Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
SageMaker Résolution des problèmes liés au compilateur
Important
Amazon Web Services (AWS) annonce qu'il n'y aura aucune nouvelle version ou version de SageMaker Training Compiler. Vous pouvez continuer à utiliser SageMaker Training Compiler via les AWS Deep Learning Containers (DLC) existants pour la SageMaker formation. Il est important de noter que même si les DLC existants restent accessibles, ils ne recevront plus de correctifs ni de mises à jour AWS, conformément à la politique de support du AWS Deep Learning Containers Framework.
Si vous rencontrez une erreur, vous pouvez utiliser la liste suivante pour essayer de résoudre votre tâche d’entraînement. Si vous avez besoin d'une assistance supplémentaire, contactez l'équipe SageMaker AI via le AWS support
La tâche d’entraînement ne converge pas comme prévu par rapport à la tâche d’entraînement du cadre natif
Les problèmes de convergence vont de « le modèle n'apprend pas lorsque le compilateur de SageMaker formation est activé » à « le modèle apprend mais plus lentement que le framework natif ». Dans ce guide de résolution des problèmes, nous partons du principe que votre convergence est satisfaisante sans SageMaker Training Compiler (dans le framework natif) et nous considérons cela comme une référence.
Face à de tels problèmes de convergence, la première étape consiste à déterminer si le problème se limite à l’entraînement distribué ou s’il provient d’un entraînement sur un seul GPU. La formation distribuée avec SageMaker Training Compiler est une extension de la formation avec un seul GPU avec des étapes supplémentaires.
-
Configurez un cluster avec plusieurs instances ou GPU.
-
Distribuez les données d’entrée à tous les collaborateurs.
-
Synchronisez les mises à jour du modèle émanant de tous les collaborateurs.
Par conséquent, tout problème de convergence lié à l’entraînement sur un seul GPU se propage à l’entraînement distribué impliquant plusieurs collaborateurs.
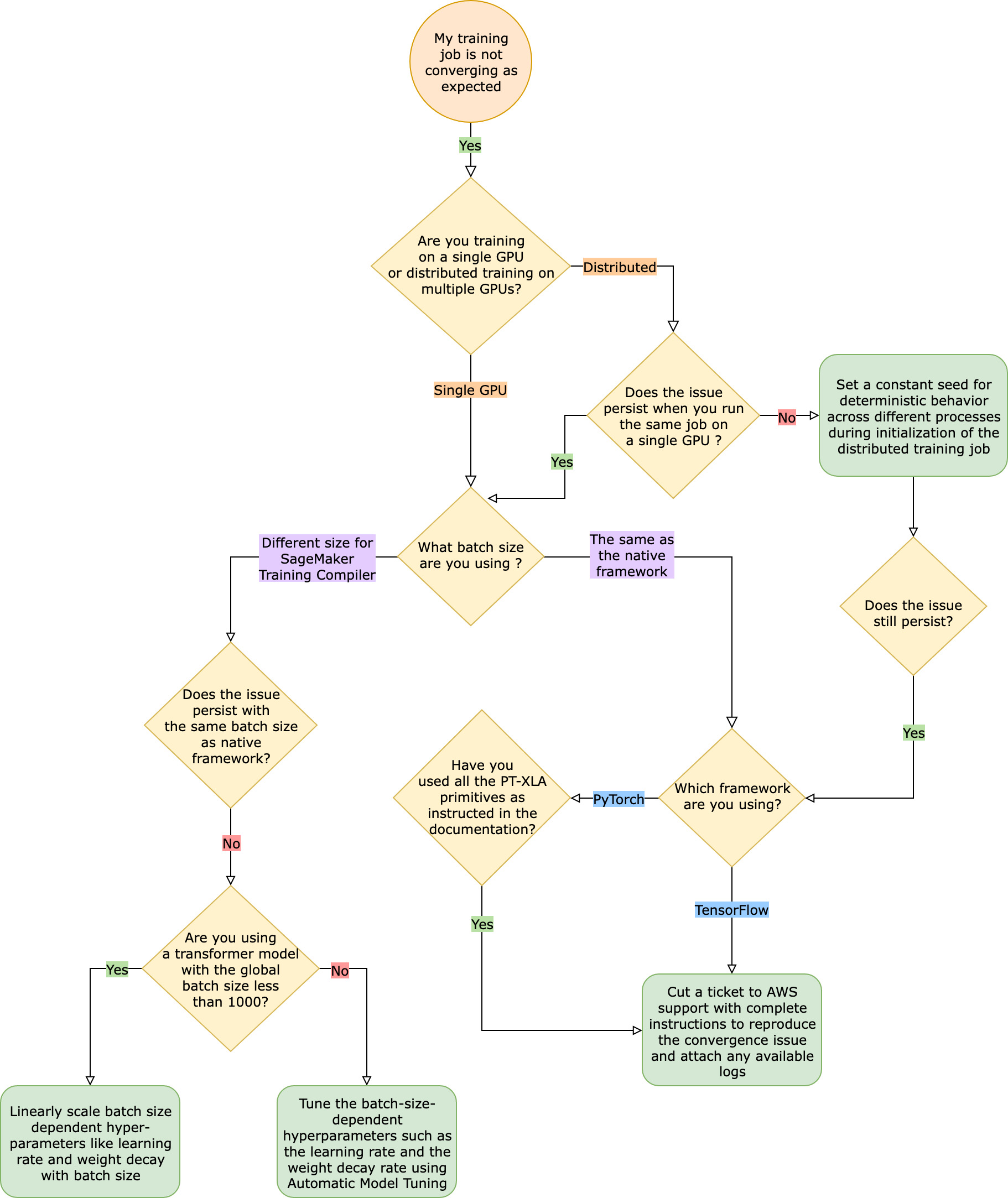
Problèmes de convergence survenant lors de l’entraînement sur un seul GPU
Si votre problème de convergence provient d’un entraînement sur un seul GPU, cela est probablement dû à de mauvais paramètres pour les hyperparamètres ou les API torch_xla.
