Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d’un modèle de tâche d’employé personnalisé
Pour créer une tâche d’étiquetage personnalisée, vous devez mettre à jour le modèle de tâche d’employé, mapper les données d’entrée de votre fichier manifeste aux variables utilisées dans le modèle et mapper les données de sortie à Amazon S3. Pour en savoir plus sur les fonctionnalités avancées qui utilisent l’automatisation Liquid, consultez Ajout de l’automatisation avec Liquid.
Les sections suivantes décrivent chacune des étapes requises.
Modèle de tâche d’employé
Un modèle de tâche d’employé est un fichier utilisé par Ground Truth pour personnaliser l’interface utilisateur employé (UI). Vous pouvez créer un modèle de tâche de travail à l'aide de HTML, de CSS JavaScript, du langage de modèle Liquid
Consultez les rubriques suivantes pour apprendre à créer un modèle de tâche d’employé. Vous pouvez consulter un référentiel d'exemples de modèles de tâches de travail de Ground Truth sur GitHub
Utilisation du modèle de tâches du travailleur de base dans la console SageMaker AI
Vous pouvez utiliser un éditeur de modèles dans la console Ground Truth pour commencer à créer un modèle. Cet éditeur inclut un certain nombre de modèles de base préconçus. Il prend en charge le remplissage automatique pour le code HTML et les éléments HTML Crowd.
Pour accéder à l’éditeur de modèles personnalisés Ground Truth :
-
Suivez les instructions incluses dans Création d’une tâche d’étiquetage (Console).
-
Sélectionnez ensuite Personnalisé pour le Type de tâche d’étiquetage.
-
Sélectionnez Suivant et vous pouvez alors accéder à l’éditeur de modèles et aux modèles de base dans la section Configuration des tâches d’étiquetage personnalisées.
-
(Facultatif) Sélectionnez un modèle de base dans le menu déroulant sous Modèles. Si vous préférez créer un modèle à partir de zéro, choisissez Personnalisé dans le menu déroulant pour un squelette de modèle minimal.
Utilisez la section suivante pour savoir comment visualiser un modèle développé localement dans la console.
Visualisation locale des modèles de tâches d’employé
Vous devez utiliser la console pour tester la manière dont votre modèle traite les données entrantes. Pour tester l’apparence du code HTML et des éléments personnalisés de votre modèle, vous pouvez utiliser votre navigateur.
Note
Les variables ne seront pas analysées. Vous devrez peut-être les remplacer par des exemples de contenu lorsque vous visionnerez votre contenu localement.
L’exemple d’extrait de code suivant charge le code nécessaire pour afficher les éléments HTML personnalisés. Utilisez cela si vous voulez développer l’apparence de votre modèle dans votre éditeur préféré plutôt que dans la console.
Exemple
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
Création d’un exemple de tâche HTML simple
Maintenant que vous disposez du modèle de tâches du collaborateur de base, vous pouvez utiliser cette rubrique pour créer un modèle de HTML-based tâche simple.
Voici un exemple d’entrée d’un fichier manifeste d’entrée.
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
Dans le modèle de tâche HTML, nous devons mapper les variables du fichier manifeste d’entrée au modèle. La variable de l’exemple de manifeste d’entrée serait mappée à l’aide de la syntaxe suivante task.input.source, task.input.labels et task.input.header.
