Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’Auto Scaling pour AWS Glue
Autoscaling est disponible pour vos tâches ETL, de sessions interactives et de streaming AWS Glue avec la version 3.0 d’AWS Glue ou une version plus récente.
Lorsque Auto Scaling est activé, vous bénéficiez des avantages suivants :
-
AWS Glue ajoute et supprime automatiquement les employés du cluster en fonction du parallélisme à chaque étape ou micro-lot de la tâche exécutée.
-
Il réduit le besoin pour vous d’expérimenter et de décider du nombre d’employés à affecter à vos tâches AWS Glue ETL.
-
Avec le nombre maximal de travailleurs donné, AWS Glue choisira les ressources de taille appropriée pour la charge de travail.
-
Vous pouvez voir comment la taille du cluster change pendant l'exécution de la tâche en consultant les CloudWatch indicateurs sur la page de détails de l'exécution de la tâche dans AWS Glue Studio.
Autoscaling pour les tâches AWS Glue ETL et de streaming permet une augmentation et une réduction horizontales à la demande des ressources de calcul de vos tâches AWS Glue. L'augmentation d'échelle à la demande vous aide à allouer uniquement les ressources de calcul requises initialement au démarrage de l'exécution de la tâche, ainsi qu'à allouer les ressources requises en fonction de la demande pendant la tâche.
Autoscaling prend également en charge la réduction horizontale dynamique des ressources de la tâche AWS Glue pendant le déroulement d’une tâche. Au cours de l'exécution d'une tâche, lorsque plus d'exécuteurs sont demandés par votre application Spark, plus d'employés seront ajoutés au cluster. Lorsque l'exécuteur est inactif sans tâches de calcul actives, il sera supprimé de même que l'employé correspondant.
Les scénarios courants dans lesquels Autoscaling contribue à réduire les coûts et l’utilisation de vos applications Spark incluent :
-
un pilote Spark répertoriant un grand nombre de fichiers dans Amazon S3 ou effectuant un chargement alors que les exécuteurs sont inactifs ;
-
des étapes Spark exécutées avec seulement quelques exécuteurs en raison d’un surprovisionnement ;
-
des distorsions de données ou une demande de calcul inégale entre les étapes Spark.
Exigences
Auto Scaling n’est disponible que pour la version 3.0 ou ultérieure de AWS Glue. Pour utiliser Auto Scaling, vous pouvez suivre le guide de migration afin de migrer vos tâches existantes vers la version 3.0 ou ultérieure de AWS Glue ou de créer de nouvelles tâches avec la version 3.0 ou ultérieure de AWS Glue.
Autoscaling est disponible pour les tâches AWS Glue ayant les types de travailleurs G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, R.8X ou G.025X (uniquement pour les tâches Streaming). DPUs Les standards ne sont pas pris en charge pour Auto Scaling.
Activation d’Auto Scaling dans AWS Glue Studio
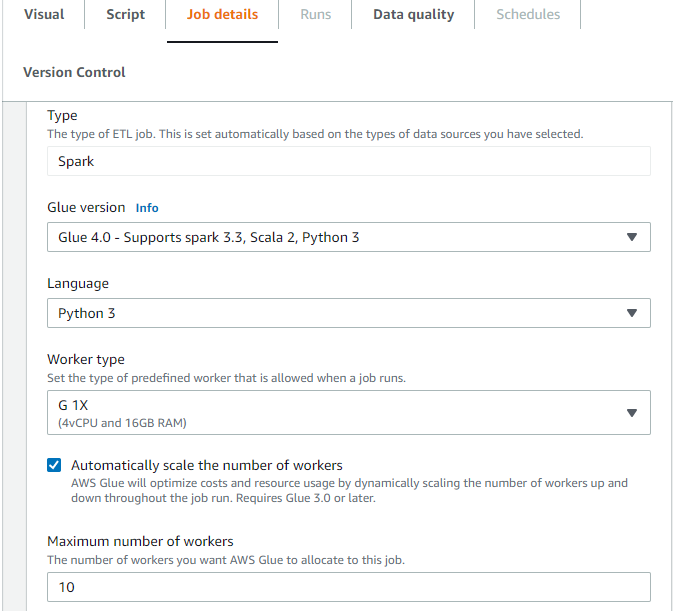
Dans l’onglet Informations de la tâche d’AWS Glue Studio, choisissez le type Spark ou Spark Streaming, et dans le champ Version de Glue, choisissez Glue 3.0 ou version ultérieure. Ensuite, une case à cocher apparaît sous Type de travailleur.
