Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Conception d’applications Lambda
Une application événementielle bien conçue utilise une combinaison de AWS services et de code personnalisé pour traiter et gérer les demandes et les données. Ce chapitre se concentre sur les sujets spécifiques à Lambda en matière de conception d’applications. Les architectes sans serveur doivent tenir compte de nombreuses considérations importantes lorsqu’ils conçoivent des applications pour des systèmes de production très sollicités.
Bon nombre des pratiques exemplaires applicables au développement de logiciels et aux systèmes distribués s’appliquent également au développement d’applications sans serveur. L’objectif global est de développer des charges de travail qui sont :
-
Fiables : offrez à vos utilisateurs finaux un haut niveau de disponibilité. Les services AWS sans serveur sont fiables, car ils sont également conçus pour résister aux défaillances.
-
Durables : offrez des options de stockage qui répondent aux besoins de durabilité de votre charge de travail.
-
Sécurisées : suivez les pratiques exemplaires et utilisez les outils fournis pour sécuriser l’accès aux charges de travail et limiter le rayon d’impact.
-
Performantes : utilisez les ressources informatiques avec efficacité et répondez aux besoins de performance de vos utilisateurs finaux.
-
Rentables : concevez des architectures qui évitent les coûts inutiles, qui peuvent se mettre à l’échelle sans dépenses excessives, et également être mises hors service sans frais généraux importants.
Les principes de conception suivants peuvent vous aider à créer des charges de travail répondant à ces objectifs. Tous les principes ne s’appliquent pas à toutes les architectures, mais ils devraient vous guider dans vos décisions générales en matière d’architecture.
Utilisation de services plutôt que de code personnalisé
Les applications sans serveur comprennent généralement plusieurs AWS services, intégrés à du code personnalisé exécuté dans les fonctions Lambda. Lambda peut être intégré à la plupart des AWS services, mais les services les plus couramment utilisés dans les applications sans serveur sont les suivants :
| Catégorie | AWS service |
|---|---|
|
Calcul |
AWS Lambda |
|
Stockage de données |
Amazon S3 Amazon DynamoDB Amazon RDS |
|
API |
Amazon API Gateway |
|
Intégration d’applications |
Amazon EventBridge Amazon SNS Amazon SQS |
|
Orchestration |
Fonctions durables Lambda AWS Step Functions |
|
Données de streaming et analytique |
Amazon Data Firehose |
Note
De nombreux services sans serveur fournissent la réplication et la prise en charge de plusieurs régions, notamment DynamoDB et Amazon S3. Les fonctions Lambda peuvent être déployées dans plusieurs régions dans le cadre d’un pipeline de déploiement, et API Gateway peut être configurée pour prendre en charge cette configuration. Consultez cet exemple d’architecture
Il existe de nombreux modèles courants bien établis dans les architectures distribuées que vous pouvez créer vous-même ou implémenter à l'aide de AWS services. Pour la plupart des clients, le développement de ces modèles à partir de zéro présente peu d’intérêt commercial. Lorsque votre application a besoin de l'un de ces modèles, utilisez le AWS service correspondant :
| Modèle | AWS service |
|---|---|
|
File d’attente |
Amazon SQS |
|
Bus d’événement |
Amazon EventBridge |
|
Publication-abonnement (diffusion en éventail) |
Amazon SNS |
|
Orchestration |
Fonctions durables Lambda AWS Step Functions |
|
API |
Amazon API Gateway |
|
Flux d’événement |
Amazon Kinesis |
Ces services sont conçus pour s’intégrer à Lambda et vous pouvez utiliser l’infrastructure en tant que code (IaC) pour créer et supprimer des ressources dans les services. Vous pouvez utiliser n’importe lequel de ces services via le kit SDK AWS
Présentation des niveaux d’abstraction Lambda
Le service Lambda limite votre accès aux systèmes d’exploitation, aux hyperviseurs et au matériel sous-jacents qui exécutent vos fonctions Lambda. Le service améliore et modifie continuellement l’infrastructure afin d’ajouter des fonctionnalités, de réduire les coûts et de rendre le service plus performant. Votre code ne doit émettre aucune hypothèse quant à l’architecture de Lambda et à l’affinité matérielle.
De même, les intégrations de Lambda avec d'autres services sont gérées par AWS, et seul un petit nombre d'options de configuration vous sont proposées. Par exemple, quand API Gateway et Lambda interagissent, il n’y a aucun concept d’équilibrage de charge, puisqu’il est entièrement géré par les services. Vous n’avez également aucun contrôle direct sur les zones de disponibilité
Cette abstraction vous aide à vous concentrer sur les aspects d’intégration de votre application, le flux de données et la logique métier dans laquelle votre charge de travail apporte de la valeur à vos utilisateurs finaux. En permettant aux services de gérer les mécanismes sous-jacents, vous pouvez développer des applications plus rapidement avec moins de code personnalisé à gérer.
