficiente. En el paralelismo de datos tradicional, como el PyTorch DDP y el Horovod, el modelo se replica completamente. Las técnicas de paralelismo de datos fragmentados más avanzadas, como el optimizador ZeRO y el FSDP DeepSpeed , también admiten el modo de fragmentación híbrida, que permite fragmentar los estados del grupo de fragmentación y replicarlos completamente entre los grupos de replicación. model/optimizer NeMo también tiene esta función de fragmentación híbrida mediante un argumento num_distributed_optimizer_instances, que permite la redundancia.
Sin embargo, añadir redundancia indica que el modelo no estará completamente fragmentado en todo el clúster, lo que se traducirá en un mayor uso de la memoria del dispositivo. La cantidad de memoria redundante variará en función de las técnicas específicas de fragmentación del modelo implementadas por el usuario. Los pesos, los gradientes y la memoria de activación del modelo de baja precisión no se verán afectados, ya que se fragmentan mediante el paralelismo del modelo. Los estados del optimizador y del modelo weights/gradients maestro de alta precisión se verán afectados. La adición de una réplica de modelo redundante aumenta el uso de memoria del dispositivo aproximadamente el equivalente al tamaño de un punto de control de DCP.
La fragmentación híbrida divide los colectivos de todos los grupos de DP en colectivos relativamente más pequeños. Anteriormente, había una dispersión reducida y una dispersión total en todo el grupo de DP. Tras la fragmentación híbrida, la dispersión reducida solo se ejecutará dentro de cada réplica del modelo y habrá una reducción total en todos los grupos de réplicas del modelo. La función «all-gather» también se ejecuta dentro de cada réplica del modelo. Como resultado, todo el volumen de comunicación permanece prácticamente sin cambios, pero los colectivos funcionan con grupos más pequeños, por lo que esperamos una mejor latencia.
Concepto: tipos de errores y reinicios
La siguiente tabla registra los diferentes tipos de errores y los mecanismos de recuperación asociados. El entrenamiento sin control intenta primero la recuperación de los errores mediante una recuperación en proceso, seguida de un reinicio a nivel del proceso. Solo se recurre a un reinicio a nivel de trabajo en caso de una falla catastrófica (por ejemplo, si varios nodos fallan al mismo tiempo).
