Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso del entrenamiento elástico en Amazon SageMaker HyperPod
El entrenamiento de Elastic es una nueva SageMaker HyperPod capacidad de Amazon que escala automáticamente los trabajos de capacitación en función de la disponibilidad de los recursos de cómputo y la prioridad de la carga de trabajo. Los trabajos de formación de Elastic pueden comenzar con los recursos de cómputo mínimos necesarios para el entrenamiento de modelos y ampliarlos o reducirlos de forma dinámica mediante puntos de control automáticos y reanudarlos en diferentes configuraciones de nodos (tamaño mundial). El escalado se logra ajustando automáticamente el número de réplicas de datos paralelos. Durante los períodos de alta utilización de los clústeres, los trabajos de formación elástica se pueden configurar para que se reduzcan automáticamente en respuesta a las solicitudes de recursos de los trabajos de mayor prioridad, lo que permite liberar recursos informáticos para las cargas de trabajo críticas. Cuando se liberan recursos durante los períodos de menor actividad, las tareas de formación elástica se reducen automáticamente para acelerar la formación y, a continuación, se reducen cuando las cargas de trabajo de mayor prioridad vuelven a necesitar recursos.
La formación elástica se basa en el operador de HyperPod formación e integra los siguientes componentes:
-
Amazon SageMaker HyperPod Task Governance para la asignación de colas, la priorización y la programación de trabajos
-
PyTorch Puntos de control distribuidos (DCP)
para una gestión escalable de estados y puntos de control, como el DCP
Marcos compatibles
-
PyTorch con datos distribuidos en paralelo (DDP) y datos totalmente fragmentados en paralelo (FSDP)
-
PyTorch Punto de control distribuido (DCP)
Requisitos previos
SageMaker HyperPod Clúster EKS
Debe tener un SageMaker HyperPod clúster en ejecución con la orquestación de Amazon EKS. Para obtener información sobre la creación de un clúster de HyperPod EKS, consulte:
SageMaker HyperPod Operador de formación
Elastic Training es compatible con la versión 1.2 y versiones posteriores de Training Operator.
Para instalar el operador de entrenamiento como complemento de EKS, consulta: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Recomendado) Instale y configure Task Governance y Kueue
Recomendamos instalar y configurar Kueue mediante la gobernanza de HyperPod tareas para especificar las prioridades de la carga de trabajo mediante un entrenamiento flexible. Kueue ofrece una mejor gestión de la carga de trabajo, ya que permite establecer colas, priorizar, programar grupos, hacer un seguimiento de los recursos y adoptar medidas preventivas adecuadas, elementos esenciales para operar en entornos de formación con varios usuarios.
-
La planificación de grupos garantiza que todos los módulos necesarios de un trabajo de formación comiencen juntos. Esto evita situaciones en las que algunos módulos se inicien mientras que otros permanezcan pendientes, lo que podría provocar un desperdicio de recursos.
-
La prevención moderada permite que los trabajos elásticos de menor prioridad cedan recursos a las cargas de trabajo de mayor prioridad. Los trabajos de Elastic pueden reducirse sin problemas sin ser desalojados por la fuerza, lo que mejora la estabilidad general del clúster.
Recomendamos configurar los siguientes componentes de Kueue:
-
PriorityClasses para definir la importancia relativa del trabajo
-
ClusterQueues para gestionar el intercambio global de recursos y las cuotas entre los equipos o las cargas de trabajo
-
LocalQueues para enrutar los trabajos de los espacios de nombres individuales a los correspondientes ClusterQueue
Para configuraciones más avanzadas, también puede incorporar:
-
Fair-share políticas para equilibrar el uso de los recursos entre varios equipos
-
Reglas de preferencia personalizadas para hacer cumplir los acuerdos de nivel de servicio o los controles de costos de la organización
Consulte:
(Recomendado) Configure los espacios de nombres de usuario y las cuotas de recursos
Al implementar esta función en Amazon EKS, recomendamos aplicar un conjunto de configuraciones básicas a nivel de clúster para garantizar el aislamiento, la equidad de los recursos y la coherencia operativa entre los equipos.
