Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Restauration en cours de processus et formation sans points de contrôle
HyperPod l'entraînement sans point de contrôle utilise la redondance des modèles pour permettre un entraînement tolérant aux pannes. Le principe de base est que les états du modèle et de l'optimiseur sont entièrement répliqués sur plusieurs groupes de nœuds, les mises à jour du poids et les changements d'état de l'optimiseur étant répliqués de manière synchrone au sein de chaque groupe. En cas de panne, les répliques saines terminent leurs étapes d'optimisation et transmettent les model/optimizer états mis à jour aux répliques en cours de restauration.
Cette approche basée sur la redondance des modèles permet plusieurs mécanismes de gestion des pannes :
-
Restauration en cours de processus : les processus restent actifs malgré les défaillances, en conservant tous les états du modèle et de l'optimiseur dans la mémoire du GPU avec les dernières valeurs
-
Gestion progressive des interruptions : interruptions contrôlées et nettoyage des ressources pour les opérations concernées
-
Réexécution d'un bloc de code : réexécution uniquement des segments de code concernés dans un bloc de code réexécutable (RCB)
-
Restauration sans point de contrôle sans perte de progression de l'entraînement : comme les processus persistent et que les états restent en mémoire, aucune progression de l'apprentissage n'est perdue ; en cas de panne, l'entraînement reprend à partir de l'étape précédente, au lieu de reprendre à partir du dernier point de contrôle enregistré
Configurations sans point de contrôle
Voici l'extrait de base de l'entraînement sans point de contrôle.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Tous les grades attendront les informations de classement provenant de l' HyperpodTrainingOperator infrastructure.HPWrapper: enveloppe de fonction Python qui active les capacités de redémarrage d'un bloc de code réexécutable (RCB). L'implémentation utilise un gestionnaire de contexte plutôt qu'un décorateur Python car les décorateurs ne peuvent pas déterminer le nombre de éléments RCBs à surveiller lors de l'exécution.CudaHealthCheck: garantit que le contexte CUDA du processus en cours est en bon état en le synchronisant avec le GPU. Utilise le périphérique spécifié par la variable d'environnement LOCAL_RANK, ou utilise par défaut le périphérique CUDA du thread principal si LOCAL_RANK n'est pas défini.HPAgentK8sAPIFactory: Cette API permet à l'entraînement sans point de contrôle de demander l'état d'entraînement des autres pods du cluster de formation Kubernetes. Il constitue également une barrière au niveau de l'infrastructure qui garantit que tous les grades terminent avec succès les opérations d'abandon et de redémarrage avant de poursuivre.CheckpointManager: Gère les points de contrôle en mémoire et la peer-to-peer restauration pour une tolérance aux pannes sans point de contrôle. Ses principales responsabilités sont les suivantes :Gestion des points de contrôle en mémoire : enregistre et gère les points de contrôle NeMo du modèle en mémoire pour une restauration rapide sans disque I/O lors de scénarios de restauration sans point de contrôle.
Validation de la faisabilité de la restauration : détermine si une restauration sans point de contrôle est possible en validant la cohérence globale des étapes, l'état du classement et l'intégrité de l'état du modèle.
Peer-to-Peer Orchestration du rétablissement : coordonne le transfert des points de contrôle entre les rangs sains et ceux qui ont échoué à l'aide d'une communication distribuée pour une reprise rapide.
Gestion des états RNG : préserve et restaure les états des générateurs de nombres aléatoires en Python, NumPy PyTorch, et Megatron pour une restauration déterministe.
[Facultatif] Déchargement du point de contrôle : déchargez le point de contrôle de la mémoire vers le processeur si le GPU ne dispose pas d'une capacité de mémoire suffisante.
PEFTCheckpointManager: Il s'étendCheckpointManageren conservant les poids du modèle de base pour le réglage précis du PEFT.CheckpointlessAbortManager: gère les opérations d'abandon dans un thread d'arrière-plan en cas d'erreur. Par défaut, il abandonne TransformerEngine, Checkpointing et TorchDistributed. DataLoader Les utilisateurs peuvent enregistrer des gestionnaires d'abandon personnalisés selon leurs besoins. Une fois l'abandon terminé, toutes les communications doivent cesser et tous les processus et threads doivent être interrompus pour éviter les fuites de ressources.CheckpointlessFinalizeCleanup: gère les opérations de nettoyage finales dans le thread principal pour les composants qui ne peuvent pas être interrompus ou nettoyés en toute sécurité dans le thread d'arrière-plan.CheckpointlessMegatronStrategy: Cela hérite de laMegatronStrategyforme de Nemo. Notez que l'entraînement sans points de contrôle doit être au moinsnum_distributed_optimizer_instanceségal à 2 pour qu'il y ait une réplication de l'optimiseur. La stratégie prend également en charge l'enregistrement des attributs essentiels et l'initialisation des groupes de processus, par exemple, sans root.CheckpointlessCallback: Lightning callback qui intègre la NeMo formation au système de tolérance aux pannes de Checkpointless Training. Ses principales responsabilités sont les suivantes :Gestion du cycle de vie des étapes d'entraînement : suit les progrès de l'entraînement et coordonne la reprise enable/disable sans point de contrôle en fonction de l'état de l'entraînement (première étape par rapport aux étapes suivantes). ParameterUpdateLock
Coordination de l'état des points de contrôle : gère la sauvegarde/restauration des points de contrôle du modèle de base PEFT en mémoire.
CheckpointlessCompatibleConnector: une PTLCheckpointConnectorqui tente de précharger le fichier de point de contrôle en mémoire, le chemin source étant déterminé selon cette priorité :essayez Checkpoint Recovery
si checkpointless renvoie None, revenez à parent.resume_start ()
Consultez l'exemple
Concepts
Cette section présente les concepts de formation sans points de contrôle. La formation Checkpointless sur Amazon SageMaker HyperPod prend en charge la restauration en cours de processus. Cette interface API suit un format similaire à celui du NVRx APIs.
Concept - Bloc de code réexécutable (RCB)
En cas d'échec, les processus sains restent actifs, mais une partie du code doit être réexécutée pour récupérer les états d'apprentissage et les piles Python. Un bloc de code réexécutable (RCB) est un segment de code spécifique qui s'exécute à nouveau lors d'une reprise après échec. Dans l'exemple suivant, le RCB englobe l'intégralité du script d'entraînement (c'est-à-dire tout ce qui se trouve sous main ()), ce qui signifie que chaque reprise après échec redémarre le script d'entraînement tout en préservant le modèle en mémoire et les états de l'optimiseur.