| Tipo de fallo | Causa | Tipo de recuperación | Mecanismo de recuperación |
|---|---|---|---|
| In-process fallo | Code-level errores, excepciones | In-Process Recuperación (IPR) | Vuelva a ejecutar RCB dentro del proceso existente; los procesos en buen estado permanecen activos |
| Error al reiniciar el proceso | Contexto CUDA dañado, proceso finalizado | Reinicio a nivel de proceso (PLR) | SageMaker HyperPod el operador de entrenamiento reinicia los procesos; omite el reinicio del módulo K8 |
| Fallo al reemplazar el nodo | Fallo node/GPU de hardware permanente | Reinicio a nivel de trabajo (JLR) | Reemplace el nodo fallido; reinicie todo el trabajo de entrenamiento |
Concepto: protección de bloqueo atómico para optimizar el paso
La ejecución del modelo se divide en tres fases: propagación hacia adelante, propagación hacia atrás y paso de optimización. El comportamiento de recuperación varía en función del momento de la falla:
Forward/backward propagación: retroceda al principio del paso de entrenamiento actual y transmita los estados del modelo a los nodos de reemplazo
Paso de optimización: permita que las réplicas en buen estado completen el paso con protección mediante bloqueo y, a continuación, transmita los estados actualizados del modelo a los nodos de reemplazo
Esta estrategia garantiza que las actualizaciones completadas del optimizador nunca se descarten, lo que ayuda a reducir el tiempo de recuperación ante fallos.
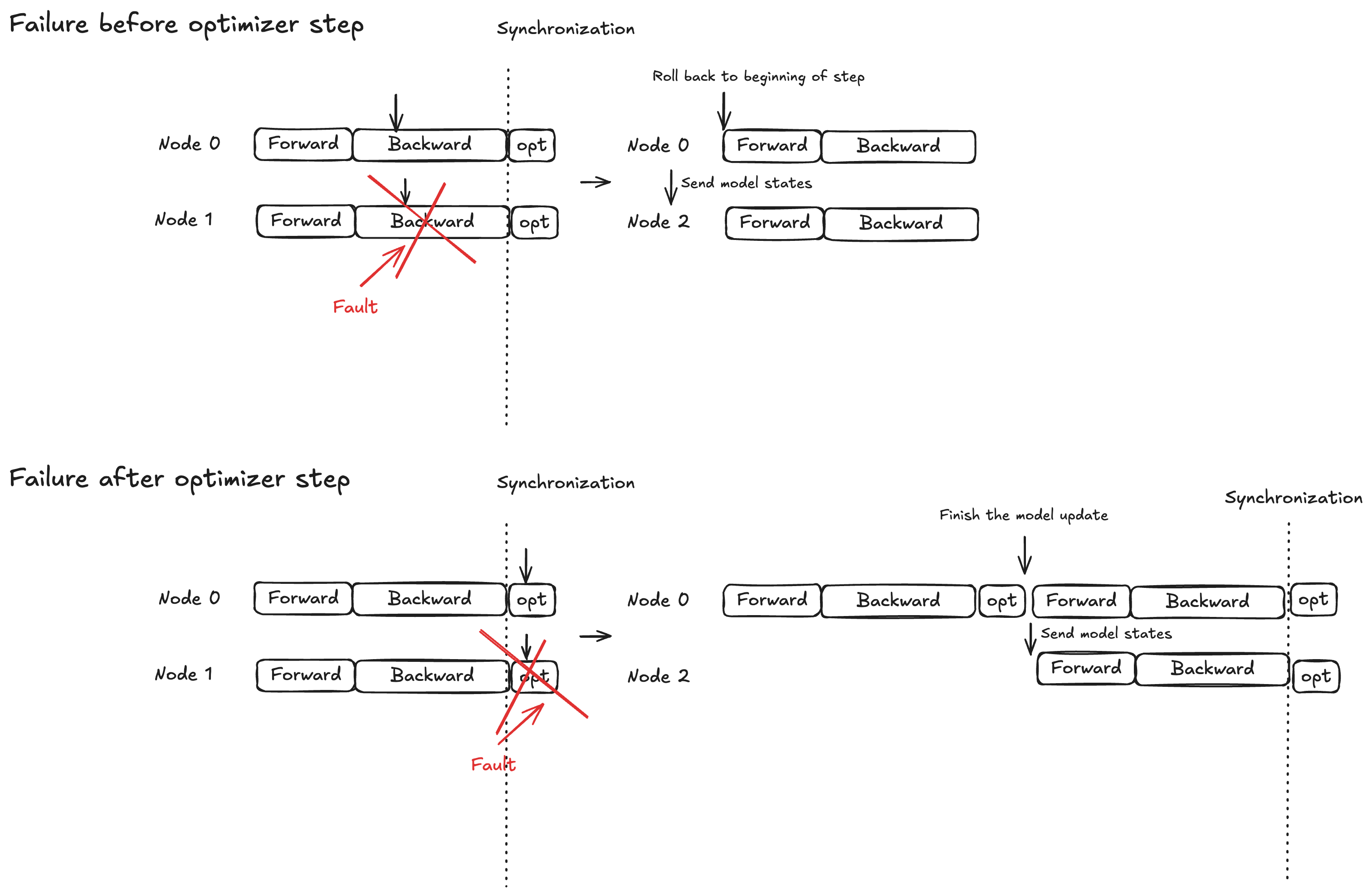
Diagrama de flujo de entrenamiento sin puntos de control
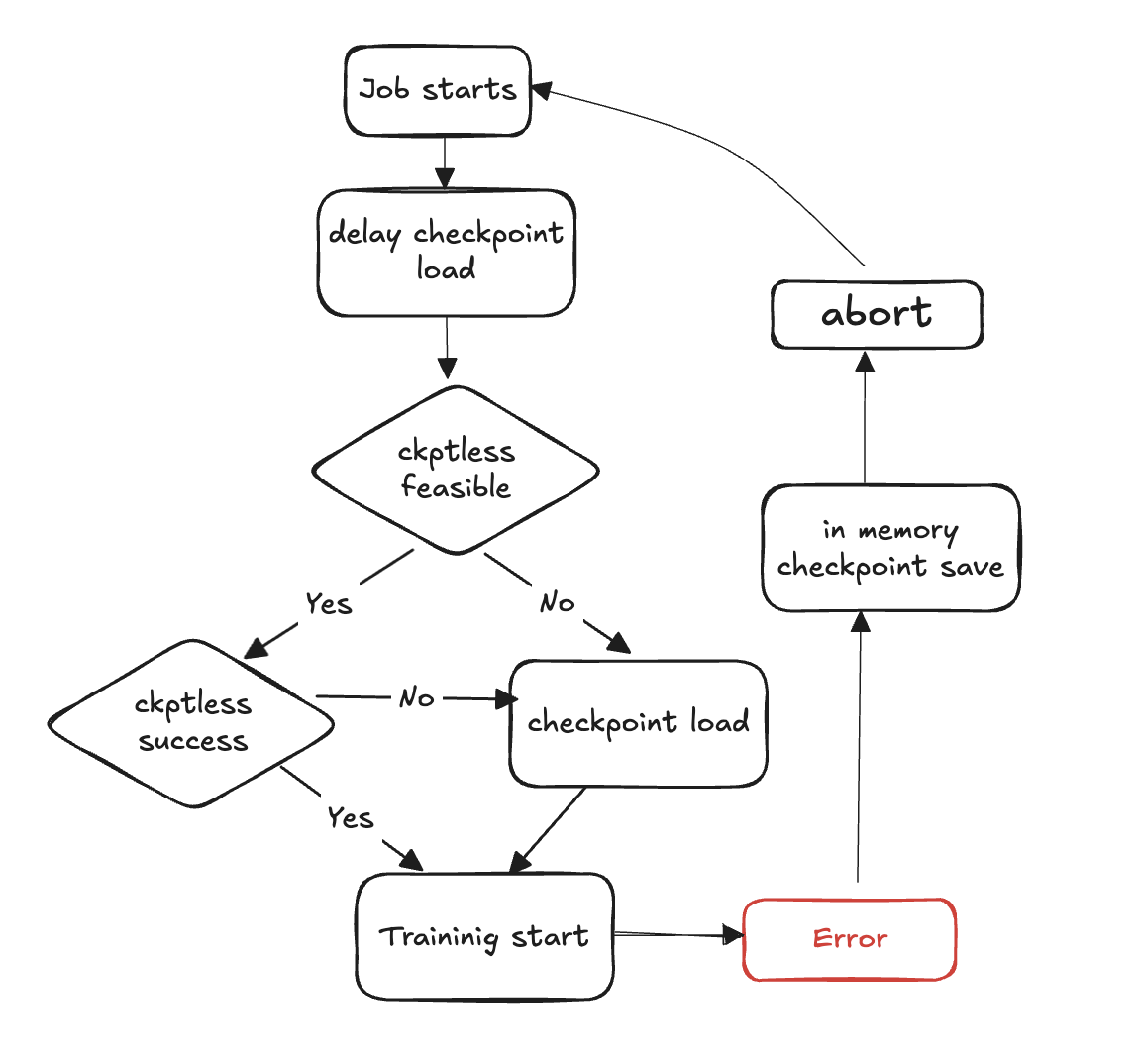
Los siguientes pasos describen el proceso de detección de fallas y recuperación sin puntos de control:
Comienza el ciclo de entrenamiento
Se produce una falla
Evalúe la viabilidad de un currículum sin puntos de control
Compruebe si es posible hacer un currículum sin puntos de control
Si es posible, intente reanudar sin puntos de control
Si la reanudación falla, recurra al punto de control para cargar desde el almacenamiento
Si la reanudación se realiza correctamente, el entrenamiento continúa desde el estado recuperado
Si no es posible, recurra al punto de control para cargar desde el almacén
Limpie los recursos: cancele todos los grupos de procesos y los backends y libere recursos para prepararlos para el reinicio.
