Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des problèmes liés à l'IA générative pour Apache Spark dans AWS Glue
La résolution des problèmes liés à l'IA générative pour les tâches Apache Spark dans AWS Glue est une nouvelle fonctionnalité qui aide les ingénieurs de données et les scientifiques à diagnostiquer et à résoudre facilement les problèmes liés à leurs applications Spark. En utilisant les technologies de machine learning et d’IA générative, cette fonctionnalité analyse les problèmes liés aux tâches Spark et fournit une analyse détaillée des causes profondes, ainsi que des recommandations pratiques pour les résoudre. Le dépannage génératif de l'IA pour Apache Spark est disponible pour les jobs exécutés sur AWS Glue version 4.0 ou supérieure.
|
Transformez votre résolution des problèmes liés à Apache Spark grâce à notre agent de AI-powered résolution des problèmes, qui prend désormais en charge tous les principaux modes de déploiement, notamment AWS Glue EMR-EC2, Amazon, Amazon EMR-Serverless et Amazon SageMaker AI Notebooks. Ce puissant agent élimine les processus de débogage complexes en combinant des interactions en langage naturel, une analyse de la charge de travail en temps réel et des recommandations de code intelligent dans une expérience fluide. Pour plus de détails sur l'implémentation, reportez-vous à la section Qu'est-ce que l'agent de résolution des problèmes Apache Spark pour Amazon EMR ? Consultez la deuxième démonstration dans la section Exemples de résolution des problèmes liés à l'utilisation de l'agent de résolution des problèmes pour AWS Glue. |
Comment fonctionne la Résolution des problèmes à l’aide de l’IA générative pour Apache Spark ?
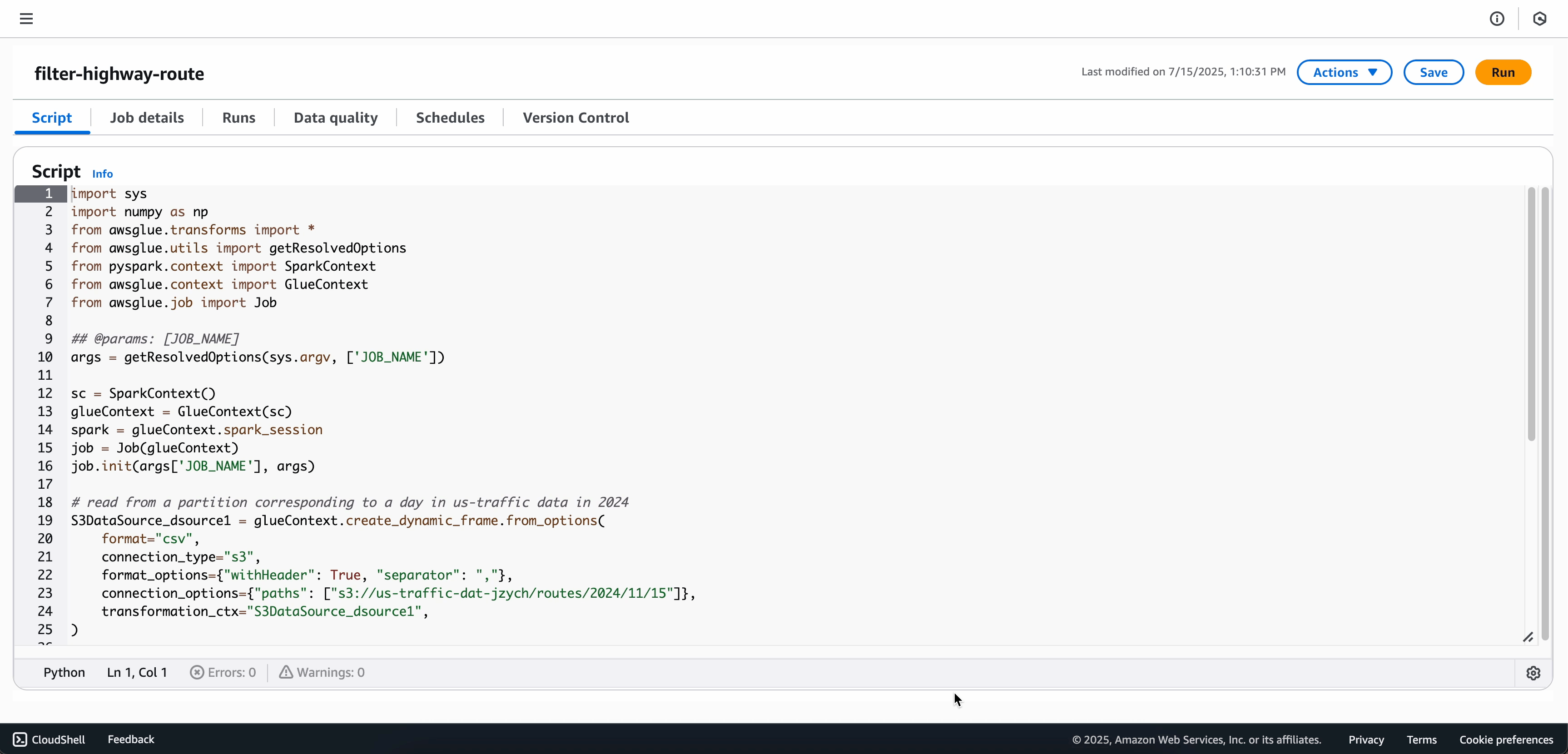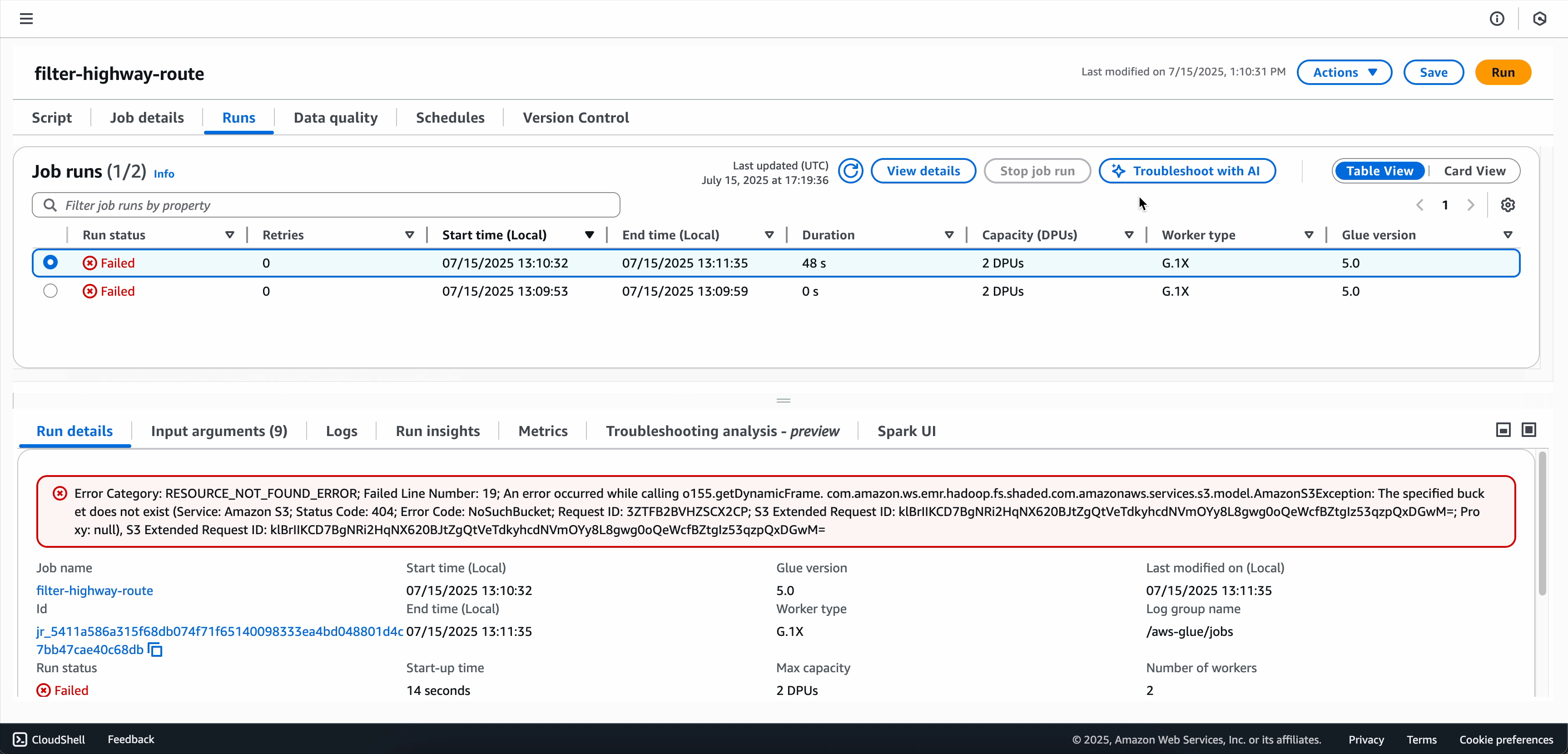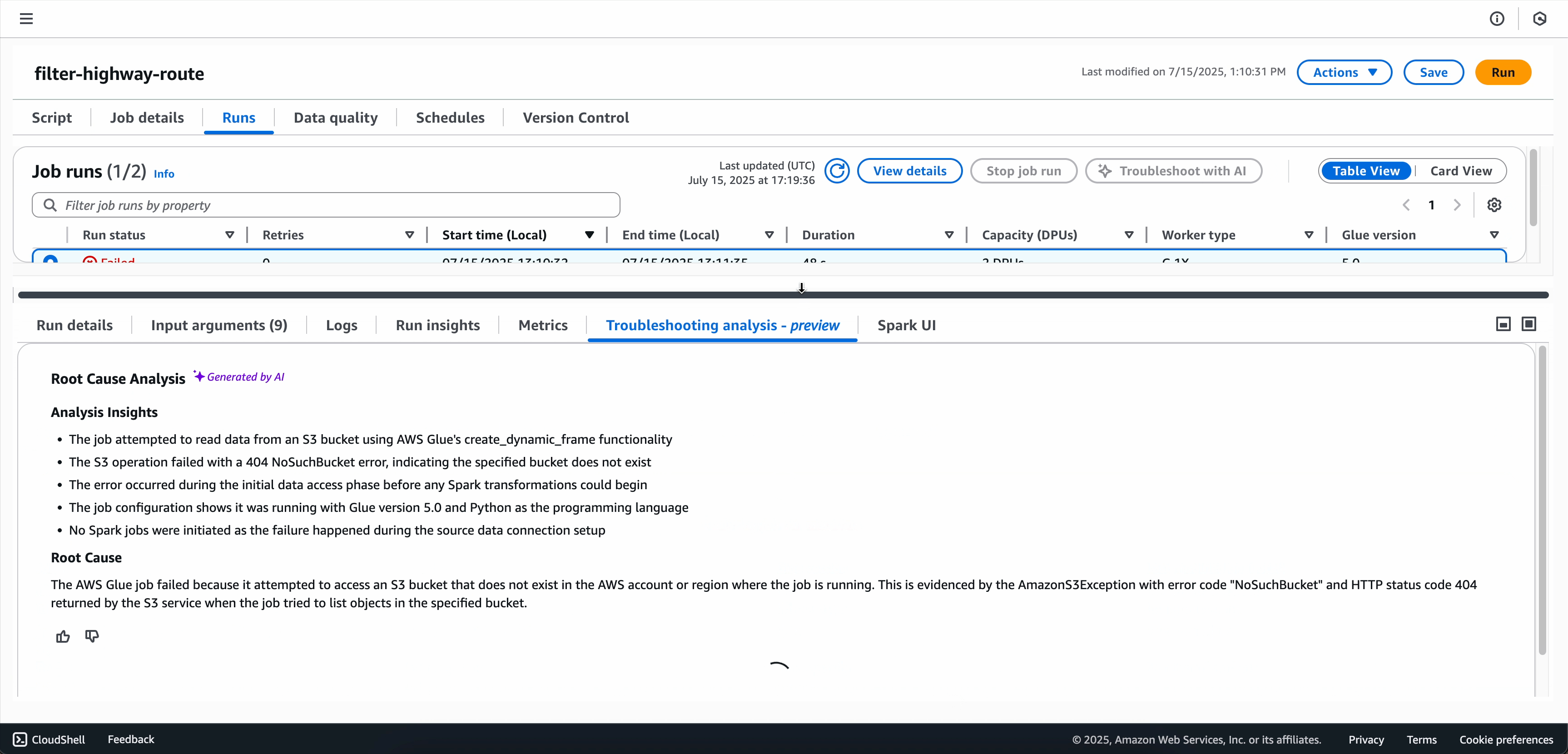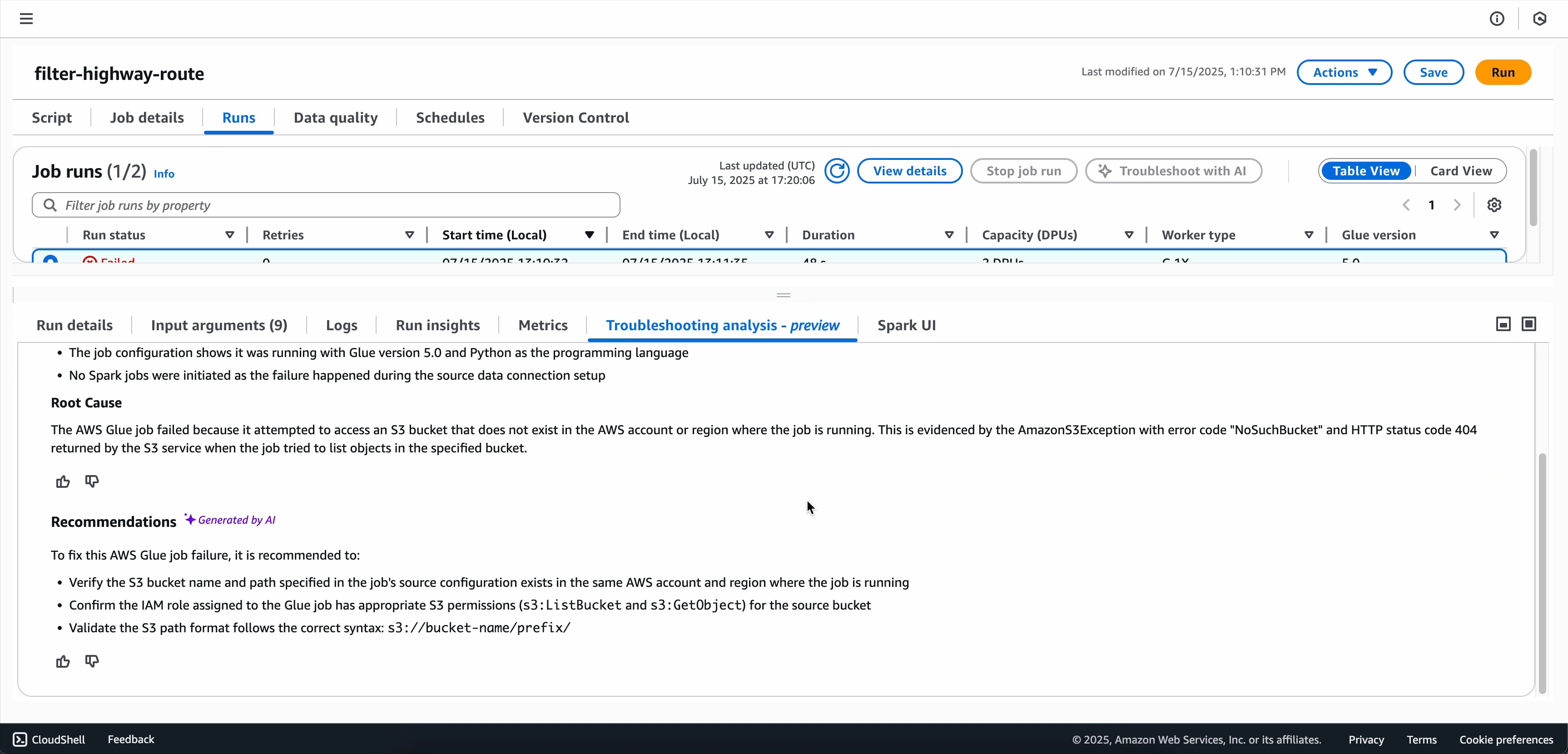