Concept - Contrôle des défauts
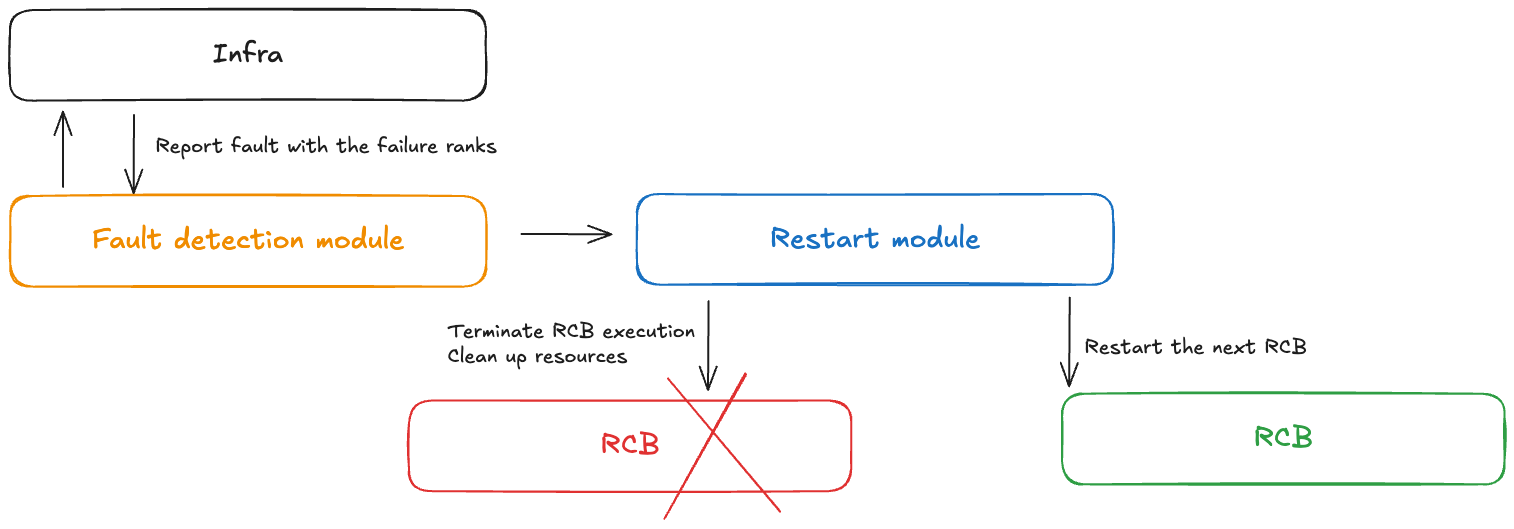
Un module de contrôle des défaillances reçoit des notifications en cas de panne lors d'un entraînement sans point de contrôle. Ce contrôleur de défauts inclut les composants suivants :
Module de détection des défauts : reçoit les notifications de défaillance de l'infrastructure
Définition du RCB APIs : permet aux utilisateurs de définir le bloc de code réexécutable (RCB) dans leur code
Module de redémarrage : met fin au RCB, nettoie les ressources et redémarre le RCB
Concept - Redondance du modèle
L'entraînement de grands modèles nécessite généralement une taille de données parallèle suffisamment importante pour entraîner les modèles de manière efficace. Dans le cadre du parallélisme de données traditionnel tel que PyTorch DDP et Horovod, le modèle est entièrement répliqué. Des techniques de parallélisme de données partitionnées plus avancées, telles que l'optimiseur DeepSpeed ZERO et le FSDP, prennent également en charge le mode de partitionnement hybride, qui permet de partitionner les model/optimizer états au sein du groupe de partitionnement et de les répliquer entièrement entre les groupes de réplication. NeMo possède également cette fonctionnalité de partitionnement hybride via un argument num_distributed_optimizer_instances, qui permet la redondance.
Cependant, l'ajout de redondance indique que le modèle ne sera pas entièrement segmenté sur l'ensemble du cluster, ce qui entraînera une augmentation de l'utilisation de la mémoire de l'appareil. La quantité de mémoire redondante varie en fonction des techniques spécifiques de partitionnement du modèle mises en œuvre par l'utilisateur. Les poids, les dégradés et la mémoire d'activation du modèle de faible précision ne seront pas affectés, car ils sont fragmentés par le parallélisme du modèle. Les états du modèle principal de haute précision weights/gradients et de l'optimiseur seront affectés. L'ajout d'une réplique de modèle redondante augmente l'utilisation de la mémoire de l'appareil d'environ l'équivalent de la taille d'un point de contrôle DCP.
Le sharding hybride divise les collectifs de l'ensemble des groupes DP en collectifs relativement plus petits. Auparavant, il y avait une réduction de la diffusion et un regroupement global dans l'ensemble du groupe de personnes déplacées. Après le sharding hybride, la réduction de la diffusion ne s'exécute qu'à l'intérieur de chaque réplique du modèle, et il y aura une réduction totale entre les groupes de répliques de modèles. Le all-gather se déroule également à l'intérieur de chaque réplique du modèle. Par conséquent, l'ensemble du volume de communication reste pratiquement inchangé, mais les collectifs fonctionnent avec des groupes plus restreints. Nous nous attendons donc à une meilleure latence.
Concept - Types de panne et de redémarrage
Le tableau suivant enregistre les différents types de défaillances et les mécanismes de restauration associés. L'entraînement sans point de contrôle tente d'abord de remédier aux défaillances via une restauration en cours de processus, suivie d'un redémarrage au niveau du processus. Il revient à un redémarrage au niveau de la tâche uniquement en cas de panne catastrophique (par exemple, plusieurs nœuds tombent en panne en même temps).
| Type de panne | Cause | Type de récupération | Mécanisme de rétablissement |
|---|---|---|---|
| Défaillance en cours de processus | Erreurs au niveau du code, exceptions | Restauration en cours de processus (IPR) | Réexécutez RCB dans le cadre du processus existant ; les processus sains restent actifs |
| Échec du redémarrage du processus | Contexte CUDA corrompu, processus arrêté | Redémarrage au niveau du processus (PLR) | SageMaker HyperPod l'opérateur de formation redémarre les processus ; ignore le redémarrage du pod K8 |
| Défaillance du remplacement du nœud | node/GPU Défaillance matérielle permanente | Redémarrage au niveau du travail (JLR) | Remplacez le nœud défaillant ; redémarrez l'intégralité de la tâche d'entraînement |
Concept - Protection par verrouillage atomique pour l'étape d'optimisation
L'exécution du modèle est divisée en trois phases : propagation vers l'avant, propagation vers l'arrière et étape d'optimisation. Le comportement de restauration varie en fonction du moment de l'échec :
Propagation avant/arrière : revenez au début de l'étape d'apprentissage en cours et diffusez les états du modèle vers le ou les nœuds de remplacement
Étape d'optimisation : autorisez les répliques saines à terminer l'étape sous protection par verrouillage, puis diffusez les états du modèle mis à jour vers le ou les nœuds de remplacement
Cette stratégie garantit que les mises à jour complètes de l'optimiseur ne sont jamais annulées, ce qui contribue à réduire le temps de réparation en cas de panne.