Reanudar el ciclo de entrenamiento: comienza un nuevo ciclo de entrenamiento y el proceso vuelve al paso 1.
Referencia de la API
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Espera y recupera la información de clasificación y, a continuación HyperPod, actualiza el entorno de proceso actual con variables de entrenamiento distribuidas.
Esta función obtiene la asignación de rangos y las variables de entorno correctas para el entrenamiento distribuido. Garantiza que cada proceso tenga la configuración adecuada para su función en el trabajo de formación distribuido.
Parámetros
Ninguno
Devuelve
Ninguna
Comportamiento
Verificación del proceso: omite la ejecución si se llama desde un subproceso (solo se ejecuta en él) MainProcess
Recuperación del entorno: obtiene la información actual
RANKyWORLD_SIZEprocedente de las variables de entornoHyperPod Comunicación: llamadas
hyperpod_wait_rank_info()para recuperar información de clasificación de HyperPodActualización del entorno: actualiza el entorno de proceso actual con las variables de entorno específicas del trabajador recibidas de HyperPod
Variables de entorno
La función lee las siguientes variables de entorno:
RANK (int): rango del proceso actual (predeterminado: -1 si no está establecido)
WORLD_SIZE (int): número total de procesos en el trabajo distribuido (predeterminado: 0 si no está establecido)
Aumenta
AssertionError— Si la respuesta de no HyperPod tiene el formato esperado o si faltan los campos obligatorios
Ejemplo
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Notas
Solo se ejecuta en el proceso principal; las llamadas al subproceso se omiten automáticamente
La función se bloquea hasta que HyperPod proporcione la información de clasificación
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Contenedor de funciones de Python que permite reiniciar un bloque de Re-executable código (RCB) en un entrenamiento sin puntos de HyperPod control.
Este contenedor proporciona capacidades de tolerancia a fallas y recuperación automática al monitorear la ejecución de la capacitación y coordinar los reinicios en todos los procesos distribuidos cuando se producen fallas. Utiliza un enfoque de administrador de contexto en lugar de un decorador para mantener los recursos globales durante todo el ciclo de vida de la formación.
Parámetros
abortar (abortar, opcional): aborta la ejecución de forma asíncrona cuando se detectan errores. Valor predeterminado:
Compose(HPAbortTorchDistributed())finalizar (Finalizar, opcional): finaliza el controlador ejecutado durante el reinicio. Rank-local Valor predeterminado:
Nonehealth_check (HealthCheck, opcional): Rank-local comprobación de estado ejecutada durante el reinicio. Valor predeterminado:
Nonehp_api_factory (invocable, opcional): función de fábrica para crear una API con la que interactuar. HyperPod HyperPod Valor predeterminado:
Noneabort_timeout (flotante, opcional): tiempo de espera para abortar una llamada en un hilo de control de errores. Valor predeterminado:
Nonehabilitado (bool, opcional): habilita la funcionalidad de contenedor. Cuando
False, el envoltorio se convierte en un elemento de paso. Valor predeterminado:Truetrace_file_path (str, opcional): ruta al archivo de rastreo para la creación de perfiles. VizTracer Valor predeterminado:
Noneasync_raise_before_abort (bool, opcional): habilita la activación antes de la interrupción en el subproceso de control de errores. Valor predeterminado:
Trueearly_abort_communicator (bool, opcional): anula el communicator () antes de anular el cargador de datos. NCCL/Gloo Valor predeterminado:
Falsecheckpoint_manager (cualquiera, opcional): administrador para gestionar los puntos de control durante la recuperación. Valor predeterminado:
Nonecheck_memory_status (bool, opcional): habilita la verificación y el registro del estado de la memoria. Valor predeterminado:
True
Métodos
def __call__(self, fn)
Incluye una función para habilitar las capacidades de reinicio.
