Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
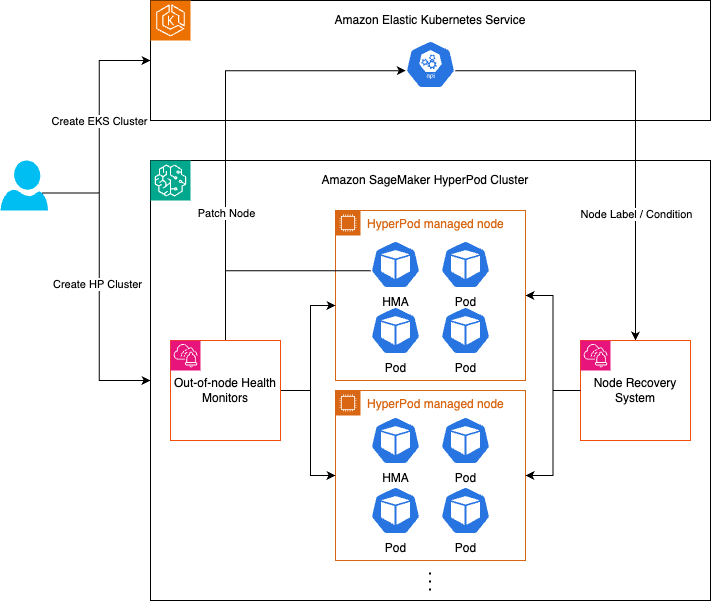
Sistema de Monitoreo de Salud
SageMaker HyperPod El sistema de monitoreo de la salud incluye dos componentes
-
Agentes de monitoreo instalados en sus nodos, que incluyen el Health Monitoring Agent (HMA) que actúa como monitor de estado en el host y un conjunto de monitores de estado fuera del nodo.
-
Sistema de recuperación de nodos gestionado por. SageMaker HyperPod El sistema de monitoreo del estado monitoreará el estado del nodo de forma continua a través de agentes de monitoreo y, luego, tomará medidas automáticamente cuando se detecte una falla utilizando el sistema de recuperación de nodos.
Controles de salud realizados por el agente de SageMaker HyperPod monitoreo de salud
El agente SageMaker HyperPod de control de la salud comprueba lo siguiente.
GPU de NVIDIA
-
Errores en el resultado de
nvidia-smi -
Varios errores en los registros generados por la plataforma Amazon Elastic Compute Cloud (EC2)
-
Validación del recuento de GPU: si no coincide el número esperado de GPU en un tipo de instancia concreto (por ejemplo, 8 GPU en el tipo de instancia ml.p5.48xlarge) y el recuento devuelto por, HMA reinicia el nodo
nvidia-smi
AWS Trainium
-
Errores en el resultado del monitor AWS Neuron
-
Salidas generadas por el detector de problemas de nodos neuronales (para obtener más información sobre el detector de problemas de nodos AWS neuronales, consulte Detección y recuperación de problemas de nodos AWS neuronales en clústeres de Amazon EKS
). -
Varios errores en los registros generados por la plataforma Amazon EC2
-
Validación del recuento de dispositivos neuronales: si hay una discrepancia entre el número real de dispositivos neuronales en un tipo de instancia concreto y el recuento devuelto por
neuron-ls, HMA reinicia el nodo
Las comprobaciones anteriores son pasivas y las comprobaciones de estado de los nodos se realizan de forma continua en los HyperPod nodos. Además de estas comprobaciones, HyperPod también realiza comprobaciones de estado exhaustivas (o activas) durante la creación y actualización de HyperPod los clústeres. Más información sobre los controles de estado profundos.
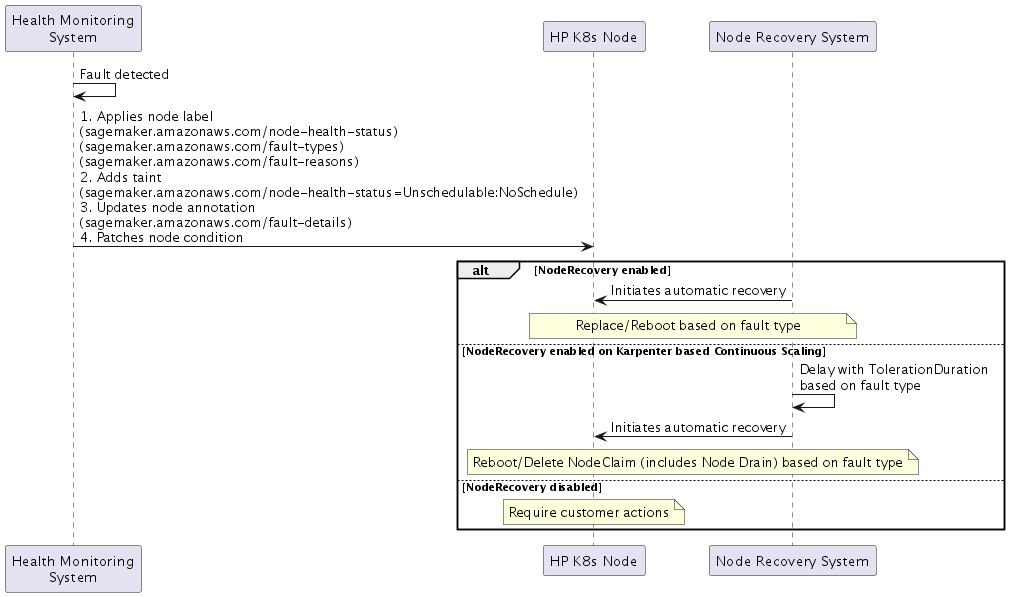
Detección de fallas
Cuando SageMaker HyperPod detecta una falla, implementa una respuesta de cuatro partes:
-
Etiquetas de nodos
-
Estado de Salud:
sagemaker.amazonaws.com/node-health-status -
Tipo de fallo:
sagemaker.amazonaws.com/fault-typesetiqueta para una categorización de alto nivel -
Motivo del error:
sagemaker.amazonaws.com/fault-reasonsetiqueta para obtener información detallada sobre el error
-
-
Contaminación del nodo
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
Anotación de nodo
-
Detalles de la falla:
sagemaker.amazonaws.com/fault-details -
Registra hasta 20 fallos con marcas de tiempo que se produjeron en el nodo
-
-
Condiciones del nodo (condición del nodo de Kubernetes
) -
Refleja el estado de salud actual en las condiciones del nodo:
-
Tipo: igual que el tipo de falla
-
Estado:
True -
Motivo: Igual que el motivo de la culpa
-
LastTransitionTime: Tiempo de aparición de la falla
-
-
Registros generados por el agente de SageMaker HyperPod monitorización del estado
El agente SageMaker HyperPod de supervisión del estado es una función de comprobación de estado lista para usar y se ejecuta de forma continua en todos los clústeres. HyperPod El agente de supervisión del estado publica los eventos de estado detectados en las instancias GPU o Trn en el grupo de registros del CloudWatch clúster. /aws/sagemaker/Clusters/
Los registros de detección del agente de supervisión del HyperPod estado se crean como flujos de registro independientes con el nombre SagemakerHealthMonitoringAgent de cada nodo. Puede consultar los registros de detección utilizando CloudWatch la información de los registros de la siguiente manera.
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
Este proceso devuelve un resultado similar al siguiente.
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
