Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Enrichissement sémantique automatique pour Serverless
Présentation de
La fonctionnalité d'enrichissement sémantique automatique peut aider à améliorer la pertinence de la recherche jusqu'à 20 % par rapport à la recherche lexicale. L'enrichissement sémantique automatique élimine le fardeau indifférencié lié à la gestion de votre propre infrastructure de modèles de ML (machine learning) et à l'intégration au moteur de recherche. La fonctionnalité est disponible pour les trois types de collection sans serveur : Search, Time Series et Vector.
Concepts de recherche sémantique
Les moteurs de recherche traditionnels s'appuient sur la correspondance mot à mot (appelée recherche lexicale) pour trouver les résultats des requêtes. Bien que cela fonctionne bien pour des requêtes spécifiques telles que les numéros de modèles de téléviseurs, il se peut que cela ne renvoie pas de résultats pertinents pour les recherches plus abstraites. Par exemple, lorsque vous recherchez « chaussures pour la plage », une recherche lexicale fait simplement correspondre les mots « chaussures », « plage », « pour » et « le » dans les articles du catalogue, ce qui peut entraîner l'absence de produits pertinents tels que « sandales imperméables » ou « chaussures de surf » qui ne contiennent pas les termes de recherche exacts.
La recherche sémantique renvoie des résultats de requête qui intègrent non seulement la correspondance des mots clés, mais aussi l'intention et le sens contextuel de la recherche de l'utilisateur. Par exemple, si un utilisateur recherche « comment traiter un mal de tête », un système de recherche sémantique peut renvoyer les résultats suivants :
-
Remèdes contre la migraine
-
Techniques de gestion de la douleur
-
Over-the-counter analgésiques
Détails du modèle et indice de performance
Bien que cette fonctionnalité gère les complexités techniques en arrière-plan sans dévoiler le modèle sous-jacent, la description du modèle et les résultats de référence suivants vous aident à prendre des décisions éclairées concernant l'adoption de fonctionnalités dans le cadre de vos charges de travail critiques.
L'enrichissement sémantique automatique utilise un modèle clairsemé pré-entraîné et géré par les services qui fonctionne efficacement sans nécessiter de réglage personnalisé. Le modèle analyse les champs que vous spécifiez et les développe en vecteurs épars basés sur des associations apprises à partir de diverses données d'entraînement. Les termes développés et leurs poids de signification sont stockés dans le format d'index Lucene natif pour une extraction efficace. Nous avons optimisé ce processus en utilisant le mode document uniquement,
La validation des performances lors du développement des fonctionnalités a utilisé le jeu de données de récupération de passages MS MARCO
-
Langue anglaise - Amélioration de la pertinence de 20 % par rapport à la recherche lexicale. Il a également réduit la latence de recherche P90 de 7,7 % par rapport à la recherche lexicale (BM25 est de 26 ms et l'enrichissement sémantique automatique est de 24 ms).
-
Multi-lingual - Amélioration de la pertinence de 105 % par rapport à la recherche lexicale, tandis que la latence de recherche P90 a augmenté de 38,4 % par rapport à la recherche lexicale (BM25 est de 26 ms et l'enrichissement sémantique automatique est de 36 ms).
Étant donné la nature unique de chaque charge de travail, vous pouvez évaluer cette fonctionnalité dans votre environnement de développement à l'aide de vos propres critères d'analyse comparative avant de prendre des décisions de mise en œuvre.
Langues prises en charge
La fonctionnalité prend en charge l'anglais. En outre, le modèle prend également en charge l'arabe, le bengali, le chinois, le finnois, le français, l'hindi, l'indonésien, le japonais, le coréen, le persan, le russe, l'espagnol, le swahili et le télougou.
Configurer un index d'enrichissement sémantique automatique pour les collections sans serveur
Vous pouvez configurer un index avec un enrichissement sémantique automatique activé pour vos champs de texte via la console, les API et les CloudFormation modèles lors de la création d'un nouvel index. Pour l'activer pour un index existant, vous devez recréer l'index en activant l'enrichissement sémantique automatique pour les champs de texte.
La AWS console vous permet de créer un index avec des champs d'enrichissement sémantique automatique. Après avoir sélectionné une collection, vous pouvez trouver le bouton Créer un index en haut de la console. Une fois que vous avez sélectionné Créer un index, la console propose des options permettant de définir des champs d'enrichissement sémantique automatique. Dans un index, vous pouvez combiner l'enrichissement sémantique automatique pour l'anglais et le multilingue, ainsi que des champs lexicaux.
