Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mise en pipeline d'un modèle
L'une des principales fonctionnalités de la bibliothèque SageMaker de parallélisme des modèles est le parallélisme des pipelines, qui détermine l'ordre dans lequel les calculs sont effectués et les données sont traitées sur les appareils pendant l'entraînement du modèle. Le Pipelining est une technique employée pour obtenir une véritable parallélisation dans le parallélisme des modèles grâce aux calculs simultanés effectués par les GPU sur différents échantillons de données, et surmonter la baisse de performance due au calcul séquentiel. Lorsque vous utilisez le parallélisme de pipelines, la tâche d'entraînement est exécutée en pipeline sur des micro-lots afin d'optimiser l'utilisation de GPU.
Note
Le parallélisme des pipelines, également appelé partitionnement des modèles, est disponible pour les deux. PyTorch TensorFlow Pour les versions de frameworks prises en charge, consultez Frameworks pris en charge et Régions AWS.
Calendrier d'exécution de pipeline
Le Pipelining repose sur la division d'un mini-lot en micro-lots, qui sont introduits individuellement dans le pipeline d'entraînement un par un et respectent un calendrier d'exécution défini par le moteur d'exécution de la bibliothèque. Un micro-lot est un sous-ensemble plus petit d'un mini-lot d'entraînement donné. Le calendrier du pipeline détermine quel micro-lot est exécuté par quel périphérique pour chaque créneau horaire.
Par exemple, en fonction du calendrier du pipeline et de la partition du modèle, le GPU i peut effectuer un calcul (vers l'avant ou vers l'arrière) sur le micro-lot b, tandis que le GPU i+1 effectue un calcul sur le micro-lot b+1, les deux GPU étant ainsi actifs en même temps. Durant une seule transmission vers l'avant et vers l'arrière, le flux d'exécution d'un seul micro-lot peut visiter le même périphérique plusieurs fois, en fonction de la décision de partitionnement. Par exemple, une opération située au début du modèle peut être placée sur le même périphérique qu'une opération située à la fin du modèle, tandis que les opérations situées entre les deux sont placées sur différents périphériques, de sorte que ce périphérique est visité deux fois.
La bibliothèque propose deux plannings de pipeline différents, simples et entrelacés, qui peuvent être configurés à l'aide du pipeline paramètre du SDK SageMaker Python. Dans la plupart des cas, le pipeline entrelacé permet d'obtenir de meilleures performances grâce à une utilisation plus efficace des GPU.
Pipeline entrelacé
Dans un pipeline entrelacé, la priorité est donnée, dans la mesure du possible, à l'exécution vers l'arrière des micro-lots. Cela permet de libérer plus rapidement la mémoire utilisée pour les activations et donc d'utiliser la mémoire plus efficacement. Cela permet aussi de mettre à l'échelle le nombre de micro-lots à un niveau supérieur et de réduire ainsi le temps d'inactivité des GPU. À l'état d'équilibre, chaque périphérique alterne entre les transmissions vers l'avant et vers l'arrière. Cela signifie que la transmission vers l'arrière d'un micro-lot peut s'exécuter avant la fin de la transmission vers l'avant d'un autre micro-lot.

La figure précédente illustre un exemple de calendrier d'exécution du pipeline entrelacé sur 2 GPU. Sur la figure, F0 représente la transmission vers l'avant pour le micro-lot 0, et B1 la transmission vers l'arrière pour le micro-lot 1. Update représente la mise à jour des paramètres par l'optimiseur. Dans la mesure du possible, GPU0 donne toujours la priorité aux transmissions vers l'arrière (en exécutant, par exemple, B0 avant F2), ce qui permet d'effacer la mémoire utilisée pour les activations précédentes.
Pipeline simple
À contrario, un pipeline simple termine d'exécuter la transmission vers l'avant pour chaque micro-lot avant de démarrer la transmission vers l'arrière. En d'autres termes, le pipeline exécute les étapes de transmission vers l'avant et vers l'arrière en interne. La figure suivante illustre un exemple de fonctionnement, sur 2 GPU.