Implémenter l’absence d’état dans les fonctions
Pour les fonctions Lambda standard, vous devez partir du principe que l'environnement n'existe que pour un seul appel. La fonction doit initialiser tout état requis lors de son premier démarrage. Par exemple, votre fonction peut nécessiter de récupérer des données dans une table DynamoDB. Elle doit valider toute modification permanente des données sur un magasin durable tel qu’Amazon S3, DynamoDB ou Amazon SQS avant de quitter. Elle ne doit pas s’appuyer sur des structures de données ou des fichiers temporaires existants, ni sur un état interne qui serait géré par de multiples invocations.
Lorsque vous utilisez Durable Functions, l'état est automatiquement préservé entre les appels, ce qui élimine le besoin de le conserver manuellement sur le stockage externe. Cependant, vous devez toujours suivre les principes de l'apatridie pour toutes les données qui ne sont pas explicitement gérées par le biais du DurableContext.
Pour initialiser les connexions aux bases de données et les bibliothèques, ou pour initialiser l’état de chargement, vous pouvez tirer parti de l’initialisation statique. Les environnements d’exécution étant réutilisés dans la mesure du possible pour améliorer les performances, vous pouvez amortir le temps nécessaire à l’initialisation de ces ressources sur plusieurs invocations. Cependant, vous ne devez stocker aucune variable ou donnée utilisée dans la fonction dans cette portée globale.
Minimiser le couplage
La plupart des architectures devraient préférer les fonctions plus nombreuses et plus petites aux fonctions moins nombreuses et plus grandes. Le but de chaque fonction doit être de gérer l’événement transmis à la fonction, sans aucune connaissance ni attente quant au flux de travail global ou au volume des transactions. Cela rend la fonction indépendante de la source de l’événement avec un couplage minimal avec les autres services.
Toutes les constantes de portée globale qui changent rarement doivent être implémentées en tant que variables d’environnement afin de permettre les mises à jour sans déploiement. Tous les secrets ou informations sensibles doivent être stockés dans AWS Systems Manager Parameter Store ou dans AWS Secrets Manager
Générer des données à la demande plutôt que pour des lots
De nombreux systèmes traditionnels sont conçus pour fonctionner périodiquement et traiter des lots de transactions accumulés au fil du temps. Par exemple, une application bancaire peut s’exécuter toutes les heures pour traiter les transactions des guichets automatiques dans des registres centraux. Dans les applications basées sur Lambda, le traitement personnalisé doit être déclenché par chaque événement, ce qui permet au service d’augmenter verticalement la simultanéité selon les besoins, afin de fournir un traitement des transactions en temps quasi réel.
Alors que les fonctions Lambda standard sont limitées à 15 minutes d'exécution, les fonctions durables peuvent fonctionner jusqu'à un an, ce qui les rend adaptées aux besoins de traitement de longue durée. Cependant, vous devez toujours préférer le traitement piloté par les événements au traitement par lots lorsque cela est possible.
Bien que vous puissiez exécuter des tâches cron
Par exemple, il n’est pas recommandé d’utiliser un traitement par lots qui déclenche une fonction Lambda pour récupérer une liste de nouveaux objets Amazon S3. Cela est dû au fait que le service peut recevoir plus de nouveaux objets entre les lots que ce qui peut être traité dans le cadre d’une fonction Lambda de 15 minutes.
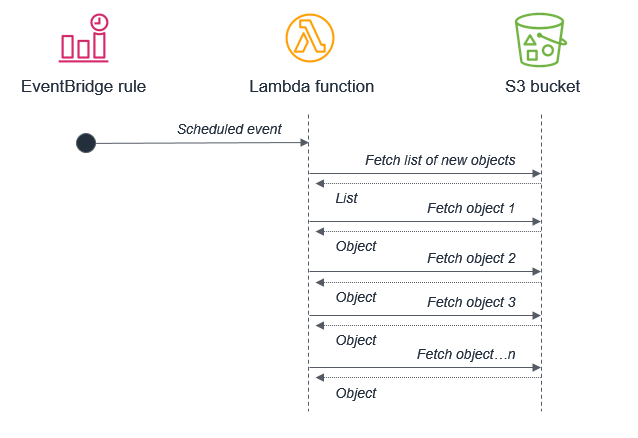
Amazon S3 doit plutôt invoquer la fonction Lambda chaque fois qu’un nouvel objet est placé dans le compartiment. Cette démarche est bien plus facile à mettre à l’échelle et fonctionne en temps quasi réel.
