Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques pour optimiser les performances de S3 Express One Zone
Lors du développement d’applications qui chargent et récupèrent les objets depuis Amazon S3 Express One Zone, suivez nos bonnes pratiques pour optimiser les performances. Pour utiliser la classe de stockage S3 Express One Zone, vous devez créer un compartiment de répertoires S3. La classe de stockage S3 Express One Zone n’est pas prise en charge pour une utilisation avec les compartiments S3 à usage général.
Pour accéder aux directives d’optimisation des performances relatives à toutes les autres classes de stockage Amazon S3 et aux compartiments à usage général S3, consultez Modèles de conception des bonnes pratiques : optimisation des performances d’Amazon S3.
Pour optimiser les performances et la capacité de mise à l’échelle de la classe de stockage S3 Express One Zone et des compartiments de répertoires pour les charges de travail à grande échelle, il est important de comprendre en quoi les compartiments de répertoires fonctionnent différemment des compartiments à usage général. Nous vous proposons ensuite de bonnes pratiques pour aligner vos applications sur le fonctionnement des compartiments de répertoires.
Fonctionnement des compartiments de répertoires
La classe de stockage Amazon S3 Express One Zone peut prendre en charge des charges de travail comportant jusqu’à deux millions de transactions GET et jusqu’à 200 000 transactions PUT par seconde (TPS) par compartiment de répertoires. Avec S3 Express One Zone, les données sont stockées dans des compartiments de répertoires S3 situés dans des zones de disponibilité. Les objets des compartiments de répertoires sont accessibles dans un espace de noms hiérarchique, semblable à un système de fichiers, contrairement aux compartiments à usage général S3 qui disposent d’un espace de noms plat. Contrairement aux compartiments à usage général, les compartiments de répertoires organisent les clés de manière hiérarchique dans des répertoires plutôt qu’avec des préfixes. Un préfixe est une chaîne de caractères au début du nom de la clé d’objet. Vous pouvez utiliser des préfixes pour organiser vos données et gérer une architecture plate de stockage d’objets dans des compartiments à usage général. Pour de plus amples informations, veuillez consulter Organisation des objets à l’aide de préfixes.
Dans les compartiments de répertoires, les objets sont organisés dans un espace de noms hiérarchique en utilisant la barre oblique (/) comme seul délimiteur pris en charge. Lorsque vous chargez un objet avec une clé comme dir1/dir2/file1.txt, les répertoires dir1/ et dir2/ sont automatiquement créés et gérés par Amazon S3. Les répertoires sont créés pendant l’opération PutObject ou CreateMultiPartUpload et automatiquement supprimés lorsqu’ils sont vidés après l’opération DeleteObject ou AbortMultiPartUpload. Le nombre d’objets et de sous-répertoires dans un répertoire n’est pas plafonné.
Les répertoires créés lorsque des objets sont chargés dans des compartiments de répertoires peuvent être mis à l’échelle instantanément afin de réduire les risques d’erreur HTTP 503 (Slow Down). Cette mise à l’échelle automatique permet à vos applications de mettre en parallèle les demandes de lecture et d’écriture dans et entre les répertoires, selon les besoins. Pour S3 Express One Zone, les répertoires sont conçus pour prendre en charge le nombre maximal de demandes d’un compartiment de répertoires. Il n’est pas nécessaire de randomiser les préfixes de clé pour optimiser les performances, car le système répartit automatiquement les objets pour équilibrer la charge. Les clés ne sont donc pas stockées par ordre lexicographique dans les compartiments de répertoires. En revanche, dans les compartiments à usage général S3, les clés qui sont plus proches lexicographiquement sont plus susceptibles de se trouver sur le même serveur.
Pour plus d’exemples d’opérations sur des compartiments de répertoires et d’interactions avec les répertoires, consultez Exemples d’opérations sur des compartiments de répertoires et d’interactions avec les répertoires.
Bonnes pratiques
Adoptez les bonnes pratiques pour optimiser les performances de votre compartiment de répertoires et mettre à l’échelle vos charges de travail au fil du temps.
