Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de l'entraînement élastique sur Amazon SageMaker HyperPod
Elastic Training est une nouvelle SageMaker HyperPod fonctionnalité d'Amazon qui adapte automatiquement les tâches de formation en fonction de la disponibilité des ressources informatiques et de la priorité de la charge de travail. Les tâches de formation élastiques peuvent commencer avec les ressources de calcul minimales requises pour l'entraînement des modèles, puis augmenter ou diminuer de manière dynamique grâce à des points de contrôle et à une reprise automatiques sur différentes configurations de nœuds (taille mondiale). La mise à l'échelle est réalisée en ajustant automatiquement le nombre de répliques parallèles aux données. Pendant les périodes d'utilisation élevée des clusters, les tâches de formation élastiques peuvent être configurées pour être automatiquement réduites en réponse aux demandes de ressources provenant de tâches plus prioritaires, libérant ainsi du calcul pour les charges de travail critiques. Lorsque les ressources sont libérées pendant les périodes creuses, les tâches de formation élastiques sont automatiquement redimensionnées pour accélérer la formation, puis redimensionnées lorsque les charges de travail prioritaires nécessitent à nouveau des ressources.
La formation élastique repose sur l'opérateur de HyperPod formation et intègre les composants suivants :
-
Amazon SageMaker HyperPod Task Governance pour la mise en file d'attente, la priorisation et la planification des tâches
-
PyTorch Point de contrôle distribué (DCP)
pour une gestion évolutive des états et des points de contrôle, comme le DCP
Cadres pris en charge
-
PyTorch avec Distributed Data Parallel (DDP) et Fully Sharded Data Parallel (FSDP)
-
PyTorch Point de contrôle distribué (DCP)
Conditions préalables
SageMaker HyperPod Cluster EKS
Vous devez disposer d'un SageMaker HyperPod cluster en cours d'exécution avec l'orchestration Amazon EKS. Pour plus d'informations sur la création d'un cluster HyperPod EKS, voir :
SageMaker HyperPod Opérateur de formation
Elastic Training est pris en charge dans Training Operator v. 1.2 et versions ultérieures.
Pour installer l'opérateur de formation en tant que module complémentaire EKS, voir : https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Recommandé) Installer et configurer Task Governance et Kueue
Nous vous recommandons d'installer et de configurer Kueue via HyperPod Task Governance afin de définir les priorités de charge de travail grâce à une formation élastique. Kueue permet une meilleure gestion de la charge de travail grâce à la mise en file d'attente, à la priorisation, à la planification des équipes, au suivi des ressources et à une préemption souple, qui sont essentiels pour opérer dans des environnements de formation à locataires multiples.
-
La planification des équipes garantit que tous les modules nécessaires à un travail de formation démarrent ensemble. Cela permet d'éviter les situations dans lesquelles certains pods démarrent alors que d'autres restent en attente, ce qui pourrait entraîner un gaspillage de ressources.
-
La préemption douce permet aux tâches élastiques moins prioritaires d'affecter des ressources à des charges de travail plus prioritaires. Les tâches élastiques peuvent être progressivement réduites sans être expulsées de force, ce qui améliore la stabilité globale du cluster.
Nous vous recommandons de configurer les composants Kueue suivants :
-
PriorityClasses pour définir l'importance relative du poste
-
ClusterQueues pour gérer le partage global des ressources et les quotas entre les équipes ou les charges de travail
-
LocalQueues pour acheminer les tâches depuis des espaces de noms individuels vers les espaces de noms appropriés ClusterQueue
Pour des configurations plus avancées, vous pouvez également intégrer :
-
Fair-share politiques visant à équilibrer l'utilisation des ressources entre plusieurs équipes
-
Règles de préemption personnalisées pour appliquer les accords de niveau de service organisationnels ou le contrôle des coûts
Veuillez vous référer à :
(Recommandé) Configurer les espaces de noms utilisateur et les quotas de ressources
Lors du déploiement de cette fonctionnalité sur Amazon EKS, nous vous recommandons d'appliquer un ensemble de configurations de base au niveau du cluster afin de garantir l'isolation, l'équité des ressources et la cohérence opérationnelle entre les équipes.
