Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comment fonctionne le tamisage SageMaker intelligent
L'objectif du criblage SageMaker intelligent est de passer au crible vos données d'entraînement pendant le processus d'entraînement et de ne fournir au modèle que des échantillons plus informatifs. Lors d'un entraînement classique avec PyTorch, les données sont envoyées de manière itérative par lots à la boucle d'entraînement et aux dispositifs accélérateurs (tels que les GPU ou les puces Trainium) par le. PyTorchDataLoader
Le schéma suivant donne un aperçu de la conception de l'algorithme de tamisage SageMaker intelligent.
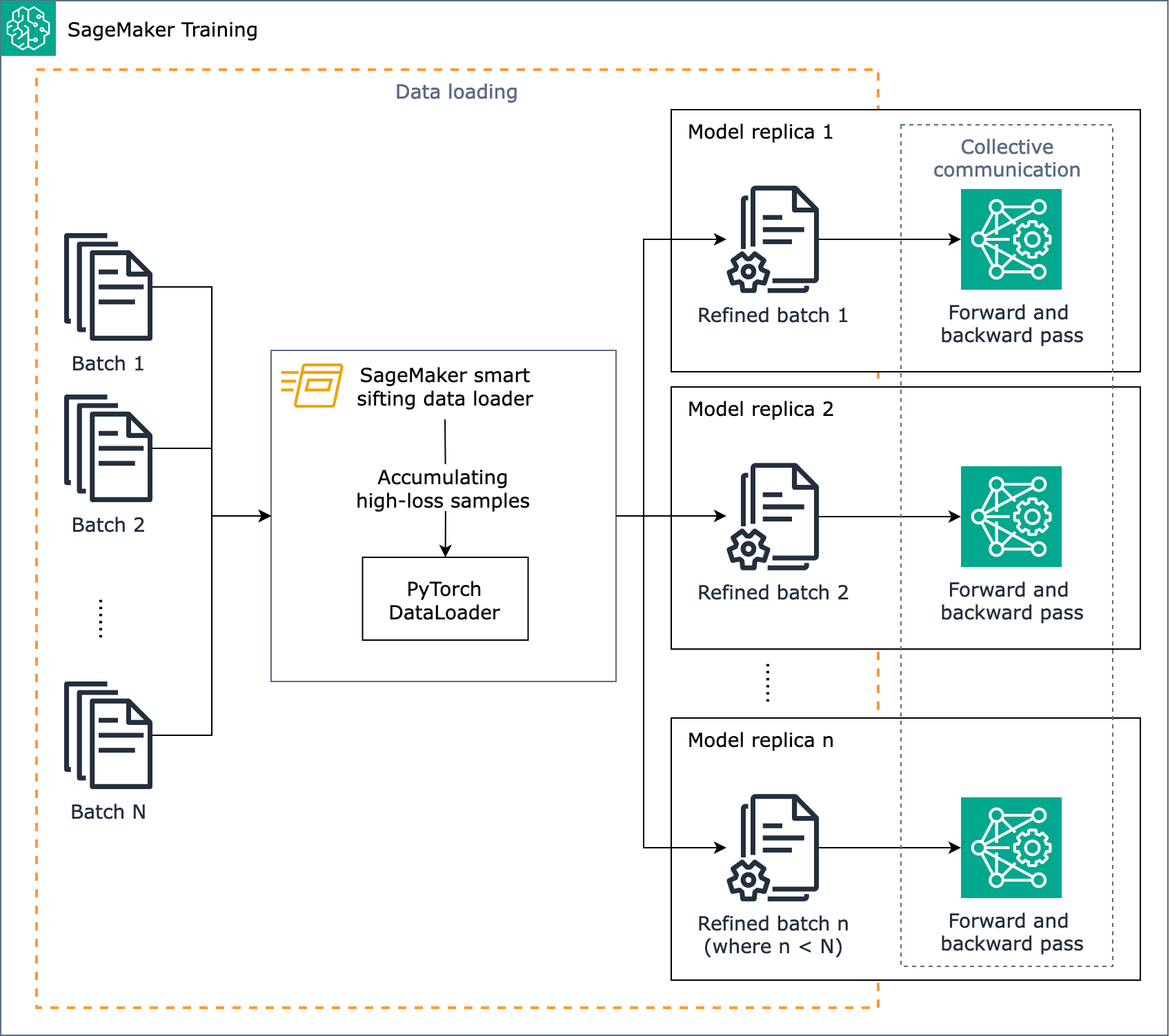
En bref, le tamisage SageMaker intelligent fonctionne pendant l'entraînement lorsque les données sont chargées. L'algorithme de tamisage SageMaker intelligent calcule les pertes sur les lots et élimine les données qui ne s'améliorent pas avant le passage en avant et en arrière de chaque itération. Le lot de données affinées est ensuite utilisé pour la transmission avant et arrière.
Note
Le tri intelligent des données sur l' SageMaker IA utilise des passes avancées supplémentaires pour analyser et filtrer vos données d'entraînement. En retour, il y a moins de transmissions arrière, car les données les moins pertinentes sont exclues de votre tâche d’entraînement. De ce fait, les modèles dont les transmissions arrière sont longues ou coûteuses obtiennent les meilleurs gains d’efficacité lorsqu’ils utilisent l’analyse intelligente. Par ailleurs, si la transmission avant de votre modèle prend plus de temps que la transmission arrière, la surcharge peut augmenter le temps total d’entraînement. Pour mesurer le temps passé par chaque transmission, vous pouvez exécuter une tâche d’entraînement pilote et collecter des journaux qui enregistrent le temps passé sur les processus. Pensez également à utiliser SageMaker Profiler qui fournit des outils de profilage et une application d'interface utilisateur. Pour en savoir plus, veuillez consulter la section Amazon SageMaker Profiler.
SageMaker le criblage intelligent convient aux tâches de PyTorch-based formation utilisant le parallélisme de données distribué classique, qui permet de répliquer le modèle sur chaque processeur graphique et de le rendre performant. AllReduce Il fonctionne avec le PyTorch DDP et la bibliothèque SageMaker AI distributed data parallel library.