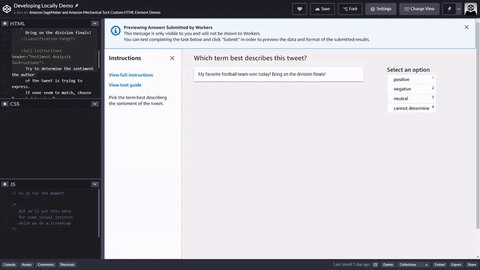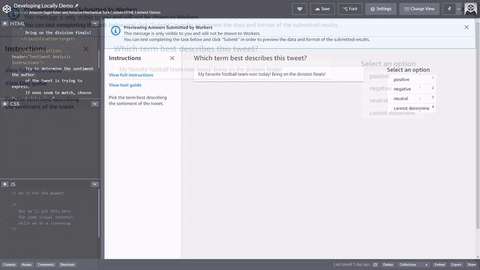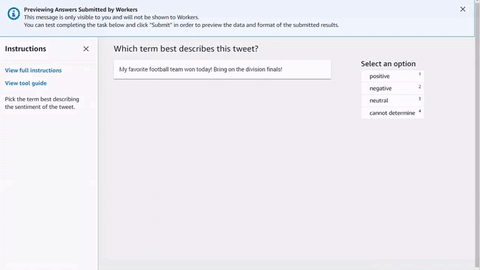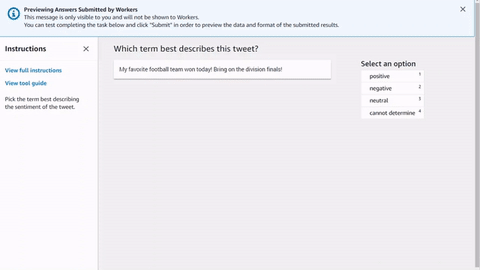
Voici un exemple simple de modèle de tâche d’employé HTML pour l’analyse de tweets. Toutes les tâches commencent et se terminent par les éléments <crowd-form> </crowd-form>. Comme les éléments HTML <form> standard, tout votre code de formulaire doit figurer entre ces éléments. Ground Truth génère les tâches des employés directement à partir du contexte spécifié dans le modèle, sauf si vous implémentez une fonction Lambda de pré-annotation. L’objet taskInput renvoyé par Ground Truth ou Pre-annotation Lambda est l’objet task.input de vos modèles.
Pour une simple tâche d’analyse de tweets , utilisez l’élément <crowd-classifier>. Il exige les attributs suivants :
name : nom de votre variable de sortie. Les annotations d’employé sont enregistrées sous ce nom de variable dans votre manifeste de sortie.
categories : tableau au format JSON des réponses possibles.
header : titre pour l’outil d’annotation
L’élément <crowd-classifier> nécessite au moins les trois éléments enfants suivants.
<classification-target> : texte que l’employé classera en fonction des options spécifiées dans l’attribut
categoriesci-dessus.<full-instructions> : instructions disponibles à partir du lien « Afficher les instructions complètes » de l’outil. Cet attribut peut rester vide, mais nous vous recommandons de donner de bonnes instructions pour obtenir de meilleurs résultats.
<short-instructions> : brève description de la tâche qui s’affiche dans la barre latérale de l’outil. Cet attribut peut rester vide, mais nous vous recommandons de donner de bonnes instructions pour obtenir de meilleurs résultats.
Une version simple de cet outil se présenterait comme suit. La variable {{ task.input.source }} est ce qui spécifie les données source de votre fichier manifeste d’entrée. {{ task.input.labels | to_json }} est un exemple de filtre de variable pour transformer le tableau en représentation JSON. L’attribut categories doit être JSON.
Exemple de l'utilisation de crowd-classifier avec l'exemple de manifeste d'entrée json
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
Vous pouvez copier et coller le code dans l'éditeur du flux de travail de création de tâches d'étiquetage de Ground Truth pour prévisualiser l'outil, ou essayer une démonstration de ce code sur CodePen.
Données d’entrée, actifs externes et votre modèle de tâches
Les sections suivantes décrivent l’utilisation d’actifs externes, les exigences relatives au format des données d’entrée et les circonstances dans lesquelles il convient d’envisager d’utiliser des fonctions Lambda de pré-annotation.
Exigences de format des données d’entrée
Lorsque vous créez un fichier manifeste d’entrée à utiliser dans votre tâche d’étiquetage Ground Truth personnalisée, vous devez stocker les données dans Amazon S3. Les fichiers manifestes d'entrée doivent également être enregistrés dans le même fichier que celui Région AWS dans lequel votre tâche d'étiquetage Ground Truth personnalisée doit être exécutée. En outre, il peut être stocké dans n’importe quel compartiment Amazon S3 accessible au rôle de service IAM que vous utilisez pour exécuter votre tâche d’étiquetage personnalisée dans Ground Truth.
Les fichiers manifestes d’entrée doivent utiliser le format JSON ou lignes JSON délimité par de nouvelles lignes. Chaque ligne est délimitée par un saut de ligne standard, \n ou \r\n. Chaque ligne doit également être un objet JSON valide.
