Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation de l'apprentissage automatique avec Amazon SageMaker AI
Cette section décrit un flux de travail d'apprentissage automatique (ML) typique et explique comment accomplir ces tâches avec Amazon SageMaker AI.
Dans le cadre du machine learning, vous apprenez à un ordinateur à effectuer des prédictions ou inférences. Tout d’abord, vous utilisez un algorithme et des exemples de données pour entraîner un modèle. Ensuite, vous intégrez votre modèle dans votre application pour générer des inférences en temps réel et à l’échelle.
Le schéma suivant montre le flux de travail typique de création de modèle ML. Il comprend trois étapes dans un flux circulaire que nous abordons plus en détail sur le schéma suivant :
-
Génération d’exemples de données
-
Entraînement d’un modèle
-
Déploiement du modèle
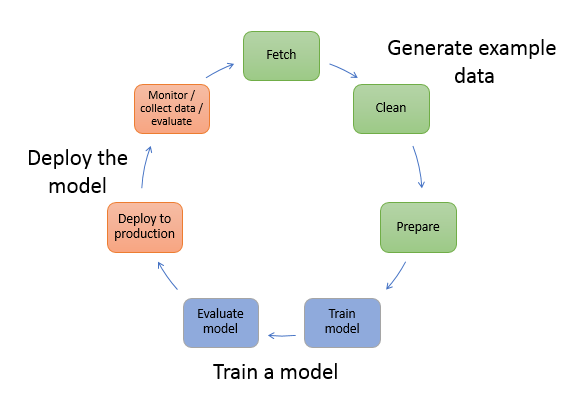
Le schéma montre comment exécuter les tâches suivantes dans les scénarios les plus courants :
-
Générer des exemples de données : pour entraîner un modèle, vous avez besoin d’exemples de données. Le type de données dont vous avez besoin dépend du problème métier que vous souhaitez voir résolu. Cela concerne les inférences que vous souhaitez que le modèle génère. Par exemple, si vous souhaitez créer un modèle qui prédit un nombre à partir d’une image en entrée représentant un chiffre manuscrit. Pour entraîner ce modèle, vous avez besoin d’exemples d’images de chiffre manuscrits.
Les spécialistes des données consacrent souvent du temps à étudier et prétraiter des exemples de données avant de les utiliser pour l’entraînement des modèles. Pour prétraiter des données, vous effectuez généralement les opérations suivantes :
-
Récupérer des données : vous pouvez posséder des référentiels de données en interne, ou utiliser des jeux de données disponibles publiquement. En général, vous placez les ensembles de données dans un référentiel unique.
-
Nettoyer les données : pour améliorer l’entraînement des modèles, étudiez les données et nettoyez-les si nécessaire. Par exemple, si vos données possèdent un attribut
country nameavec des valeursUnited StatesetUS, vous pouvez les modifier à des fins de cohérence. -
Préparer ou transformer les données : pour améliorer les performances, vous pouvez effectuer des transformations de données supplémentaires. Par exemple, vous pouvez choisir de combiner les attributs d’un modèle qui prédit les conditions nécessitant le dégivrage d’un avion. Vous pouvez combiner les attributs de température et d’humidité dans un nouvel attribut plutôt que de les utiliser séparément, afin d’améliorer le modèle.
En SageMaker intelligence artificielle, vous pouvez prétraiter des données d'exemple à l'aide d'SageMaker API avec le SDK SageMaker Python
dans un environnement de développement intégré (IDE). Avec le kit SDK pour Python (Boto3), vous pouvez récupérer, explorer et préparer vos données pour l’entraînement des modèles. Pour plus d’informations sur la préparation, le traitement et la transformation des données, consultez Recommandations pour choisir le bon outil de préparation des données en SageMaker IA, Charges de travail de transformation des données avec Processing SageMaker et Création, stockage et partage de caractéristiques avec Feature Store. -
-
Entraîner un modèle : l’entraînement des modèles inclut à la fois l’entraînement et l’évaluation du modèle, comme suit :
-
Entraînement du modèle : pour entraîner un modèle, vous avez besoin d’un algorithme ou d’un modèle de base pré-entraîné. Le choix de votre algorithme dépend de plusieurs facteurs. Pour une solution intégrée, vous pouvez utiliser l'un des algorithmes SageMaker fournis. Pour une liste des algorithmes fournis par SageMaker et des considérations connexes, voirBuilt-in algorithmes et modèles préentraînés sur Amazon SageMaker. Pour une solution de UI-based formation fournissant des algorithmes et des modèles, voirSageMaker JumpStart modèles préentraînés.
Vous devez également calculer les ressources nécessaires à l’entraînement. L’utilisation de vos ressources dépend de la taille de votre jeu de données d’entraînement et de la rapidité à laquelle vous avez besoin des résultats. Vous pouvez utiliser des ressources allant d’une instance à usage général unique à un cluster distribué d’instances GPU. Pour de plus amples informations, veuillez consulter Entraînez un modèle avec Amazon SageMaker.
-
Évaluer le modèle : après avoir entraîné votre modèle, vous l’évaluez afin de déterminer si la précision des inférences est acceptable. Pour entraîner et évaluer votre modèle, utilisez le SDK SageMaker Python
pour envoyer des demandes d'inférence au modèle via l'un des IDE disponibles. Pour plus d’informations sur l’évaluation de votre modèle, consultez Surveillance de la qualité des données et des modèles avec Amazon SageMaker Model Monitor.
-
-
Déployer le modèle : normalement, vous repensez un modèle avant de l’intégrer à votre application et de le déployer. Avec les services d'hébergement SageMaker AI, vous pouvez déployer votre modèle de manière indépendante, ce qui le dissocie du code de votre application. Pour de plus amples informations, veuillez consulter Déploiement de modèles pour l'inférence.
Le machine learning est un cycle continu. Après avoir déployé un modèle, vous surveillez les inférences, collectez plus de données de qualité élevée et évaluez le modèle pour identifier les écarts. Vous pouvez ensuite augmenter la précision de vos inférences en mettant à jour vos données d’entraînement de manière à inclure les données de qualité élevée nouvellement collectées. À mesure que davantage d’exemples de données deviennent disponibles, vous continuez de réentraîner votre modèle pour en augmenter la précision.