Configuración de espacio de nombres y acceso
Organice sus cargas de trabajo mediante espacios de nombres independientes para cada equipo o proyecto. Esto le permite aplicar un aislamiento y una gobernanza detallados. También recomendamos configurar el mapeo RBAC de AWS IAM a Kubernetes para asociar usuarios o roles individuales de IAM a sus espacios de nombres correspondientes.
Las prácticas clave incluyen:
-
Asigne las funciones de IAM a las cuentas de servicio de Kubernetes mediante las funciones de IAM para las cuentas de servicio (IRSA) cuando las cargas de trabajo necesiten permisos. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Aplique políticas RBAC para restringir a los usuarios solo a sus espacios de nombres designados (por ejemplo,
Role/enRoleBindinglugar de permisos para todo el clúster).
Restricciones de recursos e informática
Para evitar la contención de recursos y garantizar una programación justa entre los equipos, aplica cuotas y límites a nivel de espacio de nombres:
-
ResourceQuotas para limitar el número total de CPU, memoria, almacenamiento y objetos (pods, PVC, servicios, etc.).
-
LimitRanges para hacer cumplir los límites de CPU y memoria predeterminados y máximos por pod o por contenedor.
-
PodDisruptionBudgets (PDB) según sea necesario para definir las expectativas de resiliencia.
-
Opcional: restricciones de Namespace-level colas (p. ej., mediante Task Governance o Kueue) para evitar que los usuarios envíen trabajos en exceso.
Estas restricciones ayudan a mantener la estabilidad del clúster y permiten programar de forma predecible las cargas de trabajo de formación distribuidas.
Auto-scaling
SageMaker HyperPod on EKS admite el escalado automático de clústeres a través de Karpenter. Cuando se utiliza Karpenter o un aprovisionador de recursos similar junto con Elastic Training, tanto el clúster como el trabajo de entrenamiento elástico pueden ampliarse automáticamente una vez enviado un trabajo de entrenamiento elástico. Esto se debe a que el operador de Elastic Training adopta un enfoque codicioso y siempre pide más recursos de cómputo de los disponibles hasta que alcanza el límite máximo establecido por el trabajo. Esto se debe a que el operador de Elastic Training solicita continuamente recursos adicionales como parte de la ejecución flexible del trabajo, lo que puede activar el aprovisionamiento de nodos. Los aprovisionadores continuos de recursos, como Karpenter, atenderán las solicitudes ampliando el clúster de cómputo.
Para mantener estas ampliaciones predecibles y bajo control, recomendamos configurar el nivel de espacio de nombres ResourceQuotas en los espacios de nombres donde se crean los trabajos de formación elástica. ResourceQuotas ayudan a limitar el máximo de recursos que los trabajos pueden solicitar, lo que impide el crecimiento ilimitado de los clústeres y, al mismo tiempo, permite un comportamiento elástico dentro de unos límites definidos.
Por ejemplo, una ResourceQuota instancia p5.48xlarge de 8 ml tendrá el siguiente formato:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Cree un contenedor de formación
HyperPod El operador de entrenamiento trabaja con un PyTorch lanzador personalizado que se proporciona mediante el paquete python de HyperPod Elastic Agent (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun comando por hyperpodrun para iniciar la capacitación. Para obtener más información, consulte:
Un ejemplo de contenedor de entrenamiento:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Modificación del código de entrenamiento
SageMaker HyperPod proporciona un conjunto de recetas que ya están configuradas para ejecutarse con Elastic Policy.
