Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Los scripts de ciclo de vida básicos proporcionados por HyperPod
En esta sección se explican todos los componentes del proceso básico de configuración de Slurm on con un HyperPod enfoque descendente. Comienza con la preparación de una solicitud de creación de HyperPod clústeres para ejecutar la CreateCluster API y profundiza en la estructura jerárquica hasta llegar a los scripts del ciclo de vida. Usa los ejemplos de scripts de ciclo de vida que se proporcionan en el repositorio de Awsome Distributed Training GitHub
git clone https://github.com/aws-samples/awsome-distributed-training/
Los scripts básicos del ciclo de vida para configurar un clúster de Slurm SageMaker HyperPod están disponibles en. 1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
En el siguiente diagrama de flujo, se muestra una descripción detallada de cómo debe diseñar los scripts de ciclo de vida básicos. Las descripciones que aparecen debajo del diagrama y la guía de procedimientos explican cómo funcionan durante la llamada a la HyperPod CreateCluster API.
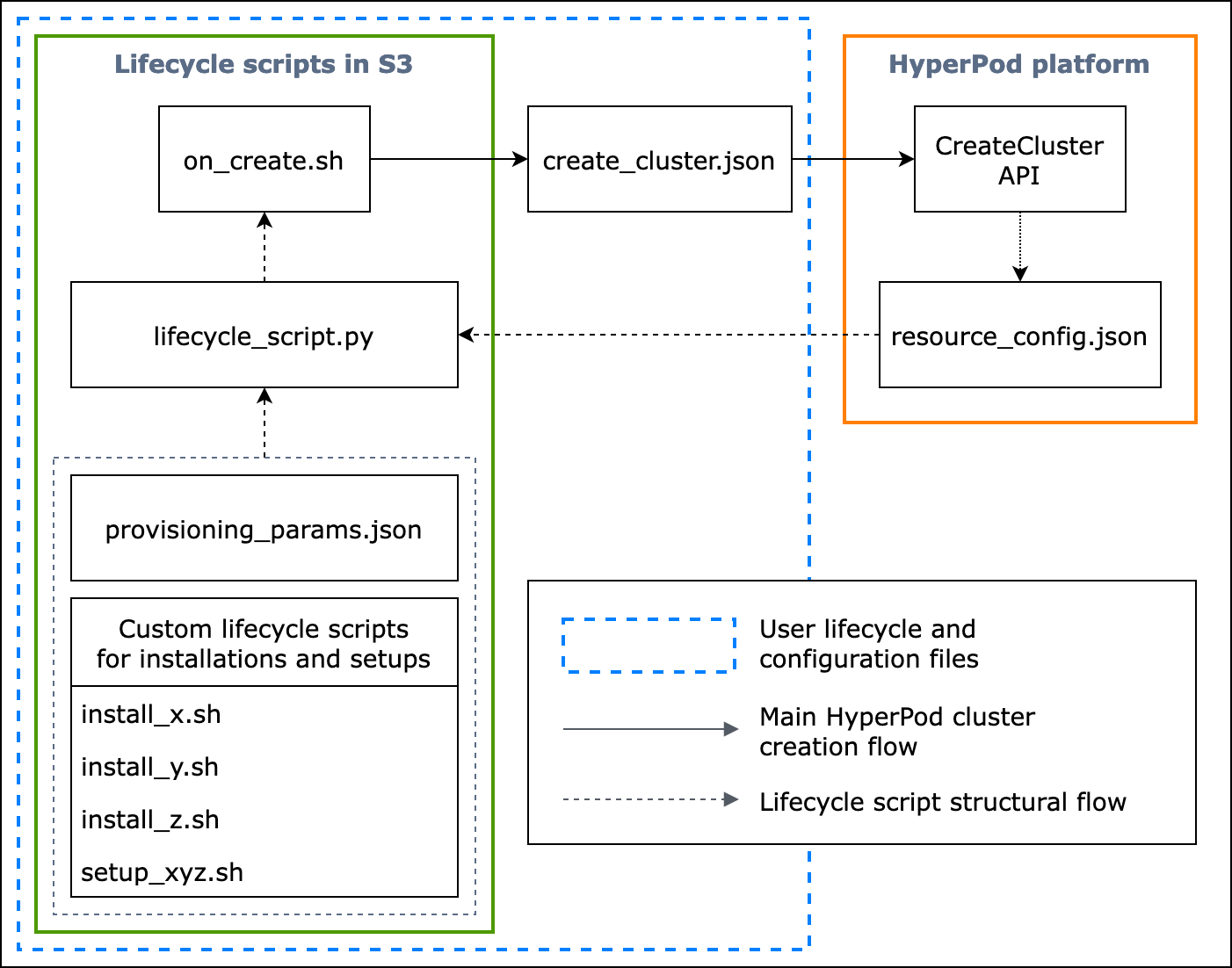
Figura: Un diagrama de flujo detallado de la creación de HyperPod clústeres y la estructura de los scripts de ciclo de vida. (1) Las flechas discontinuas se dirigen hacia donde se llaman los cuadros y muestran el flujo de preparación de los archivos de configuración y los scripts de ciclo de vida. Comienza con la preparación de provisioning_parameters.json y los scripts de ciclo de vida. Luego estos se codifican en lifecycle_script.py para permitir una ejecución colectiva en orden. Y la ejecución del lifecycle_script.py script la realiza el script del on_create.sh shell, que se ejecuta en el terminal de la HyperPod instancia. (2) Las flechas continuas muestran el flujo principal de creación del HyperPod clúster y cómo se «invoca» o se «envía» a las casillas. on_create.shes obligatorio para la solicitud de creación de un clúster, ya sea en el formulario de solicitud de creación de un clúster de la interfaz de usuario de la consola create_cluster.json o en el formulario de solicitud de creación de un clúster. Tras enviar la solicitud, HyperPod ejecuta la CreateCluster API en función de la información de configuración proporcionada en la solicitud y en los scripts del ciclo de vida. (3) La flecha punteada indica que la HyperPod plataforma crea instancias resource_config.json en el clúster durante el aprovisionamiento de los recursos del clúster. resource_config.jsoncontiene información sobre los recursos del HyperPod clúster, como el ARN del clúster, los tipos de instancias y las direcciones IP. Es importante tener en cuenta que debe preparar los scripts de ciclo de vida para que esperen el archivo resource_config.json durante la creación del clúster. Para obtener más información, consulte la guía de procedimientos que se incluye a continuación.
La siguiente guía de procedimientos explica lo que ocurre durante la creación HyperPod del clúster y cómo se diseñan los scripts del ciclo de vida básico.
-