Parámetros:
fn (Callable): la función que se incluye con capacidades de reinicio
Devoluciones:
Llamable: función empaquetada con capacidad de reinicio o función original si está deshabilitada
Ejemplo
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Notas
El envoltorio debe
torch.distributedestar disponibleCuando
enabled=False, el contenedor se convierte en un elemento de transferencia y devuelve la función original sin cambiosEl contenedor mantiene los recursos globales, como la supervisión de los hilos a lo largo del ciclo de vida de la formación
Soporta la VizTracer creación de perfiles cuando se proporciona
trace_file_pathSe integra con una HyperPod formación distribuida para una gestión coordinada de las averías
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Supervisa y gestiona el estado de un bloque de código de reinicio (RCB) durante la ejecución.
Esta clase se ocupa del ciclo de vida de la ejecución del RCB, incluida la detección de errores, la coordinación con otros niveles para los reinicios y las operaciones de limpieza. Gestiona la sincronización distribuida y garantiza una recuperación uniforme en todos los procesos de formación.
Parámetros
contenedor (HPWrapper): el contenedor principal que contiene la configuración global de recuperación durante el proceso
Atributos
step_upon_restart (int): contador que registra los pasos transcurridos desde el último reinicio y se utiliza para determinar la estrategia de reinicio
Métodos
def initialize_barrier()
Espere a que se sincronice HyperPod la barrera después de encontrar una excepción del RCB.
def start_hp_fault_handling_thread()
Inicie el hilo de gestión de fallos para supervisar y coordinar los fallos.
def handle_fn_exception(call_ex)
Procese las excepciones de la función de ejecución o del RCB.
Parámetros:
call_ex (Excepción): excepción de la función de supervisión
def restart(term_ex)
Ejecute el controlador de reinicios, incluida la finalización, la recolección de elementos no utilizados y las comprobaciones de estado.
Parámetros:
term_ex (RankShouldRestart): excepción de terminación que desencadena el reinicio
def launch(fn, *a, **kw)
Ejecute el RCB con el manejo adecuado de las excepciones.
Parámetros:
fn (Callable): función que se va a ejecutar
a — Argumentos de la función
kw — Argumentos de palabras clave de funciones
def run(fn, a, kw)
Bucle de ejecución principal que gestiona los reinicios y la sincronización de barreras.
Parámetros:
fn (Callable): función que se va a ejecutar
a — Argumentos de la función
kw — Argumentos de palabras clave de funciones
def shutdown()
Cierre los subprocesos de gestión y supervisión de errores.
Notas
Gestiona automáticamente
RankShouldRestartlas excepciones para una recuperación coordinadaGestiona el seguimiento de la memoria y anula la recolección de basura durante los reinicios
Soporta estrategias de recuperación durante el proceso y PLR (Process-Level reinicio) basadas en la temporización de los fallos
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Garantiza que el contexto CUDA del proceso actual se encuentre en buen estado durante la recuperación del entrenamiento sin puntos de control.
Esta comprobación de estado se sincroniza con la GPU para comprobar que el contexto CUDA no está dañado tras un error de entrenamiento. Realiza operaciones de sincronización de la GPU para detectar cualquier problema que pueda impedir la reanudación correcta del entrenamiento. La comprobación de estado se ejecuta una vez que se destruyen los grupos distribuidos y se ha completado la finalización.
Parámetros
timeout (datetime.timedelta, opcional): tiempo de espera para las operaciones de sincronización de la GPU. Valor predeterminado:
datetime.timedelta(seconds=30)
Métodos
__call__(state, train_ex=None)
Ejecute la comprobación de estado de CUDA para comprobar la integridad del contexto de la GPU.
Parámetros:
state (HPState): HyperPod estado actual que contiene información distribuida y de clasificación
train_ex (excepción, opcional): la excepción de entrenamiento original que provocó el reinicio. Valor predeterminado:
None
Devuelve:
tupla: una tupla que se contiene
(state, train_ex)sin cambios si se aprueba el chequeo de estado
Aumenta:
TimeoutError— Si se agota el tiempo de espera de la sincronización de la GPU, lo que indica un contexto CUDA potencialmente dañado
Preservación del estado: devuelve el estado original y la excepción sin cambios si se aprueban todas las comprobaciones
Ejemplo
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Notas
Utiliza subprocesos para implementar la protección de tiempo de espera para la sincronización de la GPU
Diseñado para detectar contextos CUDA corruptos que podrían impedir la reanudación correcta del entrenamiento
Debe usarse como parte del proceso de tolerancia a errores en escenarios de entrenamiento distribuidos
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Clase de fábrica para crear instancias de HPAgentK8SAPI que se comuniquen con HyperPod la infraestructura para la coordinación distribuida de la formación.
Esta fábrica proporciona una forma estandarizada de crear y configurar los objetos HPAgentK8SAPI que gestionan la comunicación entre los procesos de entrenamiento y el plano de control. HyperPod Encapsula la creación del cliente de socket y la instancia de API subyacentes, lo que garantiza una configuración uniforme en las diferentes partes del sistema de entrenamiento.
Métodos
__call__()
Crea y devuelve una instancia HPAgentK8SAPI configurada para la comunicación. HyperPod
Devoluciones:
HPAgentK8SAPI: instancia de API configurada para comunicarse con la infraestructura HyperPod
Ejemplo
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Notas
Diseñada para funcionar a la perfección con la infraestructura. HyperPod Kubernetes-based Es esencial para la gestión y la recuperación coordinadas de los fallos en escenarios de formación distribuidos
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Gestiona los puntos de control en memoria y la recuperación entre pares para lograr una tolerancia a los fallos sin puntos de control en la formación distribuida.