En outre, chaque objet JSON du fichier manifeste doit contenir l’une des clés suivantes : source-ref ou source. La valeur des clés est interprétée comme suit :
-
source-ref: la source de l’objet est l’objet Amazon S3 spécifié dans la valeur. Utilisez cette valeur lorsque l’objet est un objet binaire, comme une image. -
source: la source de l’objet est la valeur. Utilisez cette valeur lorsque l’objet est une valeur de texte.
Pour en savoir plus sur le formatage de vos fichiers manifestes d’entrée, consultez Fichiers manifestes source.
Pre-annotation Fonction Lambda
Vous pouvez éventuellement spécifier une fonction Lambda de pré-annotation pour gérer la manière dont les données de votre fichier manifeste d’entrée sont traitées avant l’étiquetage. Si vous avez spécifié la paire clé-valeur isHumanAnnotationRequired, vous devez utiliser une fonction Lambda de pré-annotation. Lorsque Ground Truth envoie à la fonction Lambda de pré-annotation une requête au format JSON, elle utilise les schémas suivants.
Exemple objet de données identifié par la paire clé-valeur source-référence
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
Exemple objet de données identifié par la paire clé-valeur source
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
Voici la réponse attendue de la fonction Lambda lorsque isHumanAnnotationRequired est utilisé.
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
Utilisation de ressources externes
Les modèles personnalisés Amazon SageMaker Ground Truth permettent d'intégrer des scripts externes et des feuilles de style. Par exemple, le bloc de code suivant montre comment ajouter une feuille de style située dans https://www.example.com/my-enhancement-styles.css à votre modèle.
Exemple
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
Si vous rencontrez des erreurs, veillez à ce que votre serveur d’origine envoie le type MIME et les en-têtes d’encodage corrects avec les ressources.
Par exemple, types d’encodage et MIME pour les scripts distants : application/javascript;CHARSET=UTF-8.
Type d’encodage et MIME pour les feuilles de style distantes : text/css;CHARSET=UTF-8.
Les données de sortie et votre modèle de tâche
Les sections suivantes décrivent les données de sortie d’une tâche d’étiquetage personnalisée et indiquent dans quels cas envisager d’utiliser une fonction Lambda de post-annotation.
Données de sortie
Une fois votre tâche d’étiquetage personnalisée terminée, les données sont enregistrées dans le compartiment Amazon S3 spécifié au moment où la tâche d’étiquetage a été créée. Les données sont enregistrées dans un fichier output.manifest.
Note
labelAttributeNameest une variable d'espace réservé. Dans votre sortie, il s’agit soit du nom de votre tâche d’étiquetage, soit du nom de l’attribut d’étiquette que vous spécifiez lorsque vous créez la tâche d’étiquetage.
-
sourceousource-ref: il a été demandé aux employés d’étiqueter la chaîne ou une URI S3. -
labelAttributeName: un dictionnaire contenant le contenu d’étiquette consolidé issu de la fonction Lambda de post-annotation. Si aucune fonction Lambda de post-annotation n’est spécifiée, ce dictionnaire sera vide. -
labelAttributeName-metadata: les métadonnées de votre tâche d’étiquetage personnalisée ont été ajoutées par Ground Truth. -
worker-response-ref: l’URI S3 du compartiment dans lequel les données sont enregistrées. Si une fonction Lambda de post-annotation est spécifiée, cette paire clé-valeur ne sera pas présente.
Dans cet exemple, l’objet JSON est mis en forme afin de faciliter la lecture. Dans le fichier de sortie proprement dit, l’objet JSON se trouve sur une seule ligne.
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
Utilisation d’une fonction Lambda de post-annotation pour consolider les résultats de vos employés
Par défaut, Ground Truth enregistre les réponses des employés non traitées dans Amazon S3. Pour avoir un contrôle plus précis sur le traitement des réponses, vous pouvez spécifier une fonction Lambda de post-annotation. Par exemple, une fonction Lambda de post-annotation peut être utilisée pour consolider les annotations si plusieurs employés ont étiqueté le même objet de données. Pour en savoir plus sur la création de fonctions Lambda de post-annotation, consultez Post-annotation Lambda.
Si vous souhaitez utiliser une fonction Lambda de post-annotation, elle doit être spécifiée dans le AnnotationConsolidationConfig d’une demande CreateLabelingJob.
Pour en savoir plus sur le fonctionnement de la consolidation des annotations, consultez Consolidation d’annotation.