Espace de noms et configuration d'accès
Organisez vos charges de travail en utilisant des espaces de noms distincts pour chaque équipe ou projet. Cela vous permet d'appliquer une isolation et une gouvernance précises. Nous recommandons également de configurer le mappage AWS IAM vers Kubernetes RBAC afin d'associer des utilisateurs ou des rôles IAM individuels à leurs espaces de noms correspondants.
Les principales pratiques sont les suivantes :
-
Associez les rôles IAM aux comptes de service Kubernetes à l'aide des rôles IAM pour les comptes de service (IRSA) lorsque les charges de travail ont besoin d'autorisations. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Appliquez des politiques RBAC pour restreindre les utilisateurs uniquement à leurs espaces de noms désignés (par exemple,
Role/RoleBindingplutôt que des autorisations à l'échelle du cluster).
Contraintes liées aux ressources et au calcul
Pour éviter les conflits de ressources et garantir une planification équitable entre les équipes, appliquez des quotas et des limites au niveau de l'espace de noms :
-
ResourceQuotas pour plafonner le nombre total de processeurs, de mémoire, de stockage et d'objets (pods, PVC, services, etc.).
-
LimitRanges pour appliquer les limites de processeur et de mémoire par défaut et maximum par pod ou par conteneur.
-
PodDisruptionBudgets (PDB) selon les besoins pour définir les attentes en matière de résilience.
-
Facultatif : contraintes de Namespace-level mise en file d'attente (par exemple, via Task Governance ou Kueue) pour empêcher les utilisateurs de soumettre trop de tâches.
Ces contraintes contribuent à maintenir la stabilité du cluster et à garantir une planification prévisible des charges de travail de formation distribuées.
Auto-scaling
SageMaker HyperPod sur EKS prend en charge la mise à l'échelle automatique des clusters via Karpenter. Lorsque Karpenter ou un fournisseur de ressources similaire est utilisé conjointement avec Elastic Training, le cluster ainsi que la tâche de formation Elastic peuvent augmenter automatiquement une fois qu'une tâche de formation élastique a été soumise. Cela s'explique par le fait qu'Elastic Training Operator adopte une approche gourmande et demande toujours plus que les ressources de calcul disponibles jusqu'à atteindre la limite maximale fixée par la tâche. Cela se produit parce que l'opérateur Elastic Training demande en permanence des ressources supplémentaires dans le cadre de l'exécution d'une tâche élastique, ce qui peut déclencher le provisionnement des nœuds. Les fournisseurs de ressources continues tels que Karpenter répondront aux demandes en développant le cluster de calcul.
Pour garantir la prévisibilité et le contrôle de ces mises à l'échelle, nous recommandons de configurer le niveau de l'espace de noms dans les espaces de noms ResourceQuotas dans lesquels les tâches d'entraînement élastiques sont créées. ResourceQuotas contribuent à limiter le maximum de ressources que les tâches peuvent demander, en empêchant la croissance illimitée des clusters tout en permettant un comportement élastique dans les limites définies.
Par exemple, une instance ml.p5.48xlarge ResourceQuota pour 8 aura la forme suivante :
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Construire un conteneur de formation
HyperPod L'opérateur de formation fonctionne avec un PyTorch lanceur personnalisé fourni via le package python d' HyperPod Elastic Agent (https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun commande par hyperpodrun pour lancer la formation. Pour plus de détails, veuillez consulter :
Exemple de conteneur de formation :
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Modification du code de formation
SageMaker HyperPod fournit un ensemble de recettes déjà configurées pour être exécutées avec Elastic Policy.