-
Sélectionnez l’option Automatically scale the number of workers (Mise à l’échelle automatique du nombre d’employés).
-
Configurez le Nombre maximal d’employés pour définir le nombre maximal d’employés pouvant être transférés à l’exécution de la tâche.
Activation de l'Auto Scaling avec la AWS CLI ou le SDK
Pour activer Auto Scaling à partir de la AWS CLI pour l'exécution de votre tâche, exécutez start-job-run la configuration suivante :
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
Une fois l’exécution de la tâche ETL terminée, vous pouvez également appeler get-job-run pour vérifier l’utilisation réelle des ressources de la tâche exécutée en secondes DPU. Remarque : le nouveau champ n'DPUSecondsapparaîtra que pour vos tâches par lots dans la AWS Glue version 4.0 ou ultérieure activée avec Auto Scaling. Ce champ n’est pas pris en charge pour les tâches de streaming.
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
Vous pouvez également configurer des exécutions de tâches avec Auto Scaling à l’aide du kit SDK AWS Glue en suivant la même configuration.
Activation d’Autoscaling avec des sessions interactives
Pour activer Auto Scaling lors de la création de AWS Glue tâches avec des sessions interactives, consultez la section Configuration des sessions AWS Glue interactives.
Conseils et considérations
Conseils et points à prendre en compte pour peaufiner AWS Glue Auto Scaling :
-
Si vous n'avez aucune idée de la valeur initiale du nombre maximum de travailleurs, vous pouvez commencer par le calcul approximatif expliqué dans Estimation du AWS Glue DPU. Vous ne devez pas configurer de valeur extrêmement élevée dans le nombre maximum de travailleurs pour de très faibles volumes de données.
-
AWS Glue Auto Scaling configure
spark.sql.shuffle.partitionsetspark.default.parallelismse base sur le nombre maximum de DPU (calculé en fonction du nombre maximum de travailleurs et du type de travailleur) configurés sur la tâche. Si vous préférez la valeur fixe pour ces configurations, vous pouvez remplacer ces paramètres par les paramètres de tâche suivants :-
Clé :
--conf -
Value (Valeur) :
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
Pour les tâches de streaming, par défaut, la mise à l'échelle automatique AWS Glue ne s'effectue pas au sein de microlots et plusieurs microlots sont nécessaires pour lancer la mise à l'échelle automatique. Si vous souhaitez activer l’autoscaling dans le cadre de microlots, indiquez
--auto-scale-within-microbatch. Pour plus d’informations, consultez Job parameter reference.
