Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Chargeur de données mappé en mémoire
Une autre surcharge liée au redémarrage est due au chargement des données : le cluster d'entraînement reste inactif pendant que le chargeur de données s'initialise, télécharge les données depuis des systèmes de fichiers distants et les traite par lots.
Pour résoudre ce problème, nous introduisons le chargeur de données MMAP DataLoader (Memory Mapped), qui met en cache les lots préextraits dans la mémoire persistante, garantissant ainsi leur disponibilité même après un redémarrage provoqué par une erreur. Cette approche élimine le temps de configuration du chargeur de données et permet de reprendre immédiatement l'entraînement à l'aide de lots mis en cache, tandis que le chargeur de données se réinitialise et récupère simultanément les données suivantes en arrière-plan. Le cache de données se trouve sur chaque rang nécessitant des données d'entraînement et gère deux types de lots : les lots récemment consommés qui ont été utilisés pour l'entraînement et les lots préextraits prêts à être utilisés immédiatement.
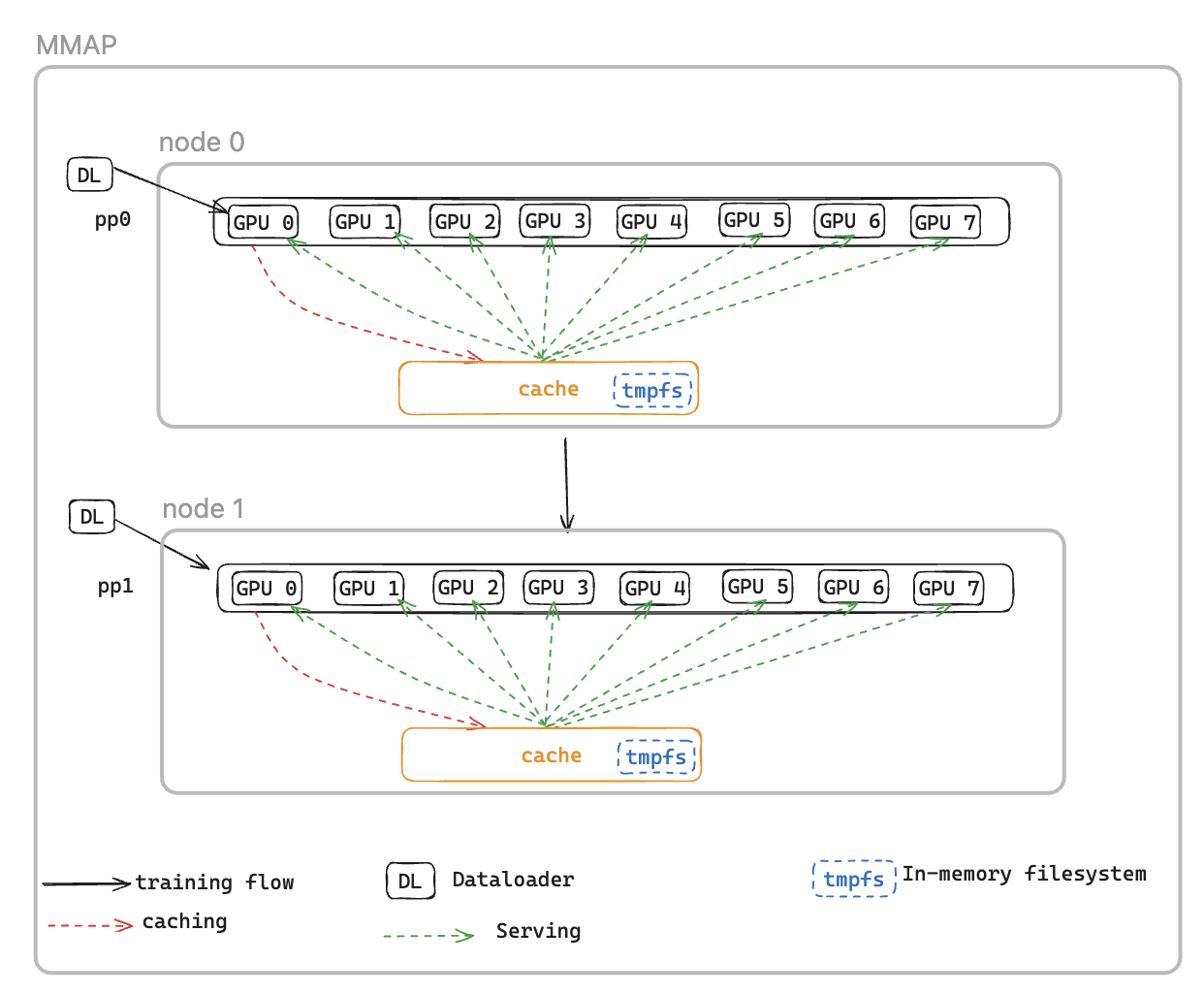
Le chargeur de données MMAP offre les deux fonctionnalités suivantes :
Préextraction des données : récupère et met en cache de manière proactive les données générées par le chargeur de données
Mise en cache persistante : stocke à la fois les lots consommés et les lots préextraits dans un système de fichiers temporaire qui survit aux redémarrages de processus
Grâce au cache, le job de formation bénéficiera des avantages suivants :
Encombrement mémoire réduit : exploite la mémoire mappée I/O pour conserver une seule copie partagée des données dans la mémoire du processeur hôte, éliminant ainsi les copies redondantes entre les processus du GPU (par exemple, réduction de 8 copies à 1 sur une instance p5 avec 8) GPUs
Restauration plus rapide : réduit le temps moyen de redémarrage (MTTR) en permettant à l'entraînement de reprendre immédiatement à partir des lots mis en cache, éliminant ainsi le temps d'attente pour la réinitialisation du chargeur de données et la génération du premier lot
Configurations MMAP
Pour utiliser MMAP, il vous suffit de transmettre le module de données d'origine dans MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: Les paramètres du chargeur de données MMAP contrôlent l'emplacement du répertoire de cache, les limites de taille et la délégation de récupération des données. Par défaut, seul le TP de rang 0 par nœud extrait les données de la source, tandis que les autres nœuds du même groupe de réplication de données lisent les données du cache partagé, éliminant ainsi les transferts redondants.