Pour activer l'entraînement élastique pour les scripts d' PyTorch entraînement personnalisés, vous devez apporter des modifications mineures à votre boucle d'entraînement. Ce guide explique les modifications nécessaires pour garantir que votre formation réponde aux événements de dimensionnement élastique qui se produisent lorsque la disponibilité des ressources informatiques change. Pendant tous les événements élastiques (par exemple, les nœuds sont disponibles ou les nœuds sont préemptés), la tâche de formation reçoit un signal d'événement élastique qui est utilisé pour coordonner un arrêt progressif en enregistrant un point de contrôle, et la reprise de l'entraînement en redémarrant à partir de ce point de contrôle enregistré avec une nouvelle configuration mondiale. Pour activer l'entraînement élastique avec des scripts d'entraînement personnalisés, vous devez :
Détectez les événements Elastic Scaling
Dans votre boucle d'entraînement, vérifiez la présence d'événements élastiques à chaque itération :
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Mettre en œuvre la sauvegarde des points de contrôle et le chargement des points de contrôle
Remarque : nous recommandons d'utiliser le point de contrôle PyTorch distribué (DCP) pour enregistrer les états du modèle et de l'optimiseur, car le DCP prend en charge la reprise à partir d'un point de contrôle dont la taille du monde est différente. Les autres formats de points de contrôle peuvent ne pas prendre en charge le chargement de points de contrôle sur des mondes de différentes tailles, auquel cas vous devrez implémenter une logique personnalisée pour gérer les changements dynamiques de taille du monde.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Facultatif) Utilisez des chargeurs de données dynamiques
Si vous ne vous entraînez que pour une seule époque (c'est-à-dire un seul passage dans l'ensemble de données), le modèle doit voir chaque échantillon de données exactement une fois. Si la tâche de formation s'arrête à mi-époque et reprend avec une taille mondiale différente, les échantillons de données précédemment traités seront répétés si l'état du chargeur de données n'est pas conservé. Un chargeur de données dynamique empêche cela en enregistrant et en rétablissant la position du chargeur de données, garantissant ainsi que les exécutions reprises se poursuivent après l'événement Elastic Scaling sans retraiter aucun échantillon. Nous vous recommandons d'utiliser StatefulDataLoaderstate_dict() et load_state_dict() méthodes, l'activation du point de contrôle intermédiaire du processus de chargement des données. torch.utils.data.DataLoader
Soumission de tâches d'entraînement élastiques
HyperPod un opérateur de formation définit un nouveau type de ressource -hyperpodpytorchjob. Elastic Training étend ce type de ressource et ajoute les champs surlignés ci-dessous :
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Utilisation de kubectl
Vous pouvez ensuite lancer Elastic Training avec la commande suivante.
kubectl apply -f elastic-training-job.yaml
Utiliser des SageMaker recettes
Les tâches d'entraînement élastiques peuvent être lancées par le biais de SageMaker HyperPod recettes
Note
Nous avons inclus 46 recettes élastiques pour les tâches SFO et DPO sur Hyperpod Recipe. Les utilisateurs peuvent lancer ces tâches en modifiant d'une ligne le script de lancement statique existant :
++recipes.elastic_policy.is_elastic=true
Outre les recettes statiques, les recettes élastiques ajoutent les champs suivants pour définir les comportements élastiques :
Politique élastique
Le elastic_policy champ définit la configuration au niveau du travail pour le travail Elastic Training. Il possède les configurations suivantes :
-
is_elastic:bool- si cette tâche est une tâche élastique -
min_nodes:int- le nombre minimum de nœuds utilisés pour l'entraînement élastique -
max_nodes:int- le nombre maximum de nœuds utilisés pour l'entraînement élastique -
replica_increment_step:int- augmente le nombre de pods dans des groupes de taille fixe, ce champ est mutuellement exclusif de celui quescale_confignous définirons ultérieurement. -
use_graceful_shutdown:bool- si vous utilisez un arrêt progressif lors d'événements de dimensionnement, la valeur par défaut esttrue. -
scaling_timeout:int- le temps d'attente en secondes lors de l'événement de dimensionnement avant l'expiration du délai -
graceful_shutdown_timeout:int- le temps d'attente pour un arrêt progressif
Voici un exemple de définition de ce champ, que vous pouvez également trouver dans le dépôt Hyperpod Recipe dans Recipe : recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Config de l'échelle
Le scale_config champ définit les configurations de remplacement à chaque échelle spécifique. Il s'agit d'un dictionnaire clé-valeur, où la clé est un entier représentant l'échelle cible et la valeur est un sous-ensemble de la recette de base. À <key> grande échelle, nous utilisons le <value> pour mettre à jour les configurations spécifiques de la base/static recette. Voici un exemple de ce champ :
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
La configuration ci-dessus définit la configuration d'entraînement aux échelles 2 et 3. Dans les deux cas, nous utilisons le taux d'apprentissage4e-4, la taille du lot de128. Mais à l'échelle 2, nous utilisons un micro_train_batch_size de 8, tandis qu'à l'échelle 3, nous utilisons une taille de lot inégale car la taille du lot de train ne peut pas être répartie uniformément sur 3 nœuds.