Utiliser des répertoires contenant de nombreuses entrées (objets ou sous-répertoires)
Les compartiments de répertoires offrent des performances élevées par défaut pour toutes les charges de travail. Pour optimiser davantage les performances de certaines opérations, la consolidation d’un grand nombre d’entrées (objets ou sous-répertoires) dans des répertoires permet de réduire le temps de latence et d’augmenter le taux de demandes :
Les opérations d’API mutantes, comme
PutObject,DeleteObject,CreateMultiPartUploadetAbortMultiPartUpload, atteignent des performances optimales lorsqu’elles sont mises en œuvre avec un nombre réduit de répertoires plus denses contenant des milliers d’entrées, plutôt qu’avec un grand nombre de petits répertoires.Les opérations
ListObjectsV2sont plus performantes lorsqu’il y a moins de répertoires à parcourir pour remplir une page de résultats.
Ne pas utiliser d’entropie dans les préfixes
Dans les opérations Amazon S3, l’entropie fait référence au caractère aléatoire de la dénomination des préfixes qui permet de répartir les charges de travail de manière uniforme sur les partitions de stockage. Cependant, étant donné que les compartiments de répertoires gèrent en interne la répartition de la charge, il n’est pas recommandé de recourir à l’entropie dans les préfixes pour améliorer les performances. En effet, pour les compartiments de répertoires, l’entropie peut ralentir les demandes en ne réutilisant pas les répertoires déjà créés.
Un modèle de clé comme $HASH/directory/object pourrait finir par créer de nombreux répertoires intermédiaires. Dans l’exemple suivant, tous les job-1 sont des répertoires différents puisque leurs parents sont différents. Les répertoires seront rares et les demandes de mutation et de liste seront plus lentes. Dans cet exemple, il existe 12 répertoires intermédiaires qui ont tous une seule entrée.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
Pour améliorer les performances, nous pouvons supprimer le composant $HASH et autoriser job-1 à devenir un répertoire unique, et améliorer ainsi la densité du répertoire. Dans l’exemple suivant, l’unique répertoire intermédiaire qui comprend six entrées peut améliorer les performances par rapport à l’exemple précédent.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
Ce gain de performances s’explique par le fait que lorsqu’une clé d’objet est créée et que son nom inclut un répertoire, celui-ci est automatiquement créé pour l’objet. Les chargements d’objets ultérieurs vers ce même répertoire ne nécessitent pas la création du répertoire, ce qui réduit la latence lors des chargements d’objets vers les répertoires existants.
Utilisez un séparateur autre que le délimiteur/pour séparer les parties de votre clé si vous n'avez pas besoin de pouvoir regrouper des objets de manière logique lors des appels V2 ListObjects
Étant donné que le délimiteur / est traité de manière particulière pour les compartiments de répertoires, il doit être utilisé à bon escient. Même si les compartiments de répertoires ne classent pas les objets par ordre lexicographique, les objets d’un répertoire sont tout de même regroupés dans les sorties ListObjectsV2. Si vous n’avez pas besoin de cette fonctionnalité, vous pouvez remplacer / par un autre caractère comme séparateur afin de ne pas provoquer la création de répertoires intermédiaires.
Supposons, par exemple, que les clés suivantes adoptent le modèle de préfixe YYYY/MM/DD/HH/.
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
Si vous n’avez pas besoin de regrouper les objets par heure ou par jour dans les résultats ListObjectsV2, mais que vous avez besoin de les regrouper par mois, le schéma de clé YYYY/MM/DD-HH- permet de réduire considérablement le nombre de répertoires et d’améliorer les performances de l’opération ListObjectsV2.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Utiliser des opérations de listes délimitées dans la mesure du possible
Une demande ListObjectsV2 sans delimiter effectue une analyse récursive approfondie de tous les répertoires. Une demande ListObjectsV2 avec un delimiter extrait uniquement les entrées du répertoire spécifié par le paramètre prefix, ce qui réduit le temps de latence des demandes et augmente le nombre de clés agrégées par seconde. Pour les compartiments de répertoires, utilisez des opérations de listes délimitées dans la mesure du possible. Les listes délimitées permettent de réduire le nombre de visites des répertoires, ce qui se traduit par un nombre accru de clés par seconde et une latence plus faible des demandes.