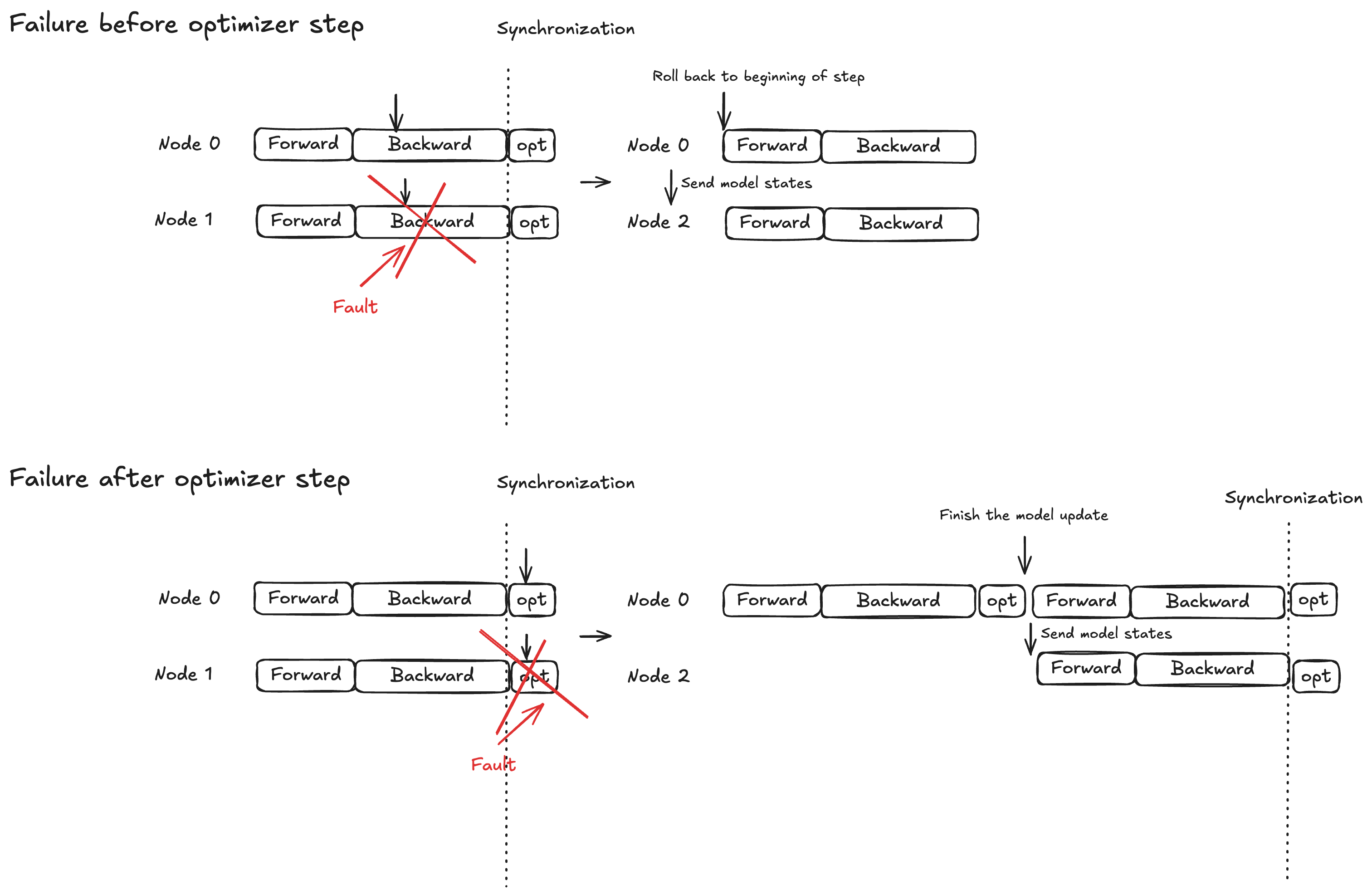
Schéma du flux d'entraînement sans point de contrôle
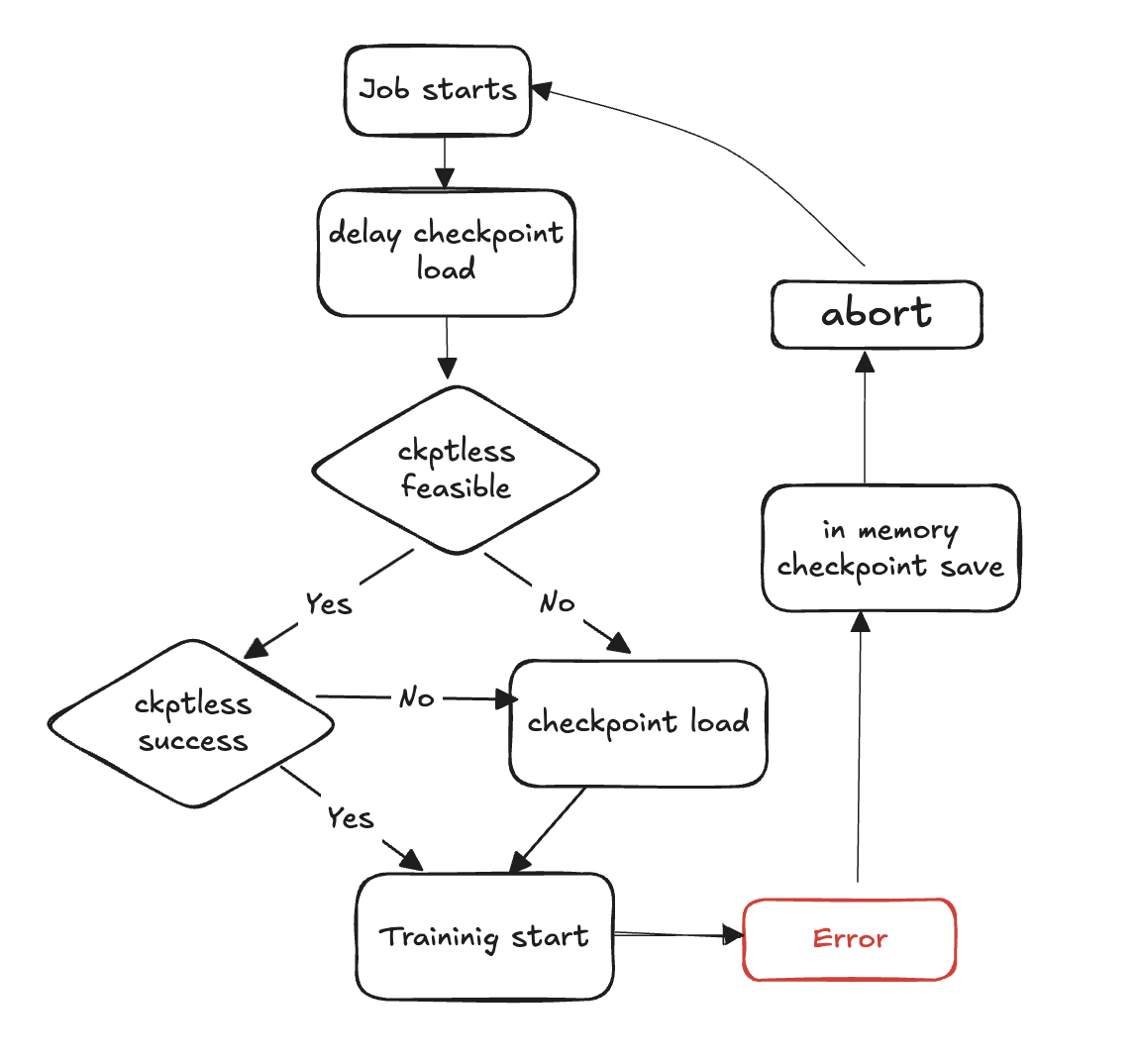
Les étapes suivantes décrivent le processus de détection des défaillances et de restauration sans point de contrôle :
La boucle d'entraînement démarre
Un défaut se produit
Évaluez la faisabilité d'un CV sans points de contrôle
Vérifiez s'il est possible de faire un CV sans point de contrôle
Si possible, essayez un CV sans point de contrôle
En cas d'échec de la reprise, retour au point de contrôle lors du chargement depuis le stockage
En cas de réussite de la reprise, la formation continue à partir de l'état rétabli
Si cela n'est pas faisable, revenez au point de contrôle pour le chargement après le stockage
Nettoyez les ressources : abandonnez tous les groupes de processus et tous les backends et libérez des ressources en vue du redémarrage.