MMAPDataModule: Il enveloppe le module de données d'origine et renvoie le chargeur de données mmap à la fois pour le train et pour la validation.
Consultez l'exemple
Référence des API
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Classe de configuration pour la fonctionnalité du chargeur de données MMAP (cache-resume memory mappé) dans le cadre d'un entraînement sans point de contrôle. HyperPod
Cette configuration permet un chargement efficace des données grâce à des fonctionnalités de mise en cache et de prélecture, ce qui permet de reprendre rapidement l'entraînement après un échec en conservant les lots de données mis en cache dans des fichiers mappés en mémoire.
Paramètres
-
cache_dir (str, facultatif) — Chemin de répertoire pour stocker les lots de données mis en cache. Par défaut : «/dev/shm/pdl_cache »
-
prefetch_length (int, facultatif) — Nombre de lots à prérécupérer pendant l'entraînement. Par défaut: 10
-
val_prefetch_length (int, facultatif) — Nombre de lots à préextraire lors de la validation. Par défaut: 10
-
lookback_length (int, facultatif) — Nombre de lots précédemment utilisés à conserver dans le cache en vue d'une éventuelle réutilisation. Par défaut: 2
-
checkpoint_frequency (int, facultatif) — Fréquence des étapes de point de contrôle du modèle. Utilisé pour l'optimisation des performances du cache. Par défaut : aucun
-
model_parallel_group (object, facultatif) — Groupe de processus pour le parallélisme des modèles. Si aucun, il sera créé automatiquement. Par défaut : aucun
-
enable_batch_encryption (bool, facultatif) — S'il faut activer le chiffrement pour les données par lots mises en cache. Par défaut : false
Méthodes
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Crée et renvoie une instance de chargeur de données MMAP configurée.
Paramètres
-
dataloader_init_callable (Callable) — Fonction pour initialiser le chargeur de données sous-jacent
-
parallel_state_util (object) — Utilitaire pour gérer l'état parallèle entre les processus
-
step (int) — L'étape de données à reprendre pendant l'entraînement
-
is_data_loading_rank (Callable) — Fonction qui renvoie True si le rang actuel doit charger des données
-
create_model_parallel_group_callable (Callable) — Fonction permettant de créer un modèle de groupe de processus parallèles
-
name (str, facultatif) — Identifiant du nom du chargeur de données. Par défaut : « Train »
-
is_val (bool, facultatif) — S'il s'agit d'un chargeur de données de validation. Par défaut : false
-
cached_len (int, facultatif) — Longueur des données mises en cache en cas de reprise à partir du cache existant. Par défaut : 0
Renvoie CacheResumePrefetchedDataLoader ou CacheResumeReadDataLoader — Instance de chargeur de données MMAP configurée
ValueErrorDéclenche si le paramètre de l'étape estNone.