Esta clase proporciona la funcionalidad básica para el entrenamiento HyperPod sin puntos de control, ya que permite gestionar los puntos de control de los NeMo modelos en la memoria, validar la viabilidad de la recuperación y organizar la transferencia de puntos de control entre pares entre los rangos en buen estado y los que han fallado. Elimina la necesidad de disponer de disco I/O durante la recuperación, lo que reduce considerablemente el tiempo medio de recuperación (MTTR).
Parámetros
enable_checksum (bool, opcional): habilita la validación de la suma de verificación del estado del modelo para las comprobaciones de integridad durante la recuperación. Valor predeterminado:
Falseenable_offload (bool, opcional): habilita la descarga de puntos de control de la GPU a la memoria de la CPU para reducir el uso de memoria de la GPU. Valor predeterminado:
False
Atributos
global_step (int o None): paso de entrenamiento actual asociado al punto de control guardado
rng_states (list o None): estados del generador de números aleatorios almacenados para una recuperación determinista
checksum_manager (MemoryChecksumManager): administrador para la validación de la suma de verificación del estado del modelo
parameter_update_lock (): bloqueo para coordinar las actualizaciones de los parámetros durante la recuperación ParameterUpdateLock
Métodos
save_checkpoint(trainer)
Guarda el punto de control NeMo del modelo en la memoria para una posible recuperación sin puntos de control.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Notas:
Se llama al final del lote o durante la gestión de excepciones CheckpointlessCallback
Crea puntos de recuperación sin I/O sobrecarga de disco
Almacena los estados completos del modelo, el optimizador y el planificador
delete_checkpoint()
Elimine el punto de control en la memoria y realice las operaciones de limpieza.
Notas:
Borra los datos de los puntos de control, los estados de RNG y los tensores almacenados en caché
Realiza la recolección de basura y la limpieza de la caché CUDA
Se llama después de una recuperación exitosa o cuando el punto de control ya no es necesario
try_checkpointless_load(trainer)
Intenta recuperarte sin puntos de control cargando el estado de los rangos de tus compañeros.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Devoluciones:
dict o None: se restaura el punto de control si es correcto, ninguno si es necesario recurrir al disco
Notas:
Punto de entrada principal para una recuperación sin puntos de control
Valida la viabilidad de la recuperación antes de intentar la transferencia P2P
Limpia siempre los puntos de control de la memoria tras un intento de recuperación
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Determine si es posible realizar una recuperación sin puntos de control en el escenario de fallo actual.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
include_checksum_verification (bool, opcional): si se debe incluir la validación de la suma de verificación . Valor predeterminado:
True
Devoluciones:
bool: Verdadero si es posible una recuperación sin puntos de control, falso en caso contrario
Criterios de validación:
Coherencia escalonada global en todos los rangos saludables
Hay suficientes réplicas en buen estado disponibles para la recuperación
Integridad de la suma de verificación del estado del modelo (si está habilitada)
store_rng_states()
Guarde todos los estados del generador de números aleatorios para una recuperación determinista.
Notas:
Captura los estados RNG de Python NumPy PyTorch CPU/GPU, y Megatron
Esencial para mantener el determinismo del entrenamiento después de la recuperación
load_rng_states()
Restaure todos los estados del RNG para continuar con la recuperación determinista.
Notas:
Restaura todos los estados de RNG previamente almacenados
Garantiza que el entrenamiento continúe con secuencias aleatorias idénticas
maybe_offload_checkpoint()
Si la descarga está habilitada, descargue el punto de control de la GPU a la memoria de la CPU.
Notas:
Reduce el uso de memoria de la GPU en modelos grandes
Solo se ejecuta si
enable_offload=TrueMantiene la accesibilidad de los puntos de control para la recuperación
Ejemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Validación: verifica la integridad de los puntos de control mediante sumas de control (si están habilitadas)
Notas
Utiliza primitivas de comunicación distribuidas para una transferencia P2P eficiente
Gestiona automáticamente las conversiones de tipo D del tensor y la ubicación de los dispositivos
MemoryChecksumManager— Maneja la validación de la integridad del estado del modelo
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Gestiona los puntos de control del PEFT (Parameter-Efficient Fine-Tuning) con un manejo independiente de la base y el adaptador para optimizar la recuperación sin puntos de control.
Este gestor de puntos de control especializado se amplía CheckpointManager para optimizar los flujos de trabajo del PEFT al separar los pesos del modelo base de los parámetros del adaptador.