Par exemple, pour les répertoires et objets suivants de votre compartiment de répertoires :
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
Pour de meilleures performances de ListObjectsV2, utilisez une liste délimitée pour répertorier vos sous-répertoires et vos objets, si la logique de votre application le permet. Par exemple, vous pouvez exécuter la commande suivante pour l’opération de liste délimitée :
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
La sortie est la liste des sous-répertoires.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
Pour mieux répertorier chaque sous-répertoire, vous pouvez exécuter une commande semblable à l’exemple suivant :
Commande :
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Sortie :
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Co-locate Stockage S3 Express One Zone avec vos ressources informatiques
Avec S3 Express One Zone, chaque compartiment de répertoires est stocké dans une zone de disponibilité unique que vous sélectionnez lorsque vous créez le compartiment. Vous pouvez commencer par créer un nouveau compartiment de répertoires dans une zone de disponibilité locale pour vos charges de travail ou vos ressources de calcul. Vous pouvez alors commencer immédiatement des opérations de lecture et d’écriture à très faible latence. Les compartiments de répertoire sont un type de compartiments S3 dans lesquels vous pouvez choisir la zone de disponibilité dans un Région AWS afin de réduire le temps de latence entre le calcul et le stockage.
Si vous accédez à des compartiments de répertoires dans différentes zones de disponibilité, vous risquez de constater une légère augmentation de la latence. Pour optimiser les performances, nous vous recommandons d’accéder à un compartiment de répertoires depuis des instances Amazon Elastic Container Service, Amazon Elastic Kubernetes Service et Amazon Elastic Compute Cloud situées dans la même zone de disponibilité, quand cela est possible.
Utiliser des connexions simultanées pour atteindre un débit élevé avec les objets de plus de 1 Mo
Vous pouvez optimiser les performances en adressant plusieurs demandes simultanées aux compartiments de répertoires pour répartir vos demandes sur des connexions distinctes et augmenter au maximum la bande passante accessible. À l’instar des compartiments à usage général, S3 Express One Zone n’impose aucune limite quant au nombre de connexions établies avec votre compartiment de répertoires. Les répertoires individuels peuvent mettre à l’échelle horizontalement et automatiquement les performances quand un grand nombre d’écritures simultanées sont effectuées dans le même répertoire.
Les connexions TCP aux compartiments de répertoires ont une limite supérieure fixe quant au nombre d’octets pouvant être chargés ou téléchargés par seconde. Lorsque les objets deviennent plus volumineux, les temps de requête sont davantage dominés par le streaming des octets que par le traitement des transactions. Afin d’utiliser plusieurs connexions pour paralléliser le chargement ou le téléchargement d’objets volumineux, vous pouvez réduire la latence de bout en bout. Si vous utilisez le kit Java 2.x SDK, vous devriez envisager d’utiliser le gestionnaire de transferts S3, qui tirera parti des améliorations de performances telles que les opérations d’API de chargement partitionné et les extractions par plage d’octets pour accéder aux données en parallèle.
Utiliser des points de terminaison d’un VPC de passerelle
Les points de terminaison de passerelle fournissent une connexion directe entre votre VPC et les compartiments de répertoires, sans nécessiter de passerelle Internet ou d’appareil NAT pour votre VPC. Pour réduire le temps que vos paquets passent sur le réseau, vous devez configurer votre VPC avec un point de terminaison d’un VPC de passerelle pour les compartiments de répertoires. Pour de plus amples informations, veuillez consulter Mise en réseau des compartiments de répertoires.
Utiliser l’authentification de session et réutiliser les jetons de session lorsqu’ils sont valides
Les compartiments de répertoires fournissent un mécanisme d’authentification par jeton de session pour réduire la latence lors des opérations d’API sensibles aux performances. Vous pouvez passer un seul appel à CreateSession pour obtenir un jeton de session, qui sera ensuite valide pour toutes les demandes pendant les cinq minutes suivantes. Pour réduire au minimum la latence de vos appels d’API, assurez-vous d’acquérir un jeton de session et de le réutiliser pendant toute sa durée de vie avant de l’actualiser.
Si vous utilisez AWS des SDK, les SDK gèrent automatiquement les actualisations des jetons de session afin d'éviter les interruptions de service à l'expiration d'une session. Nous vous recommandons d'utiliser les AWS SDK pour lancer et gérer les demandes relatives au fonctionnement de l'CreateSessionAPI.
Pour plus d’informations sur CreateSession, consultez Autorisation des opérations d’API de point de terminaison zonal avec CreateSession.