Vérifier les hyperparamètres
L'entraînement avec SageMaker Training Compiler entraîne une modification de l'empreinte mémoire d'un modèle. Le compilateur arbitre intelligemment la réutilisation et le recalcul, ce qui entraîne une augmentation ou une diminution correspondante de la consommation de mémoire. Pour en tirer parti, il est essentiel de réajuster la taille du lot et les hyperparamètres associés lors de la migration d'une tâche de formation vers Training Compiler SageMaker . Cependant, de mauvais réglages des hyperparamètres provoquent souvent des oscillations dans la perte d’entraînement et, par conséquent, un ralentissement possible de la convergence. Dans de rares cas, des hyperparamètres agressifs peuvent empêcher le modèle d’apprendre (la métrique de perte d’entraînement ne diminue pas ou ne revient pas sur NaN). Pour déterminer si le problème de convergence est dû aux hyperparamètres, effectuez un test côte à côte de deux tâches d'entraînement avec et sans SageMaker Training Compiler tout en conservant les mêmes hyperparamètres.
Vérifiez si les API torch_xla sont correctement configurées pour l’entraînement sur un seul GPU
Si le problème de convergence persiste avec les hyperparamètres de base, vous devez vérifier s’il existe une mauvaise utilisation des API torch_xla, en particulier celles destinées à la mise à jour du modèle. Fondamentalement, torch_xla continue d’accumuler des instructions (en différant l’exécution) sous forme de graphe jusqu’à ce qu’il soit explicitement invité à exécuter le graphe accumulé. La fonction torch_xla.core.xla_model.mark_step() facilite l’exécution du graphe accumulé. L’exécution du graphe doit être synchronisée à l’aide de cette fonction après chaque mise à jour du modèle et avant d’imprimer et de journaliser des variables. Sans étape de synchronisation, le modèle peut utiliser des valeurs périmées stockées en mémoire lors des impressions, des journaux et des transferts ultérieurs, au lieu d’utiliser les valeurs les plus récentes qui doivent être synchronisées après chaque itération et mise à jour du modèle.
Cela peut être plus compliqué lorsque vous utilisez SageMaker Training Compiler avec des techniques de mise à l'échelle du dégradé (éventuellement à l'aide d'AMP) ou de découpage en dégradé. L’ordre approprié de calcul du gradient avec AMP est le suivant.
-
Calcul du gradient avec mise à l’échelle
-
Mise à l’échelle décroissante du gradient, écrêtage de gradient, puis mise à l’échelle croissante
-
Mise à jour du modèle
-
Synchronisation de l’exécution du graphe avec
mark_step()
Pour trouver les API adaptées aux opérations mentionnées dans la liste, consultez le guide de migration de votre script d'entraînement vers SageMaker Training Compiler.
Envisagez d’utiliser le réglage de modèle automatique
Si le problème de convergence survient lors du réajustement de la taille du lot et des hyperparamètres associés tels que le taux d'apprentissage lors de l'utilisation du compilateur d' SageMaker entraînement, envisagez d'utiliser le réglage automatique du modèle pour ajuster vos hyperparamètres. Vous pouvez vous référer à l'exemple de bloc-notes sur le réglage des hyperparamètres avec SageMaker Training Compiler
Problèmes de convergence survenant lors de l’entraînement distribué
Si votre problème de convergence persiste dans l’entraînement distribué, cela est probablement dû à de mauvais paramètres pour l’initialisation du poids ou les API torch_xla.