Parámetros
Hereda todos los parámetros de: CheckpointManager
enable_checksum (bool, opcional): habilita la validación de la suma de verificación del estado del modelo. Valor predeterminado:
Falseenable_offload (bool, opcional): habilita la descarga de puntos de control a la memoria de la CPU. Valor predeterminado:
False
Atributos adicionales
params_to_save (set): conjunto de nombres de parámetros que deben guardarse como parámetros del adaptador
base_model_weights (dict or None): pesos del modelo base almacenados en caché, guardados una vez y reutilizados
base_model_keys_to_extract (list o None): claves para extraer los tensores del modelo base durante la transferencia P2P
Métodos
maybe_save_base_model(trainer)
Guarde los pesos del modelo base una vez, filtrando los parámetros del adaptador.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Notas:
Solo guarda los pesos del modelo base en la primera llamada; las llamadas posteriores no son operativas
Filtra los parámetros del adaptador para almacenar solo los pesos del modelo base congelados
Los pesos del modelo base se conservan durante varias sesiones de entrenamiento
save_checkpoint(trainer)
Guarde el punto de control del modelo del adaptador NeMo PEFT en la memoria para una posible recuperación sin puntos de control.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Notas:
Llama automáticamente si el modelo base aún no se ha guardado
maybe_save_base_model()Filtra el punto de control para incluir solo los parámetros del adaptador y el estado de entrenamiento
Reduce significativamente el tamaño de los puntos de control en comparación con los puntos de control del modelo completo
try_base_model_checkpointless_load(trainer)
El modelo base Tempt PEFT pondera la recuperación sin puntos de control cargando el estado de las filas homólogas.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Devoluciones:
dict or None: se restauró el punto de control del modelo base si fue correcto, ninguno si se necesitó una alternativa
Notas:
Se utiliza durante la inicialización del modelo para recuperar los pesos del modelo base
No limpia los pesos base del modelo después de la recuperación (los conserva para su reutilización)
Optimizado para escenarios de recuperación basados únicamente en los pesos del modelo
try_checkpointless_load(trainer)
El adaptador PEFT intenta sopesar la recuperación sin puntos de control cargando el estado de las filas homólogas.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Devoluciones:
dict o None: se restauró el punto de control del adaptador si fue correcto, ninguno si se necesitó una alternativa
Notas:
Recupera únicamente los parámetros del adaptador, los estados del optimizador y los planificadores
Carga automáticamente los estados del optimizador y el programador después de una recuperación exitosa
Limpia los puntos de control del adaptador tras un intento de recuperación
is_adapter_key(key)
Compruebe si la clave de dictado de estado pertenece a los parámetros del adaptador.
Parámetros:
key (str o tuple): clave de dictado de estado para comprobar
Devoluciones:
bool: verdadero si la clave es un parámetro del adaptador, falso si el parámetro del modelo base
Lógica de detección:
Comprueba si la clave está en el
params_to_savesetIdentifica las claves que contienen «.adapter». subcadena
Identifica las claves que terminan en «.adapter»
En el caso de las claves de tupla, comprueba si el parámetro requiere gradientes
maybe_offload_checkpoint()
Descarga los pesos del modelo base de la GPU a la memoria de la CPU.
Notas:
Amplía el método principal para gestionar la descarga del peso del modelo base
Los pesos de los adaptadores suelen ser pequeños y no requieren descarga
Establece un indicador interno para rastrear el estado de descarga
Notas
Diseñado específicamente para Parameter-Efficient Fine-Tuning escenarios (LoRa, adaptadores, etc.)
Gestiona automáticamente la separación de los parámetros del modelo base y del adaptador
Ejemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Clase de fábrica para crear y gestionar las composiciones de los componentes abortados para lograr una tolerancia a los fallos sin puntos de control.
Esta clase de utilidad proporciona métodos estáticos para crear, personalizar y gestionar las composiciones de los componentes abortados que se utilizan durante la gestión de fallos en una formación sin puntos de control. HyperPod Simplifica la configuración de las secuencias de cancelación que se encargan de limpiar los componentes de entrenamiento distribuidos, los cargadores de datos y los recursos específicos del marco durante la recuperación de errores.
Parámetros
Ninguno (todos los métodos son estáticos)
Métodos estáticos
get_default_checkpointless_abort()
Obtenga la instancia de composición de abortación predeterminada que contiene todos los componentes de cancelación estándar.
Devuelve:
Compose: instancia de cancelación compuesta por defecto con todos los componentes de cancelación
Componentes por defecto:
AbortTransformerEngine() — Limpia los recursos TransformerEngine
HPCheckpointingAbort() — Gestiona la limpieza del sistema de puntos de control
HPAbortTorchDistributed() — Aborta PyTorch las operaciones distribuidas
HPDataLoaderAbort() — Detiene y limpia los cargadores de datos
create_custom_abort(abort_instances)
Cree una composición de cancelación personalizada con solo las instancias de cancelación especificadas.
Parámetros:
abort_instances (Abort): número variable de instancias de anulación que se van a incluir en la composición
Devuelve:
Compose: nueva instancia de cancelación compuesta que contiene solo los componentes especificados
Aumenta:
ValueError— Si no se proporcionan instancias de aborto
override_abort(abort_compose, abort_type, new_abort)
Sustituye un componente de cancelación específico en una instancia de Compose por un componente nuevo.
Parámetros:
abort_compose (Compose): la instancia de Compose original que se va a modificar
abort_type (type): el tipo de componente de cancelación que se va a reemplazar (por ejemplo,)
HPCheckpointingAbortnew_abort (Abort): la nueva instancia de cancelación que se utilizará como reemplazo
Devuelve:
Compose: nueva instancia de Compose con el componente especificado reemplazado
Aumenta:
ValueError— Si abort_compose no tiene el atributo 'instances'
Ejemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Notas
Las configuraciones personalizadas permiten un control preciso del comportamiento de limpieza
Las operaciones de anulación son fundamentales para una limpieza adecuada de los recursos durante la recuperación de errores
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Realiza una limpieza exhaustiva tras la detección de un fallo para preparar la recuperación durante el proceso durante una formación sin puntos de control.