Taille de lot inégale
Ce champ permet de définir le comportement de distribution par lots lorsque la taille globale du lot ne peut pas être divisée uniformément par le nombre de rangs. Il n'est pas spécifique à l'entraînement élastique, mais il permet d'affiner la granularité de mise à l'échelle.
-
use_uneven_batch:bool- si vous utilisez une distribution inégale des lots -
num_dp_groups_with_small_batch_size:int- en cas de distribution inégale des lots, certains rangs utilisent une taille de lot locale plus petite, tandis que d'autres utilisent une taille de lot plus grande. La taille globale du lot doit être égale àsmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- cette valeur est la plus petite taille du lot local -
large_local_batch_size:int- cette valeur est la plus grande taille du lot local
Surveillez l'entraînement sur MLflow
Les tâches de recette Hyperpod favorisent l'observabilité grâce à MLflow. Les utilisateurs peuvent spécifier les configurations MLflow dans la recette :
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Ces configurations sont mappées à la configuration MLflow
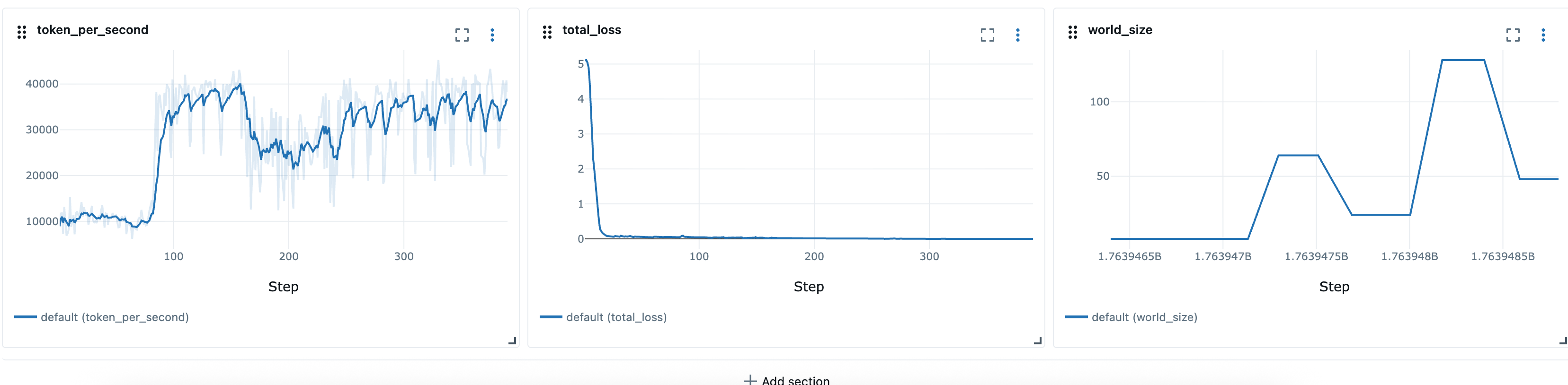
Après avoir défini les recettes élastiques, nous pouvons utiliser les scripts du lanceur, par exemple launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh pour lancer une tâche d'entraînement élastique. Cela revient à lancer une tâche statique à l'aide de la recette Hyperpod.