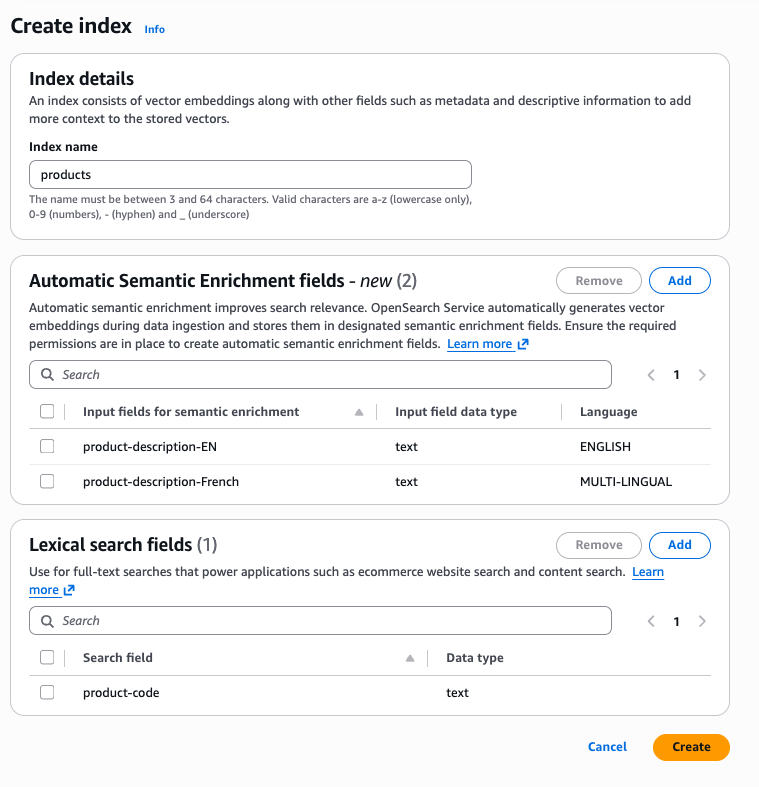
Pour créer un index d'enrichissement sémantique automatique à l'aide de l'interface de ligne de AWS commande (AWS CLI), utilisez la commande create-index :
aws opensearchserverless create-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body] \
Dans l'exemple de schéma d'index suivant, le title_semantic champ possède un type de champ défini sur text et un paramètre semantic_enrichment défini sur status. ENABLED La définition du semantic_enrichment paramètre permet un enrichissement sémantique automatique sur le title_semantic terrain. Vous pouvez utiliser le language_options champ pour spécifier l'un english ou l'autremulti-lingual.
aws opensearchserverless create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Pour décrire l'index créé, utilisez la commande suivante :
aws opensearchserverless get-index \ --id [collection_id] \ --index-name [index_name] \
Vous pouvez également utiliser des CloudFormation modèles (Type:AWS: : : OpenSearchServerless :CollectionIndex) pour créer une recherche sémantique pendant le provisionnement de la collection ainsi qu'après la création de la collection.
Mettre à jour un index existant
Vous pouvez mettre à jour un index existant pour ajouter de nouveaux champs d'enrichissement sémantique, activer ou désactiver l'enrichissement sémantique sur des champs existants ou ajouter des champs de texte non sémantiques. Utilisez la update-index commande et indiquez uniquement les champs que vous souhaitez modifier dans leindex-schema. Les champs non inclus dans la demande restent inchangés.
Note
L'index settings ne peut pas être mis à jour. Si vous incluez un settings bloc dans la demande, l'opération renvoie une erreur de validation. Pour modifier les paramètres de l'index, vous devez supprimer et recréer l'index.
Pour mettre à jour un index à l'aide de AWS CLI, utilisez la update-index commande :
aws opensearchserverless update-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body]
Ajouter un nouveau champ d'enrichissement sémantique
Vous pouvez ajouter un nouveau text champ avec l'enrichissement sémantique activé à un index existant. Le service configure automatiquement le modèle ML, le pipeline d'ingestion et le pipeline de recherche requis. Les nouveaux documents indexés après la mise à jour sont automatiquement enrichis.