Vérifier l’initialisation du poids chez les collaborateurs
Si le problème de convergence survient lors de l’exécution d’une tâche d’entraînement distribué impliquant plusieurs collaborateurs, assurez-vous qu’il existe un comportement déterministe uniforme pour tous les collaborateurs en définissant une vitesse constante, le cas échéant. Méfiez-vous des techniques telles que l’initialisation du poids qui implique une randomisation. Chaque collaborateur peut finir par entraîner un modèle différent en l’absence d’une valeur constante.
Vérifier si les API torch_xla sont correctement configurées pour l’entraînement distribué
Si le problème persiste, cela est probablement dû à une mauvaise utilisation des API torch_xla pour l’entraînement distribué. Assurez-vous d'ajouter les éléments suivants dans votre estimateur pour configurer un cluster pour l'entraînement distribué avec SageMaker Training Compiler.
distribution={'torchxla': {'enabled': True}}
Votre script d’entraînement doit également contenir une fonction _mp_fn(index), qui est appelée une fois par collaborateur. Sans cette fonction mp_fn(index), vous risquez de laisser chaque collaborateur entraîner le modèle de manière indépendante sans partager les mises à jour du modèle.
Ensuite, assurez-vous d'utiliser l'torch_xla.distributed.parallel_loader.MpDeviceLoaderAPI avec l'échantillonneur de données distribué, comme indiqué dans la documentation sur la migration de votre script d'entraînement vers SageMaker Training Compiler, comme dans l'exemple suivant.
torch.utils.data.distributed.DistributedSampler()
Cela garantit que les données d’entrée sont correctement distribuées entre tous les collaborateurs.
Enfin, pour synchroniser les mises à jour du modèle provenant de tous les collaborateurs, utilisez torch_xla.core.xla_model._fetch_gradients pour rassembler les gradients de tous les collaborateurs et torch_xla.core.xla_model.all_reduce pour combiner tous les gradients collectés en une seule mise à jour.
Cela peut être plus compliqué lorsque vous utilisez SageMaker Training Compiler avec des techniques de mise à l'échelle du dégradé (éventuellement en utilisant l'AMP) ou des techniques de découpage en dégradé. L’ordre approprié de calcul du gradient avec AMP est le suivant.
-
Calcul du gradient avec mise à l'échelle
-
Synchronisation du gradient entre tous les collaborateurs
-
Mise à l’échelle décroissante du gradient, écrêtage de gradient, puis mise à l’échelle croissante du gradient
-
Mise à jour du modèle
-
Synchronisation de l'exécution du graphe avec
mark_step()
Notez que cette liste de contrôle contient un élément supplémentaire pour la synchronisation de tous les collaborateurs par rapport à la liste de contrôle pour l’entraînement sur un seul GPU.
La tâche de formation échoue en raison d'une PyTorch/XLA configuration manquante
Si une tâche d’entraînement échoue avec le message d’erreur Missing XLA configuration, cela peut être dû à une mauvaise configuration du nombre de GPU par instance que vous utilisez.
XLA nécessite des variables d’environnement supplémentaires pour compiler la tâche d’entraînement. La variable d’environnement manquante la plus courante est GPU_NUM_DEVICES. Pour que le compilateur fonctionne correctement, vous devez définir cette variable d’environnement égale au nombre de GPU par instance.
Il existe trois approches pour définir la variable d’environnement GPU_NUM_DEVICES :
-
Approche 1 — Utilisez l'
environmentargument de la classe d'estimateur SageMaker AI. Par exemple, si vous utilisez une instanceml.p3.8xlargequi a quatre GPU, procédez comme suit :# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Approche 2 — Utilisez l'
hyperparametersargument de la classe d'estimateur SageMaker AI et analysez-le dans votre script d'entraînement.-
Pour spécifier le nombre de GPU, ajoutez une paire valeur-clé à l’argument
hyperparameters.Par exemple, si vous utilisez une instance
ml.p3.8xlargequi a quatre GPU, procédez comme suit :# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
Dans votre script d’entraînement, analysez l’hyperparamètre
n_gpuset spécifiez-le en tant qu’entrée pour la variable d’environnementGPU_NUM_DEVICES.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Approche 3 : Hard-code variable d'
GPU_NUM_DEVICESenvironnement dans votre script d'entraînement. Par exemple, ajoutez les éléments suivants à votre script si vous utilisez une instance qui a quatre GPU.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
Astuce
Pour connaître le nombre de dispositifs GPU sur les instances de machine learning que vous souhaitez utiliser, consultez Calcul accéléré
SageMaker Le compilateur d'entraînement ne réduit pas le temps total d'entraînement
Si le temps d'entraînement total ne diminue pas avec SageMaker Training Compiler, nous vous recommandons vivement de consulter la SageMaker Bonnes pratiques et considérations relatives à la formation des compilateurs page pour vérifier votre configuration d'entraînement, votre stratégie de remplissage pour la forme du tenseur d'entrée et les hyperparamètres.