Reprendre la boucle d'entraînement : une nouvelle boucle d'entraînement commence et le processus revient à l'étape 1.
Référence des API
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Attend et récupère les informations de classement HyperPod, puis met à jour l'environnement de processus actuel avec des variables d'apprentissage distribuées.
Cette fonction obtient l'attribution de grade et les variables d'environnement correctes pour l'entraînement distribué. Cela garantit que chaque processus reçoit la configuration appropriée pour son rôle dans le travail de formation distribué.
Paramètres
Aucune
Renvoie
Aucun
Comportement
Vérification du processus : ignore l'exécution s'il est appelé depuis un sous-processus (ne s'exécute que dans) MainProcess
Récupération de l'environnement : obtient les variables d'environnement actuelles
RANKetWORLD_SIZEà partir de celles-ciHyperPod Communication : appels
hyperpod_wait_rank_info()pour récupérer des informations de classement auprès de HyperPodMise à jour de l'environnement : met à jour l'environnement de processus actuel avec les variables d'environnement spécifiques au travailleur reçues de HyperPod
Variables d'environnement
La fonction lit les variables d'environnement suivantes :
RANK (int) — Classement actuel du processus (par défaut : -1 s'il n'est pas défini)
WORLD_SIZE (int) — Nombre total de processus dans le travail distribué (par défaut : 0 s'il n'est pas défini)
Augmente
AssertionError— Si la réponse de n' HyperPod est pas dans le format attendu ou si les champs obligatoires sont manquants
Exemple
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Remarques
S'exécute uniquement dans le processus principal ; les appels de sous-processus sont automatiquement ignorés
La fonction bloque jusqu'à ce qu' HyperPod elle fournisse les informations de classement
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Enveloppeur de fonctions Python qui active les capacités de redémarrage d'un bloc de code réexécutable (RCB) lors d'un entraînement sans point de contrôle. HyperPod
Ce wrapper fournit des fonctionnalités de tolérance aux pannes et de restauration automatique en surveillant l'exécution de la formation et en coordonnant les redémarrages entre les processus distribués en cas de défaillance. Il utilise une approche de gestionnaire de contexte plutôt qu'un décorateur pour gérer les ressources globales tout au long du cycle de vie de la formation.
Paramètres
abort (Abort, facultatif) : interrompt l'exécution de manière asynchrone lorsque des défaillances sont détectées. Valeur par défaut :
Compose(HPAbortTorchDistributed())finalize (Finalize, facultatif) — Gestionnaire de finalisation local exécuté au redémarrage. Valeur par défaut :
Nonehealth_check (HealthCheckfacultatif) — Contrôle de santé local exécuté lors du redémarrage. Valeur par défaut :
Nonehp_api_factory (Appelable, facultatif) — Fonction d'usine permettant de créer une HyperPod API avec laquelle interagir. HyperPod Valeur par défaut :
Noneabort_timeout (float, facultatif) — Délai d'expiration pour l'appel d'abandon dans le thread de contrôle des pannes. Valeur par défaut :
Noneactivé (bool, facultatif) — Active la fonctionnalité du wrapper. Quand
False, l'emballage devient un pass-through. Valeur par défaut :Truetrace_file_path (str, facultatif) — Chemin d'accès au fichier de trace pour le profilage. VizTracer Valeur par défaut :
Noneasync_raise_before_abort (bool, facultatif) — Active la relance avant l'abandon dans le thread de contrôle des pannes. Valeur par défaut :
Trueearly_abort_communicator (bool, facultatif) — Abandonne le communicateur (NCCL/Gloo) avant d'abandonner le chargeur de données. Valeur par défaut :
Falsecheckpoint_manager (Any, facultatif) — Gestionnaire de gestion des points de contrôle lors de la restauration. Valeur par défaut :
Nonecheck_memory_status (bool, facultatif) — Active la vérification et la journalisation de l'état de la mémoire. Valeur par défaut :
True
Méthodes
def __call__(self, fn)
Encapsule une fonction pour activer les fonctionnalités de redémarrage.
Paramètres :
fn (Callable) — La fonction à encapsuler avec des capacités de redémarrage
Retours :
Appelable — Fonction encapsulée avec capacité de redémarrage, ou fonction d'origine si elle est désactivée
Exemple
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Remarques
L'emballage doit
torch.distributedêtre disponibleLorsque
enabled=False, le wrapper devient un pass-through et renvoie la fonction d'origine inchangéeLe wrapper gère les ressources globales telles que les fils de surveillance tout au long du cycle de vie de la formation
Soutient VizTracer le profilage lorsqu'
trace_file_pathil est fourniS'intègre HyperPod pour une gestion coordonnée des pannes dans le cadre d'une formation distribuée
HPCallEmballage
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Surveille et gère l'état d'un bloc de code de redémarrage (RCB) pendant son exécution.
