Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mécanisme de classement lors de l'utilisation d'une combinaison de parallélisme de pipelines et de parallélisme de tenseurs
Cette section explique comment le mécanisme de classement du parallélisme de modèles fonctionne avec le parallélisme de tenseurs. C'est une extension des notions de base du classementsmp.tp_rank() pour le rang des tenseurs parallèles, smp.pp_rank() pour le rang des pipelines parallèles et smp.rdp_rank() pour le rang des données réduites parallèles. Les groupes de processus de communication correspondants sont le groupe de tenseurs parallèles (TP_GROUP), le groupe de pipelines parallèles (PP_GROUP) et le groupe de données réduites parallèles (RDP_GROUP). Ces groupes sont définis comme suit :
-
Un groupe de tenseurs parallèles (
TP_GROUP) est un sous-ensemble divisible de manière égale du groupe de données parallèles, sur lequel s'exerce la distribution en tenseurs parallèles des modules. Lorsque le degré de parallélisme de pipelines est de 1,TP_GROUPest identique au groupe parallèle au modèle (MP_GROUP). -
Un groupe de pipelines parallèles (
PP_GROUP) est le groupe de processus sur lequel s'exerce le parallélisme des pipelines. Lorsque le degré de parallélisme de tenseur est de 1,PP_GROUPest identique àMP_GROUP. -
Un groupe de données réduites parallèles (
RDP_GROUP) est un ensemble de processus qui contiennent les mêmes partitions de parallélisme des pipelines et les mêmes partitions de parallélisme des tenseurs, et qui réalisent un parallélisme des données entre eux. C'est ce que l'on appelle le groupe parallèle aux données réduites, car il s'agit d'un sous-ensemble de l'ensemble du groupe de parallélisme de données,DP_GROUP. Pour les paramètres du modèle distribués dans leTP_GROUP, l'opérationallreducede gradient est effectuée uniquement pour le groupe parallèle aux données réduites, tandis que pour les paramètres non distribués, l'opérationallreducede gradient a lieu sur l'ensemble duDP_GROUP. -
Un groupe parallèle au modèle (
MP_GROUP) désigne un groupe de processus qui stockent collectivement l'ensemble du modèle. Il s'agit de l'union desPP_GROUPde tous les rangs qui se trouvent dans leTP_GROUPdu processus actuel. Lorsque le degré de parallélisme de tenseur est de 1,MP_GROUPest équivalent àPP_GROUP. Il est également cohérent avec la définition existante duMP_GROUPdes versionssmdistributedprécédentes. Veuillez noter que leTP_GROUPactuel est un sous-ensemble duDP_GROUPet duMP_GROUPactuels.
Pour en savoir plus sur les API de processus de communication de la bibliothèque de parallélisme des SageMaker modèles, consultez l'API commune
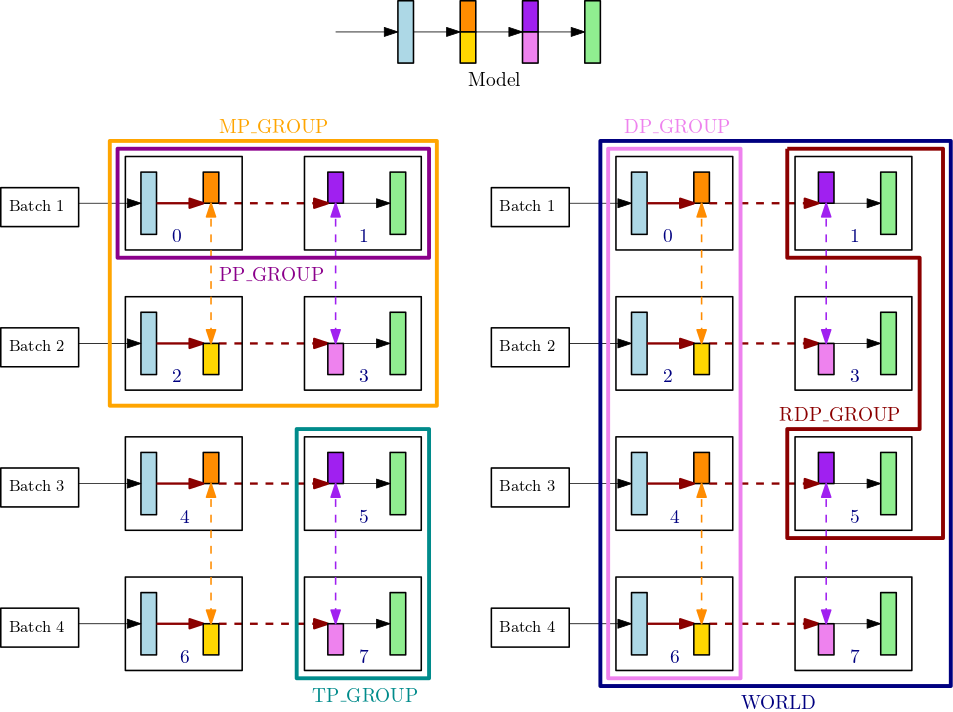
Par exemple, prenez en compte les groupes de processus pour un nœud unique doté de 8 GPU, où le degré de parallélisme des tenseurs est de 2, le degré de parallélisme des pipelines est de 2 et le degré de parallélisme des données est de 4. La partie centrale supérieure de la figure précédente montre un exemple de modèle à 4 couches. Les parties inférieure gauche et inférieure droite de la figure illustrent le modèle à 4 couches réparti entre 4 GPU à l'aide du parallélisme des pipelines et du parallélisme des tenseurs, ce dernier étant utilisé pour les deux couches du milieu. Les deux figures du bas sont de simples copies permettant d'illustrer des lignes de limites de groupe différentes. Le modèle partitionné est répliqué pour le parallélisme des données sur les GPU 0 à 3 et 4 à 7. La figure en bas à gauche montre les définitions de MP_GROUP, de PP_GROUP et de TP_GROUP. La figure en bas à droite montre RDP_GROUP, DP_GROUP et WORLD sur le même ensemble de GPU. Les opérations allreduce sont effectuées pour tous les gradients des couches et des tranches de couche de la même couleur dans le cadre du parallélisme des données. Par exemple, les opérations allreduce sont effectuées sur la première couche (bleu clair) dans DP_GROUP, alors que ces opérations allreduce ne sont effectuées sur la tranche orange foncé de la deuxième couche qu'au sein du RDP_GROUP de son processus. Les flèches rouge foncé en gras représentent des tenseurs avec le lot de tout le TP_GROUP.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
Dans cet exemple, le parallélisme de pipeline se produit entre les paires de GPU (0,1) ; (2,3) ; (4,5) et (6,7). De plus, le parallélisme des données (allreduce) s'exerce sur les GPU 0, 2, 4 et 6, et indépendamment sur les GPU 1, 3, 5 et 7. Le parallélisme de tenseur se produit sur des sous-ensembles de DP_GROUP, sur les paires de GPU (0,2) ; (1,3) ; (4,6) et (5,7).