create_cluster.json— Para enviar una solicitud de creación de HyperPod clústeres, debe preparar un archivo deCreateClustersolicitud en formato JSON. En este ejemplo de prácticas recomendadas, asumimos que el archivo de solicitud se denominacreate_cluster.json. Escribecreate_cluster.jsonpara aprovisionar un HyperPod clúster con grupos de instancias. La mejor práctica es agregar la misma cantidad de grupos de instancias que la cantidad de nodos de Slurm que planeas configurar en el HyperPod clúster. Asegúrese de asignar nombres distintivos a los grupos de instancias que asignará a los nodos de Slurm que piensa configurar.Además, debe especificar una ruta de bucket de S3 para almacenar todo el conjunto de archivos de configuración y scripts de ciclo de vida en el nombre de campo
InstanceGroups.LifeCycleConfig.SourceS3Uridel formulario de solicitudCreateCluster, y especificar el nombre de archivo de un script de intérprete de comandos de punto de entrada (supongamos que se denominaon_create.sh) enInstanceGroups.LifeCycleConfig.OnCreate.nota
Si utilizas el formulario de envío para crear un clúster en la interfaz de usuario de la HyperPod consola, la consola se encarga de rellenar y enviar la
CreateClustersolicitud en tu nombre y ejecuta laCreateClusterAPI en el backend. En este caso, no es necesario que creecreate_cluster.json; en cambio, debe asegurarse de especificar la información de configuración del clúster correcta en el formulario de envío Crear un clúster. -
on_create.sh— Para cada grupo de instancias, debes proporcionar un script shell de punto de entrada para ejecutar comandoson_create.sh, ejecutar scripts para instalar paquetes de software y configurar el entorno del HyperPod clúster con Slurm. Las dos cosas que debes preparar son unaprovisioning_parameters.jsonnecesaria HyperPod para configurar Slurm y un conjunto de scripts de ciclo de vida para instalar paquetes de software. Este script debe escribirse para buscar y ejecutar los siguientes archivos, tal y como se muestra en el script de ejemplo que aparece enon_create.sh. nota
Asegúrese de cargar todo el conjunto de scripts de ciclo de vida en la ubicación de S3 que especifique en
create_cluster.json. También debe colocar el archivoprovisioning_parameters.jsonen la misma ubicación.-
provisioning_parameters.json: este es un Formulario de configuración para provisioning_parameters.json. El scripton_create.shbusca este archivo JSON y define la variable de entorno para identificar la ruta al mismo. A través de este archivo JSON, puede configurar los nodos de Slurm y las opciones de almacenamiento, como Amazon FSx para Lustre, para que se comunique Slurm. Enprovisioning_parameters.json, asegúrate de asignar los grupos de instancias del HyperPod clúster con los nombres que especificastecreate_cluster.jsona los nodos de Slurm de forma adecuada en función de cómo planeas configurarlos.En el siguiente diagrama, se muestra un ejemplo de cómo se
provisioning_parameters.jsondeben escribir los dos archivoscreate_cluster.jsonde configuración de JSON para asignar grupos de HyperPod instancias a los nodos de Slurm. En este ejemplo, asumimos que se configuran tres nodos de Slurm: el nodo controlador (de administración), el nodo de inicio de sesión (que es opcional) y el nodo de computación (de trabajo).sugerencia