Surveillance d'Auto Scaling à l'aide CloudWatch des métriques Amazon
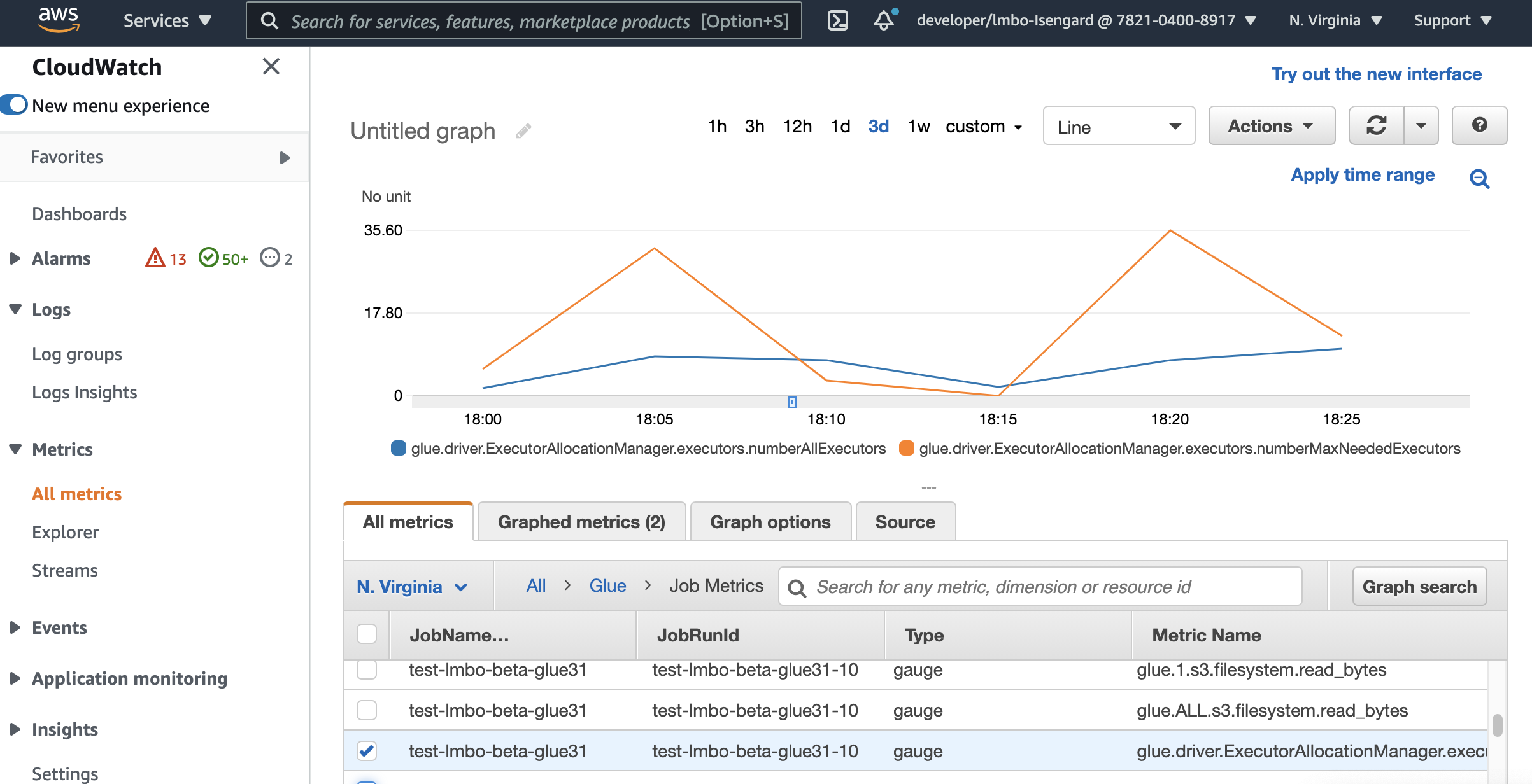
Les métriques de l' CloudWatch exécuteur sont disponibles pour vos tâches AWS Glue 3.0 ou ultérieures si vous activez Auto Scaling. Les métriques peuvent être utilisées pour contrôler la demande et l’utilisation optimisée des exécuteurs dans leurs applications Spark activées avec Auto Scaling. Pour de plus amples informations, veuillez consulter Surveillance AWS Glue à l'aide CloudWatch des métriques Amazon.
Vous pouvez également utiliser des indicateurs AWS Glue d'observabilité pour obtenir des informations sur l'utilisation des ressources. Par exemple, en surveillant glue.driver.workerUtilization, vous pouvez contrôler la quantité de ressources réellement utilisée avec ou sans autoscaling. Autre exemple, en surveillant glue.driver.skewness.job et glue.driver.skewness.stage, vous pouvez voir à quel point les données sont faussées. Ces informations vous aideront à décider d’activer l’autoscaling et d’optimiser les configurations. Pour plus d'informations, consultez la section Surveillance avecSurveillance à l'aide de métriques d'observabilité AWS Glue.