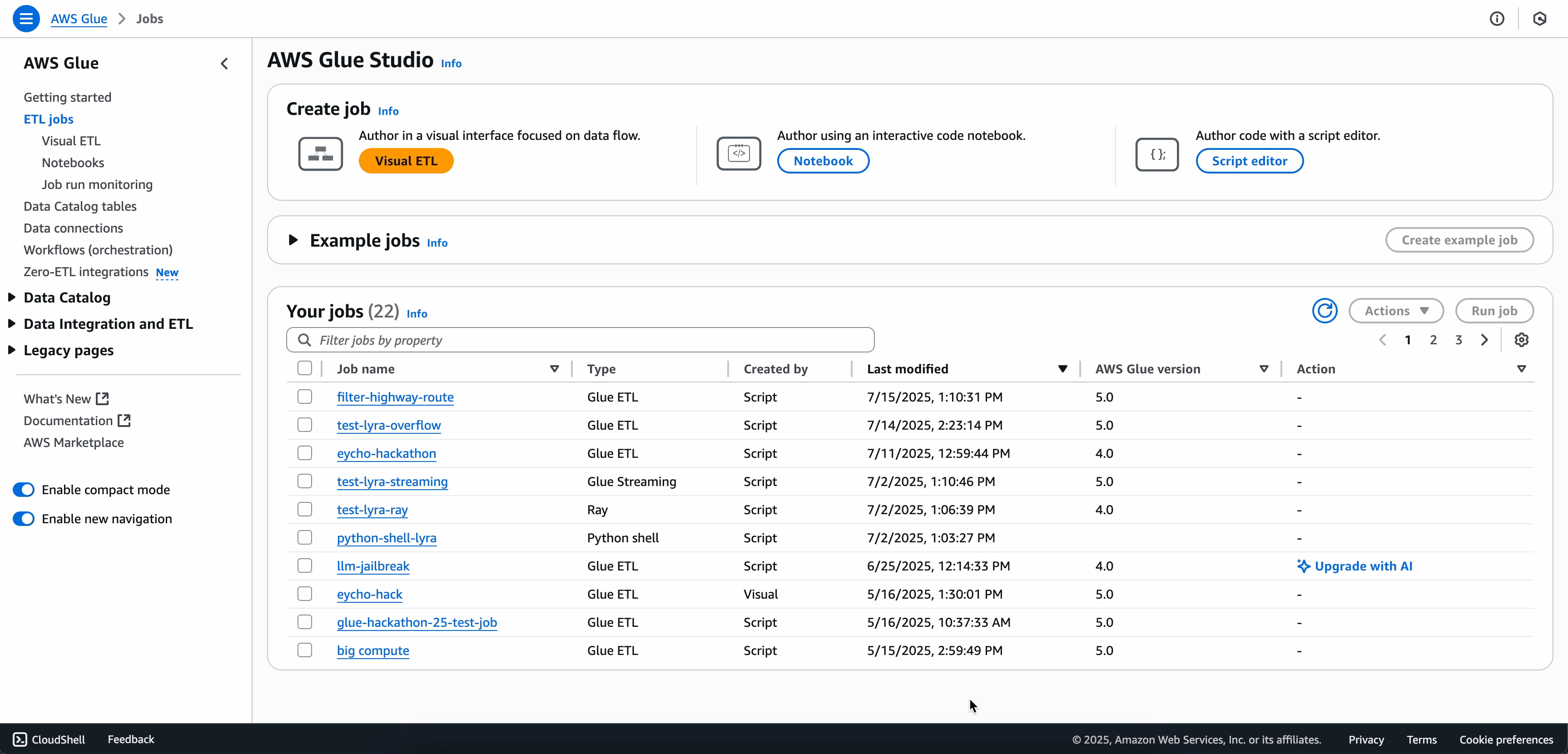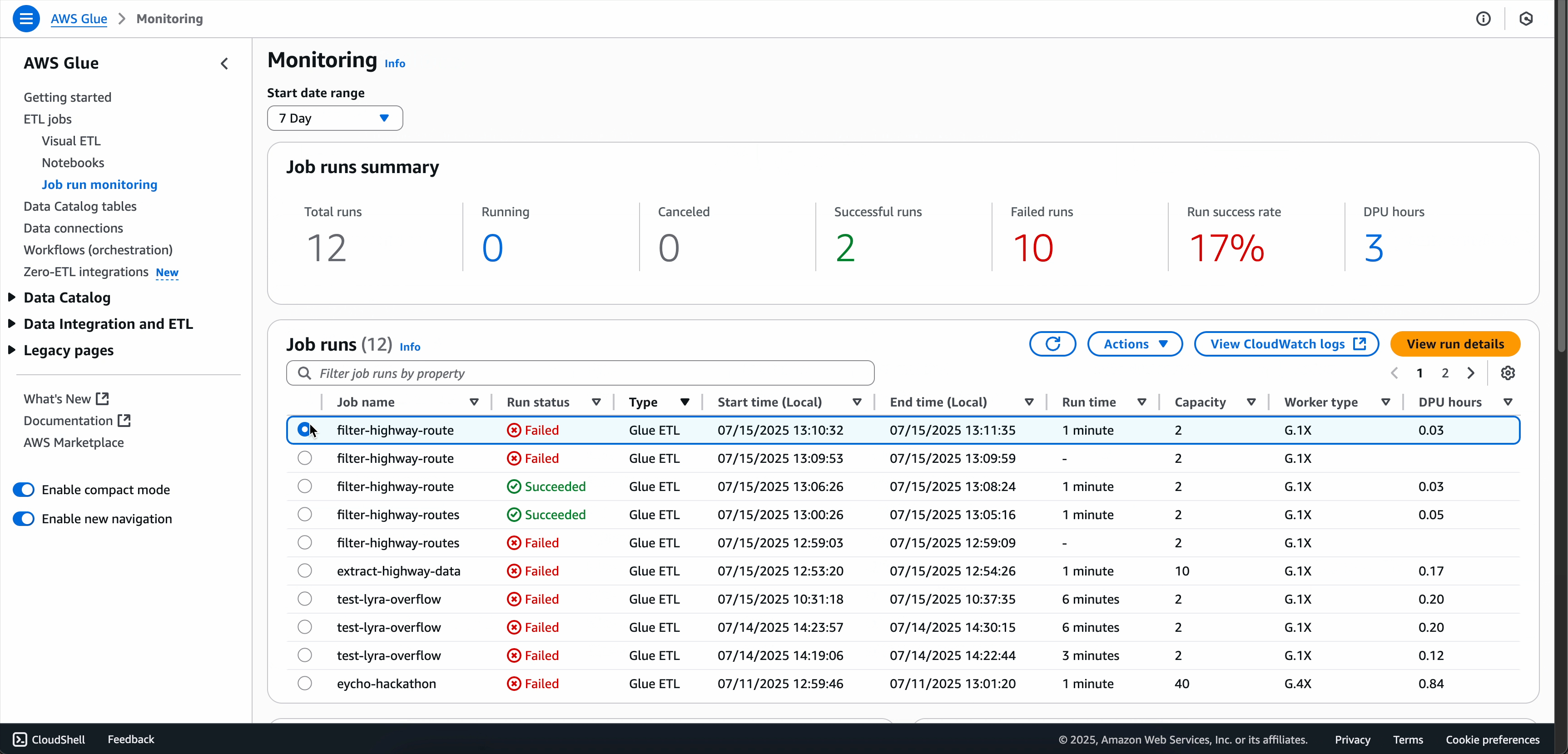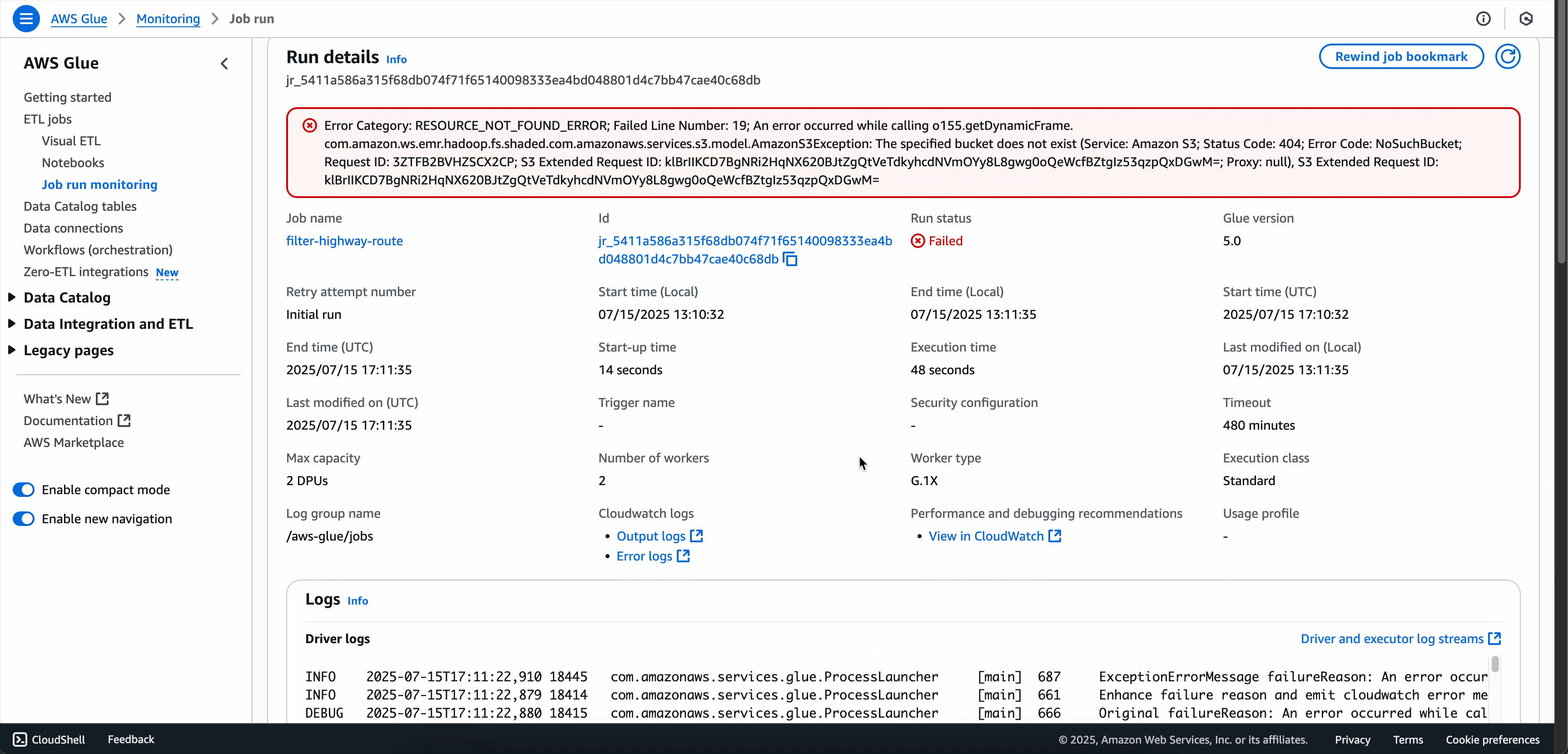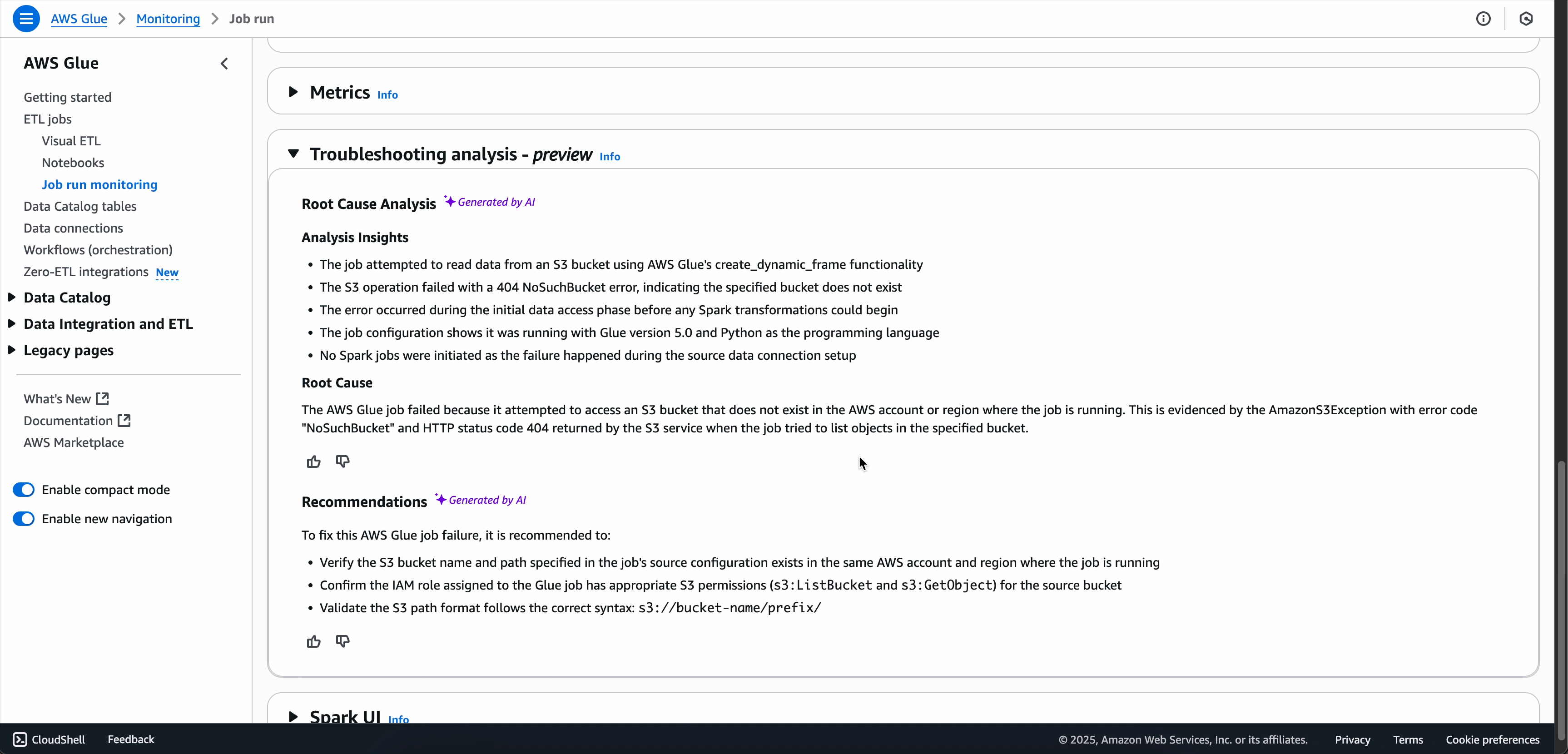
Pour les tâches Spark qui ont échoué, Generative AI Troubleshooting analyse les métadonnées des tâches ainsi que les indicateurs et journaux précis associés à la signature d'erreur de votre tâche afin de générer une analyse des causes premières, et recommande des solutions spécifiques et les meilleures pratiques pour aider à remédier aux échecs de tâches.