Para ayudarte a validar estos dos archivos JSON, el equipo de HyperPod servicio proporciona un script de validación,.
validate-config.pyPara obtener más información, consulte Validar los archivos de configuración JSON antes de crear un clúster de Slurm en HyperPod. 
Figura: Comparación directa entre la creación
create_cluster.jsonde HyperPod clústeres y la configuraciónprovisiong_params.jsonde Slurm. El número de grupos de instancias encreate_cluster.jsondebe coincidir con el número de nodos que desea configurar como nodos de Slurm. En el caso del ejemplo de la figura, se configurarán tres nodos de Slurm en un HyperPod clúster de tres grupos de instancias. Debes asignar los grupos de instancias del HyperPod clúster a los nodos de Slurm especificando los nombres de los grupos de instancias en consecuencia. -
resource_config.json— Durante la creación del clúster, ellifecycle_script.pyscript se escribe esperando unresource_config.jsonarchivo del mismo. HyperPod Este archivo contiene información sobre el clúster, como los tipos de instancias y las direcciones IP.Al ejecutar la
CreateClusterAPI, HyperPod crea un archivo de configuración de recursos en/opt/ml/config/resource_config.jsonfunción delcreate_cluster.jsonarchivo. La ruta del archivo se guarda en la variable de entorno denominadaSAGEMAKER_RESOURCE_CONFIG_PATH.importante
La HyperPod plataforma genera automáticamente el
resource_config.jsonarchivo y NO es necesario que lo cree. El siguiente código sirve para mostrar un ejemplo del archivoresource_config.jsonque se crearía a partir de la creación de un clúster en función del archivocreate_cluster.jsondel paso anterior. Además, le ayudará a entender qué ocurre en el backend y qué aspecto tendría un archivoresource_config.jsongenerado automáticamente.{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py— Este es el script principal de Python que ejecuta colectivamente los scripts del ciclo de vida que configuran Slurm en el HyperPod clúster mientras se aprovisiona. Este script lee enprovisioning_parameters.jsonyresource_config.jsondesde las rutas especificadas o identificadas enon_create.sh, pasa la información relevante a cada script de ciclo de vida y, a continuación, ejecuta los scripts de ciclo de vida en orden.Los scripts de ciclo de vida son un conjunto de scripts que puede personalizar con total flexibilidad para instalar paquetes de software y establecer las configuraciones necesarias o personalizadas durante la creación del clúster, como la configuración de Slurm, la creación de usuarios o la instalación de Conda o Docker. El script
lifecycle_script.pyde ejemplo está preparado para ejecutar otros scripts de ciclo de vida básicos en el repositorio, como la inicialización de deamons de Slurm ( start_slurm.sh), el montaje de Amazon FSx para Lustre ( mount_fsx.sh), y la configuración de la contabilidad de MariaDB ( setup_mariadb_accounting.sh) y la contabilidad de RDS ( setup_rds_accounting.sh). También puede añadir más scripts, empaquetarlos en el mismo directorio y añadir líneas de código para permitir la HyperPod ejecución de lifecycle_script.pylos scripts. Para obtener más información sobre los scripts básicos del ciclo de vida, consulte también los scripts del ciclo de vida 3.1en el GitHub repositorio de Awsome Distributed Training. nota