-
colle.driver. ExecutorAllocationManager.exécuteurs. numberAllExecutors
-
colle.driver. ExecutorAllocationManager.exécuteurs. numberMaxNeededExécuteurs
Pour en savoir plus sur ces métriques, consultez Surveillance de la planification des capacités de DPU.
Note
CloudWatch les métriques de l'exécuteur ne sont pas disponibles pour les sessions interactives.
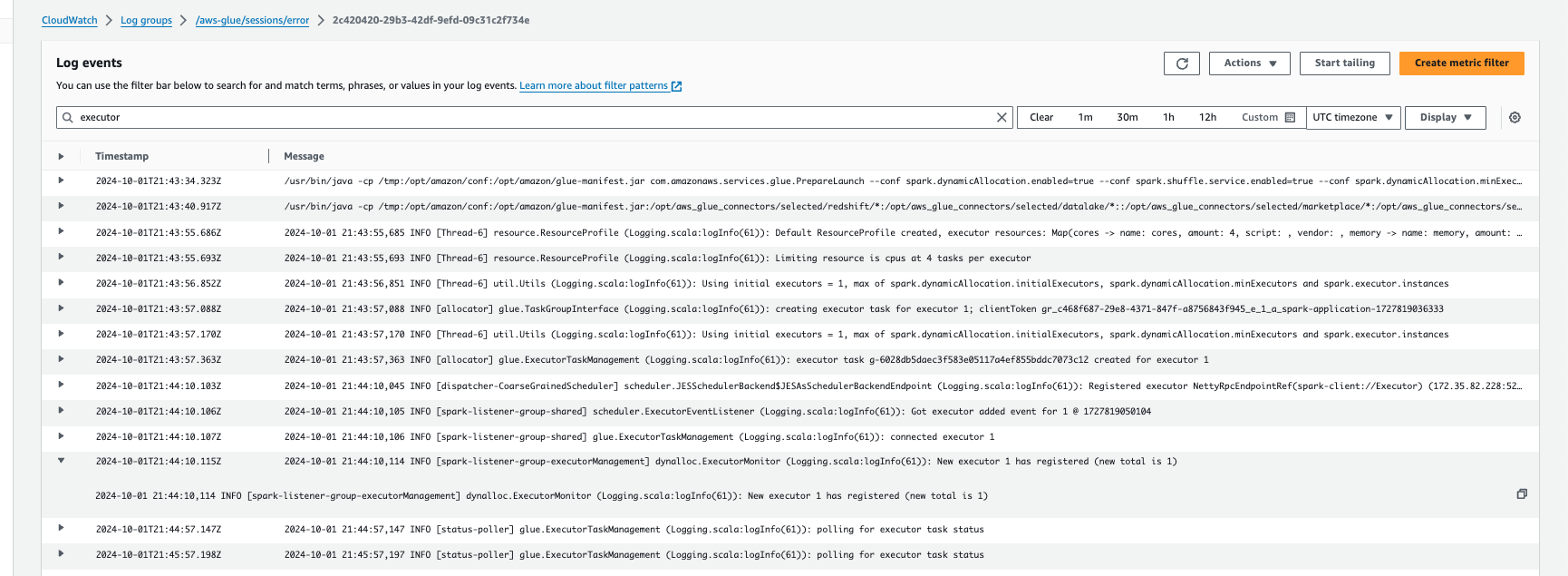
Surveillance de l'Auto Scaling avec Amazon CloudWatch Logs
Si vous utilisez des sessions interactives, vous pouvez surveiller le nombre d'exécuteurs en activant Amazon CloudWatch Logs en continu et en recherchant le terme « exécuteur » dans les journaux, ou en utilisant l'interface utilisateur Spark. Pour ce faire, utilisez la commande magique %%configure pour activer la journalisation continue avec enable auto scaling.