Utiliser un CRT-based client
Le AWS Common Runtime (CRT) est un ensemble de bibliothèques modulaires, performantes et efficaces écrites en C et destinées à servir de base aux AWS SDK. Le CRT offre un débit amélioré, une gestion optimisée des connexions et des temps de démarrage plus rapides. Le CRT est disponible via tous les AWS SDK sauf Go.
Pour plus d'informations sur la façon de configurer le CRT pour le SDK que vous utilisez, consultez les sections bibliothèques AWS Common Runtime (CRT), Accélérer le débit d'Amazon S3 avec le AWS Common Runtime
Utilisez la dernière version du AWS Kits SDK
Les AWS SDK fournissent une prise en charge intégrée de nombreuses directives recommandées pour optimiser les performances d'Amazon S3. Les kits SDK fournissent une API plus simple pour tirer parti d’Amazon S3 depuis une application. Ils sont régulièrement mis à jour pour suivre les bonnes pratiques les plus récentes. Par exemple, les kits SDK soumettent automatiquement des demandes de nouvelle tentative après des erreurs HTTP 503 et gèrent les réponses aux connexions lentes.
Si vous utilisez le Java 2.x SDK, vous devriez envisager d'utiliser le gestionnaire de transfert S3, qui redimensionne automatiquement les connexions horizontalement pour traiter des milliers de demandes par seconde en utilisant des requêtes par plage d'octets, le cas échéant. Byte-range les requêtes peuvent améliorer les performances car vous pouvez utiliser des connexions simultanées à S3 pour récupérer différentes plages d'octets au sein d'un même objet. Vous pouvez ainsi parvenir au regroupement de débits le plus élevé, par opposition à une seule demande d’objet entier. Il est donc important d'utiliser la dernière version des AWS SDK pour obtenir les dernières fonctionnalités d'optimisation des performances.
Dépannage des performances
Configurez-vous des demandes de nouvelle tentative pour les applications sensibles à la latence ?
La classe S3 Express One Zone est spécialement conçue pour fournir des niveaux élevés constants de performances sans réglages supplémentaires. Toutefois, la définition de valeurs de délai d’attente et de nouvelles tentatives agressives contribue également à garantir une latence et des performances constantes. Les AWS SDK ont des valeurs de délai d'expiration et de nouvelle tentative configurables que vous pouvez ajuster en fonction des tolérances de votre application spécifique.
Utilisez-vous AWS Des bibliothèques CRT (Common Runtime) et des types d'instances Amazon EC2 optimaux ?
Les applications qui effectuent un grand nombre d’opérations de lecture et d’écriture ont probablement besoin de plus de mémoire et de capacité de calcul que les autres. Lorsque vous lancez vos instances Amazon Elastic Compute Cloud (Amazon EC2) pour votre charge de travail exigeante en performances, choisissez les types d’instances qui disposent de la quantité de ces ressources dont votre application a besoin. Le stockage hautes performances S3 Express One Zone est idéalement associé à des types d’instances plus grands et plus récents, dotés d’une plus grande quantité de mémoire système et de CPU et GPU plus puissants, qui peuvent tirer parti d’un stockage plus performant. Nous recommandons également d'utiliser les dernières versions des CRT-enabled AWS SDK, qui permettent de mieux accélérer les requêtes de lecture et d'écriture en parallèle.
Utilisez-vous AWS Des SDK pour l'authentification basée sur les sessions ?
Avec Amazon S3, vous pouvez également optimiser les performances lorsque vous utilisez des requêtes d'API HTTP REST en suivant les mêmes bonnes pratiques que celles incluses dans les AWS SDK. Toutefois, compte tenu du mécanisme d'autorisation et d'authentification basé sur les sessions utilisé par S3 Express One Zone, nous vous recommandons vivement d'utiliser les AWS SDK pour gérer CreateSession et son jeton de session géré. Les AWS SDK créent et actualisent automatiquement les jetons en votre nom à l'aide de l'opération CreateSession API. Utilisation d'CreateSessionéconomies sur le temps de latence aller-retour par demande vers Gestion des identités et des accès AWS (IAM) pour autoriser chaque demande.
Exemples d’opérations sur des compartiments de répertoires et d’interactions avec les répertoires
Voici trois exemples illustrant le fonctionnement des compartiments de répertoires.