Important
Les documents existants ne sont pas remblayés. Pour renseigner le champ d'enrichissement sémantique sur les documents existants, vous devez les réingérer après la mise à jour. Jusqu'à ce qu'ils soient réingérés, les documents existants ne bénéficieront pas de la recherche sémantique dans le nouveau champ.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Désactiver l'enrichissement sémantique sur un champ
Pour désactiver l'enrichissement sémantique sur un champ pour lequel il est actuellement activé, définissez status cette option sur. DISABLED Le champ est supprimé des pipelines d'ingestion et de recherche. Le champ de texte sous-jacent et son champ d'intégration restent dans l'index mais ne sont plus enrichis.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Limites de mise à
Les opérations suivantes ne sont pas prises en charge par l'index update-index et vous obligent à le supprimer et à le recréer :
-
Modification
language_optionsd'un champ pour lequel l'enrichissement sémantique est actuellement activé. Désactivez d'abord le champ, puis réactivez-le avec la nouvelle option de langue. -
Mettre à jour les champs imbriqués. L'enrichissement sémantique n'est pris en charge que sur les champs de niveau supérieur.
text -
Mise à jour de l'index
settings.
Note
Si l'index possède un pipeline d'ingestion ou de recherche personnalisé qui n'a pas été créé par enrichissement sémantique automatique, l'opération de mise à jour est bloquée. Supprimez le pipeline personnalisé avant d'ajouter des champs d'enrichissement sémantique.
Ingestion et recherche de données
Une fois que vous avez créé un index avec l'enrichissement sémantique automatique activé, la fonctionnalité fonctionne automatiquement pendant le processus d'ingestion des données, aucune configuration supplémentaire n'est requise.
Ingestion des données : lorsque vous ajoutez des documents à votre index, le système :
-
Analyse les champs de texte que vous avez désignés pour l'enrichissement sémantique
-
Génère des codages sémantiques à l'aide du modèle clairsemé géré par le OpenSearch service
-
Stocke ces représentations enrichies aux côtés de vos données d'origine
Ce processus utilise OpenSearch les connecteurs ML et les pipelines d'ingestion intégrés, qui sont créés et gérés automatiquement en arrière-plan.
Recherche : les données d'enrichissement sémantique sont déjà indexées, de sorte que les requêtes s'exécutent efficacement sans invoquer à nouveau le modèle ML. Cela signifie que vous bénéficiez d'une pertinence de recherche améliorée sans surcoût de latence de recherche supplémentaire.
Configuration des autorisations pour l'enrichissement sémantique automatique
Avant de créer un index d'enrichissement sémantique automatique, vous devez configurer les autorisations requises. Cette section explique les autorisations nécessaires et explique comment les configurer.
Autorisations liées à la politique IAM
Utilisez la politique Gestion des identités et des accès AWS (IAM) suivante pour accorder les autorisations nécessaires à l'utilisation de l'enrichissement sémantique automatique :
- Autorisations de clés
-
-
Les
aoss:*Indexautorisations permettent la gestion des index -
L'
aoss:APIAccessAllautorisation autorise les opérations OpenSearch d'API -
Pour restreindre les autorisations à une collection spécifique, remplacez-la
"Resource": "*"par l'ARN de la collection
-
Configuration des autorisations d'accès aux données
Pour configurer un index pour un enrichissement sémantique automatique, vous devez disposer de politiques d'accès aux données appropriées autorisant l'accès aux ressources de collecte d'index, de pipeline et de modèles. Pour plus d'informations sur les politiques d'accès aux données, consultezContrôle d'accès aux données pour Amazon OpenSearch Serverless. Pour la procédure de configuration d'une politique d'accès aux données, consultezCréation de stratégies d'accès aux données (console).
Autorisations d'accès aux données
[ { "Description": "Create index permission", "Rules": [ { "ResourceType": "index", "Resource": ["index/collection_name/*"], "Permission": [ "aoss:CreateIndex", "aoss:DescribeIndex", "aoss:UpdateIndex", "aoss:DeleteIndex" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create pipeline permission", "Rules": [ { "ResourceType": "collection", "Resource": ["collection/collection_name"], "Permission": [ "aoss:CreateCollectionItems", "aoss:DescribeCollectionItems" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create model permission", "Rules": [ { "ResourceType": "model", "Resource": ["model/collection_name/*"], "Permission": ["aoss:CreateMLResource"] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, ]
Autorisations d'accès au réseau
Pour autoriser les API de service à accéder aux collections privées, vous devez configurer des politiques réseau qui autorisent l'accès requis entre l'API de service et la collection. Pour plus d'informations sur les politiques réseau, consultez la section Accès réseau pour Amazon OpenSearch Serverless.