Configuration de la Résolution des problèmes à l’aide de l’IA générative pour Apache Spark pour vos tâches
Configuration des autorisations IAM
L'octroi d'autorisations aux API utilisées par Spark Troubleshooting pour vos tâches dans AWS Glue nécessite les autorisations IAM appropriées. Vous pouvez obtenir des autorisations en associant la AWS politique personnalisée suivante à votre identité IAM (comme un utilisateur, un rôle ou un groupe).
Note
Les deux API suivantes sont utilisées dans la politique IAM pour permettre cette expérience via la console AWS Glue Studio : StartCompletion etGetCompletion.
Attribution d’autorisations
Pour activer l’accès, ajoutez des autorisations à vos utilisateurs, groupes ou rôles :
-
Pour les utilisateurs et les groupes dans IAM Identity Center : créez un ensemble d’autorisations. Suivez les instructions de la rubrique Create a permission set du Guide de l’utilisateur IAM Identity Center.
-
Pour les utilisateurs gérés dans IAM via un fournisseur d’identité : créez un rôle pour la fédération d’identité. Pour plus d’informations, consultez Creating a role for a third-party identity provider (federation) dans le Guide de l’utilisateur IAM.
-
Pour les utilisateurs IAM : créez un rôel que votre utilisateur peut endosser. Suivez les instructions de la rubrique Creating a role for an IAM user du Guide de l’utilisateur IAM.
Exécution d’une analyse de résolution des problèmes suite à l’échec de l’exécution d’une tâche
Vous pouvez accéder à la fonctionnalité de résolution des problèmes via plusieurs chemins dans la console AWS Glue. Voici la procédure de démarrage :
Option 1 : depuis la page Liste des tâches
-
Ouvrez la console AWS Glue à l'adresse https://console.aws.amazon.com/glue/
. -
Dans le volet de navigation, sélectionnez Tâches ETL.