Cette classe gère le cycle de vie de l'exécution du RCB, y compris la détection des défaillances, la coordination avec les autres grades pour les redémarrages et les opérations de nettoyage. Il gère la synchronisation distribuée et garantit une restauration cohérente dans tous les processus de formation.
Paramètres
wrapper (HPWrapper) — Le wrapper parent contenant les paramètres globaux de restauration en cours de processus
Attributs
step_upon_restart (int) — Compteur qui suit les étapes depuis le dernier redémarrage, utilisé pour déterminer la stratégie de redémarrage
Méthodes
def initialize_barrier()
Attendez la synchronisation des HyperPod barrières après avoir rencontré une exception provenant de RCB.
def start_hp_fault_handling_thread()
Démarrez le thread de gestion des pannes pour surveiller et coordonner les défaillances.
def handle_fn_exception(call_ex)
Exceptions de traitement issues de la fonction d'exécution ou du RCB.
Paramètres :
call_ex (Exception) — Exception à la fonction de surveillance
def restart(term_ex)
Exécutez le gestionnaire de redémarrage, y compris la finalisation, le ramassage des déchets et les contrôles de santé.
Paramètres :
term_ex (RankShouldRestart) — Exception de terminaison déclenchant le redémarrage
def launch(fn, *a, **kw)
Exécutez le RCB en gérant correctement les exceptions.
Paramètres :
fn (Callable) — Fonction à exécuter
a — Arguments de la fonction
kw — Arguments du mot-clé d'une fonction
def run(fn, a, kw)
Boucle d'exécution principale qui gère les redémarrages et la synchronisation des barrières.
Paramètres :
fn (Callable) — Fonction à exécuter
a — Arguments de la fonction
kw — Arguments du mot-clé d'une fonction
def shutdown()
Arrêtez les threads de gestion et de surveillance des pannes.
Remarques
Gère automatiquement les
RankShouldRestartexceptions pour une restauration coordonnéeGère le suivi de la mémoire et les abandons, ainsi que la collecte des déchets lors des redémarrages
Supporte à la fois les stratégies de restauration en cours de processus et les stratégies PLR (redémarrage au niveau du processus) en fonction du calendrier des défaillances
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Garantit que le contexte CUDA du processus en cours est en bon état pendant la reprise d'entraînement sans points de contrôle.
Ce contrôle de santé est synchronisé avec le GPU pour vérifier que le contexte CUDA n'est pas endommagé après un échec d'entraînement. Il effectue des opérations de synchronisation du GPU pour détecter tout problème susceptible d'empêcher la reprise réussie de l'entraînement. Le bilan de santé est exécuté une fois que les groupes distribués sont détruits et que la finalisation est terminée.
Paramètres
timeout (datetime.timedelta, facultatif) : durée du délai d'attente pour les opérations de synchronisation du GPU. Valeur par défaut :
datetime.timedelta(seconds=30)
Méthodes
__call__(state, train_ex=None)
Exécutez le contrôle de santé CUDA pour vérifier l'intégrité du contexte du GPU.
Paramètres :
state (HPState) — HyperPod État actuel contenant le classement et les informations distribuées
train_ex (Exception, optionnelle) — L'exception d'entraînement d'origine qui a déclenché le redémarrage. Valeur par défaut :
None
Retours :
tuple — Un tuple contenant la valeur
(state, train_ex)inchangée si le bilan de santé est réussi
Augmente :
TimeoutError— Si la synchronisation du GPU expire, cela indique un contexte CUDA potentiellement corrompu
Préservation de l'état : renvoie l'état d'origine et l'exception inchangés si toutes les vérifications sont réussies
Exemple
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Remarques
Utilise le threading pour implémenter la protection contre le délai d'expiration pour la synchronisation du GPU
Conçu pour détecter les contextes CUDA corrompus susceptibles d'empêcher la reprise réussie de l'entraînement
Doit être utilisé dans le cadre du pipeline de tolérance aux pannes dans les scénarios de formation distribuée
HPAgentK8 APIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Classe d'usine permettant de créer des instances HPAgent K8SAPI communiquant avec l' HyperPod infrastructure pour la coordination distribuée des formations.
Cette usine fournit un moyen standardisé de créer et de configurer des objets HPAgent K8SAPI qui gèrent la communication entre les processus de formation et le HyperPod plan de contrôle. Il encapsule la création du client de socket sous-jacent et de l'instance d'API, garantissant ainsi une configuration cohérente entre les différentes parties du système de formation.
Méthodes
__call__()
Créez et renvoyez une instance HPAgent K8SAPI configurée pour la communication. HyperPod
Retours :
HPAgentK8sAPI — Instance d'API configurée pour communiquer avec l'infrastructure HyperPod
Exemple
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Remarques
Conçu pour fonctionner parfaitement avec l'infrastructure basée HyperPod sur Kubernetes. Il est essentiel pour la gestion coordonnée des pannes et la restauration dans les scénarios de formation distribués
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Gère les points de contrôle en mémoire et la peer-to-peer restauration pour une tolérance aux pannes sans point de contrôle dans le cadre de la formation distribuée.
Cette classe fournit les fonctionnalités de base pour l'entraînement HyperPod sans points de contrôle en gérant les points de contrôle des NeMo modèles en mémoire, en validant la faisabilité de la restauration et en orchestrant le transfert des points de peer-to-peer contrôle entre les rangs sains et les rangs défaillants. Il élimine le besoin d'utiliser un disque I/O pendant la restauration, réduisant ainsi considérablement le temps moyen de restauration (MTTR).
Paramètres
enable_checksum (bool, facultatif) — Active la validation de la somme de contrôle de l'état du modèle pour les contrôles d'intégrité lors de la restauration. Valeur par défaut :
Falseenable_offload (bool, facultatif) — Activez le déchargement des points de contrôle de la mémoire du GPU vers la mémoire du processeur afin de réduire l'utilisation de la mémoire du processeur graphique. Valeur par défaut :
False
Attributs
global_step (int or None) — Étape d'entraînement actuelle associée au point de contrôle enregistré
rng_states (list or None) — États du générateur de nombres aléatoires enregistrés pour une restauration déterministe
checksum_manager (MemoryChecksumManager) — Gestionnaire pour la validation de la somme de contrôle de l'état du modèle
parameter_update_lock (ParameterUpdateLock) — Verrou pour coordonner les mises à jour des paramètres lors de la restauration
Méthodes
save_checkpoint(trainer)
Enregistrez le point de contrôle NeMo du modèle en mémoire pour une éventuelle restauration sans point de contrôle.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Remarques :
Appelé par CheckpointlessCallback à la fin du lot ou lors de la gestion des exceptions
Crée des points de restauration sans I/O surcharge de disque
Stocke les états complets du modèle, de l'optimiseur et du planificateur
delete_checkpoint()
Supprimez le point de contrôle en mémoire et effectuez des opérations de nettoyage.