Exemple
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Remarques
-
Le répertoire de cache doit disposer de suffisamment d'espace et de I/O performances rapides (par exemple, /dev/shm pour le stockage en mémoire).
-
Le réglage
checkpoint_frequencyaméliore les performances du cache en alignant la gestion du cache sur le point de contrôle du modèle -
Pour les chargeurs de données de validation (
is_val=True), l'étape est remise à 0 et le démarrage à froid est forcé -
Différentes implémentations de chargeurs de données sont utilisées selon que le rang actuel est responsable du chargement des données
MMAPDataModules
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
Un DataModule wrapper PyTorch Lightning qui applique des fonctionnalités de chargement de données mappées en mémoire (MMAP) à des formations existantes pour un entraînement sans point de contrôle. DataModules
Cette classe intègre un PyTorch Lightning existant DataModule et l'améliore avec la fonctionnalité MMAP, permettant ainsi une mise en cache efficace des données et une restauration rapide en cas d'échec de l'entraînement. Il maintient la compatibilité avec l' DataModule interface d'origine tout en ajoutant des fonctionnalités de formation sans points de contrôle.
Parameters
- data_module (pl. LightningDataModule)
Le sous-jacent DataModule à encapsuler (par exemple, LLMData Module)
- map_config () MMAPConfig
L'objet de configuration MMAP qui définit le comportement et les paramètres de mise en cache
parallel_state_util(MegatronParallelStateUtil, facultatif)Utilitaire pour gérer l'état parallèle dans les processus distribués. Par défaut : MegatronParallelStateUtil ()
is_data_loading_rank(Appelable, facultatif)Fonction qui renvoie True si le classement actuel doit charger des données. Si None, la valeur par défaut est parallel_state_util.is_tp_0. Par défaut : aucun
Attributs
global_step(int)Étape de formation globale actuelle, utilisée pour la reprise depuis les points de contrôle
cached_train_dl_len(int)Longueur mise en cache du chargeur de données d'entraînement
cached_val_dl_len(int)Longueur mise en cache du chargeur de données de validation
Méthodes
setup(stage=None)
Configurez le module de données sous-jacent pour l'étape d'apprentissage spécifiée.
stage(str, facultatif)Étape de l'entraînement (« ajustement », « validation », « test » ou « prédiction »). Par défaut : aucun
train_dataloader()
Créez la formation à l' DataLoader aide de l'encapsulage MMAP.
Retours : DataLoader — Entraînement intégré au MMAP DataLoader avec fonctionnalités de mise en cache et de prélecture
val_dataloader()
Créez la validation DataLoader avec un encapsulage MMAP.
Renvoie : DataLoader — Validation DataLoader encapsulée dans MMAP avec fonctionnalités de mise en cache
test_dataloader()
Créez le test DataLoader si le module de données sous-jacent le prend en charge.
Renvoie : DataLoader ou None — Test DataLoader à partir du module de données sous-jacent, ou None s'il n'est pas pris en charge
predict_dataloader()
Créez la prédiction DataLoader si le module de données sous-jacent la prend en charge.
Renvoie : DataLoader ou Aucun — Prédire DataLoader à partir du module de données sous-jacent, ou Aucun s'il n'est pas pris en charge
load_checkpoint(checkpoint)
Chargez les informations relatives aux points de contrôle pour reprendre l'entraînement à partir d'une étape spécifique.
- point de contrôle (dict)
Dictionnaire de points de contrôle contenant la clé « global_step »
get_underlying_data_module()
Obtenez le module de données encapsulé sous-jacent.
Retours : pl. LightningDataModule — Le module de données d'origine qui a été encapsulé
state_dict()
Obtenez le dictionnaire d'état du MMAP DataModule pour le point de contrôle.
Renvoie : dict — Dictionnaire contenant les longueurs des chargeurs de données mis en cache
load_state_dict(state_dict)
Chargez le dictionnaire d'état pour restaurer l' DataModule état du MMAP.
state_dict(dict)Dictionnaire d'états à charger
Propriétés
data_sampler
Exposez l'échantillonneur de données du module de données sous-jacent au NeMo framework.
Renvoie : object ou None — L'échantillonneur de données du module de données sous-jacent
Exemple
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Remarques
Le wrapper délègue la plupart des accès aux attributs au module de données sous-jacent en utilisant __getattr__
Seuls les rangs de chargement des données initialisent et utilisent réellement le module de données sous-jacent ; les autres rangs utilisent de faux chargeurs de données
La longueur des chargeurs de données mis en cache est maintenue pour optimiser les performances lors de la reprise de l'entraînement