[ { "Description":"Enable automatic semantic enrichment in a private collection", "Rules":[ { "ResourceType":"collection", "Resource":[ "collection/collection_name" ] } ], "AllowFromPublic":false, "SourceServices":[ "aoss.amazonaws.com" ], } ]
Pour configurer les autorisations d'accès réseau pour une collection privée
-
Connectez-vous à la console de OpenSearch service à l'adresse https://console.aws.amazon.com/aos/home
. -
Dans le volet de navigation de gauche, sélectionnez Network policies. Ensuite, effectuez l’une des actions suivantes :
-
Choisissez un nom de politique existant et cliquez sur Modifier
-
Choisissez Créer une politique réseau et configurez les détails de la politique
-
-
Dans la zone Type d'accès, choisissez Privé (recommandé), puis sélectionnez Accès privé au AWS service.
-
Dans le champ de recherche, choisissez Service, puis aoss.amazonaws.com.
-
Dans la zone Type de ressource, cochez la case Activer l'accès au OpenSearch point de terminaison.
-
Pour Rechercher une ou plusieurs collections, ou saisir des termes de préfixes spécifiques, dans le champ de recherche, sélectionnez Nom de la collection. Entrez ou sélectionnez ensuite le nom des collections à associer à la politique réseau.
-
Choisissez Créer pour une nouvelle politique réseau ou Mettre à jour pour une politique réseau existante.
Réécritures de requêtes
L'enrichissement sémantique automatique convertit automatiquement vos requêtes « correspondantes » existantes en requêtes de recherche sémantique sans qu'il soit nécessaire de les modifier. Si une requête correspondante fait partie d'une requête composée, le système parcourt votre structure de requête, trouve les requêtes correspondantes et les remplace par des requêtes neuronales clairsemées. Actuellement, la fonctionnalité prend uniquement en charge le remplacement des requêtes « match », qu'il s'agisse d'une requête autonome ou d'une partie d'une requête composée. « multi_match » n'est pas pris en charge. En outre, cette fonctionnalité prend en charge toutes les requêtes composées pour remplacer leurs requêtes de correspondance imbriquées. Les requêtes composées incluent : bool, boosting, constant_score, dis_max, function_score et hybrid.
Limites de l'enrichissement sémantique automatique
La recherche sémantique automatique est particulièrement efficace lorsqu'elle est appliquée à des champs de petite ou moyenne taille contenant du contenu en langage naturel, tels que des titres de films, des descriptions de produits, des critiques et des résumés. Bien que la recherche sémantique améliore la pertinence dans la plupart des cas d'utilisation, elle peut ne pas être optimale pour certains scénarios. Tenez compte des limites suivantes lorsque vous décidez d'implémenter l'enrichissement sémantique automatique pour votre cas d'utilisation spécifique.
-
Documents très longs — Le modèle clairsemé actuel ne traite que les 8 192 premiers jetons de chaque document en anglais. Pour les documents multilingues, il s'agit de 512 jetons. Pour les articles longs, pensez à implémenter le découpage des documents afin de garantir un traitement complet du contenu.
-
Charges de travail d'analyse des journaux : l'enrichissement sémantique augmente considérablement la taille de l'index, ce qui peut être inutile pour l'analyse des journaux où une correspondance exacte est généralement suffisante. Le contexte sémantique supplémentaire améliore rarement suffisamment l'efficacité de la recherche dans les journaux pour justifier les exigences de stockage accrues.
-
L'enrichissement sémantique automatique n'est pas compatible avec la fonctionnalité Source dérivée.
Tarification
Amazon OpenSearch Service facture l'enrichissement sémantique automatique en fonction des unités de OpenSearch calcul (OCU) consommées lors de la génération de vecteurs épars au moment de l'indexation. Vous n'êtes facturé que pour l'utilisation réelle lors de l'indexation des champs de texte pour lesquels vous avez activé l'enrichissement sémantique automatique. Une OCU de recherche sémantique peut traiter 11,1 millions de jetons pour du contenu en anglais. Pour traiter 2,4 milliards de jetons, vous aurez besoin d'environ 216 recherches sémantiques OCU-hours (2,4 milliards/11,10 millions). Avec un prix de 0,24$ par recherche sémantique OCU-hour, le coût du traitement de 10 Go de données pour la recherche sémantique automatique serait de 51$ (216 x 0$). OCU-hours 24/OCU-heure). Il n'y a pas de frais supplémentaires liés à la recherche sémantique OCU pendant les opérations de recherche ou pour le stockage des données.
Vous pouvez surveiller cette consommation à l'aide de la CloudWatch métrique AmazonSemanticSearchOCU. Pour obtenir des informations spécifiques sur les limites des jetons du modèle, le débit volumique par OCU et un exemple de calcul, consultez la section OpenSearch Service