Note
Les tâches de formation Elastic de Recipe Support reprennent automatiquement à partir des derniers points de contrôle. Toutefois, par défaut, chaque redémarrage crée un nouveau répertoire de formation. Pour permettre la reprise correcte depuis le dernier point de contrôle, nous devons nous assurer que le même répertoire de formation est réutilisé. Cela peut être fait en réglant
recipes.training_config.training_args.override_training_dir=true
Use-case exemples et limites
Scale-up lorsque davantage de ressources sont disponibles
Lorsque davantage de ressources deviennent disponibles sur le cluster (par exemple, d'autres charges de travail sont terminées). Au cours de cet événement, le contrôleur d'entraînement intensifiera automatiquement la tâche de formation. Ce comportement est expliqué ci-dessous.
Pour simuler une situation dans laquelle davantage de ressources sont disponibles, nous pouvons soumettre une tâche hautement prioritaire, puis libérer des ressources en supprimant la tâche hautement prioritaire.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
Comportement attendu :
-
L'opérateur de formation crée une charge de travail Kueue Lorsqu'une tâche de formation élastique demande un changement de taille mondiale, l'opérateur de formation génère un objet de charge de travail Kueue supplémentaire représentant les nouveaux besoins en ressources.
-
Kueue admet que la charge de travail Kueue évalue la demande en fonction des ressources disponibles, des priorités et des politiques de file d'attente. Une fois approuvée, la charge de travail est admise.
-
L'opérateur de formation crée les modules supplémentaires Une fois admis, il lance les modules supplémentaires nécessaires pour atteindre la nouvelle taille du monde.
-
Lorsque les nouveaux modules sont prêts, l'opérateur de formation envoie un signal d'événement élastique spécial au script d'entraînement.
-
La tâche d'entraînement effectue des points de contrôle, afin de préparer un arrêt progressif. Le processus d'entraînement vérifie périodiquement la présence du signal d'événement élastique en appelant la fonction elastic_event_detected (). Une fois détecté, il lance un point de contrôle. Une fois le point de contrôle terminé avec succès, le processus d'entraînement se termine correctement.
-
L'opérateur de formation redémarre la tâche avec la nouvelle taille mondiale. L'opérateur attend que tous les processus soient terminés, puis redémarre la tâche de formation en utilisant la nouvelle taille mondiale et le dernier point de contrôle.
Remarque : Lorsque Kueue n'est pas utilisé, l'opérateur de formation ignore les deux premières étapes. Il tente immédiatement de créer les modules supplémentaires nécessaires à la nouvelle taille du monde. Si des ressources suffisantes ne sont pas disponibles dans le cluster, ces pods resteront dans l'état En attente jusqu'à ce que la capacité soit disponible.