Este controlador de finalización ejecuta operaciones de limpieza específicas del marco, como la anulación, la limpieza del DDP, la recarga de módulos y la limpieza de Megatron/TransformerEngine memoria, destruyendo las referencias de los componentes de entrenamiento. Garantiza que el entorno de formación se restablezca correctamente para que la recuperación del proceso se lleve a cabo correctamente sin que sea necesaria la finalización completa del proceso.
Parámetros
Ninguno
Atributos
trainer (pytorch_lightning.trainer o None): referencia a la instancia de Lightning Trainer PyTorch
Métodos
__call__(*a, **kw)
Ejecute operaciones de limpieza exhaustivas para preparar la recuperación durante el proceso.
Parámetros:
a — Argumentos posicionales variables (heredados de la interfaz Finalize)
kw — Argumentos de palabras clave variables (heredados de la interfaz Finalize)
Operaciones de limpieza:
Megatron Framework Cleanup: llama
abort_megatron()a limpiar los recursos Megatron-specificTransformerEngine Limpieza: pide
abort_te()que se limpien los recursos TransformerEngineRoPE Cleanup: pide
cleanup_rope()limpiar las posiciones rotativas incorporando recursosDDP Cleanup: llama
cleanup_ddp()a limpiar los recursos DistributedDataParallelRecarga de módulos: requiere recargar los módulos del
reload_megatron_and_te()marcoLimpieza del módulo Lightning: opcionalmente, borra el módulo Lightning para reducir la memoria de la GPU
Limpieza de memoria: destruye las referencias a los componentes de entrenamiento para liberar memoria
register_attributes(trainer)
Registre la instancia del entrenador para utilizarla durante las operaciones de limpieza.
Parámetros:
trainer (pytorch_Lightning.Trainer): instancia de Lightning Trainer que se debe registrar PyTorch
Integración con CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Notas
Las operaciones de limpieza se ejecutan en un orden específico para evitar problemas de dependencia
La limpieza de memoria utiliza la introspección de la recolección de basura para encontrar los objetos objetivo
Todas las operaciones de limpieza están diseñadas para ser idempotentes y se pueden volver a intentar de forma segura
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Estrategia Megatron con capacidades integradas de recuperación sin puntos de control para una formación distribuida y tolerante a fallos.
Tenga en cuenta que la capacitación sin puntos de control debe ser de al menos 2 num_distributed_optimizer_instances para que la replicación sea optimizada. La estrategia también se ocupa del registro de los atributos esenciales y de la inicialización de los grupos de procesos.
Parámetros
Hereda todos los parámetros de: MegatronStrategy
Parámetros de NeMo MegatronStrategy inicialización estándar
Opciones de configuración de entrenamiento distribuidas
Modele los ajustes de paralelismo
Atributos
base_store (torch.distributed.TCPStore o None): almacén distribuido para la coordinación de grupos de procesos
Métodos
setup(trainer)
Inicie la estrategia y registre los componentes de tolerancia a errores con el entrenador.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Operaciones de configuración:
Configuración para padres: llama a la MegatronStrategy configuración para padres
Registro de inyección de errores: registra los HPFaultInjectionCallback ganchos si están presentes
Finalizar el registro: registra al entrenador con los controladores de limpieza final
Registro de abortos: registra al entrenador con los controladores de abortos que lo admiten
setup_distributed()
Inicialice el grupo de procesos mediante TCPStore con prefijo o una conexión sin root.
load_model_state_dict(checkpoint, strict=True)
Cargue el dictado de estado del modelo con una compatibilidad de recuperación sin puntos de control.
Parámetros:
checkpoint (Mapping [str, Any]): diccionario de puntos de control que contiene el estado del modelo
strict (bool, opcional): si se debe aplicar estrictamente la coincidencia de claves de dictado de estado. Valor predeterminado:
True
get_wrapper()
Obtenga la HPCallWrapper instancia necesaria para la coordinación de la tolerancia a errores.
Devoluciones:
HPCallWrapper— La instancia envolvente adjunta al entrenador para garantizar la tolerancia a los fallos
is_peft()
Comprueba si el PEFT (Parameter-Efficient Fine-Tuning) está activado en la configuración de entrenamiento comprobando las llamadas de PEFT
Devoluciones:
bool: Verdadero si la devolución de llamada PEFT está presente, falsa en caso contrario
teardown()
Anule el desmontaje nativo de PyTorch Lightning para delegar la limpieza y anular los controladores.
Ejemplo
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Lightning Callback, que integra la NeMo formación con el sistema de tolerancia a fallos de Checkpointless Training.
Esta devolución de llamadas gestiona el seguimiento de los pasos, el almacenamiento de los puntos de control y la coordinación de la actualización de los parámetros para lograr funciones de recuperación durante el proceso. Sirve como el principal punto de integración entre los ciclos de entrenamiento de PyTorch Lightning y los mecanismos de entrenamiento HyperPod sin puntos de control, ya que coordina las operaciones de tolerancia a fallos a lo largo del ciclo de formación.