Para habilitar el entrenamiento elástico para los guiones de PyTorch entrenamiento personalizados, tendrás que realizar pequeñas modificaciones en tu ciclo de entrenamiento. Esta guía explica las modificaciones necesarias para garantizar que tu trabajo de formación responda a los eventos de escalado elástico que se producen cuando cambia la disponibilidad de los recursos informáticos. Durante todos los eventos elásticos (por ejemplo, si hay nodos disponibles o si los nodos se ven afectados), el trabajo de formación recibe una señal de evento elástica que se utiliza para coordinar un cierre correcto, guardando un punto de control y reanudando el entrenamiento reiniciándolo desde ese punto de control guardado con una nueva configuración mundial. Para habilitar el entrenamiento elástico con guiones de entrenamiento personalizados, debes:
Detectar eventos de Elastic Scaling
En su ciclo de entrenamiento, compruebe si hay eventos elásticos durante cada iteración:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Implemente el almacenamiento de puntos de control y la carga de puntos de control
Nota: Recomendamos usar el punto de control PyTorch distribuido (DCP) para guardar los estados del modelo y del optimizador, ya que el DCP permite reanudar desde un punto de control con diferentes tamaños de mundo. Es posible que otros formatos de puntos de control no admitan la carga de puntos de control en mundos de diferentes tamaños, en cuyo caso tendrás que implementar una lógica personalizada para gestionar los cambios dinámicos de tamaño del mundo.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Opcional) Usa cargadores de datos con estado
Si solo está entrenando para una sola época (es decir, una sola pasada por todo el conjunto de datos), el modelo debe ver cada muestra de datos exactamente una vez. Si el trabajo de formación termina a mitad de la fase y se reanuda con un tamaño mundial diferente, las muestras de datos procesadas anteriormente se repetirán si el estado del cargador de datos no se mantiene. Un cargador de datos con estado lo evita guardando y restaurando la posición del cargador de datos, lo que garantiza que las ejecuciones reanudadas continúen desde el evento de escalado elástico sin tener que volver a procesar ninguna muestra. Le recomendamos que lo utilice StatefulDataLoaderstate_dict() y load_state_dict() métodos, ya torch.utils.data.DataLoader que permite controlar el proceso de carga de datos a mitad de época.
Presentar trabajos de formación elásticos
HyperPod el operador de formación define un nuevo tipo de recurso:hyperpodpytorchjob. Elastic Training amplía este tipo de recurso y agrega los campos resaltados a continuación:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Uso de kubectl
Posteriormente, puedes iniciar Elastic Training con el siguiente comando.
kubectl apply -f elastic-training-job.yaml
Uso de SageMaker recetas
Los trabajos de entrenamiento elásticos se pueden lanzar a través de SageMaker HyperPod recetas
nota
Hemos incluido 46 recetas elásticas para trabajos de SFO y DPO en Hyperpod Recipe. Los usuarios pueden iniciar esos trabajos con un cambio de línea sobre el script de inicio estático existente:
++recipes.elastic_policy.is_elastic=true
Además de las recetas estáticas, las recetas elásticas añaden los siguientes campos para definir los comportamientos elásticos:
Política elástica
El elastic_policy campo define la configuración de nivel de trabajo para el trabajo de entrenamiento elástico y tiene las siguientes configuraciones:
-
is_elastic:bool- si este trabajo es elástico -
min_nodes:int- el número mínimo de nodos utilizados para el entrenamiento elástico -
max_nodes:int- el número máximo de nodos utilizados para el entrenamiento elástico -
replica_increment_step:int- incrementar la cantidad de cápsulas en grupos de tamaño fijo, este campo se excluye mutuamente del quescale_configdefinimos más adelante. -
use_graceful_shutdown:bool- si se utiliza un apagado correcto durante los eventos de escalado, el valor predeterminado es.true -
scaling_timeout:int- el tiempo de espera en segundos durante el evento de escalado antes del tiempo de espera -
graceful_shutdown_timeout:int- el tiempo de espera para un cierre correcto
El siguiente es un ejemplo de definición de este campo, que también puedes encontrar en el repositorio Hyperpod Recipe de Recipe: recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Config de escala
El scale_config campo define las configuraciones principales en cada escala específica. Es un diccionario clave-valor, donde la clave es un número entero que representa la escala objetivo y el valor es un subconjunto de la receta básica. A <key> escala, utilizamos la <value> para actualizar las configuraciones específicas de la receta. base/static A continuación se muestra un ejemplo de este campo:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
La configuración anterior define la configuración de entrenamiento en las escalas 2 y 3. En ambos casos, utilizamos la tasa de aprendizaje4e-4, el tamaño del lote de128. Pero en la escala 2, utilizamos a micro_train_batch_size de 8, mientras que en la escala 3 utilizamos un tamaño de lote irregular, ya que el tamaño del lote del tren no se puede dividir uniformemente en 3 nodos.
Tamaño de lote desigual
Se trata de un campo para definir el comportamiento de distribución de los lotes cuando el tamaño del lote global no se puede dividir uniformemente por el número de rangos. No es específico del entrenamiento elástico, pero permite escalar con mayor precisión la granularidad.