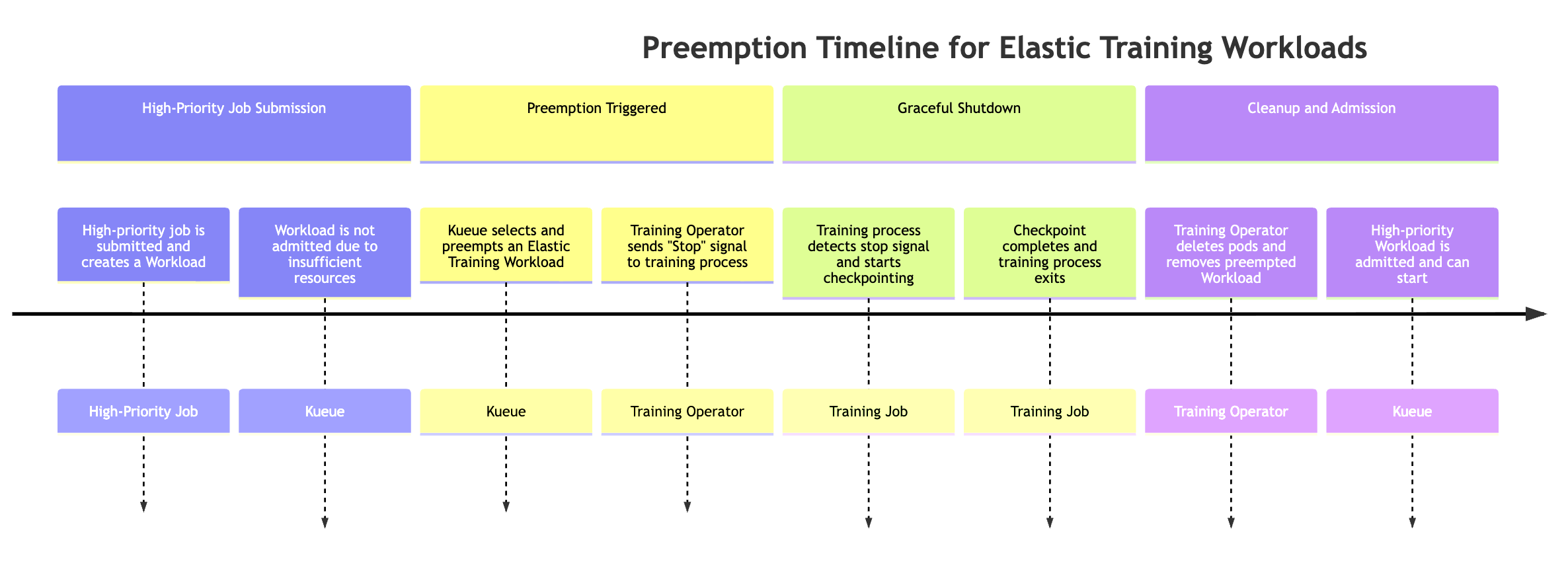
Préemption par un emploi hautement prioritaire
Les tâches élastiques peuvent être réduites automatiquement lorsqu'une tâche hautement prioritaire nécessite des ressources. Pour simuler ce comportement, vous pouvez soumettre une tâche d'entraînement élastique, qui utilise le maximum de ressources disponibles dès le début de la formation, puis soumettre une tâche hautement prioritaire et observer un comportement de préemption.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
Lorsqu'une tâche hautement prioritaire nécessite des ressources, Kueue peut préempter les charges de travail Elastic Training moins prioritaires (plusieurs objets de charge de travail peuvent être associés à une tâche Elastic Training). Le processus de préemption suit la séquence suivante :
-
Une tâche hautement prioritaire est soumise La tâche crée une nouvelle charge de travail Kueue, mais la charge de travail ne peut pas être admise en raison de ressources insuffisantes du cluster.
-
Kueue préempte l'une des charges de travail de la tâche Elastic Training Les tâches élastiques peuvent avoir plusieurs charges de travail actives (une par configuration mondiale). Kueue en sélectionne un à préempter en fonction des politiques de priorité et de file d'attente.
-
L'opérateur de formation envoie un signal d'événement élastique. Une fois que la préemption est déclenchée, l'opérateur d'entraînement indique au processus d'entraînement en cours d'arrêt progressif.
-
Le processus de formation effectue des points de contrôle. Le travail de formation vérifie périodiquement la présence de signaux d'événements élastiques. Lorsqu'il est détecté, il lance un point de contrôle coordonné afin de préserver la progression avant de s'arrêter.
-
un opérateur de formation nettoie les nacelles et les charges de travail. L'opérateur attend la fin du point de contrôle, puis supprime les modules d'entraînement qui faisaient partie de la charge de travail préemptée. Il supprime également l'objet Workload correspondant de Kueue.
-
La charge de travail hautement prioritaire est admise. Une fois les ressources libérées, Kueue accepte la tâche hautement prioritaire, ce qui lui permet de commencer à être exécutée.