HyperPod se ejecuta SageMaker HyperPod DLAMI en cada instancia de un clúster y la AMI tiene paquetes de software preinstalados que cumplen las compatibilidades entre ellos y HyperPod las funcionalidades. Tenga en cuenta que si reinstala alguno de los paquetes preinstalados, usted es responsable de instalar los paquetes compatibles y tenga en cuenta que es posible que algunas HyperPod funcionalidades no funcionen del modo esperado.
Además de las configuraciones predeterminadas, en la carpeta
utilshay más scripts para instalar el siguiente software. El archivo lifecycle_script.pyya está preparado para incluir líneas de código para ejecutar los scripts de instalación, así que consulte los siguientes elementos para buscar esas líneas y quitar las marcas de comentario para activarlas.-
Las siguientes líneas de código sirven para instalar Docker
, Enroot y Pyxis . Estos paquetes son necesarios para ejecutar contenedores de Docker en un clúster de Slurm. Para habilitar este paso de instalación, defina el parámetro
enable_docker_enroot_pyxisparaTrueen el archivoconfig.py. # Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
Puede integrar su HyperPod clúster con Amazon Managed Service for Prometheus y Amazon Managed Grafana para exportar métricas HyperPod sobre el clúster y los nodos del clúster a los paneles de Amazon Managed Grafana. Para exportar métricas y usar el panel de Slurm
, el panel de NVIDIA DCGM Exporter y el panel de métricas de EFA en Amazon Managed Grafana, debe instalar el exportador de Slurm para Prometheus , el exportador de NVIDIA DCGM y el exportador de nodos de EFA . Para obtener más información sobre la instalación de los paquetes de exportador y el uso de los paneles de Grafana en un espacio de trabajo de Amazon Managed Grafana, consulte SageMaker HyperPod monitoreo de recursos de clústeres. Para habilitar este paso de instalación, defina el parámetro
enable_observabilityparaTrueen el archivoconfig.py. # Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
Asegúrese de cargar todos los archivos de configuración y los scripts de configuración del Paso 2 en el bucket de S3 que haya indicado en la solicitud
CreateClusterdel paso 1. Por ejemplo, supongamos que su solicitudcreate_cluster.jsontiene lo siguiente."LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }En este caso,
"s3://sagemaker-hyperpod-lifecycle/src"debería conteneron_create.sh,lifecycle_script.py,provisioning_parameters.jsony todos los demás scripts de configuración. Suponga que ha preparado los archivos en una carpeta local de la siguiente manera.└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyPara cargar los archivos, utilice el comando de S3 de la siguiente manera.
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
