Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo funciona el tamizado SageMaker inteligente
El objetivo del cribado SageMaker inteligente es filtrar los datos de entrenamiento durante el proceso de entrenamiento y enviar solo muestras más informativas al modelo. Durante un entrenamiento normal PyTorch, los datos se envían de forma iterativa en lotes al circuito de entrenamiento y a los dispositivos aceleradores (como las GPU o los chips Trainium). PyTorchDataLoader
El siguiente diagrama muestra una descripción general de cómo está diseñado el algoritmo de cribado SageMaker inteligente.
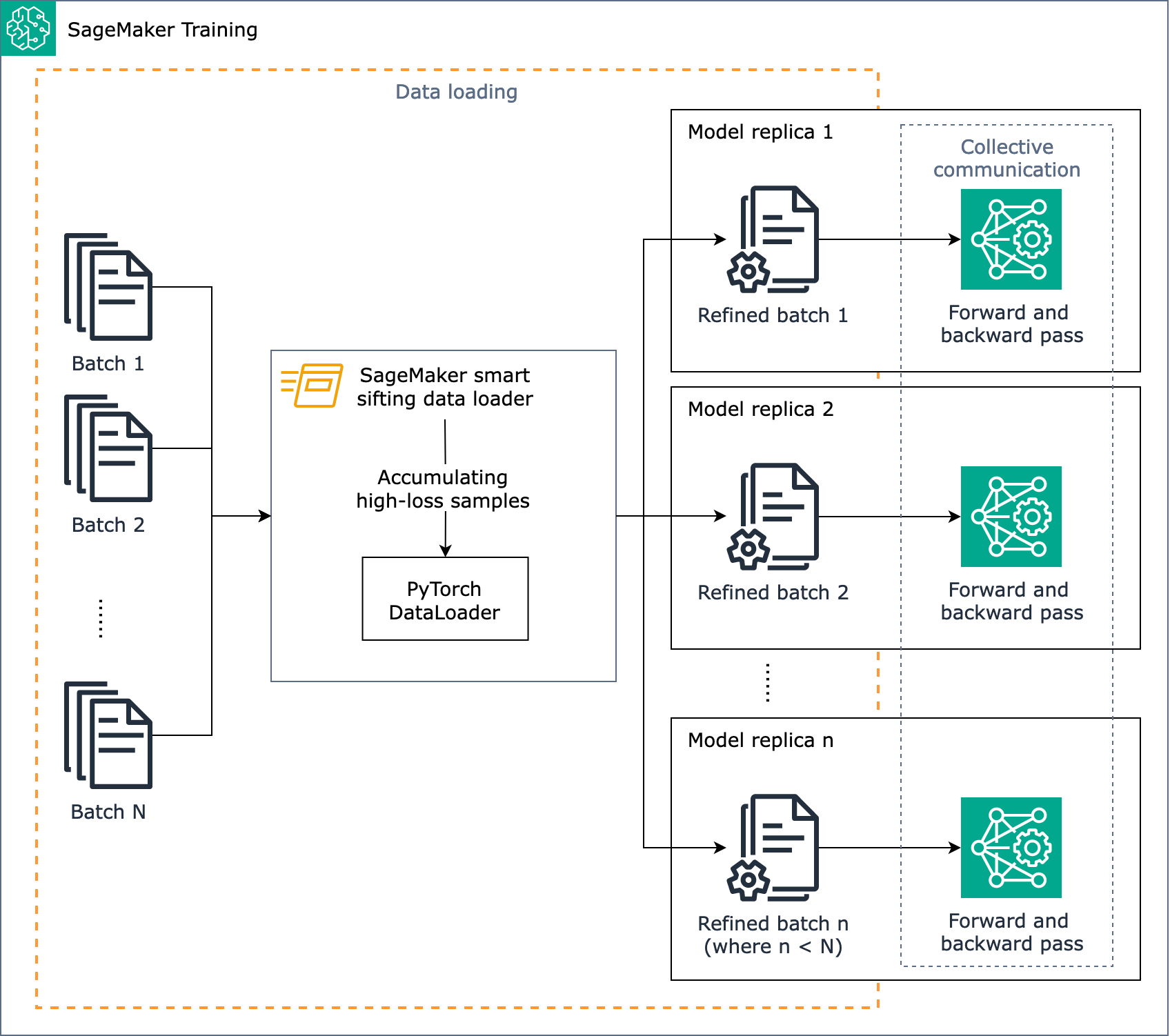
En resumen, el tamizado SageMaker inteligente funciona durante el entrenamiento a medida que se cargan los datos. El algoritmo de filtrado SageMaker inteligente calcula las pérdidas entre los lotes y filtra los datos que no mejoran antes de avanzar y retroceder en cada iteración. A continuación, el lote de datos refinado se utiliza para la pasada hacia delante y hacia atrás.
nota
El filtrado inteligente de los datos en la SageMaker IA utiliza pases directos adicionales para analizar y filtrar los datos de entrenamiento. A su vez, hay menos pasadas hacia atrás, ya que los datos menos impactantes se excluyen de su trabajo de entrenamiento. Por este motivo, los modelos que tienen pasadas hacia atrás largas o caras obtienen los mayores beneficios de eficiencia cuando utilizan la selección inteligente. Por otro lado, si la pasada hacia delante del modelo tarda más que la pasada hacia atrás, la sobrecarga podría aumentar el tiempo total de entrenamiento. Para medir el tiempo empleado en cada pasada, puede realizar un trabajo de entrenamiento de piloto y recopilar registros que registren el tiempo que tardan los procesos. Considere también la posibilidad de utilizar SageMaker Profiler, que proporciona herramientas de creación de perfiles y una aplicación de interfaz de usuario. Para obtener más información, consulte Amazon SageMaker Profiler.
SageMaker El filtrado inteligente sirve para tareas de PyTorch-based entrenamiento con el clásico paralelismo de datos distribuidos, que permite crear réplicas de modelos en cada unidad de trabajo de la GPU y su rendimiento. AllReduce Funciona con PyTorch DDP y la biblioteca paralela de datos distribuidos de SageMaker IA.