La préemption peut entraîner une pause de l'ensemble de la tâche de formation, ce qui n'est peut-être pas souhaitable pour tous les flux de travail. Pour éviter une suspension complète des tâches tout en permettant une évolutivité élastique, les clients peuvent configurer deux niveaux de priorité différents au sein d'une même tâche de formation en définissant deux replicaSpec sections :
-
Un ReplicaSpec principal (fixe) avec une priorité normale ou élevée
-
Contient le nombre minimum de répliques nécessaires au bon déroulement de la tâche de formation.
-
Utilise une valeur supérieure PriorityClass pour garantir que ces répliques ne sont jamais préemptées.
-
Maintient les progrès de base même lorsque le cluster est soumis à une pression sur les ressources.
-
-
Un ReplicaSpec élastique (évolutif) avec une priorité inférieure
-
Contient les répliques facultatives supplémentaires qui fournissent des capacités de calcul supplémentaires lors de la mise à l'échelle élastique.
-
Utilise une valeur inférieure PriorityClass, ce qui permet à Kueue de préempter ces répliques lorsque des tâches prioritaires nécessitent des ressources.
-
Garantit que seule la partie élastique est récupérée, tandis que l'entraînement de base se poursuit sans interruption.
-
Cette configuration permet une préemption partielle, seule la capacité élastique étant récupérée, ce qui permet de maintenir la continuité de la formation tout en garantissant un partage équitable des ressources dans les environnements multi-locataires. Exemple :
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
Gestion de l'expulsion du pod, des pannes du pod et de la dégradation du matériel :
L'opérateur de HyperPod formation inclut des mécanismes intégrés permettant de reprendre le processus d'entraînement lorsqu'il est interrompu de manière inattendue. Les interruptions peuvent survenir pour diverses raisons, telles que des défaillances du code d'entraînement, l'expulsion de pods, des défaillances de nœuds, une dégradation du matériel et d'autres problèmes d'exécution.
Dans ce cas, l'opérateur tente automatiquement de recréer les modules concernés et de reprendre l'entraînement à partir du dernier point de contrôle. Si le rétablissement n'est pas immédiatement possible, par exemple en raison d'une capacité de réserve insuffisante, l'opérateur peut poursuivre sa progression en réduisant temporairement la taille du monde et en réduisant le travail d'entraînement élastique.
Lorsqu'une tâche d'entraînement élastique se bloque ou perd des répliques, le système se comporte comme suit :
-
Phase de restauration (utilisation de nœuds de rechange) Le Training Controller attend que
faultyScaleDownTimeoutInSecondsles ressources soient disponibles et tente de récupérer les répliques défaillantes en redéployant les pods sur de la capacité inutilisée. -
Réduction élastique Si la reprise n'est pas possible dans le délai imparti, l'opérateur de formation réduit la taille de la tâche à une taille mondiale plus petite (si la politique d'élasticité de la tâche le permet). L'entraînement reprend ensuite avec moins de répliques.
-
Mise à l'échelle élastique Lorsque des ressources supplémentaires sont à nouveau disponibles, l'opérateur redimensionne automatiquement la tâche de formation à la taille mondiale souhaitée.
Ce mécanisme garantit que la formation peut se poursuivre avec un temps d'arrêt minimal, même en cas de pression sur les ressources ou de défaillances partielles de l'infrastructure, tout en tirant parti de l'évolutivité élastique.
Utilisez l'entraînement élastique avec d'autres HyperPod fonctionnalités
Elastic Training ne prend actuellement pas en charge les fonctionnalités de formation sans point de contrôle, le point de contrôle hiérarchisé HyperPod géré ou les instances Spot.
Note
Nous collectons certaines mesures opérationnelles agrégées et anonymisées de routine afin de garantir la disponibilité des services essentiels. La création de ces métriques est entièrement automatisée et n'implique aucun examen humain de la charge de travail de formation du modèle sous-jacent. Ces indicateurs concernent une tâche et le dimensionnement des opérations, la gestion des ressources et les fonctionnalités essentielles des services.