-
use_uneven_batch:bool- si utiliza una distribución desigual de los lotes -
num_dp_groups_with_small_batch_size:int- en una distribución desigual de lotes, algunos rangos utilizan lotes locales más pequeños, mientras que otros utilizan lotes más grandes. El tamaño del lote global debe ser igual asmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- este valor es el tamaño de lote local más pequeño -
large_local_batch_size:int- este valor es el tamaño de lote local más grande
Supervise la formación en MLflow
Los trabajos con recetas de Hyperpod permiten la observabilidad a través de MLflow. Los usuarios pueden especificar las configuraciones de MLflow en la receta:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Estas configuraciones se asignan a la configuración de MLflow
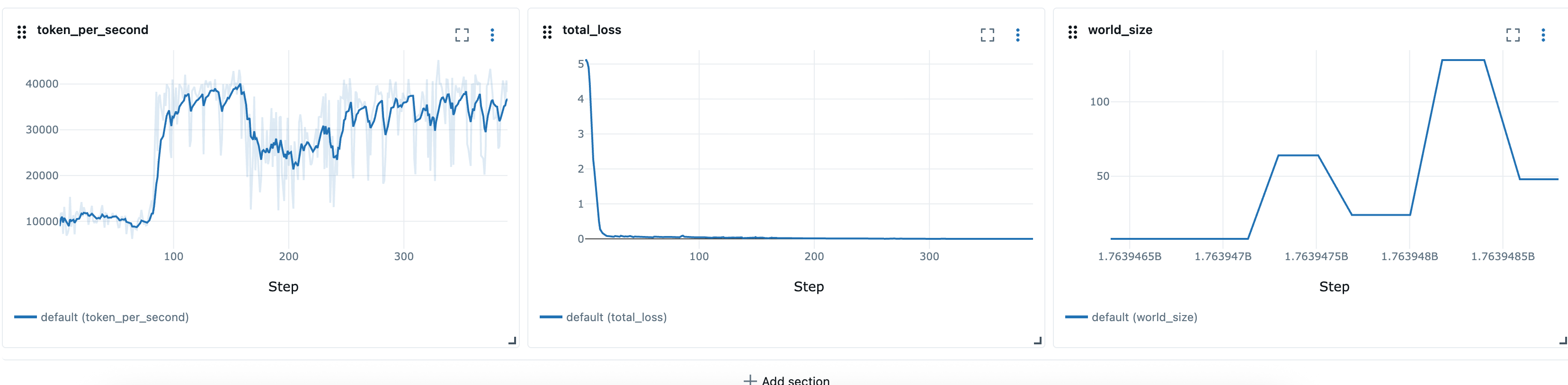
Tras definir las recetas elásticas, podemos utilizar los scripts del lanzador, por ejemplo, launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh para lanzar un trabajo de entrenamiento elástico. Esto es similar a lanzar un trabajo estático con la receta de Hyperpod.
nota
El trabajo de entrenamiento elástico del soporte de recetas se reanuda automáticamente a partir de los últimos puntos de control. Sin embargo, de forma predeterminada, cada reinicio crea un nuevo directorio de entrenamiento. Para poder reanudar correctamente desde el último punto de control, debemos asegurarnos de que se vuelva a utilizar el mismo directorio de formación. Esto se puede hacer configurando
recipes.training_config.training_args.override_training_dir=true
Use-case ejemplos y limitaciones
Scale-up cuando haya más recursos disponibles
Cuando haya más recursos disponibles en el clúster (por ejemplo, cuando se completen otras cargas de trabajo). Durante este evento, el controlador de formación ampliará automáticamente el trabajo de formación. Este comportamiento se explica a continuación.