Remarques :
Efface les données des points de contrôle, les états RNG et les tenseurs mis en cache
Effectue la collecte des déchets et le nettoyage du cache CUDA
Appelé après une restauration réussie ou lorsque le point de contrôle n'est plus nécessaire
try_checkpointless_load(trainer)
Essayez une restauration sans point de contrôle en chargeant l'état à partir des rangs des pairs.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Retours :
dict or None — Point de contrôle restauré en cas de succès, None si le repli sur le disque est nécessaire
Remarques :
Point d'entrée principal pour une restauration sans point de contrôle
Valide la faisabilité de la restauration avant de tenter un transfert P2P
Nettoie toujours les points de contrôle en mémoire après une tentative de restauration
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Déterminez si une restauration sans point de contrôle est possible pour le scénario de défaillance actuel.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
include_checksum_verification (bool, facultatif) — S'il faut inclure la validation de la somme de contrôle. Valeur par défaut :
True
Retours :
bool — True si la restauration sans point de contrôle est possible, False dans le cas contraire
Critères de validation :
Cohérence globale des échelons dans les rangs sains
Nombre suffisant de répliques saines disponibles pour la restauration
Intégrité de la somme de contrôle de l'état du modèle (si activée)
store_rng_states()
Stockez tous les états du générateur de nombres aléatoires pour une restauration déterministe.
Remarques :
Capture les états de Python NumPy, PyTorch CPU/GPU et Megatron RNG
Essentiel pour maintenir le déterminisme de l'entraînement après la convalescence
load_rng_states()
Restaurez tous les états RNG pour poursuivre la restauration déterministe.
Remarques :
Restaure tous les états RNG précédemment stockés
Garantit la poursuite de l'entraînement avec des séquences aléatoires identiques
maybe_offload_checkpoint()
Déchargez le point de contrôle du GPU vers la mémoire du processeur si le déchargement est activé.
Remarques :
Réduit l'utilisation de la mémoire du GPU pour les grands modèles
Ne s'exécute que si
enable_offload=TrueMaintient l'accessibilité des points de contrôle pour le rétablissement
Exemple
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Validation : vérifie l'intégrité du point de contrôle à l'aide de sommes de contrôle (si activé)
Remarques
Utilise des primitives de communication distribuées pour un transfert P2P efficace
Gère automatiquement les conversions de type tenseur et le placement des appareils
MemoryChecksumManager— Gère la validation de l'intégrité de l'état du modèle
PEFTCheckpointDirecteur
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Gère les points de contrôle pour le PEFT (Parameter-Efficient Fine-Tuning) avec une gestion séparée de la base et de l'adaptateur pour une restauration optimisée sans point de contrôle.
Ce gestionnaire de points de contrôle spécialisé permet CheckpointManager d'optimiser les flux de travail PEFT en séparant les poids du modèle de base des paramètres de l'adaptateur.
Paramètres
Hérite de tous les paramètres de CheckpointManager:
enable_checksum (bool, facultatif) — Active la validation de la somme de contrôle de l'état du modèle. Valeur par défaut :
Falseenable_offload (bool, facultatif) — Active le déchargement des points de contrôle vers la mémoire du processeur. Valeur par défaut :
False
Attributs supplémentaires
params_to_save (set) — Ensemble de noms de paramètres qui doivent être enregistrés en tant que paramètres d'adaptateur
base_model_weights (dict or None) — Poids du modèle de base mis en cache, enregistrés une fois et réutilisés
base_model_keys_to_extract (list or None) — Clés pour extraire les tenseurs du modèle de base lors d'un transfert P2P
Méthodes
maybe_save_base_model(trainer)
Enregistrez les poids du modèle de base une seule fois, en filtrant les paramètres de l'adaptateur.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Remarques :
Enregistre les poids du modèle de base uniquement lors du premier appel ; les appels suivants ne sont pas opérationnels
Filtre les paramètres de l'adaptateur pour ne stocker que les poids du modèle de base figés
Les poids du modèle de base sont préservés pendant plusieurs séances d'entraînement
save_checkpoint(trainer)
Enregistrez le point de contrôle du modèle d'adaptateur NeMo PEFT en mémoire pour une éventuelle restauration sans point de contrôle.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Remarques :
Appelle automatiquement
maybe_save_base_model()si le modèle de base n'est pas encore enregistréFiltre le point de contrôle pour inclure uniquement les paramètres de l'adaptateur et l'état d'entraînement
Réduit considérablement la taille des points de contrôle par rapport aux points de contrôle du modèle complet
try_base_model_checkpointless_load(trainer)
Essayez de récupérer les poids du modèle de base PEFT sans point de contrôle en chargeant l'état à partir des rangs des pairs.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Retours :
dict or None — Point de contrôle du modèle de base restauré en cas de succès, None si une solution de secours est nécessaire
Remarques :
Utilisé lors de l'initialisation du modèle pour récupérer les poids du modèle de base
Ne nettoie pas les poids du modèle de base après la récupération (conserve en vue de sa réutilisation)
Optimisé pour les scénarios model-weights-only de restauration
try_checkpointless_load(trainer)
Essayez de pondérer la récupération sans point de contrôle de l'adaptateur PEFT en chargeant l'état à partir des rangs des pairs.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Retours :
dict or None — Point de contrôle de l'adaptateur restauré en cas de succès, None si une solution de secours est nécessaire
Remarques :
Récupère uniquement les paramètres de l'adaptateur, les états de l'optimiseur et les planificateurs
Charge automatiquement les états de l'optimiseur et du planificateur après une restauration réussie
Nettoie les points de contrôle de l'adaptateur après une tentative de restauration
is_adapter_key(key)
Vérifiez si la clé state dict appartient aux paramètres de l'adaptateur.
Paramètres :
key (str ou tuple) — Clé d'état à vérifier
Retours :
bool — True si la clé est un paramètre d'adaptateur, False si le paramètre du modèle de base
Logique de détection :
Vérifie si la clé est
params_to_saveactivéeIdentifie les clés contenant « .adapter ». substring
Identifie les clés se terminant par « .adapters »
Pour les clés de tuple, vérifie si le paramètre nécessite des dégradés
maybe_offload_checkpoint()
Déchargez les pondérations du modèle de base du GPU vers la mémoire du processeur.
Remarques :
Étend la méthode parent pour gérer le déchargement du poids du modèle de base
Les poids des adaptateurs sont généralement petits et ne nécessitent pas de déchargement
Définit un indicateur interne pour suivre l'état du déchargement
Remarques
Conçu spécifiquement pour les scénarios de réglage précis utilisant efficacement les paramètres (LoRa, adaptateurs, etc.)
Gère automatiquement la séparation des paramètres du modèle de base et de l'adaptateur
Exemple
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Classe d'usine permettant de créer et de gérer des compositions de composants abandonnées pour une tolérance aux pannes sans point de contrôle.