-
Recherchez votre tâche qui a échoué dans la liste des tâches.
-
Sélectionnez l’onglet Exécutions dans la section des informations de la tâche.
-
Cliquez sur la tâche qui a échoué et que vous souhaitez analyser.
-
Choisissez Résoudre les problèmes avec l’IA pour démarrer l’analyse.
-
Lorsque l’analyse de résolution des problèmes est terminée, vous pouvez consulter l’analyse des causes premières et les recommandations dans l’onglet Analyse de résolution des problèmes en bas de l’écran.
Option 2 : utilisation de la page Surveillance de l’exécution des tâches
-
Accédez à la page de Surveillance de l’exécution des tâches.
-
Localisez l’exécution de votre tâche qui a échoué.
-
Choisissez le menu déroulant Actions.
-
Choisissez Résoudre les problèmes avec l’IA.
Option 3 : depuis la page Détails de l’exécution des tâches
-
Accédez à la page de détails de l’exécution de la tâche qui a échoué en cliquant sur Afficher les détails d’une exécution échouée dans l’onglet Exécutions ou en sélectionnant l’exécution de la tâche sur la page Surveillance de l’exécution des tâches.
-
Sur la page des détails de l’exécution des tâches, recherchez l’onglet Analyse de dépannage.
Catégories de dépannage prises en charge
Ce service se concentre sur trois catégories principales de problèmes que les ingénieurs de données et les développeurs rencontrent fréquemment dans leurs applications Spark :
-
Erreurs de configuration et d'accès aux ressources : lors de l'exécution d'applications Spark dans AWS Glue, les erreurs de configuration des ressources et d'accès figurent parmi les problèmes les plus courants mais les plus difficiles à diagnostiquer. Ces erreurs se produisent souvent lorsque votre application Spark tente d'interagir avec AWS des ressources mais rencontre des problèmes d'autorisation, des ressources manquantes ou des problèmes de configuration.
-
Problèmes de mémoire liés au pilote et à l'exécuteur Spark : Memory-related les erreurs dans les tâches Apache Spark peuvent être complexes à diagnostiquer et à résoudre. Ces erreurs se produisent souvent lorsque vos exigences en matière de traitement des données dépassent les ressources de mémoire disponibles, que ce soit sur le nœud du pilote ou les nœuds d’exécuteur.
-
Problèmes de capacité du disque Spark : Storage-related les erreurs dans les tâches AWS Glue Spark apparaissent souvent lors d'opérations de remaniement, de fuite de données ou lors de transformations de données à grande échelle. Ces erreurs peuvent être particulièrement délicates, car elles peuvent ne pas se manifester avant que votre tâche ne soit en cours d’exécution pendant une certaine durée, ce qui peut entraîner une perte de temps et de ressources de calcul précieux.
-
Erreurs d'exécution des requêtes : les échecs de requête dans Spark SQL et les DataFrame opérations peuvent être difficiles à résoudre car les messages d'erreur peuvent ne pas indiquer clairement la cause première, et les requêtes qui fonctionnent correctement avec de petits ensembles de données peuvent soudainement échouer à grande échelle. Ces erreurs deviennent encore plus difficiles lorsqu'elles se produisent au cœur de pipelines de transformation complexes, où le véritable problème peut être dû à des problèmes de qualité des données survenus aux étapes précédentes plutôt qu'à la logique de requête elle-même.
Note
Avant de mettre en œuvre les modifications suggérées dans votre environnement de production, examinez-les attentivement. Le service fournit des recommandations basées sur des modèles et des bonnes pratiques, mais votre cas d’utilisation spécifique peut nécessiter des considérations supplémentaires.
Régions prises en charge
La résolution des problèmes liés à l'IA générative pour Apache Spark est disponible dans les régions suivantes :
-
Afrique : Le Cap (af-south-1)
-
Asie-Pacifique : Hong Kong (ap-east-1), Tokyo (ap-northeast-1), Séoul (ap-northeast-2), Osaka (ap-northeast-3), Mumbai (ap-south-1), Singapour (ap-southeast-1) ap-southeast-1), Sydney (ap-southeast-2) et Jakarta (ap-southeast-3)
-
Europe : Francfort (eu-central-1), Stockholm (eu-nord-1), Milan (eu-sud-1), Irlande (eu-west-1), Londres (eu-west-2) et Paris (eu-west-3)
-
Moyen-Orient : Bahreïn (me-south-1) et Émirats arabes unis (me-central-1)
-
Amérique du Nord : Canada (ca-central-1)
-
Amérique du Sud : São Paulo (sa-east-1)
-
États-Unis : Virginie du Nord (us-east-1), Ohio (us-east-2), Californie du Nord (us-west-1) et Oregon (us-west-2)