Exécution de pipeline dans des cadres spécifiques
Utilisez les sections suivantes pour en savoir plus sur les décisions de planification de pipeline spécifiques au framework que la bibliothèque SageMaker de parallélisme des modèles permet et. TensorFlow PyTorch
Exécution du pipeline avec TensorFlow
L'image suivante est un exemple de TensorFlow graphe partitionné par la bibliothèque de parallélisme du modèle, à l'aide du découpage automatique du modèle. Lorsqu'un graphe est divisé, chaque sous-graphe obtenu est répliqué B fois (sauf pour les variables), B désignant le nombre de micro-lots. Sur cette figure, chaque sous-graphe est répliqué 2 fois (B=2). Une opération SMPInput est insérée à chaque entrée d'un sous-graphe, et une opération SMPOutput est insérée à chaque sortie. Ces opérations communiquent avec le backend de la bibliothèque pour transférer les tenseurs entre eux de façon bidirectionnelle.

L'image suivante illustre un exemple de 2 sous-graphes divisés avec B=2, avec ajout d'opérations de gradient. Le gradient d'une opération SMPInput est une opération SMPOutput, et vice versa. Les gradients peuvent ainsi circuler vers l'arrière pendant la rétro-propagation.
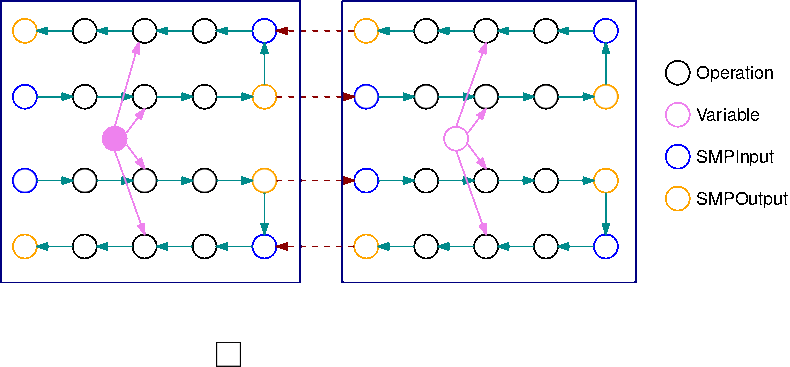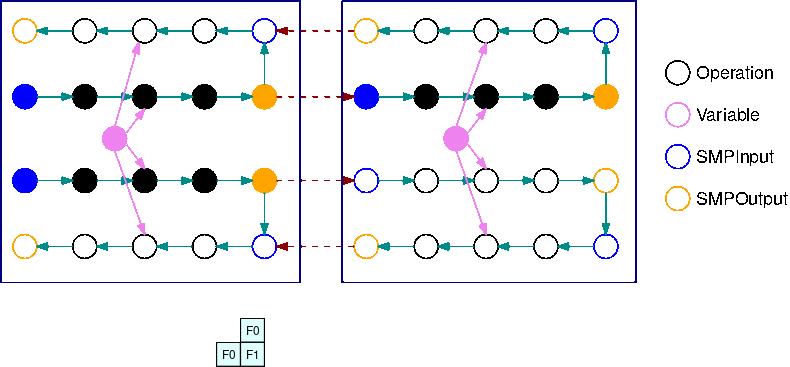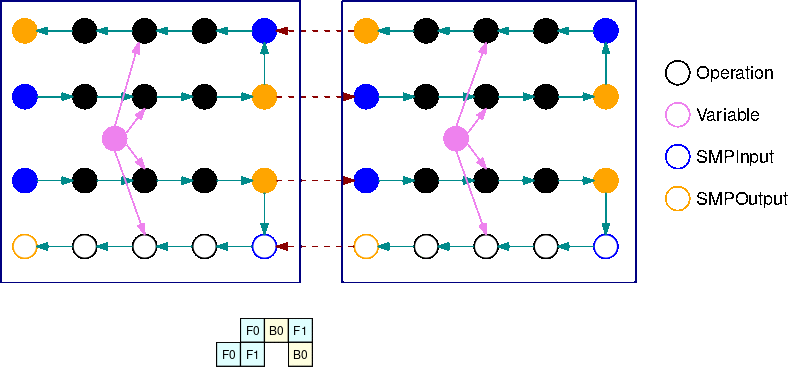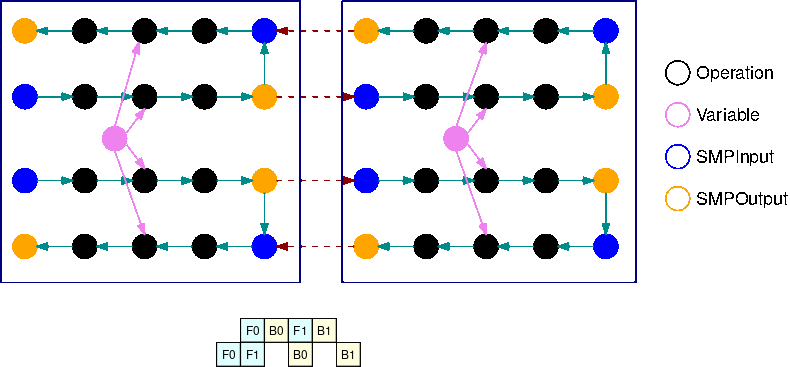
Ce GIF illustre un exemple de calendrier d'exécution de pipeline entrelacé avec B=2 micro-lots et 2 sous-graphes. Chaque périphérique exécute l'un des réplicas de sous-graphe séquentiellement afin d'améliorer l'utilisation du GPU. À mesure que B augmente, la fraction d'intervalles de temps d'inactivité tend vers zéro. Chaque fois qu'un calcul (vers l'avant ou vers l'arrière) doit être fait sur un réplica de sous-graphe spécifique, la couche de pipeline signale aux opérations SMPInput bleues correspondantes qu'il est temps de démarrer l'exécution.