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
Dans les CloudWatch événements Amazon Logs, recherchez « exécuteur » dans les journaux :
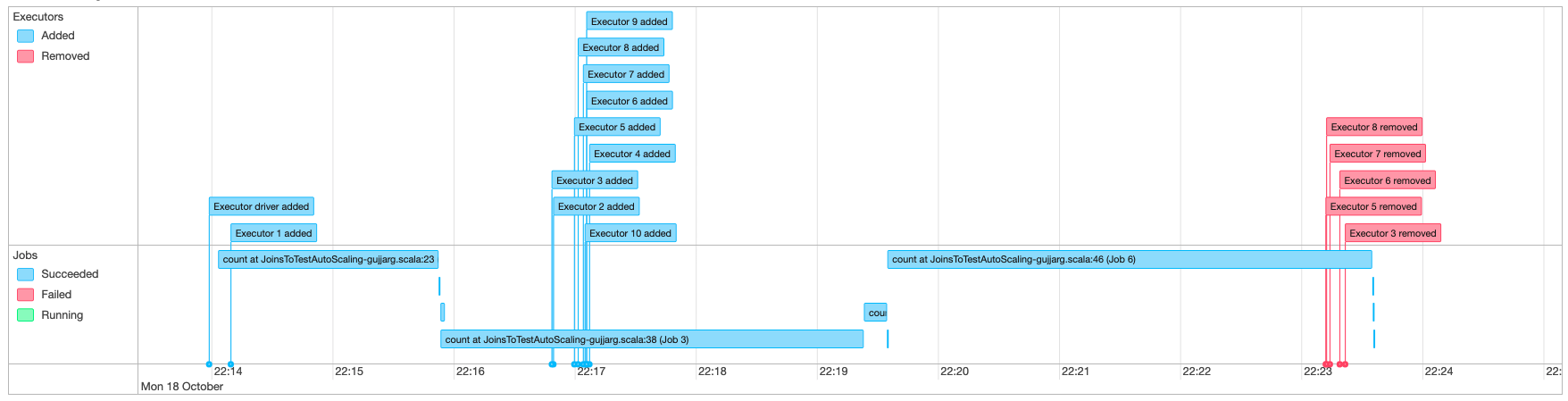
Surveillance de Auto Scaling avec Spark UI
Lorsqu’Auto Scaling est activé, vous pouvez également surveiller l’ajout et la suppression d’exécuteurs à l’aide de l’augmentation et de la réduction en fonction de la demande de vos tâches AWS Glue à l’aide de la Glue Spark UI. Pour de plus amples informations, veuillez consulter Activation de l’interface utilisateur web Apache Spark pour les tâches AWS Glue.
Lorsque vous utilisez des sessions interactives depuis le bloc-notes Jupyter, vous pouvez exécuter la commande magique suivante pour activer l’autoscaling avec l’interface utilisateur Spark :
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
Surveillance de l’utilisation du DPU d’exécution de la tâche Auto Scaling
Vous pouvez utiliser AWS Glue Studio Job run view pour vérifier l’utilisation du DPU de vos tâches Auto Scaling.
-
Choisissez Monitoring dans le volet AWS Glue Studio de navigation. La page Surveillance apparaît.
-
Faites défiler la page jusqu’à atteindre le graphique Exécutions de tâche.
-
Accédez à l’exécution de la tâche qui vous intéresse et faites défiler la page jusqu’à atteindre la colonne « heures » du DPU pour vérifier l’utilisation de l’exécution de la tâche spécifique.
Limitations
AWS Gluestreaming Auto Scaling ne prend actuellement pas en charge une DataFrame jointure de streaming avec une statique DataFrame créée en dehors deForEachBatch. Une statique DataFrame créée à l'intérieur du ForEachBatch fonctionnera comme prévu.