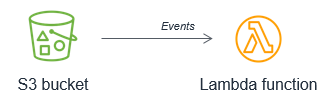
Choisissez une option d'orchestration pour les flux de travail complexes
Les flux de travail qui impliquent une logique de ramification, différents types de modèles d’échec et une logique de nouvelle tentative utilisent généralement un orchestrateur pour suivre l’état de l’exécution globale. Ne créez pas d'orchestration ad hoc dans les fonctions Lambda standard. Cela se traduit par un couplage étroit, un code de routage complexe et l'absence de restauration automatique de l'état.
Utilisez plutôt l'une de ces options d'orchestration spécialement conçues :
-
Fonctions Lambda durables : orchestration centrée sur les applications à l'aide de langages de programmation standard avec point de contrôle automatique, nouvelle tentative intégrée et reprise d'exécution. Idéal pour les développeurs qui préfèrent conserver la logique du flux de travail dans le code aux côtés de la logique métier dans Lambda.
-
AWS Step Functions: orchestration visuelle du flux de travail avec intégrations natives à plus de 220 AWS services. Idéal pour la coordination multiservices, les infrastructures sans maintenance et la conception visuelle des flux de travail.
Pour savoir comment choisir entre ces options, voir Durable functions ou Step Functions.
Avec Step Functions
Il est courant que les flux de travail simples dans les fonctions Lambda se complexifient au fil du temps. Lorsque vous utilisez une application de production sans serveur, il est important d'identifier le moment où cela se produit, afin de pouvoir migrer cette logique vers une machine à états ou une fonction durable.
Implémenter l’idempotence
AWS les services sans serveur, y compris Lambda, sont tolérants aux pannes et conçus pour gérer les défaillances. Par exemple, si un service invoque une fonction Lambda et qu’il y a une interruption de service, Lambda invoque votre fonction dans une autre zone de disponibilité. Si la fonction renvoie une erreur, Lambda relance l’invocation.
Comme le même événement peut être reçu plusieurs fois, les fonctions doivent être conçues pour être idempotentes
Vous pouvez implémenter l’idempotence dans les fonctions Lambda en utilisant une table DynamoDB pour suivre les identifiants récemment traités afin de déterminer si la transaction a déjà été traitée. La table DynamoDB implémente généralement une valeur de durée de vie (TTL) pour faire expirer les éléments afin de limiter l’espace de stockage utilisé.
Utiliser plusieurs AWS comptes pour gérer les quotas
De nombreux quotas de service AWS sont définis au niveau du compte. Cela signifie qu’à mesure que vous ajoutez de nouvelles charges de travail, vous pouvez rapidement épuiser vos limites.
Un moyen efficace de résoudre ce problème consiste à utiliser plusieurs AWS comptes, en consacrant chaque charge de travail à son propre compte. Cela empêche le partage des quotas avec d’autres charges de travail ou des ressources non liées à la production.
Par ailleurs, grâce à AWS Organizations
Une approche courante consiste à fournir un AWS compte à chaque développeur, puis à utiliser des comptes distincts pour la phase de déploiement et de production de la version bêta :
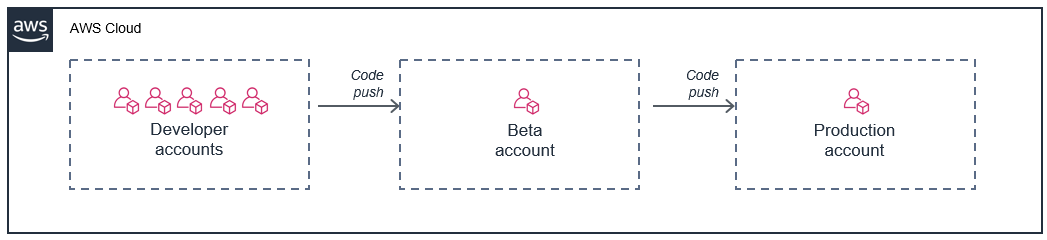
Dans ce modèle, chaque développeur a son propre ensemble de limites pour le compte, de sorte que leur utilisation n’a aucune incidence sur votre environnement de production. Cette approche permet également aux développeurs de tester les fonctions Lambda localement sur leurs machines de développement par rapport aux ressources cloud actives de leurs comptes individuels.