Une fois que les gradients de tous les micro-lots d'un seul mini-lot sont calculés, la bibliothèque combine les gradients entre les micro-lots, qui peuvent ensuite être appliqués aux paramètres.
Exécution du pipeline avec PyTorch
Conceptuellement, le pipeline suit une idée similaire dans. PyTorch Cependant, comme il PyTorch n'implique pas de graphes statiques, la PyTorch fonctionnalité de la bibliothèque de parallélisme du modèle utilise un paradigme de pipeline plus dynamique.
Par exemple TensorFlow, chaque lot est divisé en plusieurs microlots, qui sont exécutés un par un sur chaque appareil. Toutefois, le calendrier d'exécution est géré via des serveurs d'exécution lancés sur chaque périphérique. Chaque fois que le périphérique actuel a besoin de la sortie d'un sous-module placé sur un autre périphérique, une demande d'exécution est envoyée au serveur d'exécution du périphérique distant et les tenseurs d'entrée au sous-module. Le serveur exécute alors ce module avec les entrées données et renvoie la réponse au périphérique actuel.
Comme le périphérique actuel est inactif pendant l'exécution du sous-module distant, l'exécution locale du micro-lot actuel s'interrompt et le moteur d'exécution de la bibliothèque bascule l'exécution vers un autre micro-lot sur lequel le périphérique actuel peut travailler activement. La priorité donnée aux micro-lots est déterminée par le calendrier de pipeline choisi. Dans le cas d'un calendrier de pipeline entrelacé, les micro-lots qui se trouvent dans l'étape de transmission vers l'arrière du calcul sont prioritaires dans la mesure du possible.