Cette classe utilitaire fournit des méthodes statiques pour créer, personnaliser et gérer les compositions de composants d'abandon utilisées lors de la gestion des pannes dans le cadre d'un entraînement sans HyperPod point de contrôle. Il simplifie la configuration des séquences d'interruption qui gèrent le nettoyage des composants de formation distribués, des chargeurs de données et des ressources spécifiques au framework lors de la reprise après défaillance.
Paramètres
Aucune (toutes les méthodes sont statiques)
Méthodes statiques
get_default_checkpointless_abort()
Obtenez l'instance abort compose par défaut contenant tous les composants d'abort standard.
Retours :
Compose — Instance d'abandon composée par défaut avec tous les composants d'abandon
Composants par défaut :
AbortTransformerEngine() — Nettoie les ressources TransformerEngine
HPCheckpointingAbort () — Gère le nettoyage du système de points de contrôle
HPAbortTorchDistributed() — Annule les opérations PyTorch distribuées
HPDataLoaderAbort() — Arrête et nettoie les chargeurs de données
create_custom_abort(abort_instances)
Créez une composition d'abandon personnalisée avec uniquement les instances d'abandon spécifiées.
Paramètres :
abort_instances (Abort) — Nombre variable d'instances d'abandon à inclure dans la composition
Retours :
Compose — Nouvelle instance d'abandon composée contenant uniquement les composants spécifiés
Augmente :
ValueError— Si aucune instance d'abandon n'est fournie
override_abort(abort_compose, abort_type, new_abort)
Remplacez un composant d'abandon spécifique dans une instance de Compose par un nouveau composant.
Paramètres :
abort_compose (Compose) — L'instance Compose d'origine à modifier
abort_type (type) — Le type de composant d'abandon à remplacer (par exemple,)
HPCheckpointingAbortnew_abort (Abort) — La nouvelle instance d'abandon à utiliser en remplacement
Retours :
Compose — Nouvelle instance de Compose avec le composant spécifié remplacé
Augmente :
ValueError— Si abort_compose n'a pas d'attribut « instances »
Exemple
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Remarques
Les configurations personnalisées permettent un contrôle précis du comportement de nettoyage
Les opérations d'interruption sont essentielles pour un nettoyage correct des ressources lors de la reprise après panne
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Effectue un nettoyage complet après la détection d'un défaut afin de préparer la restauration en cours de processus lors d'une formation sans point de contrôle.
Ce gestionnaire de finalisation exécute des opérations de nettoyage spécifiques au framework, notamment l' Megatron/TransformerEngine abandon, le nettoyage DDP, le rechargement des modules et le nettoyage de la mémoire en détruisant les références aux composants d'entraînement. Cela garantit que l'environnement de formation est correctement réinitialisé pour une restauration en cours de processus réussie sans nécessiter l'arrêt complet du processus.
Paramètres
Aucune
Attributs
trainer (PyTorch_Lightning.Trainer or None) — Référence à l'instance Lightning Trainer PyTorch
Méthodes
__call__(*a, **kw)
Exécutez des opérations de nettoyage complètes pour préparer la restauration en cours de processus.
Paramètres :
a — Arguments positionnels variables (hérités de l'interface Finalize)
kw — Arguments de mots clés variables (hérités de l'interface Finalize)
Opérations de nettoyage :
Megatron Framework Cleanup — Appels à nettoyer les ressources spécifiques
abort_megatron()à MegatronTransformerEngine Nettoyage — Appels
abort_te()à nettoyer les ressources TransformerEngineRope Cleanup — Appels
cleanup_rope()pour nettoyer les ressources d'intégration des positions rotativesDDP Cleanup — Appels
cleanup_ddp()à nettoyer les ressources DistributedDataParallelRechargement de modules — Appels
reload_megatron_and_te()pour recharger les modules du frameworkNettoyage du module Lightning : efface éventuellement le module Lightning pour réduire la mémoire du processeur graphique
Nettoyage de la mémoire — Détruit les références aux composants d'entraînement pour libérer de la mémoire
register_attributes(trainer)
Enregistrez l'instance de formation pour l'utiliser lors des opérations de nettoyage.
Paramètres :
trainer (PyTorch_Lightning.Trainer) — Instance Lightning Trainer à enregistrer PyTorch
Intégration avec CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Remarques
Les opérations de nettoyage sont exécutées dans un ordre spécifique afin d'éviter les problèmes de dépendance
Le nettoyage de la mémoire utilise l'introspection de la collecte des déchets pour trouver les objets cibles
Toutes les opérations de nettoyage sont conçues pour être idempotentes et peuvent être réessayées en toute sécurité.
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Stratégie Megatron avec fonctionnalités intégrées de restauration sans point de contrôle pour un entraînement distribué tolérant aux pannes.
Notez que l'entraînement sans points de contrôle doit être au moins num_distributed_optimizer_instances égal à 2 pour qu'il y ait une réplication de l'optimiseur. La stratégie prend également en charge l'enregistrement des attributs essentiels et l'initialisation des groupes de processus.
Paramètres
Hérite de tous les paramètres de MegatronStrategy:
Paramètres d' NeMo MegatronStrategy initialisation standard
Options de configuration de formation distribuée
Paramètres de parallélisme du modèle
Attributs
base_store (torch.distributed). TCPStore(ou aucun) : magasin distribué pour la coordination des groupes de processus
Méthodes
setup(trainer)
Initialisez la stratégie et enregistrez les composants de tolérance aux pannes auprès du formateur.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Opérations de configuration :
Configuration du parent : appelle le programme de MegatronStrategy configuration du parent
Enregistrement de l'injection de défauts — Enregistre les HPFault InjectionCallback crochets s'ils sont présents
Finalisation de l'inscription — Enregistre le formateur auprès des responsables du nettoyage
Abandonner l'enregistrement — Enregistre le formateur auprès des gestionnaires d'abandon qui le prennent en charge
setup_distributed()
Initialisez le groupe de processus à l'aide d'un préfixe ou d' TCPStore une connexion sans racine.
load_model_state_dict(checkpoint, strict=True)
Chargez le modèle state dict avec compatibilité de restauration sans point de contrôle.
Paramètres :
point de contrôle (Mapping [str, Any]) — Dictionnaire de points de contrôle contenant l'état du modèle
strict (bool, facultatif) — S'il faut appliquer strictement la correspondance des clés state dict. Valeur par défaut :
True
get_wrapper()
Obtenez l'instance HPCall Wrapper pour la coordination de la tolérance aux pannes.
Retours :
HPCallWrapper : instance de wrapper attachée au formateur pour la tolérance aux pannes
is_peft()
Vérifiez si le PEFT (Parameter-Efficient Fine-Tuning) est activé dans la configuration d'entraînement en vérifiant les rappels PEFT
Retours :
bool — True si le rappel PEFT est présent, False dans le cas contraire
teardown()
Remplacez le PyTorch démontage natif de Lightning pour déléguer le nettoyage aux gestionnaires d'abandon.