Parámetros
enable_inprocess (bool, opcional): habilita las capacidades de recuperación durante el proceso. Valor predeterminado:
Falseenable_checkpointless (bool, opcional): habilita la recuperación sin puntos de control (obligatorio).
enable_inprocess=TrueValor predeterminado:Falseenable_checksum (bool, opcional): habilita la validación de la suma de verificación del estado del modelo (obligatorio).
enable_checkpointless=TrueValor predeterminado:Falseclean_tensor_hook (bool, opcional): borra todos los tensores de la GPU durante la limpieza (operación costosa). Valor predeterminado:
Falseclean_lightning_module (bool, opcional): habilita la limpieza del módulo Lightning para liberar memoria de la GPU después de cada reinicio. Valor predeterminado:
False
Atributos
tried_adapter_checkpointless (bool): marca para comprobar si se ha intentado restaurar el adaptador sin puntos de control
Métodos
get_wrapper_from_trainer(trainer)
Solicita la instancia del formador para coordinar la tolerancia a fallos. HPCallWrapper
Parámetros:
trainer (pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Devoluciones:
HPCallWrapper— La instancia contenedora para las operaciones de tolerancia a fallos
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Se utiliza al principio de cada lote de formación para gestionar el seguimiento de los pasos y la recuperación.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Se está capacitando al módulo Lightning
lote: datos del lote de entrenamiento actual
batch_idx (int): índice del lote actual
args: argumentos posicionales adicionales
kwargs: argumentos de palabras clave adicionales
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Libera el bloqueo de actualización de parámetros al final de cada lote de entrenamiento.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Se está capacitando al módulo Lightning
salidas (STEP_OUTPUT) — Salidas de los pasos de entrenamiento
batch (Any): datos actuales del lote de entrenamiento
batch_idx (int): índice del lote actual
Notas:
El tiempo de liberación del bloqueo garantiza que la recuperación sin puntos de control pueda continuar una vez finalizadas las actualizaciones de los parámetros
Solo se ejecuta cuando ambos
enable_inprocessy son verdaderosenable_checkpointless
get_peft_callback(trainer)
Recupera la llamada PEFT de la lista de devoluciones de llamadas del entrenador.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
Devoluciones:
PEFT o Ninguno: instancia de devolución de llamada de PEFT si se encuentra, None en caso contrario
_try_adapter_checkpointless_restore(trainer, params_to_save)
Intente restaurar sin puntos de control los parámetros del adaptador PEFT.
Parámetros:
trainer (Pytorch_Lightning.Trainer): instancia de Lightning Trainer PyTorch
params_to_save (set): conjunto de nombres de parámetros para guardar como parámetros del adaptador
Notas:
Solo se ejecuta una vez por sesión de entrenamiento (controlada por un indicador)
tried_adapter_checkpointlessConfigura el administrador de puntos de control con la información de los parámetros del adaptador
Ejemplo
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Administración de la memoria
clean_tensor_hook: elimina los ganchos tensores durante la limpieza (caro pero minucioso)
clean_lightning_module: Libera la memoria de la GPU del módulo Lightning durante los reinicios
Ambas opciones ayudan a reducir el consumo de memoria durante la recuperación de errores
Coordina con ParameterUpdateLock un seguimiento seguro de las actualizaciones de parámetros
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Conector Lightning Checkpoint que integra la recuperación sin puntos de control con la carga tradicional de puntos de control basada en disco.
Este conector amplía el de PyTorch Lightning _CheckpointConnector para proporcionar una integración perfecta entre la recuperación sin puntos de control y la restauración de puntos de control estándar. En primer lugar, intenta realizar una recuperación sin puntos de control y, a continuación, recurre a la carga mediante puntos de control basados en disco si la recuperación sin puntos de control no es factible o se produce un error.
Parámetros
Hereda todos los parámetros de _ CheckpointConnector
Métodos
resume_start(checkpoint_path=None)
Intente precargar el punto de control con una prioridad de recuperación sin puntos de control.
Parámetros:
checkpoint_path (str o None, opcional): ruta al punto de control del disco como alternativa. Valor predeterminado:
None
resume_end()
Complete el proceso de carga del punto de control y realice las operaciones posteriores a la carga.
Notas
Amplía la
_CheckpointConnectorcategoría interna de PyTorch Lightning con un soporte de recuperación sin puntos de controlMantiene una compatibilidad total con los flujos de trabajo estándar de PyTorch Lightning Checkpoint
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Se amplía AutoResume con NeMo una configuración diferida para permitir la validación de la recuperación sin puntos de control antes de resolver la ruta del punto de control.
Esta clase implementa una estrategia de inicialización en dos fases que permite realizar la validación de la recuperación sin puntos de control antes de volver a la carga tradicional de puntos de control basada en disco. Retrasa la AutoResume configuración de forma condicional para evitar una resolución prematura de la ruta de los puntos de control, lo que permite validar primero si es posible realizar una recuperación entre pares sin puntos de CheckpointManager control.
Parámetros
Hereda todos los parámetros de AutoResume
Métodos
setup(trainer, model=None, force_setup=False)
Retrasa la AutoResume configuración de forma condicional para permitir la validación de la recuperación sin puntos de control.
Parámetros:
trainer (Pytorch_Lightning.Trainer o Lightning.Fabric.Fabric): instancia de Lightning Trainer o Fabric PyTorch
modelo (opcional): instancia de modelo para la configuración. Valor predeterminado:
Noneforce_setup (bool, opcional): si es verdadero, evita el retraso y ejecuta AutoResume la configuración inmediatamente. Valor predeterminado:
False
Ejemplo
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Notas
Extiende NeMo la AutoResume clase con un mecanismo de retardo que permite una recuperación sin puntos de control
Funciona en conjunto con un flujo de trabajo
CheckpointlessCompatibleConnectorde recuperación completo