Exemple 1 : interaction de demandes S3 PutObject adressées à un compartiment de répertoires avec les répertoires
-
Lorsque l’opération
PUT(<bucket>, "documents/reports/quarterly.txt")est exécutée dans un compartiment vide, le répertoiredocuments/situé à la racine du compartiment est créé, le répertoirereports/dansdocuments/est créé, et l’objetquarterly.txtdansreports/est créé. Pour cette opération, deux répertoires ont été créés en plus de l’objet.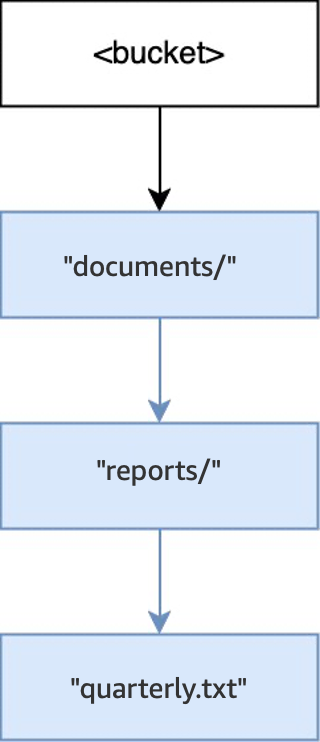
-
Ensuite, lorsqu’une autre opération
PUT(<bucket>, "documents/logs/application.txt")est exécutée, le répertoiredocuments/existe déjà, le répertoirelogs/dansdocuments/n’existe pas et est créé, et l’objetapplication.txtdanslogs/est créé. Pour cette opération, un seul répertoire a été créé en plus de l’objet.
-
Enfin, lorsqu’une opération
PUT(<bucket>, "documents/readme.txt")est exécutée, le répertoiredocuments/situé à la racine existe déjà et l’objetreadme.txtest créé. Pour cette opération, aucun répertoire n’est créé.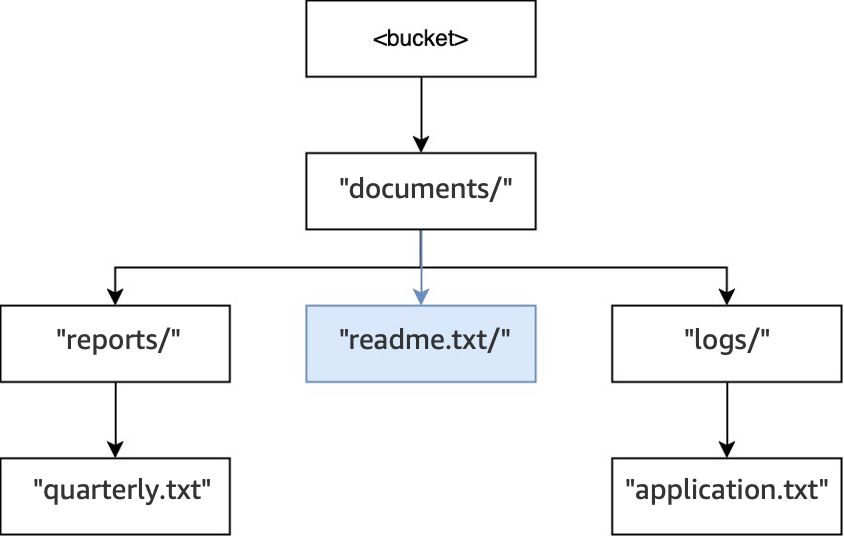
Exemple 2 : Comment les requêtes S3 ListObjectsV2 adressées à un compartiment de répertoire interagissent avec les répertoires
Pour les demandes S3 ListObjectsV2 sans délimiteur, un compartiment est parcouru en profondeur. Les sorties sont renvoyées dans un ordre cohérent. Cependant, bien qu’il reste identique entre les demandes, cet ordre n’est pas lexicographique. Pour le compartiment et les répertoires créés dans l’exemple précédent :
-
Lorsqu’un
LIST(<bucket>)est exécuté, le répertoiredocuments/est saisi et le parcours commence. -
Le sous-répertoire
logs/est saisi et le parcours commence. -
L’objet
application.txtest trouvé danslogs/. -
Il n’existe aucune autre entrée dans
logs/. L’opération Liste sort delogs/, puis entre à nouveau dansdocuments/. -
Le répertoire
documents/continue d’être parcouru et l’objetreadme.txtest trouvé. -
Le répertoire
documents/continue d’être parcouru, le sous-répertoirereports/est saisi et le parcours commence. -
L’objet
quarterly.txtest trouvé dansreports/. -
Il n’existe aucune autre entrée dans
reports/. L’opération Liste sort dereports/, puis entre à nouveau dansdocuments/. -
Il n’existe aucune autre entrée dans
documents/et l’opération Liste revient.