Exemple
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Lightning Callback qui intègre la NeMo formation au système de tolérance aux pannes de checkpointless Training.
Ce rappel gère le suivi des étapes, la sauvegarde des points de contrôle et la coordination des mises à jour des paramètres pour les capacités de restauration en cours de processus. Il constitue le principal point d'intégration entre les boucles d'entraînement PyTorch Lightning et les mécanismes de formation HyperPod sans point de contrôle, coordonnant les opérations de tolérance aux pannes tout au long du cycle de formation.
Paramètres
enable_inprocess (bool, facultatif) — Active les fonctionnalités de restauration en cours de processus. Valeur par défaut :
Falseenable_checkpointless (bool, facultatif) — Active la restauration sans point de contrôle (obligatoire).
enable_inprocess=TrueValeur par défaut :Falseenable_checksum (bool, facultatif) — Active la validation de la somme de contrôle de l'état du modèle (obligatoire).
enable_checkpointless=TrueValeur par défaut :Falseclean_tensor_hook (bool, facultatif) — Supprimez les crochets tensoriels de tous les tenseurs du GPU pendant le nettoyage (opération coûteuse). Valeur par défaut :
Falseclean_lightning_module (bool, facultatif) — Activez le nettoyage du module Lightning pour libérer de la mémoire GPU après chaque redémarrage. Valeur par défaut :
False
Attributs
tried_adapter_checkpointless (bool) — Indicateur permettant de savoir si une restauration sans point de contrôle de l'adaptateur a été tentée
Méthodes
get_wrapper_from_trainer(trainer)
Obtenez l'instance HPCall Wrapper auprès du formateur pour la coordination de la tolérance aux pannes.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Retours :
HPCallWrapper — L'instance de wrapper pour les opérations de tolérance aux pannes
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Appelé au début de chaque session de formation pour gérer le suivi des étapes et la récupération.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Module Lightning en cours de formation
batch — Données du lot d'entraînement actuel
batch_idx (int) — Index du lot en cours
args — Arguments positionnels supplémentaires
kwargs — Arguments de mots clés supplémentaires
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Relâchez le verrou de mise à jour des paramètres à la fin de chaque lot d'apprentissage.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Module Lightning en cours de formation
sorties (STEP_OUTPUT) — Sorties des étapes d'entraînement
batch (Any) — Données du lot d'entraînement actuel
batch_idx (int) — Index du lot en cours
Remarques :
Le moment du déverrouillage garantit que la restauration sans point de contrôle peut se poursuivre une fois les mises à jour des paramètres terminées
Ne s'exécute que lorsque
enable_inprocessles deuxenable_checkpointlesssont vrais
get_peft_callback(trainer)
Récupérez le rappel PEFT dans la liste des rappels du formateur.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
Retours :
PEFT ou None : instance de rappel PEFT si elle est trouvée, None dans le cas contraire
_try_adapter_checkpointless_restore(trainer, params_to_save)
Essayez de restaurer sans point de contrôle les paramètres de l'adaptateur PEFT.
Paramètres :
trainer (PyTorch_Lightning.trainer) — instance Lightning Trainer PyTorch
params_to_save (set) — Ensemble de noms de paramètres à enregistrer en tant que paramètres d'adaptateur
Remarques :
Ne s'exécute qu'une seule fois par séance d'entraînement (contrôlé par un
tried_adapter_checkpointlessdrapeau)Configure le gestionnaire de points de contrôle avec les informations sur les paramètres de l'adaptateur
Exemple
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Gestion de mémoire
clean_tensor_hook : Supprime les crochets tenseurs pendant le nettoyage (coûteux mais complet)
clean_lightning_module : libère de la mémoire graphique du module Lightning lors des redémarrages
Les deux options permettent de réduire l'encombrement de la mémoire lors de la reprise après panne
Se coordonne avec ParameterUpdateLock pour un suivi des mises à jour des paramètres en toute sécurité dans les threads
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Connecteur Lightning Checkpoint qui intègre la restauration sans point de contrôle au chargement par point de contrôle traditionnel sur disque.
Ce connecteur étend celui de PyTorch Lightning _CheckpointConnector pour permettre une intégration parfaite entre la restauration sans point de contrôle et la restauration par point de contrôle standard. Il tente d'abord une restauration sans point de contrôle, puis revient au chargement par point de contrôle sur disque si la restauration sans point de contrôle n'est pas réalisable ou échoue.
Paramètres
Hérite de tous les paramètres de _ CheckpointConnector
Méthodes
resume_start(checkpoint_path=None)
Essayez de précharger le point de contrôle avec une priorité de restauration sans point de contrôle.
Paramètres :
checkpoint_path (str ou None, facultatif) — Chemin d'accès au point de contrôle du disque pour le repli. Valeur par défaut :
None
resume_end()
Terminez le processus de chargement au point de contrôle et effectuez les opérations de post-chargement.
Remarques
PyTorch Étend la
_CheckpointConnectorclasse interne de Lightning grâce à la prise en charge de la restauration sans point de contrôleMaintient une compatibilité totale avec les flux de travail PyTorch Lightning Checkpoint standard
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Prolonge NeMo la AutoResume configuration différée pour permettre la validation de la restauration sans point de contrôle avant la résolution du chemin du point de contrôle.
Cette classe met en œuvre une stratégie d'initialisation en deux phases qui permet la validation de la restauration sans point de contrôle avant de revenir au chargement par point de contrôle traditionnel sur disque. Il retarde la AutoResume configuration de manière conditionnelle pour empêcher la résolution prématurée de la trajectoire des points de contrôle, ce qui permet de valider dans CheckpointManager un premier temps si une restauration sans point de contrôle peer-to-peer est faisable.
Paramètres
Hérite de tous les paramètres de AutoResume
Méthodes
setup(trainer, model=None, force_setup=False)
Retardez la AutoResume configuration de manière conditionnelle pour permettre la validation de la restauration sans point de contrôle.
Paramètres :
trainer (PyTorch_Lightning.Trainer ou Lightning.Fabric.Fabric) — Lightning Trainer ou instance Fabric PyTorch
model (facultatif) — Instance de modèle à configurer. Valeur par défaut :
Noneforce_setup (bool, facultatif) — Si c'est vrai, contournez le délai et exécutez AutoResume la configuration immédiatement. Valeur par défaut :
False
Exemple
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Remarques
AutoResume Classe NeMo d'extension avec mécanisme de temporisation pour permettre une restauration sans point de contrôle
Fonctionne conjointement avec
CheckpointlessCompatibleConnectorpour un flux de travail de restauration complet