Para simular una situación en la que haya más recursos disponibles, podemos enviar un trabajo de alta prioridad y, a continuación, liberar los recursos eliminando el trabajo de alta prioridad.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
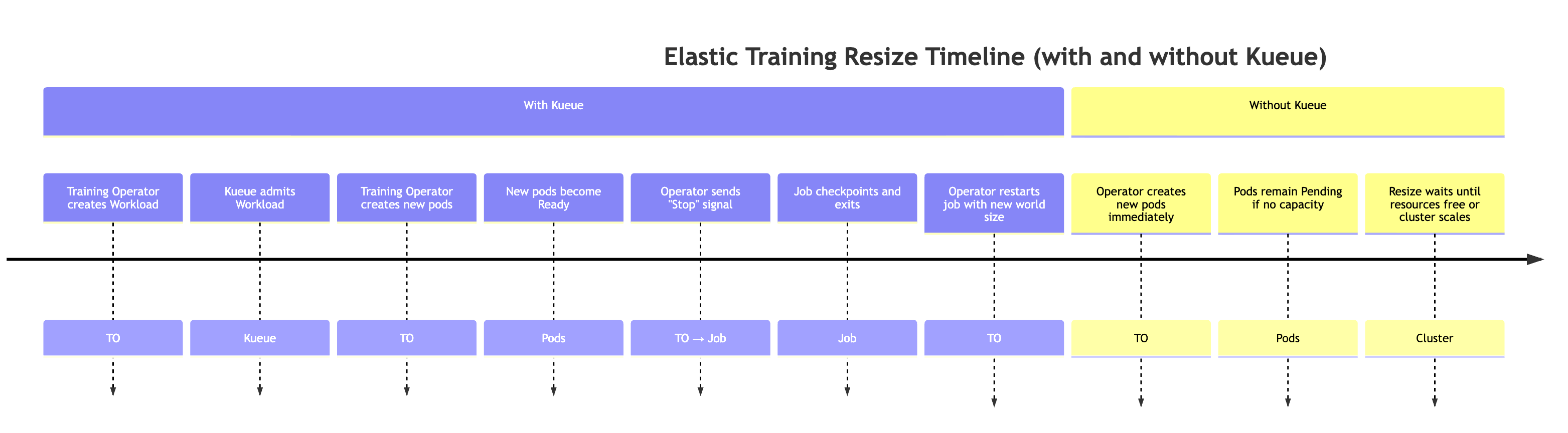
Comportamiento esperado:
-
El operador de formación crea una carga de trabajo de Kueue Cuando un trabajo de formación flexible solicita un cambio de tamaño mundial, el operador de formación genera un objeto de carga de trabajo de Kueue adicional que representa los nuevos requisitos de recursos.
-
Kueue admite la carga de trabajo Kueue evalúa la solicitud en función de los recursos disponibles, las prioridades y las políticas de colas. Una vez aprobada, se admite la carga de trabajo.
-
El operador de formación crea los módulos adicionales Una vez ingresados, el operador lanza los módulos adicionales necesarios para alcanzar el nuevo tamaño mundial.
-
Cuando las nuevas cápsulas estén listas, el operador de entrenamiento envía una señal de evento elástica especial al guion de entrenamiento.
-
El trabajo de entrenamiento realiza puntos de control para preparar una parada correcta. El proceso de entrenamiento comprueba periódicamente la presencia de la señal elástica del evento mediante una llamada a la función elastic_event_detected (). Una vez detectada, inicia un punto de control. Una vez que el punto de control se haya completado correctamente, el proceso de formación finaliza sin problemas.
-
El operador de formación reinicia el trabajo con el nuevo tamaño mundial. El operador espera a que se cierren todos los procesos y, a continuación, reinicia el trabajo de formación utilizando el tamaño mundial actualizado y el punto de control más reciente.
Nota: Cuando no se usa Kueue, el operador de entrenamiento se salta los dos primeros pasos. Intenta crear inmediatamente los módulos adicionales necesarios para el nuevo tamaño del mundo. Si no hay suficientes recursos disponibles en el clúster, estos módulos permanecerán en estado pendiente hasta que haya capacidad disponible.