Dans cet exemple, logs/ est classé avant readme.txt, et readme.txt avant reports/.
Exemple 3 : interaction de demandes S3 DeleteObject adressées à un compartiment de répertoires avec les répertoires
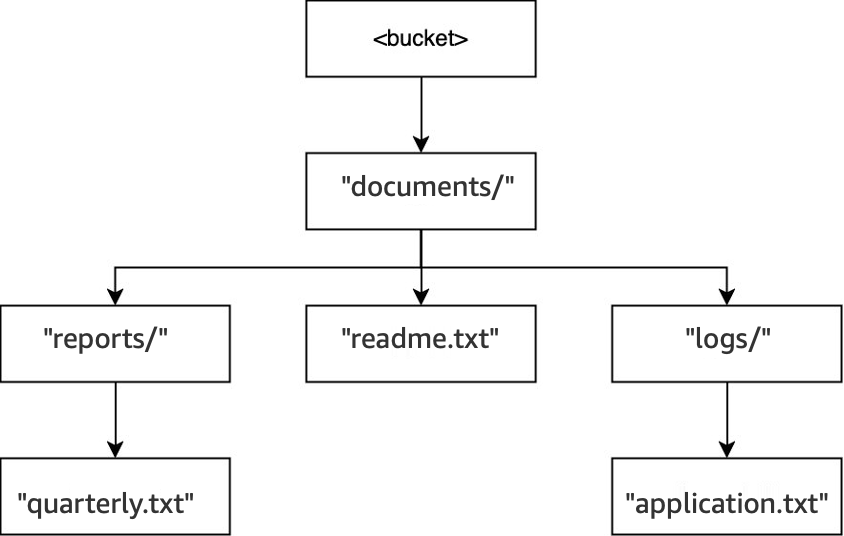
-
Dans ce même compartiment, lorsque l’opération
DELETE(<bucket>, "documents/reports/quarterly.txt")est exécutée, l’objetquarterly.txtest supprimé, laissant le répertoirereports/vide, ce qui entraîne sa suppression immédiate. Le répertoiredocuments/n’est pas vide, car il contient le répertoirelogs/et l’objetreadme.txt. Il n’est donc pas supprimé. Pour cette opération, un seul objet et un seul répertoire ont été supprimés.
-
Lorsque l’opération
DELETE(<bucket>, "documents/readme.txt")est exécutée, l’objetreadme.txtest supprimé. Le répertoiredocuments/n’est toujours pas vide, car il contient le répertoirelogs/. Il n’est donc pas supprimé. Pour cette opération, aucun répertoire n’est supprimé. Seul l’objet l’est.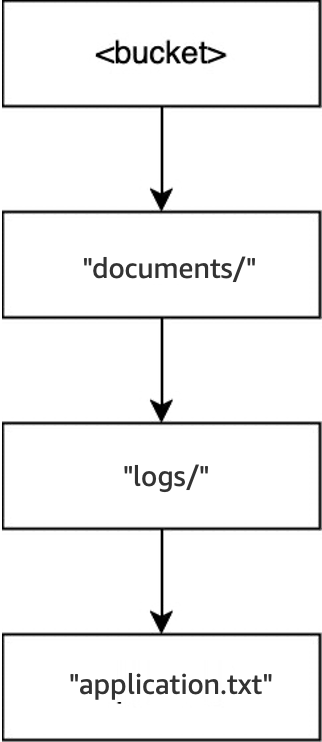
-
Enfin, lorsque l’opération
DELETE(<bucket>, "documents/logs/application.txt")est exécutée, l’objetapplication.txtest supprimé, laissant le sous-répertoirelogs/vide, ce qui entraîne sa suppression immédiate. Le répertoiredocuments/est alors vide et immédiatement supprimé. Pour cette opération, deux répertoires et un objet sont supprimés. Le compartiment est maintenant vide.