Prioridad por trabajo de alta prioridad
Los trabajos elásticos se pueden reducir automáticamente cuando un trabajo de alta prioridad necesita recursos. Para simular este comportamiento, puede enviar un trabajo de formación flexible, que utilice el máximo número de recursos disponibles desde el inicio de la formación, en lugar de enviar un trabajo de alta prioridad y observar el comportamiento preferente.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
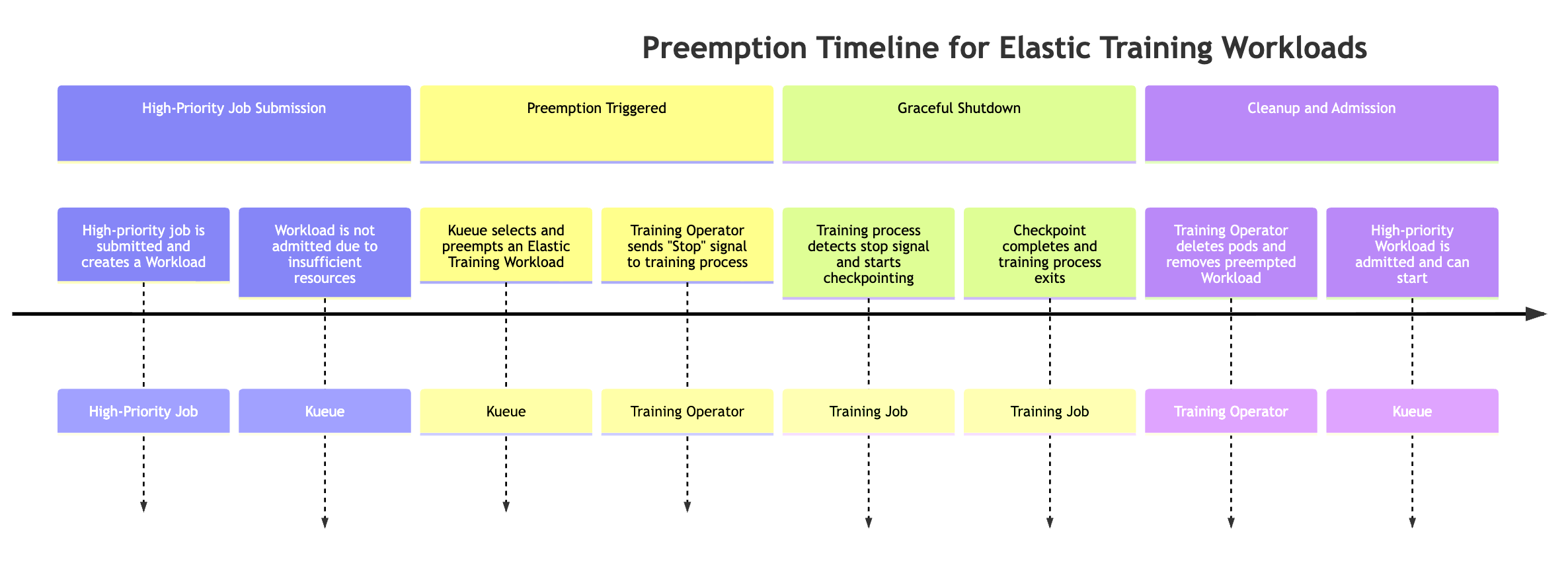
Cuando un trabajo de alta prioridad necesita recursos, Kueue puede evitar las cargas de trabajo de Elastic Training de menor prioridad (puede haber más de un objeto de carga de trabajo asociado al trabajo de Elastic Training). El proceso de preferencia sigue esta secuencia:
-
Se envía un trabajo de alta prioridad. El trabajo crea una nueva carga de trabajo de Kueue, pero la carga de trabajo no se puede admitir porque los recursos del clúster son insuficientes.
-
Kueue se antepone a una de las cargas de trabajo del trabajo de Elastic Training Los trabajos de Elastic pueden tener varias cargas de trabajo activas (una por configuración de tamaño mundial). Kueue selecciona una opción prioritaria en función de las políticas de prioridad y de colas.
-
El operador de entrenamiento envía una señal de evento elástica. Una vez que se activa la preferencia, el operador de entrenamiento notifica al proceso de entrenamiento en ejecución que se detenga correctamente.
-
El proceso de formación lleva a cabo una serie de controles. El trabajo de entrenamiento comprueba periódicamente si hay señales de eventos elásticas. Cuando se detecta, comienza un punto de control coordinado para preservar el progreso antes de detenerse.
-
un operador de formación limpia los módulos y las cargas de trabajo. El operador espera a que se complete el punto de control y, a continuación, elimina los módulos de formación que formaban parte de la carga de trabajo prioritaria. También elimina el objeto Workload correspondiente de Kueue.
-
Se admite la carga de trabajo de alta prioridad. Con los recursos liberados, Kueue admite el trabajo de alta prioridad, lo que le permite iniciar la ejecución.
La preferencia puede provocar que todo el trabajo de entrenamiento se detenga, lo que puede no ser deseable para todos los flujos de trabajo. Para evitar la suspensión total del trabajo y, al mismo tiempo, permitir la escalabilidad elástica, los clientes pueden configurar dos niveles de prioridad diferentes dentro del mismo trabajo de formación definiendo dos secciones: replicaSpec
-
Un ReplicaSpec principal (fijo) con prioridad normal o alta
-
Contiene el número mínimo de réplicas necesario para mantener el trabajo de formación en ejecución.
-
Utiliza un valor superior PriorityClass, lo que garantiza que estas réplicas nunca se sustituyan.
-
Mantiene el progreso inicial incluso cuando el clúster está bajo presión de recursos.
-
-
Un ReplicaSpec elástico (escalable) con menor prioridad
-
Contiene las réplicas opcionales adicionales que proporcionan procesamiento adicional durante el escalado elástico.
-
Utiliza una inferior PriorityClass, lo que permite a Kueue adelantarse a estas réplicas cuando los trabajos de mayor prioridad necesitan recursos.
-
Garantiza que solo se recupere la parte elástica, mientras que el entrenamiento básico continúa sin interrupciones.
-
Esta configuración permite la prevención parcial, en la que solo se recupera la capacidad elástica, lo que mantiene la continuidad de la formación y, al mismo tiempo, permite compartir equitativamente los recursos en entornos con varios usuarios. Ejemplo:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
El desalojo del módulo de almacenamiento, los fallos del módulo y la degradación del hardware:
El operador de HyperPod formación incluye mecanismos integrados para recuperar el proceso de formación cuando se interrumpe inesperadamente. Las interrupciones pueden producirse por varios motivos, como errores en el código de entrenamiento, desalojos de módulos, fallos de nodos, degradación del hardware y otros problemas de tiempo de ejecución.
Cuando esto ocurre, el operador intenta recrear automáticamente los módulos afectados y reanudar el entrenamiento desde el último punto de control. Si la recuperación no es posible de inmediato, por ejemplo, debido a una capacidad sobrante insuficiente, el operador puede seguir progresando reduciendo temporalmente el tamaño del mundo y reduciendo el elástico trabajo de formación.
Cuando un trabajo de entrenamiento elástico se interrumpe o pierde réplicas, el sistema se comporta de la siguiente manera:
-
Fase de recuperación (utilizando nodos de reserva) El controlador de entrenamiento espera a que
faultyScaleDownTimeoutInSecondslos recursos estén disponibles e intenta recuperar las réplicas fallidas mediante la redistribución de los módulos de la capacidad sobrante. -
Reducción elástica Si la recuperación no es posible dentro del plazo de espera, el operador de formación reduce la tarea a un tamaño mundial más pequeño (si la política de flexibilidad del trabajo lo permite). Luego, la capacitación se reanuda con menos réplicas.
-
Escalabilidad elástica Cuando vuelven a estar disponibles recursos adicionales, el operador vuelve a escalar automáticamente el trabajo de capacitación al tamaño mundial preferido.
Este mecanismo garantiza que la capacitación pueda continuar con un tiempo de inactividad mínimo, incluso en caso de escasez de recursos o de fallas parciales de la infraestructura, sin dejar de aprovechar la escalabilidad elástica.
Usa el entrenamiento elástico con otras HyperPod funciones
Actualmente, Elastic Training no admite las capacidades de entrenamiento sin puntos de control, los puntos de control HyperPod gestionados por niveles ni las instancias puntuales.
nota
Recopilamos ciertas métricas operativas rutinarias agregadas y anónimas para proporcionar la disponibilidad de los servicios esenciales. La creación de estas métricas está totalmente automatizada y no implica una revisión humana de la carga de trabajo de formación del modelo subyacente. Estas métricas se refieren a un trabajo y al escalamiento de las operaciones, a la gestión de recursos y a la funcionalidad esencial del servicio.
